







 该博客通过pandas库对2014年第二季度捞起生鱼片的销售数据进行定量分析,包括计算极差、确定组距和组数、绘制频率分布直方表和图表。使用cut方法进行数据分组,然后通过groupby和agg方法计算各销售量区间的频次,并进一步转换为频率比例。最终,绘制出频率分布直方图,揭示了销售数据的分布情况。
该博客通过pandas库对2014年第二季度捞起生鱼片的销售数据进行定量分析,包括计算极差、确定组距和组数、绘制频率分布直方表和图表。使用cut方法进行数据分组,然后通过groupby和agg方法计算各销售量区间的频次,并进一步转换为频率比例。最终,绘制出频率分布直方图,揭示了销售数据的分布情况。
对数据集“捞起生鱼片”做定量分析
穿插pandas的cut,groupby,agg方法
定量数据分布分析
对于定量数据而言,选择组数与组宽是做评率分布分析时最主要的问题,步骤如下:
-第一步:求极差【max-min】
-第二步:决定组距与组数【组距观察数据自己给出,一般组距都是左闭右开区间的;组数=极差/组距】
-第三步:决定分点【也就是分布区间表格】
-第四步:列出频率分布表
-第五步:绘制频率分布直方图
原则:各组是相斥的,且包含了所有数据,各组的组宽最好相等
例子:菜品“捞起生鱼片”在2014年第二个季度的销售数据,绘制销售量的频率分布表,频率分布图,对该定量数据做出相应分析。
- #加载查看数据
import pandas
data = pd.read_excel(catering_fish_congee.xls")
print(data.max()-data.min())
》》》》》结果:
2014-04-01 00:00:00 89 days 00:00:00
420 3915
dtype: object
-
第一步:求极差 最大值-最小值=3915
-
第二步:分组 ,组距看实际情况可取为500
组数 = 极差/组距 = 3915/500 约等于8 -
第三步:决定分点
[0,500) [500,1000) … [3500,4000) -
第四步:绘制频率分布直方表
Excel操作 -
第五步:绘制频率分布直方图
#分析生鱼片第二季度的销售数据 每天的销售额为x轴,频率与组距之比为y轴
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_excel("catering_fish_congee.xls", names = ['date','sale'])
#print(data.head())
#print(data['sale'].max())
#print(data['sale'].min())
bins = [0,500,1000,1500,2000,2500,3000,3500,4000]#由销售量分布区间可知
labels = ['[0,500)','[500,1000)','[1000,1500)','[1500,2000)',
'[2000,2500)','[2500,3000)','[3000,3500)','[3500,4000)']
#在对数据进行分段分组时,可采用cut方法,用bins的方式实现。这种情况一般使用于,对于销售量,年龄、分数等数据。
data["sale分层"] = pd.cut(data.sale, bins = bins, labels = labels)
print(data["sale分层"].head())
print(data.head())
>>>>>>结果:
>
D:\Tool\Anaconda\python.exe "D:/python/数据挖掘与分析/第三章 数据探索/定量数据频率分布直方图.py"
0 [500,1000)
1 [1000,1500)
2 [0,500)
3 [1500,2000)
4 [1000,1500)
Name: sale分层, dtype: category
Categories (8, object): ['[0,500)' < '[500,1000)' < '[1000,1500)' < '[1500,2000)' < '[2000,2500)' <
'[2500,3000)' < '[3000,3500)' < '[3500,4000)']
date sale sale分层
0 2014-04-02 900 [500,1000)
1 2014-04-03 1290 [1000,1500)
2 2014-04-04 420 [0,500)
3 2014-04-05 1710 [1500,2000)
4 2014-04-06 1290 [1000,1500)
Process finished with exit code 0
1.pandas.cut():一般常用于对数据进行分段分组,比如销售量,年龄等。具体可以参照上面代码
2.data.head():查看数据,默认前五行,可以自己指定查看多少行;相反的,data.tail()默认是查看数据最后五行的。
3.原始数据只有date与sale两列,并且列名是自己加上去的。
aggResult = data.groupby(by = ['sale分层'])['sale'].agg(np.size)
print(aggResult,type(aggResult))
paggResult = round(aggResult/aggResult.sum(), 2, ) * 100
#round(数值,保留小数位数),当保留小数位大于0时采用四舍五入的方法
print(paggResult,type(paggResult))
》》》》》》》》结果:
sale分层
[0,500) 28
[500,1000) 20
[1000,1500) 12
[1500,2000) 12
[2000,2500) 8
[2500,3000) 3
[3000,3500) 4
[3500,4000) 3
Name: sale, dtype: int64 <class 'pandas.core.series.Series'>
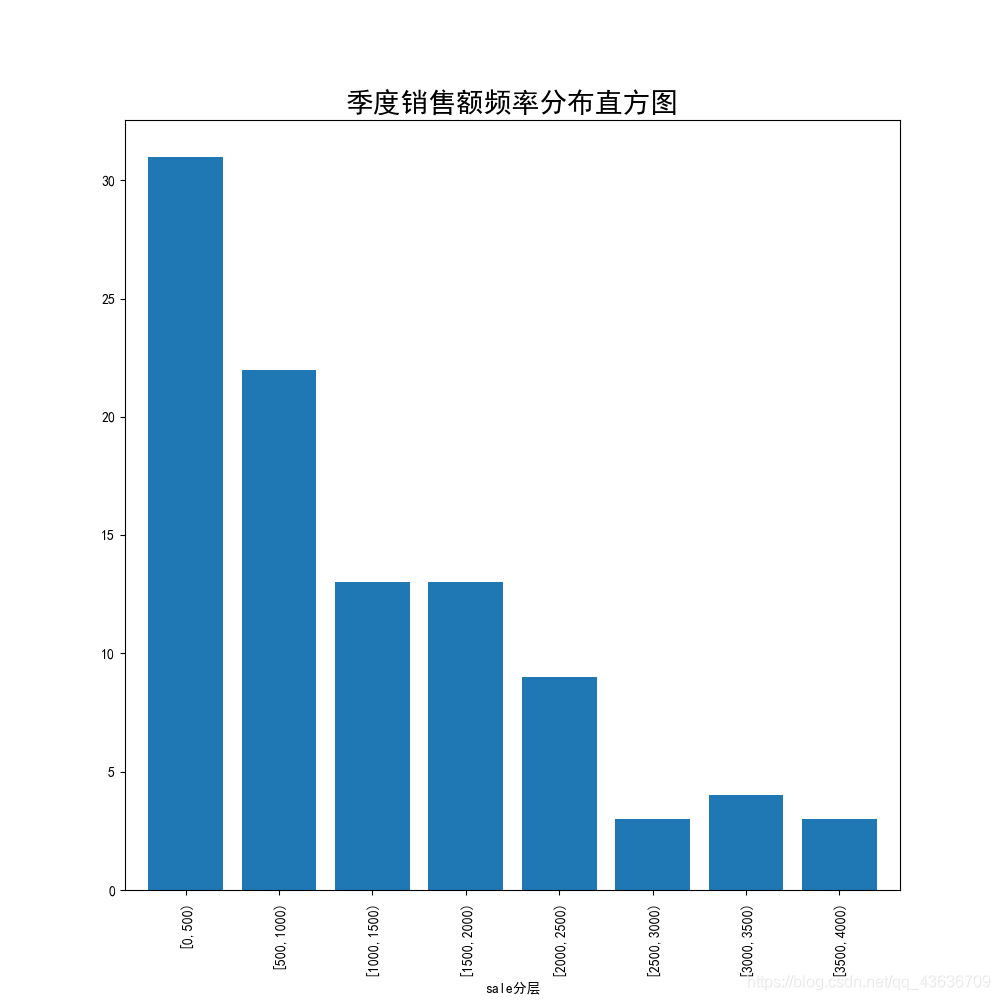
sale分层
[0,500) 31.0
[500,1000) 22.0
[1000,1500) 13.0
[1500,2000) 13.0
[2000,2500) 9.0
[2500,3000) 3.0
[3000,3500) 4.0
[3500,4000) 3.0
Name: sale, dtype: float64 <class 'pandas.core.series.Series'>
Process finished with exit code 0
1.groupy():分组操作,不计算,返回已分组的DataFrame或者Series。
2.agg(func):聚合操作,计算,接收函数,如max(),min(),size()等。
3.round():语法 round(数值,保留小数位数),当保留小数位大于0时采用四舍五入的方法
#pandas引入了agg函数,它提供基于列的聚合操作,进行计算。
#groupby是分组操作,不进行计算,或者说index的聚合操作。这种索引操作所返回的对象是一个已分组的DataFrame(如果传入的是列表或数组)或已分组的Series。
#s.groupby([1,1,2,2]).agg([‘min’,‘max’]):加[],agg的func仅接受一个参数,等效于s.groupby([1,1,2,2]).min()对data1,把min更名为a,max更名为b
#df.groupby([‘key1’])[‘data1’].agg({‘a’:‘min’,‘b’:‘max’})#这里的’min’ 'max’为两个函数名
重要技巧: groupby之后直接.reset_index()可以得到一个没有多级索引的DataFram,之后可以通过df.rename({‘old_col1’:‘new_col1’,‘old_col2’:‘new_col2’,…})重命名
#df1= df.groupby([‘date’])[‘price’].agg({‘sum’,‘count’}).reset_index()
参考了该博主的文章
https://blog.csdn.net/u013317445/article/details/85268877
plt.figure(figsize=(10,10))#设置图标框大小尺寸
paggResult.plot(kind = 'bar', width = 0.8, fontsize = 10)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("季度销售额频率分布直方图", fontsize = 20)
plt.show()

















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









