







什么是 DQN
什么是 DQN - 强化学习 Reinforcement Learning | 莫烦Python
why
Q-Learning存在的问题
QLearning表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值.
也就是说,现在要使用神经网络替换了原有的表格储存
我们可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值.
how
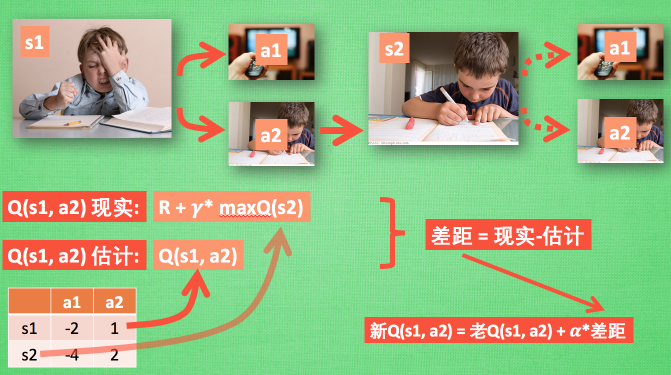
Q 现实: a1, a2,an 正确的Q值
Q 估计:通过 NN 预测出Q(s2, a1) 和 Q(s2,a2) 的值
what
https://yulizi123.github.io/static/results/ML-intro/q3.png
得到新的Q值
两大因素支撑着 DQN 使得它变得无比强大. 这两大因素就是 Experience replay 和 Fixed Q-targets.
Experience replay:利用off-policy的特点,回放过去学习的内容,同时打乱经历之间的相关性, 也使得神经网络更新更有效率
fixed Q-targets:我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计的神经网络具备最新的参数
DQN 算法更新 (Tensorflow)
DQN 算法更新 (Tensorflow) - 强化学习 Reinforcement Learning | 莫烦Python
神经网络计算 Q 值
- 记忆库 (用于重复学习)
- 暂时冻结
q_target参数 (切断相关性)
和Q-Learning一样有action, observation, reward, done 不细说了
Experience replay的体现:记忆库的设计
初始存储记忆库,先不学习
# 控制学习起始时间和频率 (先累积一些记忆再开始学习)
if (step > 200) and (step % 5 == 0):
RL.learn()设置一个
# DQN 存储记忆
RL.store_transition(observation, action, reward, observation_)DQN 神经网络 (Tensorflow)
DQN 神经网络 (Tensorflow) - 强化学习 Reinforcement Learning | 莫烦Python
fixed Q-targets的体现
build_net
在eval_net中包含了target_network的信息
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target')
# 用来接收 q_target 的值, 这个之后会通过计算得到在eval_net计算误差和梯度
with tf.variable_scope('loss'): # 求误差
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'): # 梯度下降
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)DQN 思维决策 (Tensorflow)
注意要包含n_actions和n_features,memory_size等信息
pandas引用和memory有关系
Store_transition:
不断记录不断索引
choose_action 需要增加observation的维数,记得一定比例的随机选择
replace要将参数调用
这里蛮重要的——
在 DeepQNetwork 中, 是如何学习, 更新参数的. 这里涉及了 target_net 和 eval_net 的交互使用.
q_next, q_eval 包含所有 action 的值,
而我们需要的只是已经选择好的 action 的值, 其他的并不需要.
所以我们将其他的 action 值全变成 0, 将用到的 action 误差值 反向传递回去, 作为更新凭据.
所有为 0 的 action 值是当时没有选择的 action, 之前有选择的 action 才有不为0的值.
也就是说(q_target - q_eval) 只有在更改过的地方才是非0的















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}