







前两篇博客分别总结了numpy和Pytorch中常用的乘法函数:
numpy常用乘法函数总结:np.dot()、np.multiply()、*、np.matmul()、@、np.prod()、np.outer()-CSDN博客
- 主要是 np.dot()、np.multiply()、*、np.matmul()、@ 五种,其中 np.matmul() 和 @ 完全等价,np.multiply() 和 * 在输入数据类型为 np.array 时也完全等价
Pytorch常用乘法函数总结:torch.mul()、*、torch.mm()、torch.bmm()、torch.mv()、torch.dot()、@、torch.matmul()-CSDN博客
- torch.mul() 和 * 等价,为element-wise乘,可广播;
- torch.mm() 二维矩阵乘法,torch.bmm() 三维批量矩阵乘法,均不可广播;
- torch.mv(mat, vec) 为矩阵向量乘法,不可广播;
- torch.dot() 仅支持两个一维向量点积,返回一个标量数字;
- @ 矩阵乘法,等价于 torch.dot() + torch.mv() + torch.mm();
- torch.matmul() 矩阵乘法,与 @ 类似,但它不止一维二维,可扩高维,可广播
本文总结TensorFlow常用的乘法函数,代码示例以TensorFlow2.x为例,其中 tf.tensordot() 这个函数的用法比较复杂;tf.einsum() 可以理解为一个通用的函数模板,在numpy和Pytorch中也有类似的函数和用法
常用
tf.multiply() 或 *【元素对位相乘】
tf.multiply(x, y) 等价于 x*y,为矩阵的element-wise乘法,要求两个矩阵的shape一致,或其中一个维度为1(扩展为另一个矩阵对应位置的维度大小)
import tensorflow as tf
X = tf.constant([[1, 2, 3], [4, 5 ,6]], dtype=tf.float32)
Y = tf.constant([[1, 1, 1], [2, 2 ,2]], dtype=tf.float32)
Z = tf.multiply(X, Y) # 乘法操作,对应位置元素相乘
out:
tf.Tensor(
[[ 1. 2. 3.]
[ 8. 10. 12.]], shape=(2, 3), dtype=float32)tf.matmul() 或 @【矩阵乘法】
tf.matmul(x, y) 等价于 x@y,为矩阵乘法,参与运算的是最后两维形成的矩阵
- 矩阵-向量乘法不能用这个函数,会报错,应该用 tf.linalg.matvec()
- 两个向量的点积不能用这个函数,会报错,可以用以下两种方式:
- tf.tensordot(a, b, axes=1) 或 tf.tensordot(a, b, axes=[0, 0])
- tf.reduce_sum(tf.multiply(a, b))
import tensorflow as tf
X = tf.constant([[1, 2, 3], [4, 5, 6]], dtype=tf.float32)
Y = tf.constant([[1, 2], [1, 2], [1, 2]], dtype=tf.float32)
Z = tf.matmul(X, Y) # 矩阵乘法操作
out:
tf.Tensor(
[[ 6. 12.]
[15. 30.]], shape=(2, 2), dtype=float32)不常用
tf.scalar_mul()【参数之一为标量】
标量和张量相乘(标量乘标量或向量或矩阵)
import tensorflow as tf
x = tf.constant(2, dtype=tf.float32)
Y1 = tf.constant(3, dtype=tf.float32)
Z1 = tf.scalar_mul(x, Y1) # 标量×标量
Y2 = tf.constant([1, 2, 3], dtype=tf.float32)
Z2 = tf.scalar_mul(x, Y2) # 标量×向量
Y3 = tf.constant([[1, 2, 3], [4, 5, 6]], dtype=tf.float32)
Z3 = tf.scalar_mul(x, Y3) # 标量×矩阵
out:
tf.Tensor(6.0, shape=(), dtype=float32)
tf.Tensor([2. 4. 6.], shape=(3,), dtype=float32)
tf.Tensor(
[[ 2. 4. 6.]
[ 8. 10. 12.]], shape=(2, 3), dtype=float32)tf.tensordot()
参考了博客 tensorflow和numpy库中tensordot详解-CSDN博客,但是规则看的有点迷糊 = = 按照我容易理解的方式归纳总结了几种情况
tf.tensordot(
a,
b,
axes,
name=None # 操作的名称(可选)
)
其中a和b是32位或者64位的tensor张量
axes:可以取值为整数N,代表的是a的倒数N个维度和b的正数N个维度相乘求和
也可以采用元组或者列表的形式,例如axes=(1,1)或者axes=[1,1]
函数输出的结果是两个张量按照上述规则形成的n维数组一维
axes=0(将第一个向量中的每个标量乘以第二个向量)
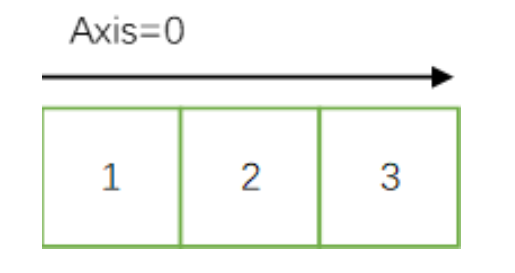
import tensorflow as tf
a = tf.constant([1, 2, 3], dtype=tf.float32)
b = tf.constant([4, 5, 6], dtype=tf.float32)
z = tf.tensordot(a, b, axes=0)
out:
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[ 4., 5., 6.],
[ 8., 10., 12.],
[12., 15., 18.]], dtype=float32)>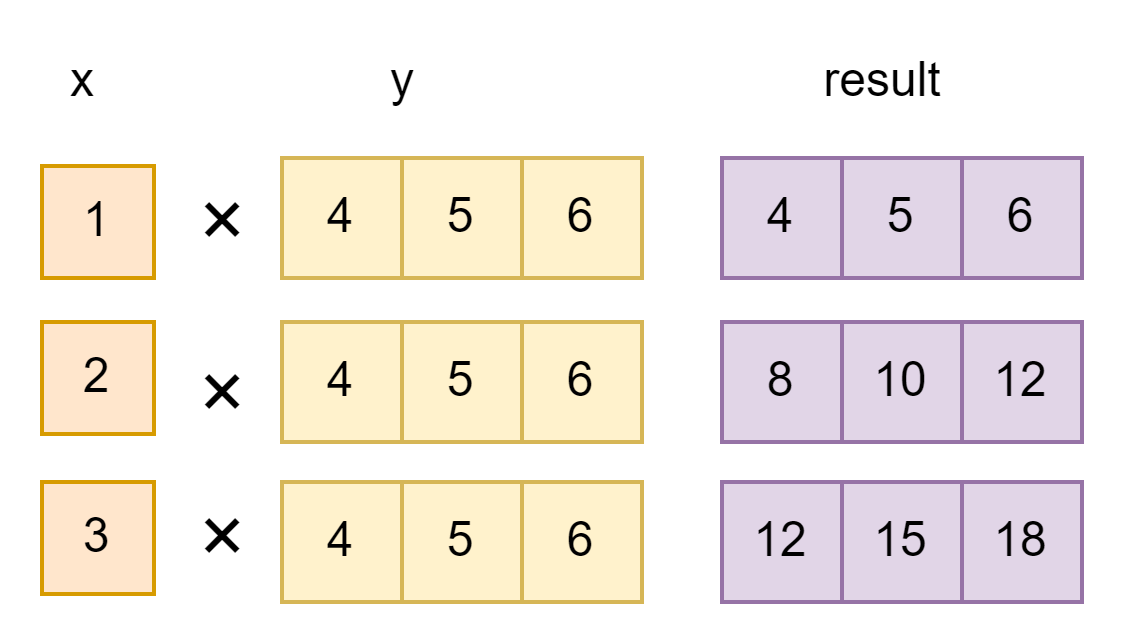
axes=1(两个一维向量的点积,等价于axes=[0,0])
import tensorflow as tf
a = tf.constant([1, 2, 3], dtype=tf.float32)
b = tf.constant([4, 5, 6], dtype=tf.float32)
z = tf.tensordot(a, b, axes=1) # 等价于 tf.tensordot(a, b, axes=[0,0])
out:
<tf.Tensor: shape=(), dtype=float32, numpy=32.0>二维
axes=0 对每一列操作,axes=1 对每一行操作
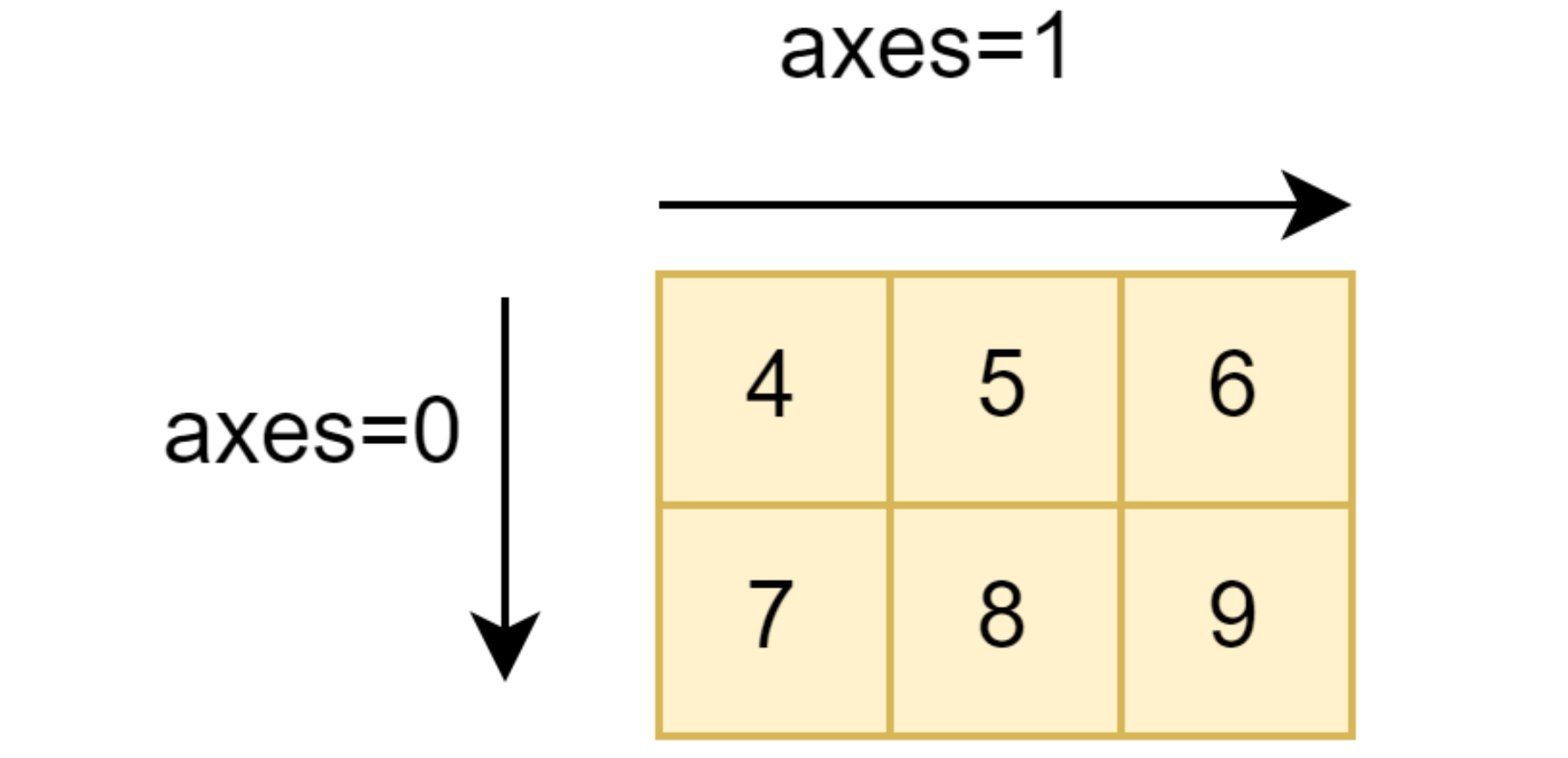
axes=0(将第一个矩阵中的每个标量乘以第二个矩阵整体,结果4维)
import tensorflow as tf
a = tf.constant([[1,2,3],[4,5,6]], dtype=tf.float32)
b = tf.constant([[4,5,6],[7,8,9]], dtype=tf.float32)
z = tf.tensordot(a, b, axes=0)
out:
<tf.Tensor: shape=(2, 3, 2, 3), dtype=float32, numpy=
array([[[[ 4., 5., 6.],
[ 7., 8., 9.]],
[[ 8., 10., 12.],
[14., 16., 18.]],
[[12., 15., 18.],
[21., 24., 27.]]],
[[[16., 20., 24.],
[28., 32., 36.]],
[[20., 25., 30.],
[35., 40., 45.]],
[[24., 30., 36.],
[42., 48., 54.]]]], dtype=float32)>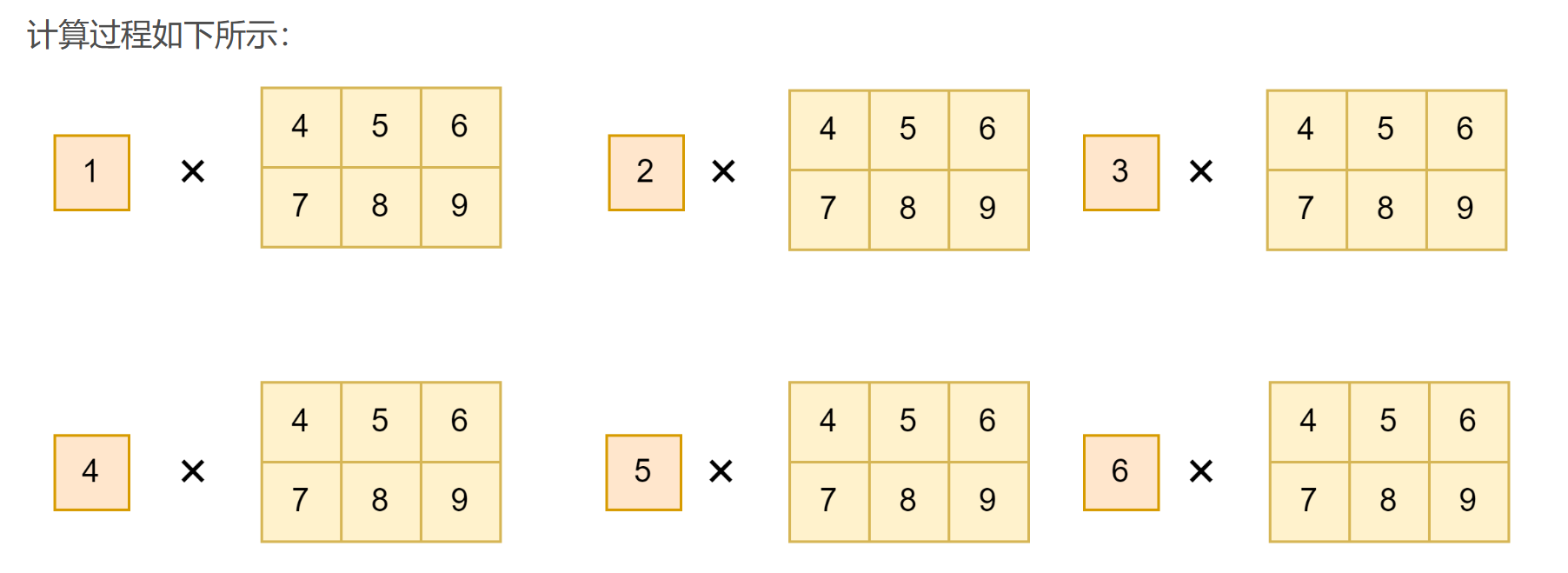
axes=1(对第二个参数转置后矩阵乘法)
直接 tf.tensordot(a, b, axes=1) 会报错
import tensorflow as tf
a = tf.constant([[1,2,3],[4,5,6]], dtype=tf.float32)
b = tf.constant([[4,5,6],[7,8,9]], dtype=tf.float32)
z = tf.tensordot(a, b, axes=1)
out:报错
InvalidArgumentError: Matrix size-incompatible: In[0]: [2,3], In[1]: [2,3] [Op:MatMul]把b进行转置后才不会报错,即 tf.tensordot(a, tf.transpose(b), axes=1),等价于 tf.matmul(a, tf.transpose(b))
import tensorflow as tf
a = tf.constant([[1,2,3],[4,5,6]], dtype=tf.float32)
b = tf.constant([[4,5,6],[7,8,9]], dtype=tf.float32)
z = tf.tensordot(a, tf.transpose(b), axes=1)
out:
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[ 32., 50.],
[ 77., 122.]], dtype=float32)>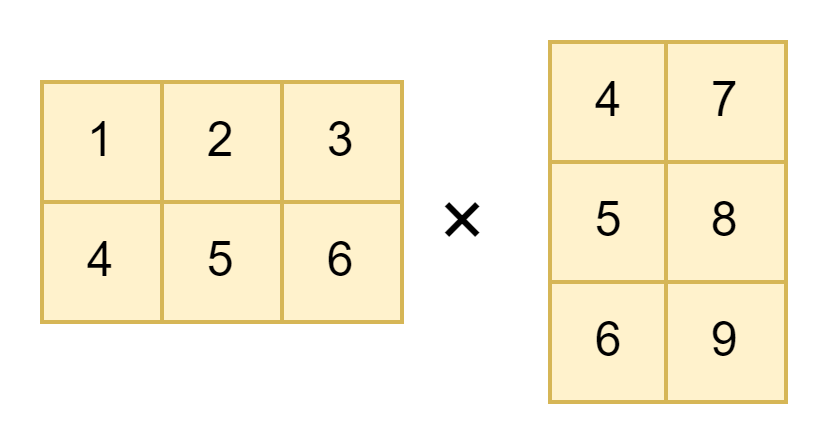
axes=2(均展平为一维向量再做向量内积)
import tensorflow as tf
a = tf.constant([[1,2,3],[4,5,6]], dtype=tf.float32)
b = tf.constant([[4,5,6],[7,8,9]], dtype=tf.float32)
z = tf.tensordot(a, b, axes=2)
out:
<tf.Tensor: shape=(), dtype=float32, numpy=154.0>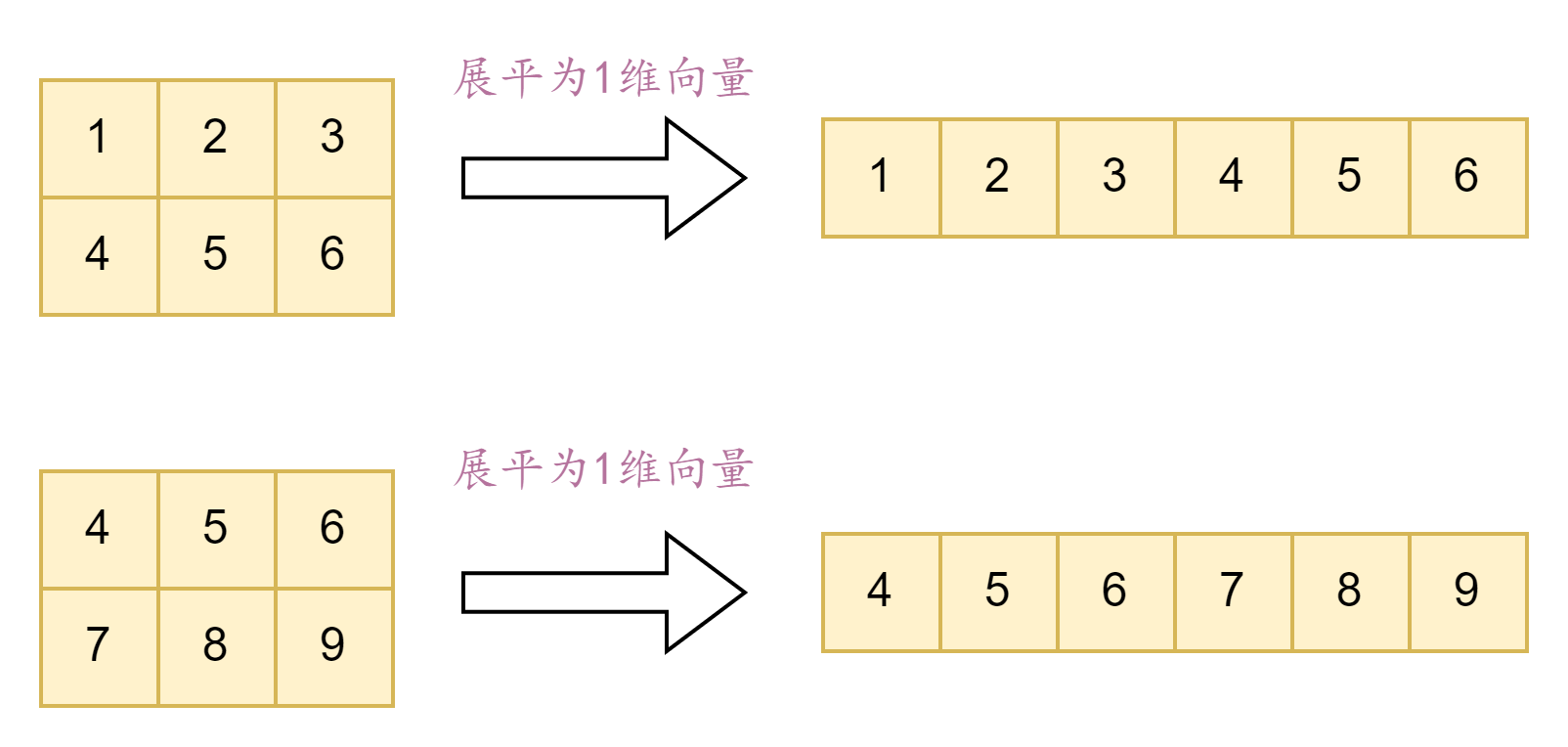
axes=[0,0](两个矩阵的列向量对应元素依次相乘再相加)
import tensorflow as tf
a = tf.constant([[1,2,3],[4,5,6]], dtype=tf.float32)
b = tf.constant([[4,5,6],[7,8,9]], dtype=tf.float32)
z = tf.tensordot(a, b, axes=[0,0])
out:
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[32., 37., 42.],
[43., 50., 57.],
[54., 63., 72.]], dtype=float32)>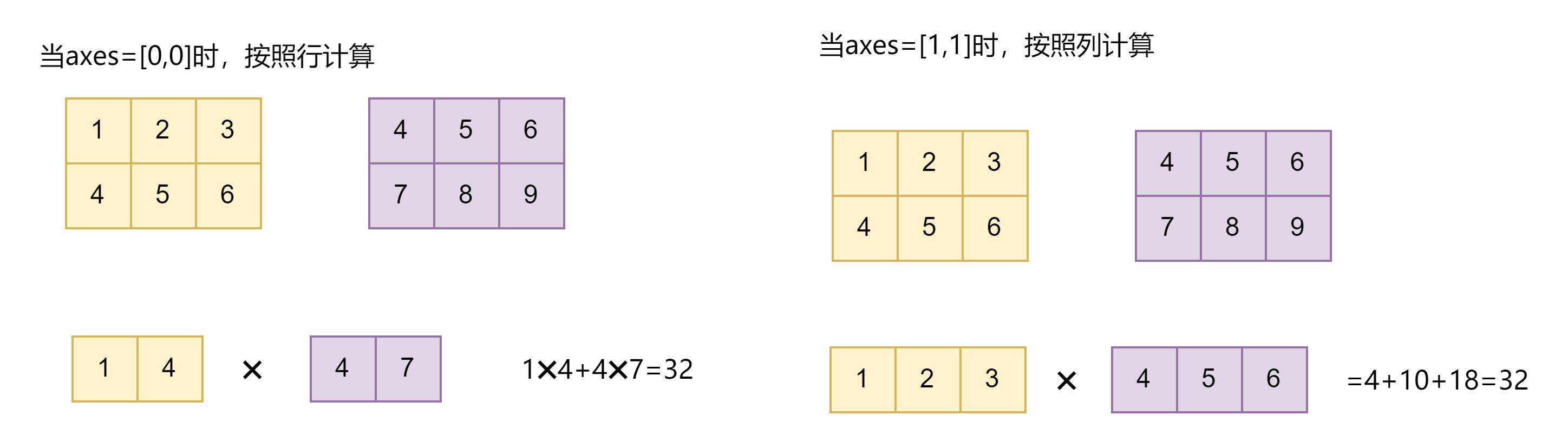
axes=[1,1](无需转置,直接等价于矩阵乘法)
import tensorflow as tf
a = tf.constant([[1,2,3],[4,5,6]], dtype=tf.float32)
b = tf.constant([[4,5,6],[7,8,9]], dtype=tf.float32)
z = tf.tensordot(a, b, axes=[1,1])
out:
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[ 32., 50.],
[ 77., 122.]], dtype=float32)>等价于 tf.matmul(a, tf.transpose(b))
三维(前二维后三维)
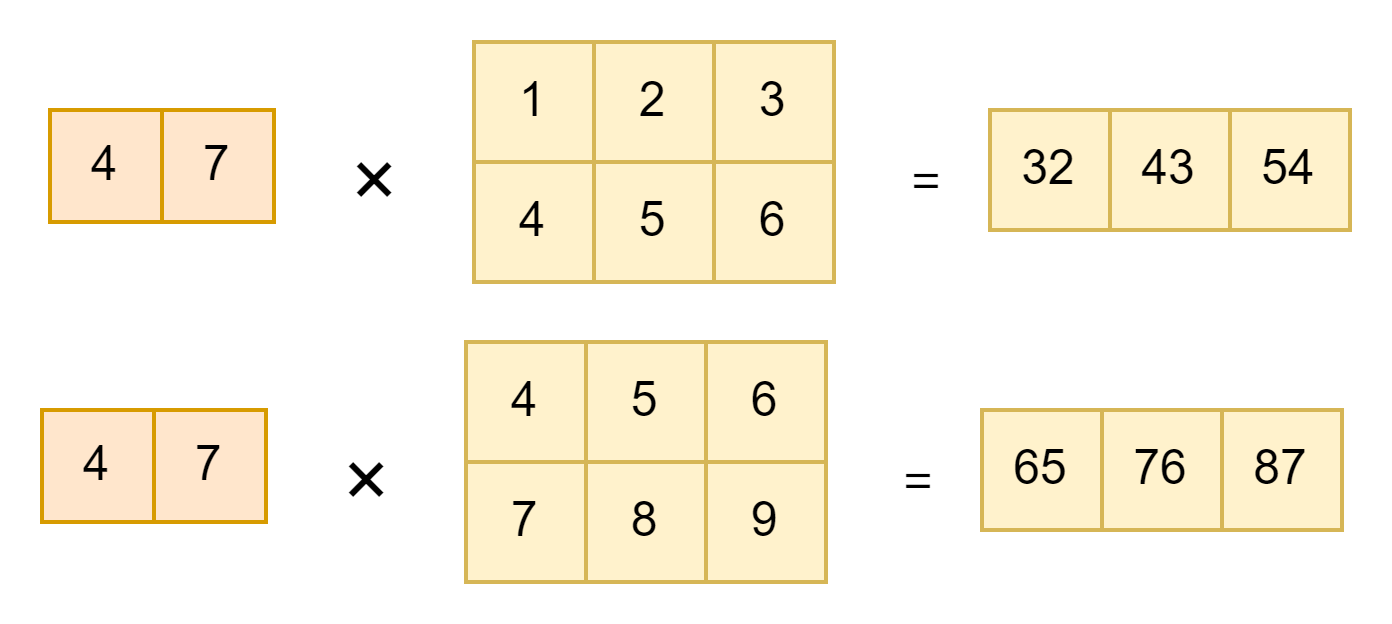
axes=1(二维的每一行依次乘以三维的每一组,结果为3维)
假设给定的a是二维向量,b是三维向量,那么就是a的最后一个维度和b的第一个维度进行计算
import tensorflow as tf
a = tf.constant([[4,7],[5,8],[6,9]], dtype=tf.float32) # (3,2)
b = tf.constant([[[1,2,3],[4,5,6]],[[4,5,6],[7,8,9]]], dtype=tf.float32) # (2,2,3)
z = tf.tensordot(a, b, axes=1)
out:
<tf.Tensor: shape=(3, 2, 3), dtype=float32, numpy=
array([[[ 32., 43., 54.],
[ 65., 76., 87.]],
[[ 37., 50., 63.],
[ 76., 89., 102.]],
[[ 42., 57., 72.],
[ 87., 102., 117.]]], dtype=float32)>计算过程以(4,7)为例,其他类似:
axes=2(需要对三维转置才不会报错)
假设给定的a是二维向量,b是三维向量,直接 tf.tensordot(a, b, axes=2) 会报错
import tensorflow as tf
a = tf.constant([[4,7],[5,8],[6,9]], dtype=tf.float32)
b = tf.constant([[[1,2,3],[4,5,6]],[[4,5,6],[7,8,9]]], dtype=tf.float32)
z = tf.tensordot(a, b, axes=2)
out:报错
InvalidArgumentError: Matrix size-incompatible: In[0]: [1,6], In[1]: [4,3] [Op:MatMul]把b进行转置后才不会报错,即 tf.tensordot(a, tf.transpose(b), axes=2)
import tensorflow as tf
a = tf.constant([[4,7],[5,8],[6,9]], dtype=tf.float32)
b = tf.constant([[[1,2,3],[4,5,6]],[[4,5,6],[7,8,9]]], dtype=tf.float32)
z = tf.tensordot(a, tf.transpose(b), axes=2)
out:
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([154., 271.], dtype=float32)>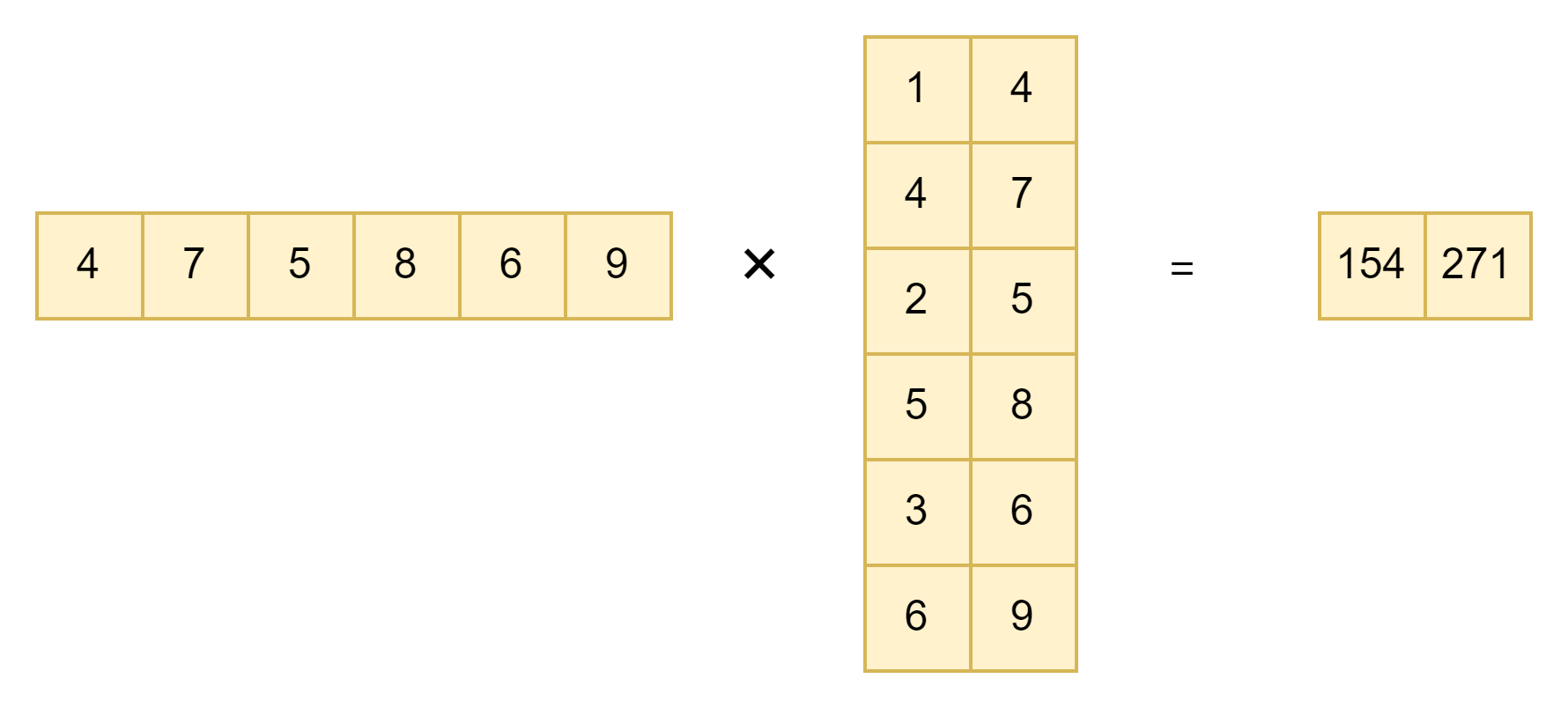
三维(前三维后二维)
tensorflow中多维tensor运算(tf.multiply, tf.matmul, tf.tensordot)_tensorflow tensor 多维 不同维度索引-CSDN博客
import tensorflow as tf
a = tf.constant([1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24], shape=[2, 3, 4])
b = tf.constant([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], shape=[4, 3])
c = tf.tensordot(a, b, axes=1)
# 同 tf.matmul,普通矩阵相乘
# shape: [2, 3, 4] x [4, 3] = [2, 3, 3]
d = tf.tensordot(a, b, axes=2)
# 对a的后2个轴的数据进行Flatten,即a的shape变成 [2, 3X4] = [2, 12];
# 对b的前2个轴的数据进行Flatten,即b的shape变成[12]
# shape: [2, 12] x [12] = [2,]
e = tf.tensordot(a, b, axes=([1,2], [0,1]))
# 分别指定两个轴,此结果同 tf.tensordot(a, b, axes=2)
# 对a的后2个轴(索引1,2)的数据进行Flatten,即a的shape变成 [2, 3X4] = [2, 12];
# 对b的前2个轴(索引0,1)的数据进行Flatten,即b的shape变成[12],展开结果[1,2,3,4,5,6,7,8,9,10,11,12]
# shape: [2, 12] x [12] = [2,]
f = tf.tensordot(a, b, axes=([1,2], [1,0]))
# 分别指定两个轴
# 对a的后2个轴(索引1,2)的数据进行Flatten,即a的shape变成 [2, 3X4] = [2, 12];
# 对b的前2个轴(索引1,0)的数据进行Flatten,即b的shape变成[12]
# 轴的顺序不同,展开方式不同,展开结果[1,4,7,10,2,5,8,11,3,6,9,12]
# shape: [2, 12] x [12] = [2,]
g = tf.tensordot(a, b, axes=([1], [1]))
# 指定任何轴,指定的轴形状一致
# shape: [2, 3, 4] x [4, 3] = [2, 4, 4] (消去(3,3))再高维就不写了,看 tensorflow和numpy库中tensordot详解-CSDN博客 慢慢悟吧...
通用模板 .einsum()
einsum在numpy中实现为np.einsum,在PyTorch中实现为torch.einsum,在TensorFlow中实现为tf.einsum,函数格式均为 einsum(equation, inputs),其中 equation是表示规则约定的字符串,inputs则是张量序列(在numpy和TensorFlow中是变长参数列表,在PyTorch中是列表)
详细的讲解看 tf.einsum—爱因斯坦求和约定-CSDN博客 就够了,本文在这里主要是举几个例子方便需要时查看
1、矩阵转置(transpose)
tf.einsum('ij->ji', a) 等价于 tf.transpose(a, [1, 0]) 或 tf.transpose(a)import tensorflow as tf
a = tf.constant([[0, 1, 2], [3, 4, 5]], dtype=tf.float32)
input:
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0., 1., 2.],
[3., 4., 5.]], dtype=float32)>
out:
<tf.Tensor: shape=(3, 2), dtype=float32, numpy=
array([[0., 3.],
[1., 4.],
[2., 5.]], dtype=float32)>2、求和
tf.einsum('ij->', a) 等价于 tf.reduce_sum(a)import tensorflow as tf
a = tf.constant([[0, 1, 2], [3, 4, 5]], dtype=tf.float32)
input:
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0., 1., 2.],
[3., 4., 5.]], dtype=float32)>
out:
<tf.Tensor: shape=(), dtype=float32, numpy=15.0>3、列求和
tf.einsum('ij->j', a) 等价于 tf.reduce_sum(a, axis=0)import tensorflow as tf
a = tf.constant([[0, 1, 2], [3, 4, 5]], dtype=tf.float32)
input:
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0., 1., 2.],
[3., 4., 5.]], dtype=float32)>
out:
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([3., 5., 7.], dtype=float32)>4、行求和
tf.einsum('ij->i', a) 等价于 tf.reduce_sum(a, axis=1)import tensorflow as tf
a = tf.constant([[0, 1, 2], [3, 4, 5]], dtype=tf.float32)
input:
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0., 1., 2.],
[3., 4., 5.]], dtype=float32)>
out:
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([ 3., 12.], dtype=float32)>5、矩阵-向量相乘
tf.einsum('ik,k->i', a, b) 等价于 tf.linalg.matvec(a, b)import tensorflow as tf
a = tf.constant([[1, 2, 3], [4, 5, 6]], dtype=tf.float32)
b = tf.constant([0, 1, 2], dtype=tf.float32)
input:
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[1., 2., 3.],
[4., 5., 6.]], dtype=float32)>
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([0., 1., 2.], dtype=float32)>
out:
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([ 8., 17.], dtype=float32)>6、矩阵-矩阵相乘
tf.einsum('ik,kj->ij', a, b) 等价于 tf.matmul(a, b)import tensorflow as tf
a = tf.reshape(tf.range(6), (2, 3))
b = tf.reshape(tf.range(15), (3, 5))
input:
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[0, 1, 2],
[3, 4, 5]])>
<tf.Tensor: shape=(3, 5), dtype=int32, numpy=
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])>
out:
<tf.Tensor: shape=(2, 5), dtype=int32, numpy=
array([[ 25, 28, 31, 34, 37],
[ 70, 82, 94, 106, 118]])>7、点积(Dot product)
tf.einsum('i,i->', a, b)
等价于 tf.tensordot(a, b, axes=1) 或 tf.tensordot(a, b, axes=[0, 0])
也等价于 tf.reduce_sum(tf.multiply(a, b))import tensorflow as tf
a = tf.constant([0, 1, 2], dtype=tf.float32)
b = tf.constant([3, 4, 5], dtype=tf.float32)
input:
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([0., 1., 2.], dtype=float32)>
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([3., 4., 5.], dtype=float32)>
out:
<tf.Tensor: shape=(), dtype=float32, numpy=14.0>8、哈达玛积(逐元素相乘)
tf.einsum('ij,ij->ij', a, b) 等价于 tf.multiply(a, b)import tensorflow as tf
a = tf.reshape(tf.range(6), (2, 3))
b = tf.reshape(tf.range(6, 12), (2, 3))
input:
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[0, 1, 2],
[3, 4, 5]])>
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[ 6, 7, 8],
[ 9, 10, 11]])>
out:
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[ 0, 7, 16],
[27, 40, 55]])>9、外积(Outer product)
tf.einsum('i,j->ij', a, b) 等价于 tf.tensordot(a, b, axes=0)import tensorflow as tf
a = tf.constant([0, 1, 2], dtype=tf.float32)
b = tf.constant([3, 4, 5, 6], dtype=tf.float32)
input:
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([0., 1., 2.], dtype=float32)>
<tf.Tensor: shape=(4,), dtype=float32, numpy=array([3., 4., 5., 6.], dtype=float32)>
out:
<tf.Tensor: shape=(3, 4), dtype=float32, numpy=
array([[ 0., 0., 0., 0.],
[ 3., 4., 5., 6.],
[ 6., 8., 10., 12.]], dtype=float32)>10、batch矩阵相乘
tf.einsum('ijk,ikl->ijl', a, b) 等价于 tf.matmul(a, b)import tensorflow as tf
a = tf.random.normal((3, 2, 5))
b = tf.random.normal((3, 5, 3))
out:
<tf.Tensor: shape=(3, 2, 3), dtype=float32, numpy=
array([[[-0.13089229, 0.2916508 , 1.7230573 ],
[-1.2323114 , -0.67534804, -1.7209171 ]],
[[-0.07423151, 3.9215555 , -4.080279 ],
[-0.05451638, -0.46641332, 1.6494975 ]],
[[-0.23555136, -0.76107085, -1.1223997 ],
[ 0.282961 , -0.37376913, 1.3674018 ]]], dtype=float32)>















 2818
2818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











