






Revisiting Few-Shot Object Detection with Vision-Language Models

论文地址:[2312.14494] Revisiting Few-Shot Object Detection with Vision-Language Models
项目地址:未开源
发表会议:预发表
摘要
现在的少样本基准都是将COCO或VOC数据集划分为base和novel,但这些基准数据集并未反映FSOD在实践中的部署方式。 文章提出,与仅在少数基础类别上进行预训练不同,更实际的方法是为目标领域对基础模型进行微调,例如,在大规模网络数据上预训练的视觉语言模型(VLM)。令人惊讶的是,发现像GroundingDINO这样的VLM进行的0-shot在COCO上的表现明显优于最先进的方法(48.3 vs. 33.1 AP)。然而,这种0-shot推断模型仍然可能与目标概念不一致,例如,网络上的拖车可能与自动驾驶车辆上下文中的拖车不同。因此,文章提出了Foundational FSOD,这是一个新的基准协议,评估在任何外部数据集上预训练并对每个目标类别进行K次微调的检测器。此外,文章指出当前的FSOD基准实际上是包含对子集数据的每个类别进行详尽注释的联邦数据集。作者利用这一观点提出了使用联邦损失对VLM进行微调的简单策略。
Introduction
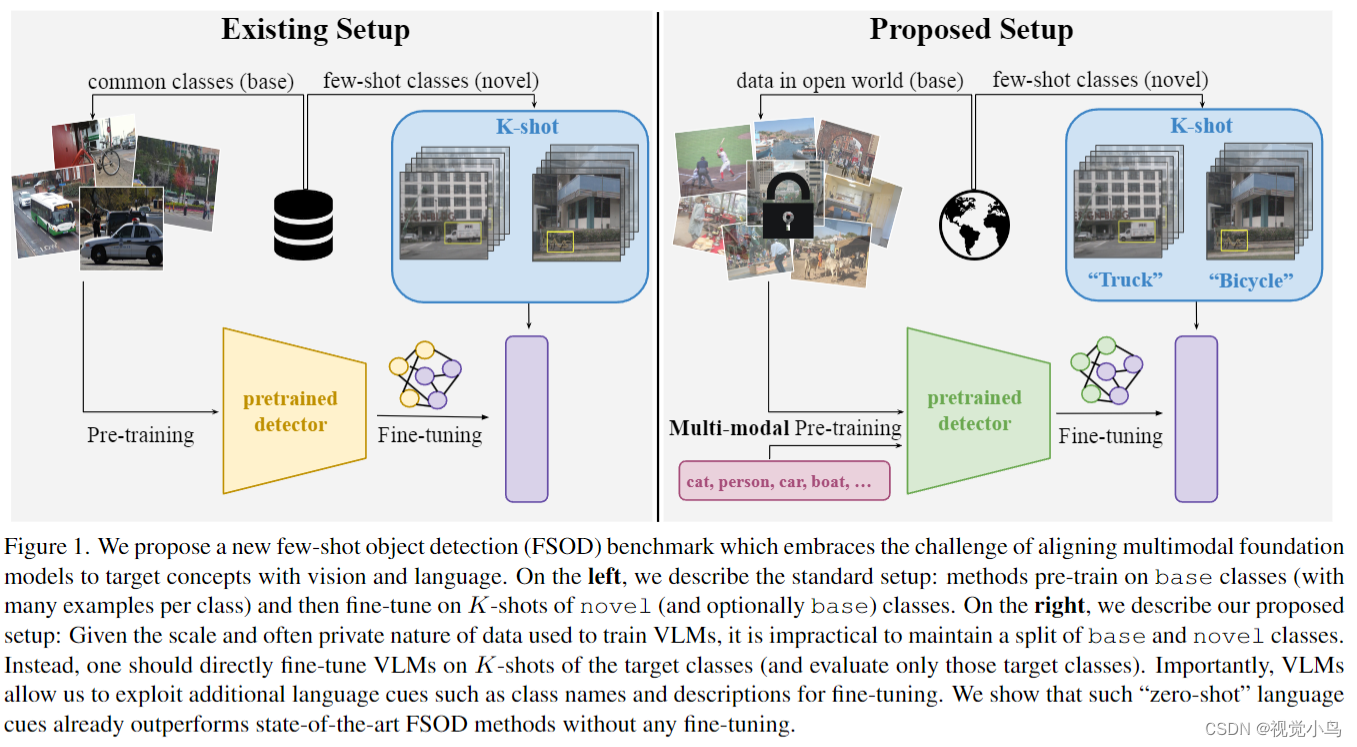
传统的Few-shot object detection (FSOD) 基准数据集要求基础类别和新颖类别是不相交的,以防止概念泄漏并测量对未见过类别的泛化能力。然而,由于大多数检测器都是在ImageNet上进行预训练的,概念泄漏已经在现代基准数据集中发生。例如,在COCO FSOD基准数据集中,猫和人被认为是新颖的,但它们已经存在于ImageNet中。由于很难避免概念泄漏,作者提出应该积极接受它。直观地说,在大规模多样的基础类别上进行预训练(这些类别可能与新颖概念重叠)最终将提高对新颖类别的泛化能力。
Foundational FSOD
实践者可能更倾向于使用在(可能是私有的)大规模网络数据上预训练的基础视觉语言模型(VLMs),并对其进行微调以适应他们的任务。由于VLMs的预训练数据集包含各种概念,很难防止概念泄漏。因此,人们可能会对利用VLMs进行Few-shot object detection (FSOD) 感到犹豫。然而,基础模型的性能是不可否认的;像GroundingDINO这样的最先进的VLMs在COCO上已经在没有微调的情况下超越了所有领先的FSOD方法。

Multi-Modal Concept Alignment.
强大的zero-shot推断性能是否意味着Few-shot目标检测不再是一个有趣的问题?并非如此!我们发现目标类别名称通常无法充分描述目标概念。例如,在nuImages中,“拖车"的定义与在大规模网络数据中的定义不同。正如图2所示,即使是人类注释者也需要几次指导来识别目标概念的微妙之处。有趣的是,注释者的指导通常是多模态的,经常包括视觉示例和文本描述。我们提倡采用类似的视觉和语言线索进行VLM概念对齐的Few-shot目标检测设置。我们将我们提出的设置称为"基础性Few-shot目标检测”。

Federated Few-shot Learning
为了有效地使用K-shot多模态“指导”对齐VLM概念,我们利用了一个简单但明显被低估的观察:Few-shot目标检测数据集实际上是联邦数据集。联邦数据集由较小的子集组成,其中每个子集仅对单个类别进行详尽注释。例如,与摩托车相关的K张图像的背景中可能有汽车,也可能没有(参见图3)。然而,现有的Few-shot目标检测方法错误地假设非汽车图像的背景中不存在汽车。受到在联邦数据集学习和弱监督学习方面的先前工作的启发,我们证明使用联邦损失对VLM进行微调始终优于零次推断。

Contributions :
-
我们通过采用在互联网规模数据上预训练的视觉语言基础模型,使Few-shot目标检测(FSOD)基准更加现代化。我们强调使用多模态的少样本示例定义目标语义概念的实际挑战。
-
我们指出现有的Few-shot目标检测(FSOD)基准实际上是联邦数据集,并提出了用于微调视觉语言模型(VLMs)的简单策略。
-
我们进行了大量实验,剖析了我们的设计选择,并展示了我们简单方法在LVIS和nuImages基础Few-shot目标检测(Foundational FSOD)基准上实现了最先进的结果。
Method
没有提供源码,且方向不太感兴趣,方法部分就没有细看0.0
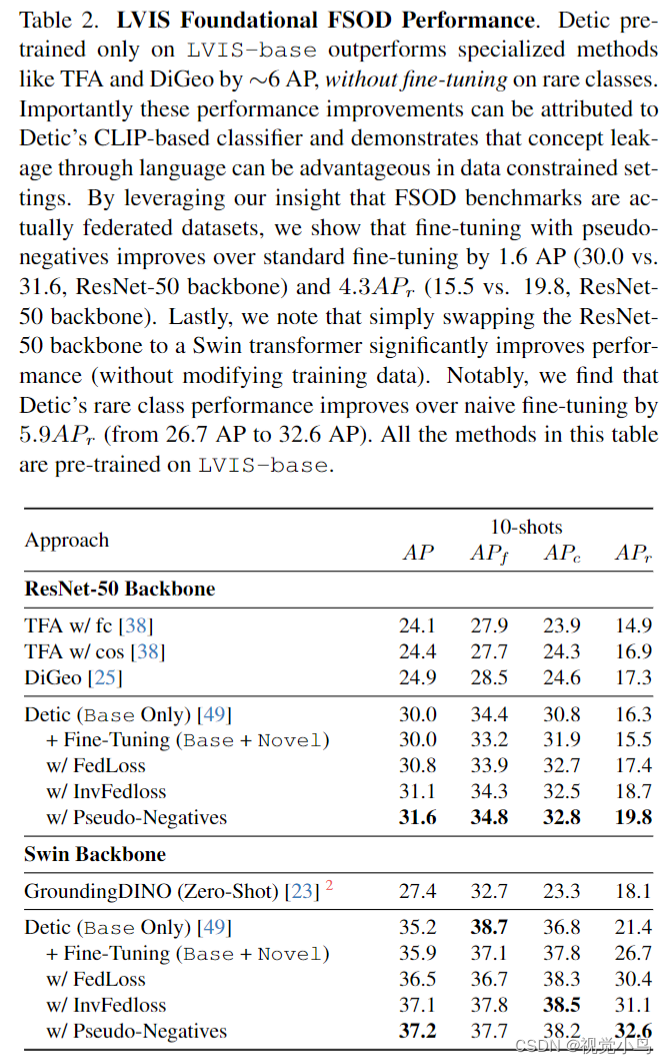
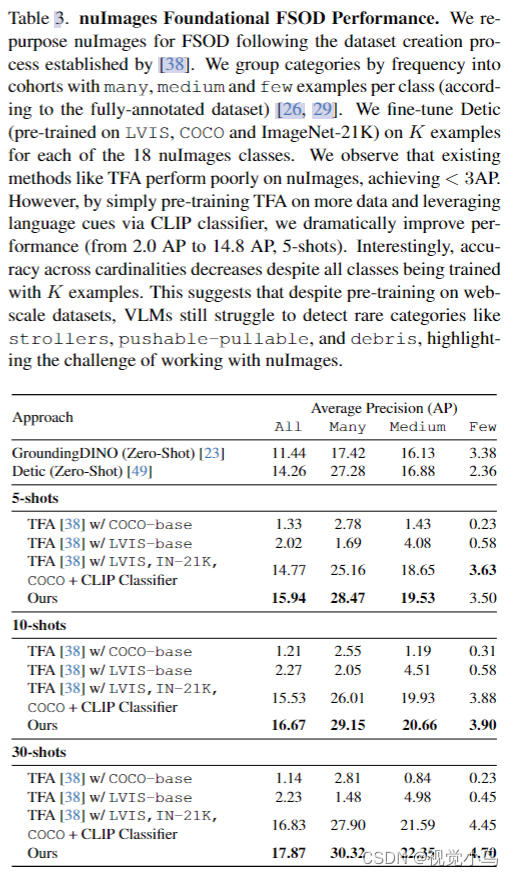
Experiments















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









