







一、JMM内存交互层面实现
volatile修饰的变量的read、load、use操作和assign、store、write必须是连续的,即修改后必须立即同步回主内存,使用时必须从主内存刷新,由此保证volatile变量操作对多线程的可见性。
二、Volatile在hotspot的实现
在JVM层面,使用storeLoader内存屏障保证可见性。
我们知道Java中有两种解释器:字节码解释器和模板解释器。接下来我们从这两种解释器层面来看看:
字节码解释器实现
JVM中的字节码解释器(bytecodeInterpreter),用C++实现了JVM指令,其优点是实现相对简单且容易理解,缺点是执行慢。
我们来看看hotspot中volatile的实现,实现代码在bytecodeInterpreter.cpp文件中。
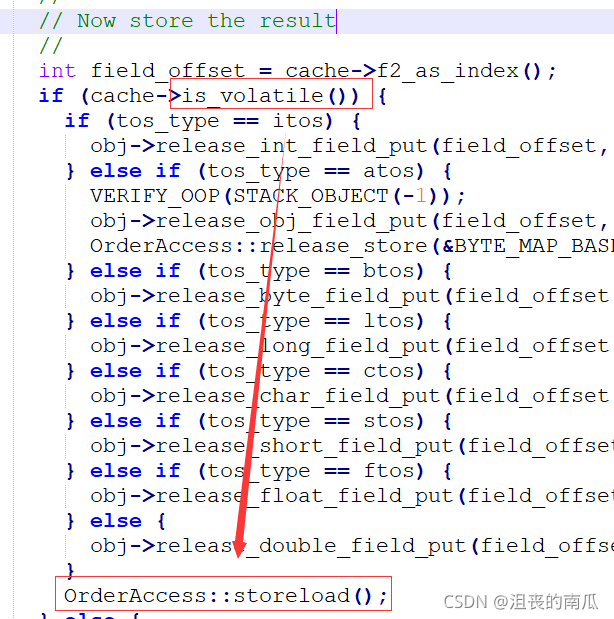
这里会使用 cache->is_volatile判断某个属性是否是volatile修饰的,如果是的话还会继续判断属性的类型,是否是obj, byte, long, char, short, float, double等。
最终都会调用OrderAccess::storeload(),也就是会为这些加了volatile变量的属性添加storeload内存屏障!
模板解释器实现
模板解释器(templateInterpreter),其对每个指令都写了一段对应的汇编代码,启动时将每个指令与对应汇编代码入口绑定,可以说是效率做到了极致。
templateTable_x86_64.cpp
void TemplateTable::volatile_barrier(Assembler::Membar_mask_bits
order_constraint) {
// Helper function to insert a is-volatile test and memory barrier
// 如果os是多核处理器,会调用membar方法
if (os::is_MP()) { // Not needed on single CPU
__ membar(order_constraint);
}
}
// 负责执行putfield或putstatic指令
void TemplateTable::putfield_or_static(int byte_no, bool is_static, RewriteControl rc) {
// ...
// Check for volatile store
__ testl(rdx, rdx);
__ jcc(Assembler::zero, notVolatile);
putfield_or_static_helper(byte_no, is_static, rc, obj, off, flags);
volatile_barrier(Assembler::Membar_mask_bits(Assembler::StoreLoad |
Assembler::StoreStore));
__ jmp(Done);
__ bind(notVolatile);
putfield_or_static_helper(byte_no, is_static, rc, obj, off, flags);
__ bind(Done);
}
membar方法在assembler_x86.hpp文件中:
// Serializes memory and blows flags
void membar(Membar_mask_bits order_constraint) {
// We only have to handle StoreLoad
// x86平台只需要处理StoreLoad内存屏障
if (order_constraint & StoreLoad) {
int offset = -VM_Version::L1_line_size();
if (offset < -128) {
offset = -128;
}
// 下面这两句插入了一条lock前缀指令: lock addl $0, $0(%rsp)
lock(); // lock前缀指令
addl(Address(rsp, offset), 0); // addl $0, $0(%rsp)
}
}
可以看到,在汇编层面,最终是调用了 lock addl $0, $0(%rsp) Lock前缀来实现和内存屏障一样的功能。
三、Volatile在linux系统x86中的实现
orderAccess_linux_x86.inline.hpp
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::fence() {
// 如果OS是多核处理器
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
// 在X86处理器中lock前缀的性能要优于内存屏障,所以x86处理器中利用lock实现类似内存屏障的效果。
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
X86 linux处理上调用fence()方法,判断处理器是否是多核,如果是则添加lock; addl $0,0(%%rsp) 。即添加Lock前缀指令!因为在X86处理器上,认为Lock指令的性能要优于内存屏障,所以使用的是Lock指令,而并不是系统级别的内存屏障实现。注意:内存屏障和Lock前缀具有相同的作用,都可以使得更新后的值立即刷回主从,并使得其他缓存中的数据副本失效!
lock前缀指令的作用
- 确保后续指令执行的原子性。在Pentium及之前的处理器中,带有lock前缀的指令在执行期间会锁住总线,使得其它处理器暂时无法通过总线访问内存,很显然,这个开销很大。在新的处理器中,Intel使用缓存锁定来保证指令执行的原子性,缓存锁定将大大降低lock前缀指令的执行开销。
- LOCK前缀指令具有类似于内存屏障的功能,禁止该指令与前面和后面的读写指令重排序。
- LOCK前缀指令会 等待它之前所有的指令完成、并且所有缓冲的写操作写回内存(也就是将store buffer中的内容写入内存)之后才开始执行,并且根据缓存一致性协议,刷新store buffer的操作会导致其他cache中的副本失效。
四、汇编层面volatile的实现
添加下面的jvm参数可以查看汇编指令:
-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp

可以看到volatile变量修饰的属性前是天际了lock前缀的,这也验证了上面的思想。
五、从硬件层面分析Lock前缀指令
《64-ia-32-architectures-software-developer-vol-3a-part-1-manual.pdf》中有如下描述:
The 32-bit IA-32 processors support locked atomic operations on locations in system memory. These operations are typically used to manage shared data structures (such as semaphores, segment descriptors, system segments, or page tables) in which two or more processors may try simultaneously to modify the same field or flag. The processor uses three interdependent mechanisms for carrying out locked atomic operations:
• Guaranteed atomic operations
• Bus locking, using the LOCK# signal and the LOCK instruction prefix
• Cache coherency protocols that ensure that atomic operations can be carried out on cached data structures (cache lock); this mechanism is present in the Pentium 4, Intel Xeon, and P6 family processors
32位的IA-32处理器支持对系统内存中的位置进行锁定的原子操作。这些操作通常用于管理共享的数据结构(如信号量、段描述符、系统段或页表),在这些结构中,两个或多个处理器可能同时试图修改相同的字段或标志。处理器使用三种相互依赖的机制来执行锁定的原子操作:
- 有保证的原子操作
- 总线锁定,使用LOCK#信号和LOCK指令前缀
- 缓存一致性协议,确保原子操作可以在缓存的数据结构上执行(缓存锁);这种机制出现在Pentium 4、Intel Xeon和P6系列处理器中
六** 总结Java中可见性是如何保证的
归类为两种方式:
1、JVM层面:调用storeFence内存屏障(storeLoader);硬件层面:X86处理器下是使用Lock前缀替换内存屏障实现相同功能;
2、上下文切换(Thread.yield())















 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









