






代码: https://github.com/microsoft/muzic/tree/main/deeprapper
论文:https://arxiv.org/pdf/2107.01875.pdf
本文提出了一种新的用于rap生成的语言模型
在训练和生成中对歌词序列中的节拍进行建模。
将预训练纳入我们的模型,以进一步提高rap生成的质量。
在预训练阶段,
我们基于上述两个数据集【1)具有对齐的节拍的非说唱歌曲、2)纯歌词】对我们的DeepRapper模型进行预训练。
然后,我们根据节奏调整说唱歌曲来微调我们预先训练的模型。
微调后的模型用于最终的rap生成
我们在DeepRapper中引入了N -gram押韵建模来处理rap中不同的押韵模式。
我们设计了一个数据挖掘管道来自动提取节拍-歌词对齐
目录
DeepRapper: Neural Rap Generation with Rhyme and Rhythm Modeling
Vocal and Accompaniment Separation人声和伴奏分离
Vocal and Lyric Alignment人声和歌词对齐
Lyric and Beat Alignment歌词和节拍对齐
4.2.1 reverse-order language model逆序语言模型
Case Analyses on Generated Raps 对生成的rap的案例分析
DeepRapper: Neural Rap Generation with Rhyme and Rhythm Modeling
具有韵律和节奏建模的神经说唱生成
Abstract
Rap生成,旨在产生歌词和相应的歌唱节拍,需要模拟押韵和节奏。之前的Rap生成作品集中在押韵歌词,但忽略了节奏节拍,这对说唱表演很重要。在本文中,我们开发了DeepRapper,一个基于Transformer的说唱生成系统,可以模拟押韵和节奏。由于没有可用的有节奏节拍的说唱数据集,我们开发了一个数据挖掘管道来收集一个大规模的说唱数据集,其中包括大量歌词和有节奏节拍一致的饶舌歌曲。其次,我们设计了一个基于变换的自回归语言模型Transformer-based autoregressive language model,它仔细地建模押韵和节奏。具体来说,我们以相反的顺序生成歌词,押韵表示和约束增强,并在歌词中插入一个节拍符号用于节奏/节拍建模。据我们所知,DeepRapper是第一个同时用押韵和节奏产生说唱的系统。客观和主观的评价都表明,深度说唱歌手产生创造性和高质量的说唱和押韵和节奏。代码将在GitHub【https://github.com/microsoft/muzic/tree/main/deeprapper 】上发布。
1 Introduction
说唱是20世纪70年代起源于美国的一种音乐形式,并迅速发展成为世界主流音乐流派之一(Keyes,2004)。随着人工智能的快速发展,rap歌词自动生成引起了学术界的关注(Potash et al .,2015;马尔米等人,2016;梁等,2018;尼科洛夫等人,2020年)。一般来说,说唱歌词需要在语义上有意义,并且流行,以传达有趣的故事或表达情感。不同于自然语言或其他艺术流派(例如,歌词或诗歌)说唱音乐有着鲜明的特点:1)它通常在几个连续的句子之间包含复杂的押韵模式,这是形成一个良好的流程的关键;2)它需要与歌唱节拍一致,因为说唱歌词通常是根据一些节奏伴奏来说唱的。因此,如何生成具有良好押韵和节奏的说唱歌词是一个棘手的问题。
之前的作品(Potash等人,2015;马尔米等人,2016;梁等,2018;Nikolov et al .,2020)主要关注歌词生成,其中一些人开发了押韵建模策略。Potash等人(2015年)直接在诗句末尾添加了“< endLine >”标记,并期望隐式学习押韵模式。Nikolov等人(2020)应用了两步策略,首先生成说唱歌词,然后在生成的歌词末尾添加韵脚标记。然而,这些方法不能保证每一行歌词的押韵模式,并且只关心最后一行的押韵。虽然许多作品研究了其他艺术体裁(如诗歌)的押韵模式(李等,2020;范德克鲁伊,2020;刘等,2020),它们不适合说唱生成由于复杂的押韵结构在说唱。例如,诗歌只需要与每个词尾的最后一个词押韵,而说唱音乐则需要在每个句子的末尾与多个连续的标记押韵。
据我们所知,以前没有作品研究过节奏建模(即说唱中的节拍)。其中一个主要原因是缺乏节拍-歌词对齐的说唱数据集。因此,没有节奏节拍的歌词生成不能被视为完整的说唱生成。
在本文中,我们开发了DeepRapper,这是一个基于Transformer (Vaswani et al .,2017)的rap生成系统,可以对押韵和节奏进行建模。为了构建该系统,由于没有可用的具有一致节奏节拍的rap数据集,我们设计了一个数据挖掘管道并收集大规模rap数据集用于节奏建模。具体来说,我们首先从网络上抓取许多说唱歌曲,每首歌曲都有说唱歌词和音频。对于每首抓取的说唱歌曲,我们执行一系列数据预处理步骤来提取节奏节拍以及节拍-歌词对齐。为了更好地模拟押韵,我们以渐进的方式从右到左生成说唱句子中的单词。这样做,我们可以很容易地确定一个句子的最后几个词(现在成为反序句子的第一个词)押韵。此外,我们将几个与押韵相关的表示合并到我们的语言模型中,以进一步提高押韵质量,并在推理过程中通过押韵约束鼓励生成的rap歌词中的N -gram押韵。我们使用一个特殊的标记[BEAT]来表示有节奏的节拍,并将其插入到歌词中相应单词的前面。这样,我们可以在训练和生成中对歌词序列中的节拍进行建模。
受预训练语言模型成功的启发(Devlin等人,2019;拉德福德等人,2018;杨等,2019;宋等,2019;刘等人,2019),我们将预训练纳入我们的系统。为了获得用于预训练的大规模数据,我们还使用我们的数据挖掘管道来收集另外两个数据集:1)具有对齐的节拍的非说唱歌曲,其可以大于说唱数据集,因为非说唱歌曲比说唱歌曲更普遍;2)纯歌词,可以比非说唱歌曲更大。在预训练阶段,我们基于上述两个数据集对我们的DeepRapper模型进行预训练。然后,我们根据节奏调整说唱歌曲来微调我们预先训练的模型。微调后的模型用于最终的rap生成。主客观评测都验证了DeepRapper在生成有韵脚有节奏的说唱歌词方面的优势。
我们的主要贡献可以总结如下:
- 为了模拟rap生成中的节奏,我们开发了一个数据挖掘管道来创建带有对齐节奏节拍的rap数据集。
- 为了更好地模拟押韵,我们设计了一个自回归语言模型来从右到左生成带有押韵约束的说唱歌词。据我们所知,DeepRapper是第一个明确建模N-gram韵脚的。
- 我们精心地在歌词中插入节拍标记来模拟有节奏的节拍。DeepRapper是第一个为rap生成建模节奏的系统。
2 Background
由于DeepRapper生成的rap歌词同时具有押韵和节奏建模,因此在本节中,我们简单介绍一下相关背景:歌词生成、押韵建模和节奏建模。
歌词生成Lyric Generation
广义来说,歌词生成可以涵盖rap歌词生成(Potash et al .,2015;尼科洛夫等人,2020;梁等,2018)、song lyric generation(渡边等,2018;陆等,2019;陈和,2020;盛等,2020),general poetry generation(张、拉帕塔,2014;Lau等人,2018;李等,2020;刘等,2020)等。与以往利用语言模型生成类似于自然语言的歌词不同,本文提出了一种新的用于rap生成的语言模型,通过精心设计的韵律和节奏模型来适应rap歌词的特点。此外,受预训练语言模型成功的启发(Devlin等人,2019;杨等,2019;刘等,2019;拉德福德等人,2019;Song et al .,2019)在NLP应用中,我们还将预训练纳入我们的模型,以进一步提高rap生成的质量。
押韵建模Rhyme Modeling
押韵建模在rap生成中起着重要的作用,它要求连续句子中的最后几个记号具有相同的押韵模式。现有的rap生成系统要么直接在rap歌词的结尾添加特殊标记“< endLine >”,以对模型进行编码来学习韵律结构(Potash等人,2015),要么引入两步策略来进行韵律建模,首先生成rap歌词,然后在生成的歌词之后添加韵律标记(Nikolov等人,2020)。然而,这些作品只关注单格韵,而说唱更欣赏n格韵。虽然很多作品在其他类型中探索了押韵建模,但是大部分都不能直接用于rap生成。比如诗歌生成(Lau et al .,2018;志鹏等,2019;廖等,2019;李等,2020)通常使用预定义的格式来控制押韵模式,因为诗歌通常有固定的字数,只关心最后一个词的押韵模式。然而,说唱歌词在多个连续的句子中有不同的押韵结构,最重要的是多个连续的单词。因此,我们在DeepRapper中引入了N -gram押韵建模来处理rap中不同的押韵模式。此外,我们还以相反的顺序(即从右到左)训练我们的语言模型,类似于以前的工作(Van de Cruys,2020),以更好地模拟押韵,因为它们总是出现在句子的末尾。
节奏建模Rhythm Modeling
节奏建模通常用于音乐生成(朱等,2018;黄和杨,2020;Ren等人,2020),其生成音符的持续时间以及音符音高,以在旋律和伴奏生成中形成有节奏的节拍。与音乐生成不同,rap更在乎节奏节拍而不是音符音高(即旋律)。这样,生成的说唱歌词需要与相应的节奏节拍对齐,才能被说唱,否则不能视为完整的说唱。然而,据我们所知,以前的作品没有研究过说唱生成中的节奏建模。在这篇文章中,我们介绍了一种新颖的节拍建模策略。
3 Rap Dataset Mining Rap数据集挖掘
前期作品(Potash等,2015;梁等,2018;Nikolov等人,2020)通常使用只有歌词的rap数据集,而不考虑节奏节拍信息。为了在rap生成中建模节奏,rap数据集应该包含具有对齐的节奏节拍的歌词。然而,节拍对齐很难获得,因为它们的注释需要具有专业知识的音乐家来识别说唱歌曲中的重音音节。为了解决这个问题,我们设计了一个数据挖掘管道来自动提取节拍-歌词对齐。在本节中,我们将详细介绍数据挖掘管道以及基于该管道挖掘的数据集。
3.1数据挖掘管道

图1概述了我们的数据挖掘管道,它由5个步骤组成:数据爬行、人声和伴奏分离、人声和歌词对齐、节拍检测以及歌词和节拍对齐。
Data Crawling数据抓取
为了挖掘大规模的说唱数据集,我们首先从网络上抓取大量带有歌词和演唱音频的说唱歌曲。为了确保歌词和音频可以在句子级别对齐,这有利于我们稍后的单词级别节拍对齐,我们还爬取了每个歌词句子对应于音频的开始和结束时间。
Vocal and Accompaniment Separation人声和伴奏分离
对于每首rap歌曲,我们利用Spleeter (Hennequin等人,2020) 【https://github.com/deezer/spleeter】,一种公共音乐分离工具,从抓取的rap音频中分离出人声(包含rap演唱)和伴奏(包含节奏节拍)。
Vocal and Lyric Alignment人声和歌词对齐
我们根据每个歌词的开始和结束时间将分离的人声划分到句子级别,从而可以获得句子级别的人声-歌词对齐。我们通过 音素化器Phonemizer 【https://github.com/bootphon/phonemizer
】将歌词转换成音素,并利用蒙特利尔强制对齐器Montreal Forced Aligner【https://github.com/MontrealCorpusTools/MontrealForced-Aligner】来获得音素级别的声乐歌词对齐。基于这些音素级别的声乐歌词对齐,我们获得了歌唱音频中每个单词的相应时间戳。
Beat Detection节拍检测
为了获得歌词和节拍之间的对齐,我们需要知道每个节拍的时间戳。因此,我们使用节拍轨迹检测工具Librosa (McFee et al .,2020) 【https://github.com/librosa/librosa】来跟踪来自从第二步获得的分离伴奏的每个节拍的时间戳。
Lyric and Beat Alignment歌词和节拍对齐
在我们获得每个单词和每个节拍的时间戳后,我们可以根据它们的时间戳将它们对齐在一起。然而,由于说唱歌手可能不会完全跟着节拍唱歌,直接使用时间戳来精确匹配单词和节拍是不合适的。因此,我们提出一种近似的方法来对齐它们。 Denote the word sequence of a lyric


表1:三个挖掘数据集的统计数据。第二和第三列表示每个数据集的歌曲和句子的数量。
3.2 Mined Datasets挖掘的数据集
使用上述数据挖掘管道,我们获得了具有对齐节拍的rap歌词数据集(命名为D-RAP,其中D表示“数据集”),这满足了构建具有韵律和节奏建模的RAP生成系统的要求。我们以4:1的比例将D-RAP数据集分成训练集和验证集。由于说唱只是音乐流派中的一种,并且与更一般的歌曲相比,说唱歌曲的数量通常更少,所以我们还利用相同的挖掘管道挖掘另外两个数据集来预训练我们的DeepRapper模型:1)具有对齐节拍的非说唱歌曲(命名为D-SONG);2)没有对齐节拍的纯歌词(命名为D-LYRIC)。我们在表1中总结了三个数据集的统计数据,并在图2中显示了一首说唱歌曲,其节拍与D-Rap一致。
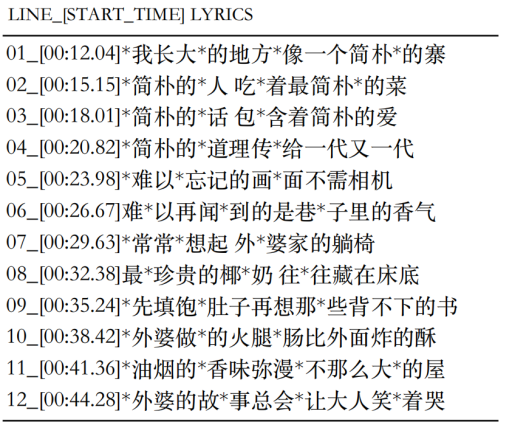
图2:在我们挖掘的“D-rap”数据集中,一首RAP歌曲的节拍是一致的。'* '表示节拍与紧接在' * '后面的单词对齐。内容的翻译在补充材料中。
4 Rap Generation Model
在这一节中,我们介绍我们的Rap生成模型的架构,以及它的押韵建模和节奏建模的细节。
4.1模型概述
图3说明了我们的rap生成模型的详细架构。我们使用 Transformer(瓦斯瓦尼等人,2017年)来建立一个autoregressive language model自动回复语言模型(拉德福德等人,2018年,2019年)。对于rap生成,引入了几个新的设计:
- 为了更好地模拟押韵,我们的模型从右到左生成句子,因为押韵的单词总是在句子的末尾;
- 如前所述,节奏对于rap性能至关重要,因此我们为显式节拍建模插入了一个特殊的标记[BEAT];
- 与只有单词嵌入和位置嵌入的原始Transformer不同,我们添加了多个附加嵌入来更好地模拟韵律和节奏。
接下来,我们在4.2小节中介绍我们的韵律建模,在4.3小节中介绍节奏建模。
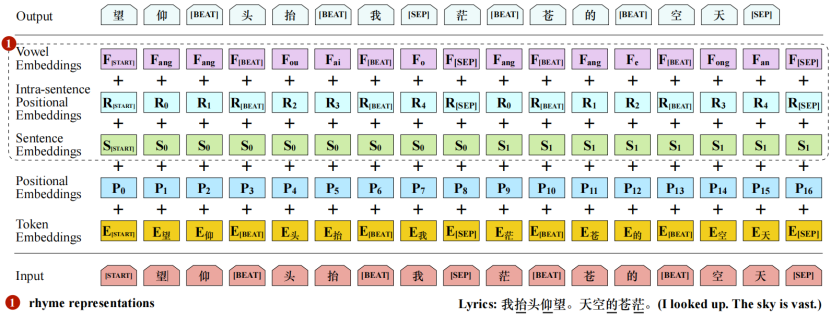
图3:我们的DeepRapper中rap生成模型的架构。这里的输入序列是一个来自中国说唱的样本,名为《红色》。该示例包含两个节拍对齐的歌词句子。每一句都反过来做押韵建模。因此,样本的原始形式是:我抬头仰望。天空的苍茫。带下划线的单词表示一个节拍与这个单词对齐。句子由特殊符号“[SEP]”分隔。标记“[START]”表示歌曲的开始。
4.2 Rhyme Modeling押韵
押韵是形成良好说唱流的关键。在DeepRapper中,我们用三个组件来模拟押韵:1)逆序语言模型 reverse-order language model;2)押韵表现 rhyme
representation;3)押韵限制 rhyme constraint。
4.2.1 reverse-order language model逆序语言模型
押韵词通常出现在每个抒情句子的末尾。如果使用标准的自回归语言模型,从左到右生成标记,我们需要识别当前生成步骤是否是句子的结尾,这决定了是否要生成与前面句子一致的押韵词。因此,为了更好地模拟押韵,我们使用逆序语言模型从右到左生成句子,如图3所示。这样做我们可以很容易地识别一个句子的最后几个词(现在是倒序句的前几个词)来控制它们的押韵。请注意,我们只是颠倒了一个句子中的单词,仍然按照原来的顺序生成不同的句子。图4比较了从左到右顺序和从右到左顺序的句子,从中可以看出,每个句子的押韵词在逆序中共享相同的相对位置(偏移到第一个标记),易于建模和控制。
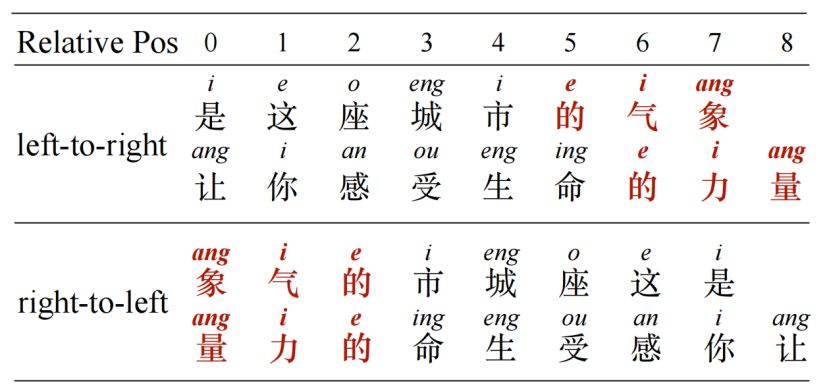
图4:从左到右和从右到左顺序的句子对比。每个记号的上标代表它的韵脚。
4.2.2 Rhyme Representation
押韵词有两个重要特征:1)用于押韵的元音;2)在句子中的相对位置,决定连续句子中押韵词之间的对应关系(例如,在逆序设置中,当前句子的第一个/第二个词应与前一个句子的第一个/第二个词押韵)。
我们用汉字拼音中的元音来代表它们的韵脚。为此,我们构建一个元音词典F()
来识别每个单词的元音。如图3所示,我们添加了额外的元音嵌入F和句内相对位置嵌入R,以增强每个单词的押韵表示。此外,为了更好地识别不同的句子,我们引入一个句子嵌入S来区分不同的句子。
4.2.3 Rhyme Constraint
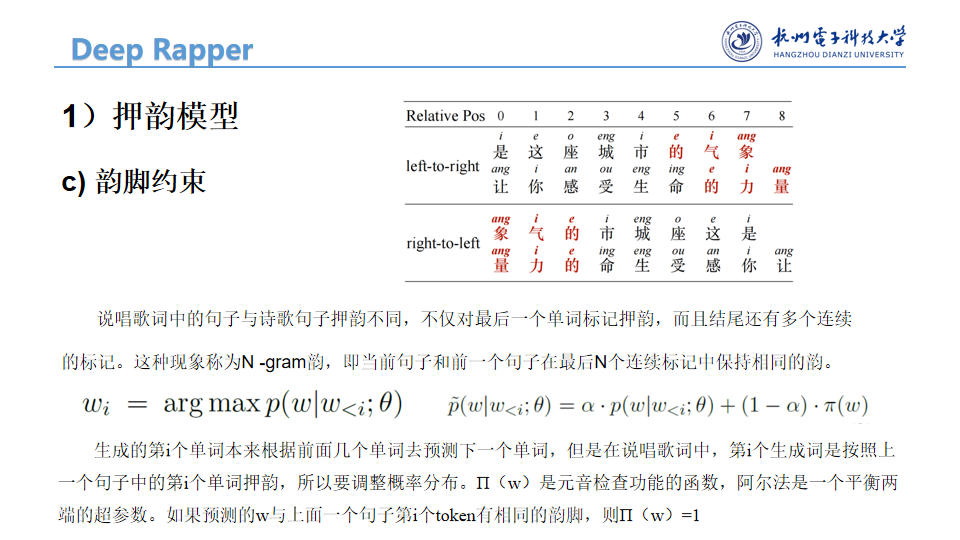
除了逆序语言模型和韵脚表示,我们还引入了韵脚约束来提高推理中韵脚生成的质量。如图4所示,说唱歌词中的句子不仅与最后一个标记押韵,而且结尾还有多个连续的标记。我们把这种现象称为N -gram韵,这意味着当前句子和前一个句子在最后N个连续标记中保持相同的韵。据我们所知,以前没有研究过N-gram韵(N > 1),尽管它对提高rap质量很重要。我们提出的韵脚约束使我们的模型能够调整下一个预测记号的概率,以进一步鼓励N元韵脚生成。约束条件介绍如下。
为了在标准推理过程中生成第i个单词wi,我们通常选择具有最大概率的预测标记,即![]() ,其中w<i表示逆序句中位置i之前的词,θ是模型。当前句和上句的位置i之前的单词有相同的押韵模式时,我们会使用调整后的概率分布p ̃(w|w<i;θ)鼓励第i个生成的词按照上一句的第i个词押韵,形成N格韵。调整后的概率分布p ̃(w|w<i;θ)为:
,其中w<i表示逆序句中位置i之前的词,θ是模型。当前句和上句的位置i之前的单词有相同的押韵模式时,我们会使用调整后的概率分布p ̃(w|w<i;θ)鼓励第i个生成的词按照上一句的第i个词押韵,形成N格韵。调整后的概率分布p ̃(w|w<i;θ)为:
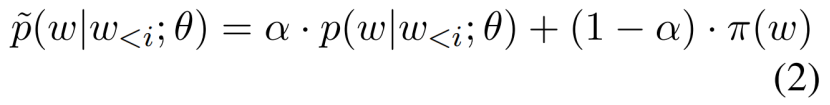
其中π(w)是元音检查函数,α是用于平衡这两项的超参数。这里,如果预测的w与前一句中的第i个标记具有相同的元音,则π(w)为1,否则为0。换句话说,在预测第i个token(i ≤ N)时,我们鼓励我们的模型更多地关注这些与上一句中第i个token具有相同元音的单词。通过这种方式,模型倾向于生成具有大N的N -gram韵脚。
4.3 Rhythm Modeling节奏建模
生成具有对齐节拍的歌词是必要的,因为说唱歌词需要用有节奏的节拍来说唱。因此,我们建模并生成带有特定符号的歌词的节奏节拍:我们将节拍视为一个特殊的 token [BEAT],并将其插入到歌词序列中进行模型训练。如图3所示,我们在它的对齐单词前插入[BEAT],如下面的示例: "我[BEAT]抬 头[BEAT]仰望。天空[BEAT]的苍[BEAT]茫。"
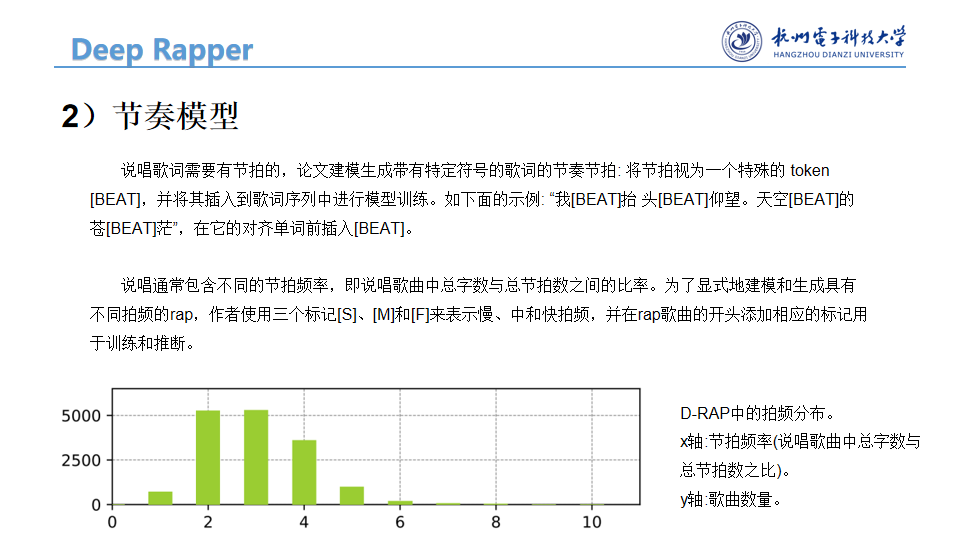
说唱通常包含不同的节拍频率,即说唱歌曲中总字数与总节拍数之间的比率。为了显式地建模和生成具有不同拍频的rap,我们使用三个标记[S]、[M]和[F]来表示慢、中和快拍频,并在rap歌曲的开头添加相应的标记用于训练和推断。在我们的D-RAP数据集中,拍频的分布如图5所示。根据分布,我们将[S]、[M]、[F]分别赋给拍频小于3、等于3、大于3的歌曲。

图5:D-RAP中的拍频分布。x轴:节拍频率(说唱歌曲中总字数与总节拍数之比)。y轴:歌曲数量。
5实验设置
5.1模型、数据和训练配置
我们的DeepRapper模型建立在 autoregressive自回归 Transformer decoder上(Vaswani等人,2017;拉德福德等人,2018,2019),其中隐藏大小、关注头数量和Transformer层数设置为768,12,12。DeepRapper中所有不同种类的嵌入的维数设置为768。考虑到不存在逆序的预训练语言模型,我们不利用任何预训练语言模型进行初始化。相反,我们首先在D-LYRIC和D-SONG上预训练我们的模型两百万步,然后在D-RAP上用3K步微调我们的模型,因为D-RAP的大小小于我们的预训练语料库。我们通过剪切较长的序列或填充较短的序列,将每首歌曲转换成长度为1024个记号的序列。我们的模型在4个NVIDIA TITAN V GPUs上以8首歌曲的批量进行训练。我们使用Adam optimizer,学习率为0.00015,β1 = 0.9,β2 = 0.999,ε = 10^-6。我们将N-gram韵的最大值设置为3,并将等式2中的超参数α设置为0.95。样本是根据给定的参考句子生成的。
5.2评估指标
在这一小节中,我们引入了客观和主观指标来评估生成的rap的质量。
客观评价
我们从语言质量、韵律和节奏方面对生成的rap进行评价。我们选择了五个度量来评估我们的模型:
- 困惑度Perplexity(PPL),一个评估语言模型质量的标准度量;
- 押韵准确度Rhyme Accuracy (RA),正确预测押韵的句子的比率;
- Rhyme density(RD),一首歌曲最长的押韵,对所有歌曲进行平均,由Malmi等人(2016)引入,用于衡量押韵流畅度的质量;
- Combo-N,在说唱歌曲中具有相同N-gram韵的连续句子的最大数量,在所有歌曲上平均,其中我们研究N = 1,2,3;
- 节拍准确度Beat Accuracy(BA),我们的模型在节拍预测中的准确度,在teacherforcing mode.模式下。
主观评价
与以前的作品相似(张和拉帕塔,2014;Nikolov等人,2020)在艺术创作中,我们也使用人工评估来准确评估生成的rap的质量。我们邀请了10个具有音乐专业知识的参与者作为人类注释者来评估100个样本rap。要求每个注释者从以下角度进行评分,从1(差)到5(完美):
- 说唱歌词主题的清晰性;
- 说唱歌词的流畅性;
- 押韵的质量;
- 押韵的多样性。
所有注释者在所有抽样rap上的平均分数被用作每个视角的评估分数。
6 Experimental Results
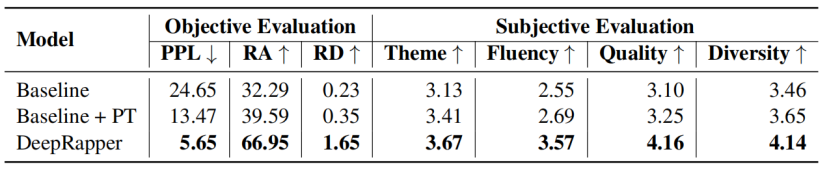
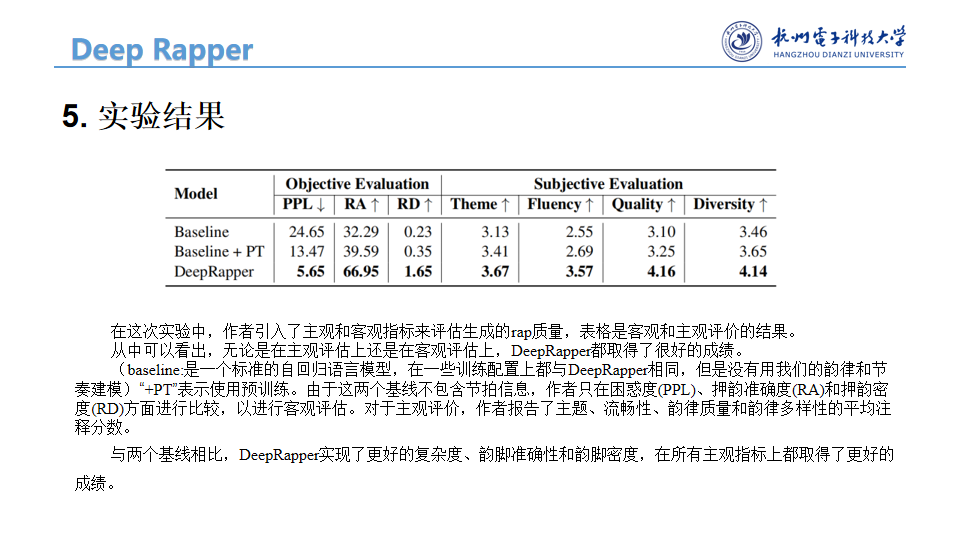
表2:客观和主观评价的结果。“+PT”表示使用预训练。由于这两个基线不包含节拍信息,我们只在困惑度(PPL)、押韵准确度(RA)和押韵密度(RD)方面进行比较,以进行客观评估。对于主观评价,我们报告了主题、流畅性、韵律质量和韵律多样性的平均注释分数。
结果
表2示出了与两个基线相比较的DeepRapper的客观和主观结果:1)基线:标准自回归语言模型,其具有与DeepRapper相同的模型配置,但是没有我们提出的韵律和节奏建模;2)基线+ PT,使用基线预训练。我们从表2中得到几个观察结果:
- 与两个基线相比,DeepRapper实现了更好的复杂度、韵脚准确性和韵脚密度,这证明了我们的方法在生成具有准确和多样韵脚的高质量rap歌词方面的优势。
- DeepRapper在所有主观指标上都取得了更好的成绩,证明了DeepRapper可以生成高质量且符合人类口味的押韵Rap。
- 预训练提高了基线在主客观指标上的表现,表明了预训练的重要性。但是,它的表现仍然比DeepRapper差。
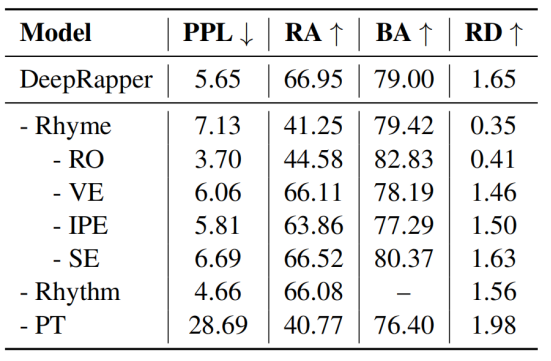
Ablation Studies
为了进一步验证DeepRapper中每个组件的必要性,我们进行了一系列消融研究,分别包括去韵建模、节奏建模和预训练。结果报告在表3中。我们有几个观察结果:
- 去除押韵模型对押韵质量影响很大,因为它导致押韵准确性和押韵密度的急剧下降;
- 去除押韵建模中的每个特定设计(即RO:逆序语言模型,VE:元音嵌入,IPE:句内位置嵌入,se:句子embedding)导致更差的押韵准确度和押韵密度。具体而言,虽然根据Wu等人(2018)的分析,移除RO会导致更好的PPL,因为从左到右的顺序比从右到左的顺序更容易建模,但它会导致押韵质量的准确性大幅下降。
- 很明显,没有节奏模型的DeepRapper不能产生任何节拍信息;
- 没有经过预训练的DeepRapper对困惑度和押韵准确度有很大影响,但获得了较高的押韵密度。原因是在没有预先训练的情况下,DeepRapper由于缺乏泛化能力(较大的PPL)而倾向于复制以前的押韵令牌。为了验证这一点,我们统计了押韵词的重复率,发现DeepRapper的重复率为23.8%,而没有预训练的重复率为42.5%,高于使用预训练的重复率。
以上结果验证了DeepRapper中各个组件的有效性。
表3:对DeepRapper中各成分的消融研究。“-”表示删除相应的组件。“Rhyme”、“Rhythm”和“PT”代表了押韵建模、节奏建模和预训练。“RO”、“VE”、“IPE”和“SE”分别是指逆序、元音嵌入、句内位置嵌入和句子嵌入。
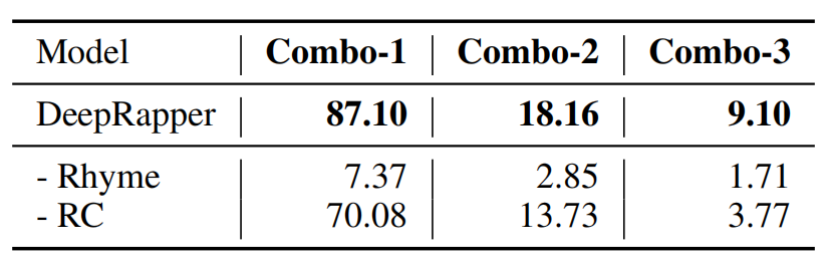
N-gram Rhyme
为了突出DeepRapper在建模N-gram韵方面的优势,我们使用Combo-N来衡量DeepRapper中每个设计对N-gram韵的建模能力。结果报告在表4中。我们可以发现
- 无韵建模的模型几乎不能生成好的韵,不管N-gram中N的值是多少;
- 消除押韵限制也削弱了生成N元押韵的能力。
这些结果进一步证明了我们的押韵建模和押韵约束在生成多个连续押韵中的重要性。
表4:N-gram押韵在组合N方面的质量。“- Rhyme”意味着去除押韵建模,“- RC”意味着在推理期间去除押韵约束
Beat Frequency
为了更好地测量节拍质量,我们通过DeepRapper和具有节拍频率控制的DeepRapper随机生成了大约5000个样本。我们提出了一阶分布(FOD)和二阶分布(SOD),并测量了这些分布在生成的样本和我们的DRAP数据集之间的距离(通过Wasserstein距离(Vallender,1974))。我们把当前[ BEAT]的间隔定义为当前[ BEAT]和下一个[ BEAT]之间的字数。所以FOD定义为当前[ BEAT]的间隔分布。类似地,SOD被定义为当前[ BEAT]和下一个[ BEAT]的间隔之间的差的分布。距离的结果被归一化为[0,1]并记录在表5中。可以看出,采用拍频控制的DeepRapper在拍频建模中获得了更好的性能,这表明了拍频控制在拍频建模中的重要性。
表5:节拍产生的测量值。“ + Beat Frequency”代表DeepRapper有节拍频率控制。

Case Analyses on Generated Raps 对生成的rap的案例分析
我们在图6中列出了一个来自我们生成的rap的样本案例,以展示由DeepRapper生成的rap的良好质量。通过将图2中示例的第一句输入到DeepRapper来生成样本。正如我们所看到的,生成的样本表现出良好的主题、流畅性和韵律。样本是一段说唱,有很多1格,2格,3格,甚至4格的韵脚。生成的歌词描绘了童年的美好回忆和对未来的美好憧憬。我们还提供了一组用拍频控制产生的样品。为了节省篇幅,我们把它们和所有例句的翻译放在附录里。https://deeprapper.github.io中提供了更多示例。
7结论
在本文中,我们开发了DeepRapper,这是一个新颖的基于Transformer的rap生成系统,它利用韵律建模、节奏建模和预训练来生成rap。考虑到没有可用的具有对齐的节奏节拍的rap数据集用于节奏建模,我们提出了一种数据挖掘管道来挖掘具有节拍-歌词对齐的rap数据集。我们利用从右到左生成、韵脚表示和韵脚约束来更好地模拟韵脚和鼓励N元韵脚,并通过在歌词序列中相应单词旁边插入节拍标记来显式地模拟节拍信息。据我们所知,DeepRapper是第一个同时生成押韵和节奏的rap的系统。客观和主观评价都表明,DeepRapper生成了高质量的rap,具有良好的韵律和节奏。由于DeepRapper的设计,我们可以进一步建立另一个rap演唱系统,根据韵律和节奏演唱rap,这是我们未来的工作。我们也将多语言DeepRapper作为未来的工作。

图6:由DeepRapper生成的rap。对于每个例子,我们提供每个单词对应的元音。红色的元音代表这个词与上一句押韵。粗体字表示节拍与单词对齐。例子的译文附在补充材料中。
ppt
























 9601
9601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









