







问题:在投稿时,遇到template中要求“Embed All Fonts”——即嵌入所有字体选项时应该如何操作?
回答:本操作基于word与福昕PDF阅览器展开;
(1)在word中生成pdf,文件>>导出>>创建PDF;
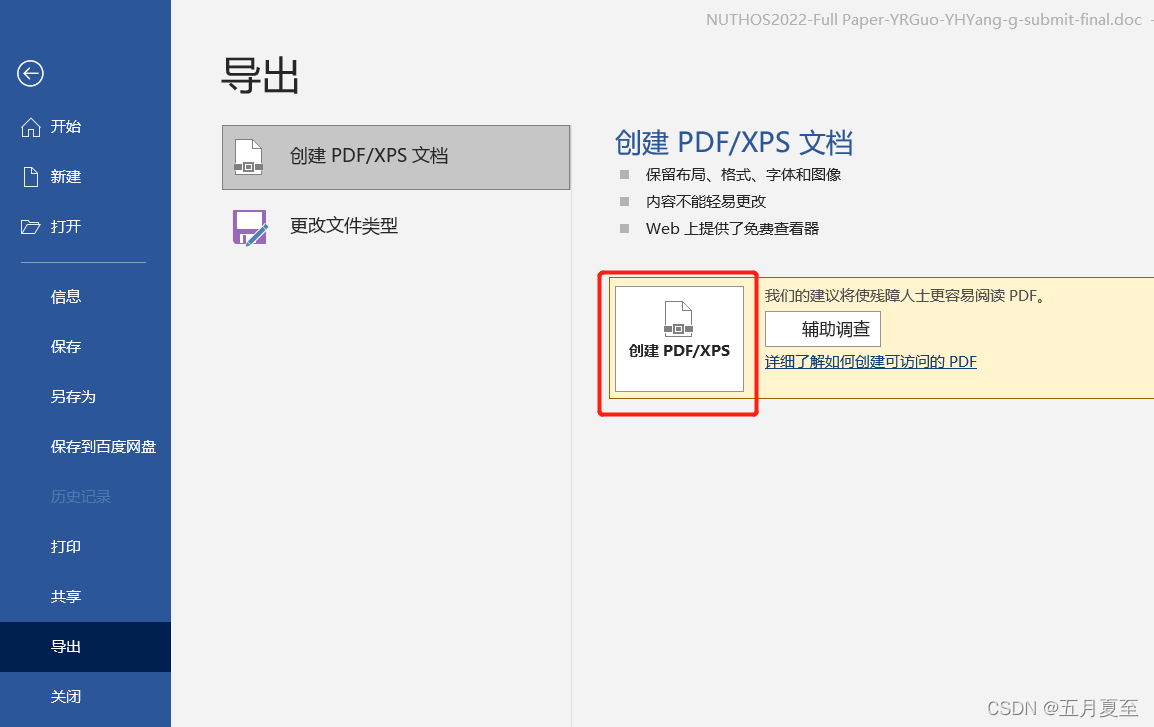 (2)在弹出框中选择:选项;
(2)在弹出框中选择:选项;
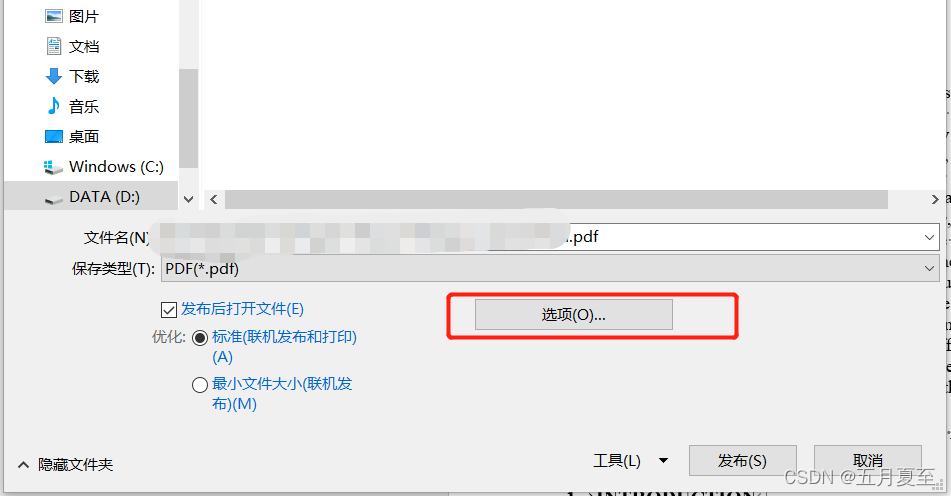 (3)在PDF选项中,默认的是“无法嵌入字体情况下显示文本位图”,在这里需要勾选“符合PDF/A”,默认选项会自动置灰;
(3)在PDF选项中,默认的是“无法嵌入字体情况下显示文本位图”,在这里需要勾选“符合PDF/A”,默认选项会自动置灰;
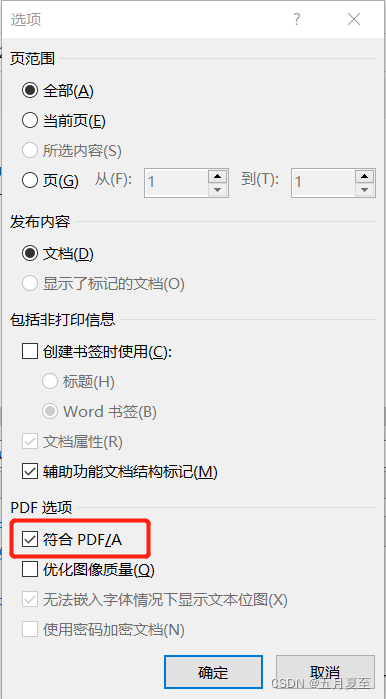
(4)生成完成PDF,然后再福昕阅读器中打开,并检查是否“全部嵌入字体”选项选择成功。
(5)在福昕中,选择文件>>文档属性>>字体,滑动查看,如果所有字体后都有“(嵌入字符集)”,则嵌入成功。


















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









