







1、PSPNet原代码地址: link.
2、Resnet嵌入CBAM代码参考: link.
3、注意力机制原理参考: link.
起初直接按照Resnet嵌入CBAM代码进行修改,由于增加机制后的resnet增加了预训练的参数,因此报错:
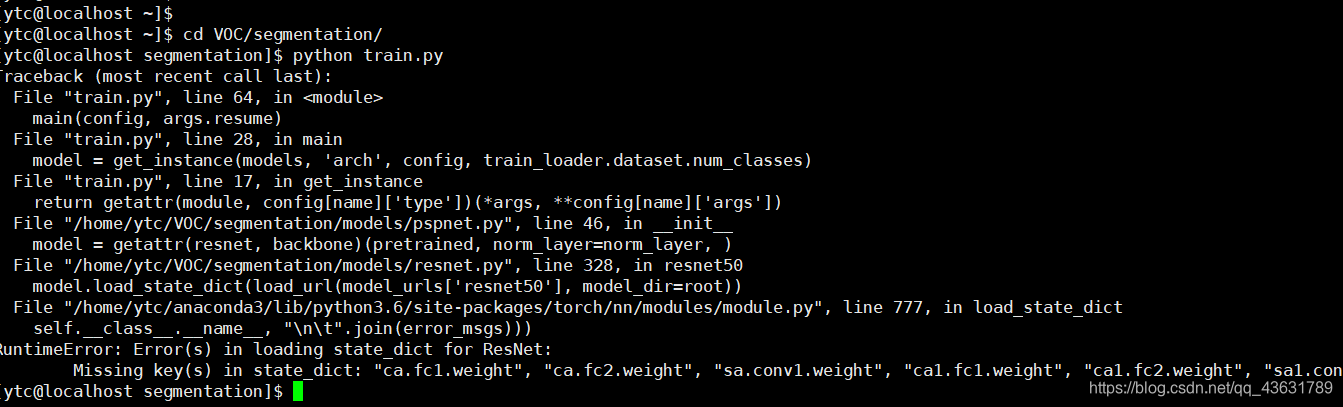
百度搜了一下解决方案:
需要修改预训练的参数,但网上的代码多是用于解决原预训练参数多于修改后的模型,例如:(原博客地址一时翻不出来了,如有找到了的麻烦告诉一下,侵删)

但我们的实际情况是原预训练参数比修改后的参数少,因此按照上面的方法修改依旧报错:
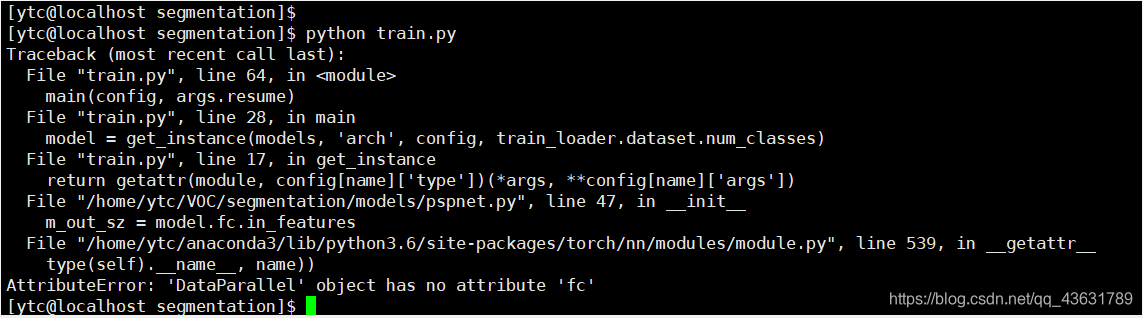
最后找到了适合增加预训练参数的代码(原博客地址一时翻不出来了,如有找到了的麻烦告诉一下,侵删):
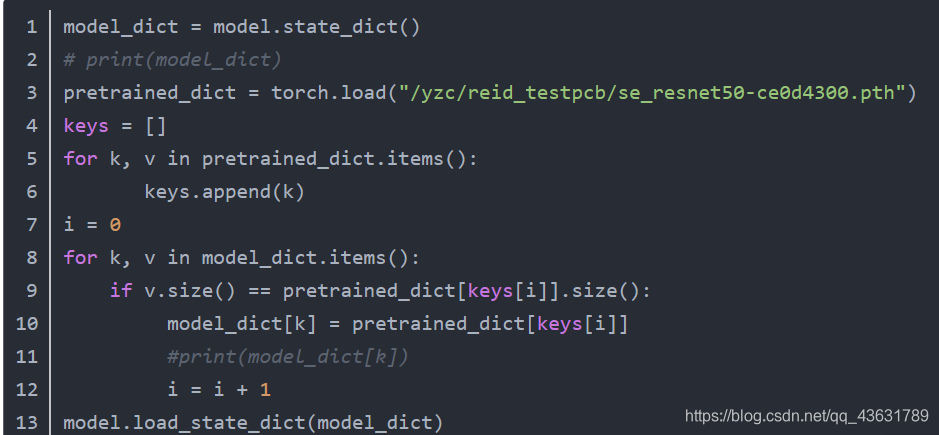
按照上述代码思路对Resnet.py中的预训练参数部分做对应修改:
model_dict = model.state_dict()
pretrained_dict = model_zoo.load_url(model_urls['resnet50'])
keys = []
for k, v in pretrained_dict.items():
keys.append(k)
i=0
for k, v in model_dict.items():
if v.size() == pretrained_dict[keys[i]].size():
model_dict[k] = pretrained_dict[keys[i]]
i = i + 1
model.load_state_dict(model_dict)
此时,程序可以正常运行但loss值为nan
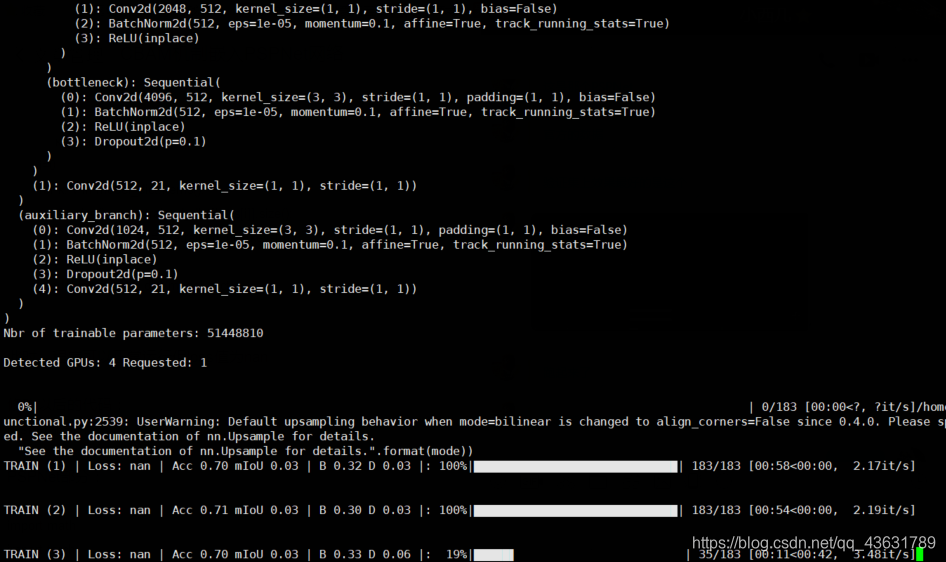
一开始发现loss不正常,怀疑是优化器的问题,尝试了Adam、RMS,adadelt之类的优化器以后,仍然有这个问题。然后怀疑可能是学习率太高,导致无法收敛,尝试降低学习率从0.01到0.001,大概能撑100个batch,降低了学习率以后发现只能延缓这个问题,最后还是会出现前几个batch的问题。
所以怀疑是网络结构不合理,然后看了两个attention,感觉没啥毛病,确实是attention机制,按说不该造成网络结构不合理的问题,然后经过检查,发现问题出在那个 self.initial ,每次都是因为它的输出变成了nan,然后分析了一下发现
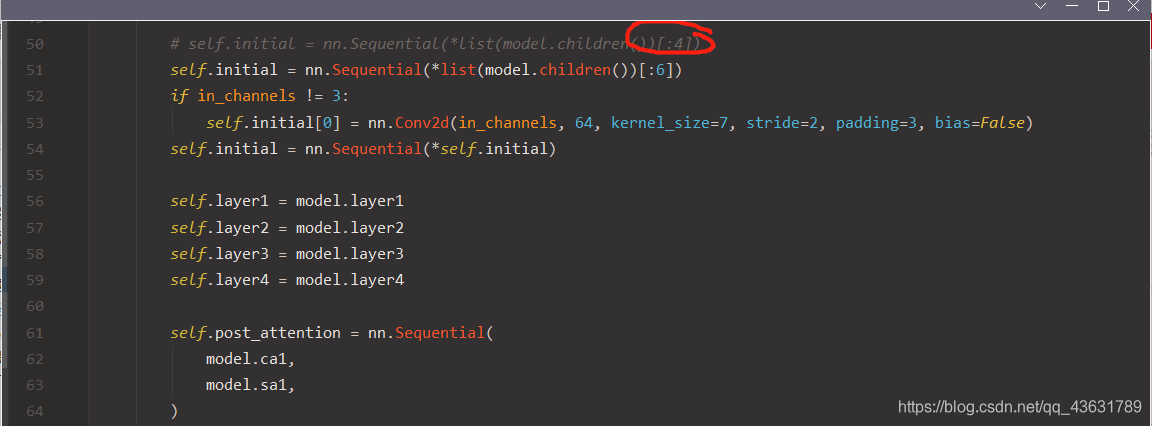
这里原本写的是4,然后这个4代表着ResNet中的
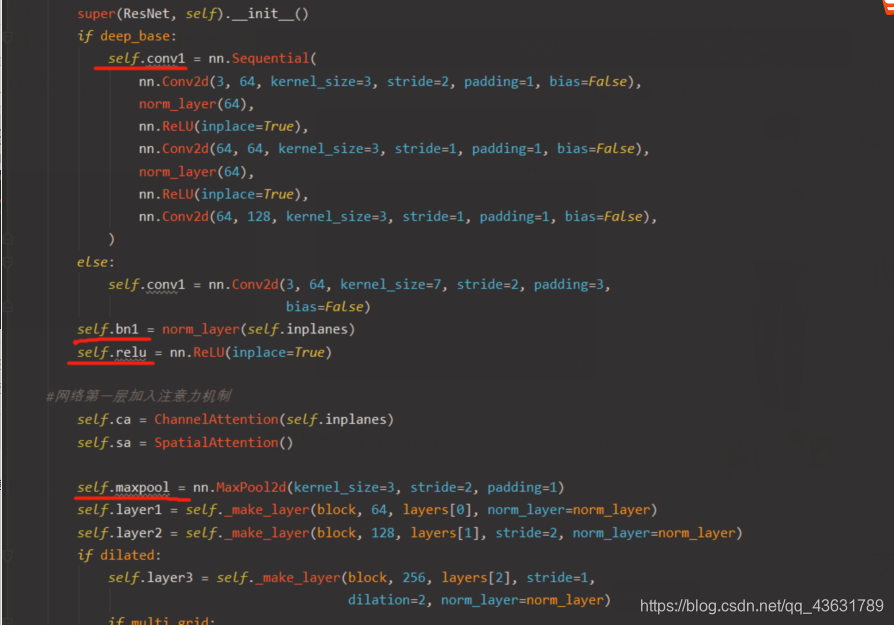
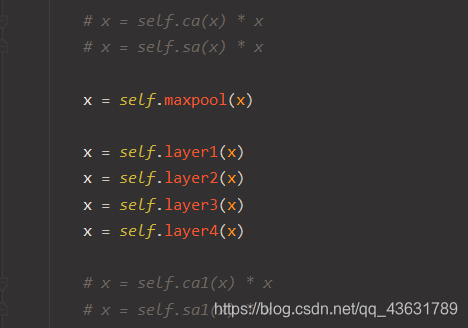
这四个东西。然后检查了self.initial的结构,发现变成了 conv1, bn1, relu, ca 这四个东西。所以把那个4改成了6,这样就把ResNet中本该有的东西都包含进来了,也就是conv1, bn1, relu, ca, sa, maxpool。跑了一下直接报了维度错误,检查了一下发现原本 initial 的输出应该是 batch * channel * 啥 * 啥,这个channel是128,然而这样改完之后变成了1。于是乎找了一下和那个知乎的区别,发现问题出在forward里面,它改了ResNet的forward的逻辑,也就是加了被注释掉的这四行
然而这样在PSPNet用ResNet的时候,并没有引入这个计算逻辑,所以我把这 attention * x 的操作移植到了attention机制内部,这样在PSPNet用的时候就会保留这个计算逻辑,修改如下:
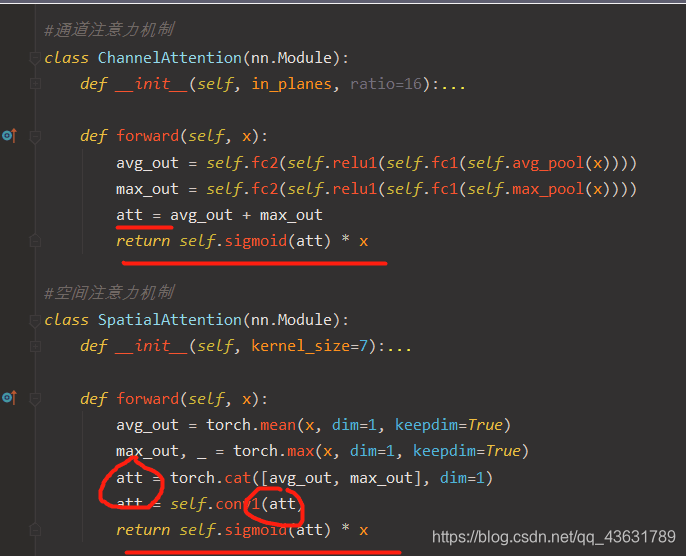
之后程序就可以正常运行了。
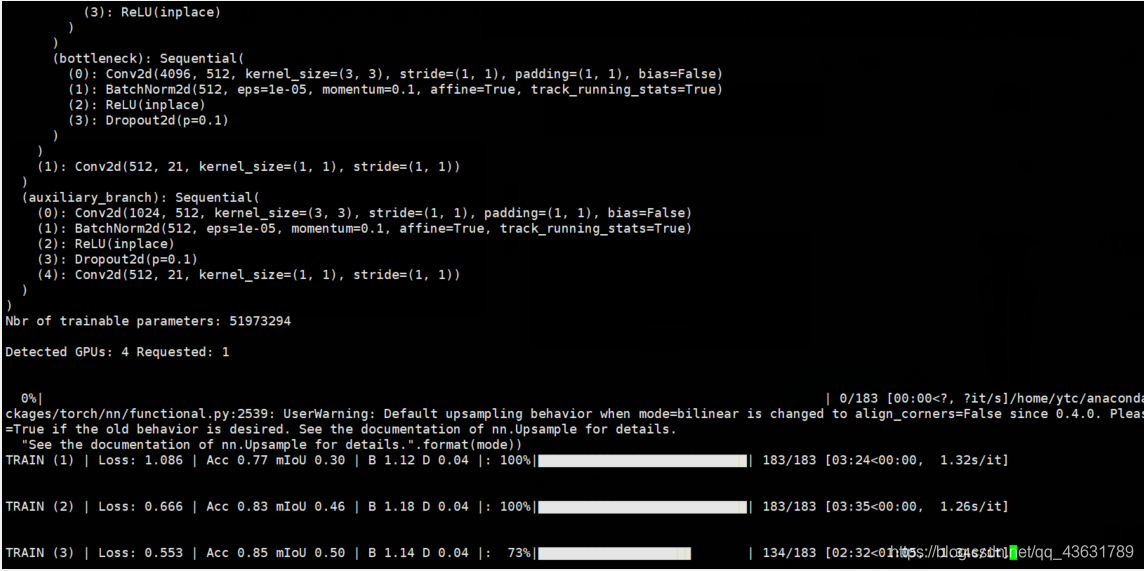
修改以后的代码:
PSPNet部分:
import math
import torch
import torch.nn.functional as F
from torch import nn
from models import resnet
from torchvision import models
from base import BaseModel
from utils.helpers import initialize_weights, set_trainable
from itertools import chain
class _PSPModule(nn.Module):
def __init__(self, in_channels, bin_sizes, norm_layer):
super(_PSPModule, self).__init__()
out_channels = in_channels // len(bin_sizes)
self.stages = nn.ModuleList([self._make_stages(in_channels, out_channels, b_s, norm_layer)
for b_s in bin_sizes])
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels+(out_channels * len(bin_sizes)), out_channels,
kernel_size=3, padding=1, bias=False),
norm_layer(out_channels),
nn.ReLU(inplace=True),
nn.Dropout2d(0.1)
)
def _make_stages(self, in_channels, out_channels, bin_sz, norm_layer):
prior = nn.AdaptiveAvgPool2d(output_size=bin_sz)
conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
bn = norm_layer(out_channels)
relu = nn.ReLU(inplace=True)
return nn.Sequential(prior, conv, bn, relu)
def forward(self, features):
h, w = features.size()[2], features.size()[3]
pyramids = [features]
pyramids.extend([F.interpolate(stage(features), size=(h, w), mode='bilinear',
align_corners=True) for stage in self.stages])
output = self.bottleneck(torch.cat(pyramids, dim=1))
return output
class PSPNet(BaseModel):
def __init__(self, num_classes, in_channels=3, backbone='resnet152', pretrained=True, use_aux=True, freeze_bn=False, freeze_backbone=False):
super(PSPNet, self).__init__()
# TODO: Use synch batchnorm
norm_layer = nn.BatchNorm2d
model = getattr(resnet, backbone)(pretrained, norm_layer=norm_layer, )
m_out_sz = model.fc.in_features
self.use_aux = use_aux
# self.initial = nn.Sequential(*list(model.children())[:4])
self.initial = nn.Sequential(*list(model.children())[:6])
if in_channels != 3:
self.initial[0] = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.initial = nn.Sequential(*self.initial)
self.layer1 = model.layer1
self.layer2 = model.layer2
self.layer3 = model.layer3
self.layer4 = model.layer4
self.post_attention = nn.Sequential(
model.ca1,
model.sa1,
)
self.master_branch = nn.Sequential(
_PSPModule(m_out_sz, bin_sizes=[1, 2, 3, 6], norm_layer=norm_layer),
nn.Conv2d(m_out_sz//4, num_classes, kernel_size=1)
)
self.auxiliary_branch = nn.Sequential(
nn.Conv2d(m_out_sz//2, m_out_sz//4, kernel_size=3, padding=1, bias=False),
norm_layer(m_out_sz//4),
nn.ReLU(inplace=True),
nn.Dropout2d(0.1),
nn.Conv2d(m_out_sz//4, num_classes, kernel_size=1)
)
initialize_weights(self.master_branch, self.auxiliary_branch)
if freeze_bn: self.freeze_bn()
if freeze_backbone:
set_trainable([self.initial, self.layer1, self.layer2, self.layer3, self.layer4], False)
def forward(self, x):
input_size = (x.size()[2], x.size()[3])
x = self.initial(x) # [8, 128, 1, 1]
x = self.layer1(x) # [8, 256, 1, 1]
x = self.layer2(x) # [8, 512, 1, 1]
x_aux = self.layer3(x) # [8, 1024, 1, 1]
x = self.layer4(x_aux) # [8, 2048, 1, 1]
output = self.master_branch(x)
output = F.interpolate(output, size=input_size, mode='bilinear')
output = output[:, :, :input_size[0], :input_size[1]]
if self.training and self.use_aux:
aux = self.auxiliary_branch(x_aux)
aux = F.interpolate(aux, size=input_size, mode='bilinear')
aux = aux[:, :, :input_size[0], :input_size[1]]
return output, aux
return output
def get_backbone_params(self):
return chain(self.initial.parameters(), self.layer1.parameters(), self.layer2.parameters(),
self.layer3.parameters(), self.layer4.parameters())
def get_decoder_params(self):
return chain(self.master_branch.parameters(), self.auxiliary_branch.parameters())
def freeze_bn(self):
for module in self.modules():
if isinstance(module, nn.BatchNorm2d): module.eval()
## PSP with dense net as the backbone
class PSPDenseNet(BaseModel):
def __init__(self, num_classes, in_channels=3, backbone='densenet201', pretrained=True, use_aux=True, freeze_bn=False, **_):
super(PSPDenseNet, self).__init__()
self.use_aux = use_aux
model = getattr(models, backbone)(pretrained)
m_out_sz = model.classifier.in_features
aux_out_sz = model.features.transition3.conv.out_channels
if not pretrained or in_channels != 3:
# If we're training from scratch, better to use 3x3 convs
block0 = [nn.Conv2d(in_channels, 64, 3, stride=2, bias=False), nn.BatchNorm2d(64), nn.ReLU(inplace=True)]
block0.extend(
[nn.Conv2d(64, 64, 3, bias=False), nn.BatchNorm2d(64), nn.ReLU(inplace=True)] * 2
)
self.block0 = nn.Sequential(
*block0,
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
initialize_weights(self.block0)
else:
self.block0 = nn.Sequential(*list(model.features.children())[:4])
self.block1 = model.features.denseblock1
self.block2 = model.features.denseblock2
self.block3 = model.features.denseblock3
self.block4 = model.features.denseblock4
self.transition1 = model.features.transition1
# No pooling
self.transition2 = nn.Sequential(
*list(model.features.transition2.children())[:-1])
self.transition3 = nn.Sequential(
*list(model.features.transition3.children())[:-1])
for n, m in self.block3.named_modules():
if 'conv2' in n:
m.dilation, m.padding = (2,2), (2,2)
for n, m in self.block4.named_modules():
if 'conv2' in n:
m.dilation, m.padding = (4,4), (4,4)
self.master_branch = nn.Sequential(
_PSPModule(m_out_sz, bin_sizes=[1, 2, 3, 6], norm_layer=nn.BatchNorm2d),
nn.Conv2d(m_out_sz//4, num_classes, kernel_size=1)
)
self.auxiliary_branch = nn.Sequential(
nn.Conv2d(aux_out_sz, m_out_sz//4, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(m_out_sz//4),
nn.ReLU(inplace=True),
nn.Dropout2d(0.1),
nn.Conv2d(m_out_sz//4, num_classes, kernel_size=1)
)
initialize_weights(self.master_branch, self.auxiliary_branch)
if freeze_bn: self.freeze_bn()
def forward(self, x):
input_size = (x.size()[2], x.size()[3])
x = self.block0(x)
x = self.block1(x)
x = self.transition1(x)
x = self.block2(x)
x = self.transition2(x)
x = self.block3(x)
x_aux = self.transition3(x)
x = self.block4(x_aux)
output = self.master_branch(x)
output = F.interpolate(output, size=input_size, mode='bilinear')
if self.training and self.use_aux:
aux = self.auxiliary_branch(x_aux)
aux = F.interpolate(aux, size=input_size, mode='bilinear')
return output, aux
return output
def get_backbone_params(self):
return chain(self.block0.parameters(), self.block1.parameters(), self.block2.parameters(),
self.block3.parameters(), self.transition1.parameters(), self.transition2.parameters(),
self.transition3.parameters())
def get_decoder_params(self):
return chain(self.master_branch.parameters(), self.auxiliary_branch.parameters())
def freeze_bn(self):
for module in self.modules():
if isinstance(module, nn.BatchNorm2d): module.eval()
resnet部分:
import math
import torch
import os
import sys
import zipfile
import shutil
import torch.utils.model_zoo as model_zoo
import torch.nn as nn
try:
from urllib import urlretrieve
except ImportError:
from urllib.request import urlretrieve
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152', 'BasicBlock', 'Bottleneck']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
# 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-25c4b509.pth',
# 'resnet50': 'https://hangzh.s3.amazonaws.com/encoding/models/resnet50-25c4b509.zip',
'resnet101': 'https://hangzh.s3.amazonaws.com/encoding/models/resnet101-2a57e44d.zip',
'resnet152': 'https://hangzh.s3.amazonaws.com/encoding/models/resnet152-0d43d698.zip'
}
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
"""ResNet BasicBlock
"""
expansion = 1
def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None, previous_dilation=1,
norm_layer=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride,
padding=dilation, dilation=dilation, bias=False)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1,
padding=previous_dilation, dilation=previous_dilation, bias=False)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""ResNet Bottleneck
"""
# pylint: disable=unused-argument
expansion = 4
def __init__(self, inplanes, planes, stride=1, dilation=1,
downsample=None, previous_dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = norm_layer(planes)
self.conv2 = nn.Conv2d(
planes, planes, kernel_size=3, stride=stride,
padding=dilation, dilation=dilation, bias=False)
self.bn2 = norm_layer(planes)
self.conv3 = nn.Conv2d(
planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = norm_layer(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.dilation = dilation
self.stride = stride
def _sum_each(self, x, y):
assert(len(x) == len(y))
z = []
for i in range(len(x)):
z.append(x[i]+y[i])
return z
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
#通道注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
att = avg_out + max_out
return self.sigmoid(att) * x
#空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
att = torch.cat([avg_out, max_out], dim=1)
att = self.conv1(att)
return self.sigmoid(att) * x
class ResNet(nn.Module):
"""Dilated Pre-trained ResNet Model, which preduces the stride of 8 featuremaps at conv5.
Reference:
- He, Kaiming, et al. "Deep residual learning for image recognition." CVPR. 2016.
- Yu, Fisher, and Vladlen Koltun. "Multi-scale context aggregation by dilated convolutions."
"""
# pylint: disable=unused-variable
def __init__(self, block, layers, num_classes=1000, dilated=True, multi_grid=False,
deep_base=True, norm_layer=nn.BatchNorm2d):
self.inplanes = 128 if deep_base else 64
super(ResNet, self).__init__()
if deep_base:
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False),
norm_layer(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
norm_layer(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1, bias=False),
)
else:
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
#网络第一层加入注意力机制
self.ca = ChannelAttention(self.inplanes)
self.sa = SpatialAttention()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], norm_layer=norm_layer)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, norm_layer=norm_layer)
if dilated:
self.layer3 = self._make_layer(block, 256, layers[2], stride=1,
dilation=2, norm_layer=norm_layer)
if multi_grid:
self.layer4 = self._make_layer(block, 512, layers[3], stride=1,
dilation=4, norm_layer=norm_layer,
multi_grid=True)
else:
self.layer4 = self._make_layer(block, 512, layers[3], stride=1,
dilation=4, norm_layer=norm_layer)
else:
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
norm_layer=norm_layer)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
norm_layer=norm_layer)
# 网络的最后一层加入注意力机制
self.ca1 = ChannelAttention(self.inplanes)
self.sa1 = SpatialAttention()
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, norm_layer):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1, dilation=1, norm_layer=None, multi_grid=False):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
norm_layer(planes * block.expansion),
)
layers = []
multi_dilations = [4, 8, 16]
if multi_grid:
layers.append(block(self.inplanes, planes, stride, dilation=multi_dilations[0],
downsample=downsample, previous_dilation=dilation, norm_layer=norm_layer))
elif dilation == 1 or dilation == 2:
layers.append(block(self.inplanes, planes, stride, dilation=1,
downsample=downsample, previous_dilation=dilation, norm_layer=norm_layer))
elif dilation == 4:
layers.append(block(self.inplanes, planes, stride, dilation=2,
downsample=downsample, previous_dilation=dilation, norm_layer=norm_layer))
else:
raise RuntimeError("=> unknown dilation size: {}".format(dilation))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
if multi_grid:
layers.append(block(self.inplanes, planes, dilation=multi_dilations[i],
previous_dilation=dilation, norm_layer=norm_layer))
else:
layers.append(block(self.inplanes, planes, dilation=dilation, previous_dilation=dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# x = self.ca(x) * x
# x = self.sa(x) * x
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# x = self.ca1(x) * x
# x = self.sa1(x) * x
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
#空间注意力机制
# class SpatialAttention(nn.Module):
# def __init__(self, kernel_size=7):
# super(SpatialAttention, self).__init__()
#
# assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
# padding = 3 if kernel_size == 7 else 1
#
# self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
# self.sigmoid = nn.Sigmoid()
#
# def forward(self, x):
# avg_out = torch.mean(x, dim=1, keepdim=True)
# max_out, _ = torch.max(x, dim=1, keepdim=True)
# x = torch.cat([avg_out, max_out], dim=1)
# x = self.conv1(x)
# return self.sigmoid(x)
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
def resnet34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
def resnet50(pretrained=False, root='./pretrained', **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
pretrained_dict = load_url(model_urls['resnet50'], model_dir=root)
model_dict = model.state_dict()
keys = []
for k, v in pretrained_dict.items():
keys.append(k)
i = 0
for k, v in model_dict.items():
if v.size() == pretrained_dict[keys[i]].size():
model_dict[k] = pretrained_dict[keys[i]]
i = i + 1
model.load_state_dict(model_dict)
return model
def resnet101(pretrained=False, root='./pretrained', **kwargs):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(load_url(model_urls['resnet101'], model_dir=root))
return model
def resnet152(pretrained=False, root='./pretrained', **kwargs):
"""Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(load_url(model_urls['resnet152'], model_dir=root))
return model
def load_url(url, model_dir='./pretrained', map_location=None):
if not os.path.exists(model_dir):
os.makedirs(model_dir)
filename = url.split('/')[-1].split('.')[0]
cached_file = os.path.join(model_dir, filename+'.pth')
if not os.path.exists(cached_file):
# cached_file = os.path.join(model_dir, filename + '.zip')
cached_file = os.path.join(model_dir, filename+'.pth')
sys.stderr.write('Downloading: "{}" to {}\n'.format(url, cached_file))
urlretrieve(url, cached_file)
zip_ref = zipfile.ZipFile(cached_file, 'r')
zip_ref.extractall(model_dir)
zip_ref.close()
os.remove(cached_file)
cached_file = os.path.join(model_dir, filename+'.pth')
return torch.load(cached_file, map_location=map_location)
代码运行中遇到的问题:loss为nan














 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









