







1. Elasticsearch 中的倒排索引是什么?
Elasticsearch 使用一种称为倒排索引的结构,ES中的倒排索引其实就是 lucene 的倒排索引,区别于传统的正向索引,倒排索引会再存储数据时将关键词和数据进行关联,保存到倒排表中,然后查询时,将查询内容进行分词后在倒排表中进行查询,最后匹配数据即可。
2. ElasticSearch的基本概念

3. ElasticSearch的搜索流程
1. 客户端向集群发送请求,集群随机选择一个 NodeX 处理这次请求。
2. Nodex 先计算文档在哪个主分片上,比如是主分片 A,它有三个副本 A1,A2,A3。那么请求
会轮询三个副本中的一个完成请求。
3. 如果无法确认分片,比如检索的不是一个文档,就遍历所有分片。客户端发送请求到coordinate node,协调节点将搜索请求广播到所有的primary shard或replica,每个分片在本地执行搜索并构建一个匹配文档的大小为from + size的优先队列。接着每个分片返回各自优先队列中所有docld和打分值给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。协调节点根据Query阶段产生的结果,去各个节点上查询docld实际的document内容,最后由协调节点返回结果给客户端。
4. ElasticSearch如何实现master选举
Master节点负责管理集群状态信息,包括处理创建、删除索引等请求,决定分片被分配到哪个节点,维护和更新集群状态。值得注意的是,只有Master节点才能修改集群的状态信息,并负责同步给其他节点。

5. Elasticsearch更新和删除文档的过程

6. Elasticsearch创建索引文档的过程

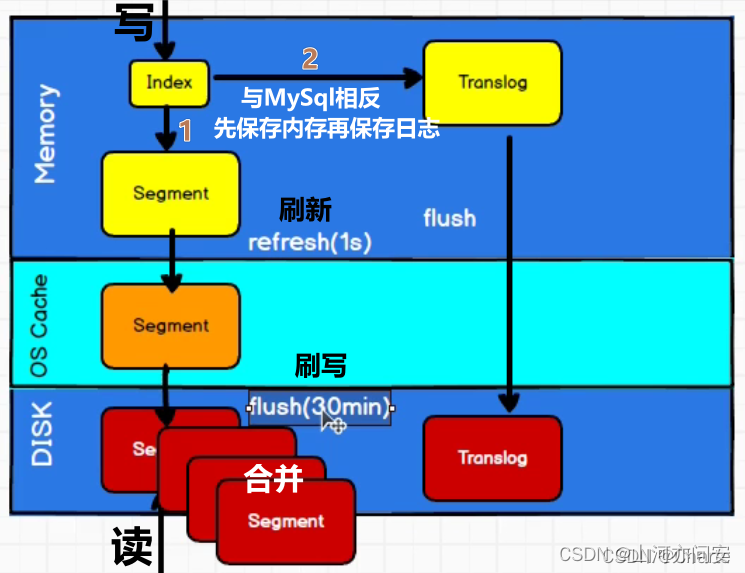
7. 了解文本相似度 TF-IDF吗
TF = Term Frequency 词频,一个词在这个文档中出现的频率。值越大,说明这文档越匹配,
正向指标。
IDF = Inverse Document Frequency 反向文档频率,简单点说就是一个词在所有文档中都出
现,那么这个词不重要。
TF-IDF = TF / IDF
8. 了解ElasticSearch 深翻页的问题及解决吗?
深翻页:比如我们检索一次,轮询所有分片,汇集结果,根据 TF-IDF 等算法打分,排序后将前 10
条数据返回。用户感觉不错,说我看看下一页。ES 依然是轮询所有分片,汇集结果,根据 TF-IDF
等算法打分,排序后将前 11-20 条数据返回。
对用户来说,翻页应该很快啊,但是实际上,第一次检索多复杂,下一次检索就多复杂。
解决的话,可以把用户的检索结果,存入 Redis 中 10 分钟。这样分页就很快,超过 10 分钟,用户
不翻页,也就不会翻页了,数据就可以清除了。
9. 熟悉ElasticSearch 性能优化
1. 批量提交
背景是大量的写操作,每次提交都是一次网络开销。网络永久是优化要考虑的重点。
2. 优化硬盘
索引文件需要落地硬盘,段的思想又带来了更多的小文件,磁盘 IO 是 ES 的性能瓶颈。一个固态硬
盘比普通硬盘好太多。
3. 减少副本数量
副本可以保证集群的可用性,但是严重影响了 写索引的效率。写索引时不只完成写入索引,还要完成索引到副本的同步。ES 不是存储引擎,不要考虑数据丢失,性能更重要。 如果是批量导入,建议就关闭副本。
10. ElasticSearch 查询优化手段有哪些?
设计阶段调优
(1)根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引;
(2)使用别名进行索引管理;
(3)每天凌晨定时对索引做 force_merge 操作,以释放空间;
(4)采取冷热分离机制,热数据存储到 SSD,提高检索效率;冷数据定期进行 shrink操作,以缩
减存储;
(5)采取 curator 进行索引的生命周期管理;
(6)仅针对需要分词的字段,合理的设置分词器;
(7)Mapping 阶段充分结合各个字段的属性,是否需要检索、是否需要存储等。……..
写入调优
(1)写入前副本数设置为 0;
(2)写入前关闭 refresh_interval 设置为-1,禁用刷新机制;
(3)写入过程中:采取 bulk 批量写入;
(4)写入后恢复副本数和刷新间隔;
(5)尽量使用自动生成的 id。
查询调优
(1)禁用 wildcard;
(2)禁用批量 terms(成百上千的场景);
(3)充分利用倒排索引机制,能 keyword 类型尽量 keyword;
(4)数据量大时候,可以先基于时间敲定索引再检索;
(5)设置合理的路由机制。
11. ElasticSearch集群是CP还是AP?
ES集群出现分区时,故障节点就会被剔除集群,数据分片会重新分配到其它节点,保证数据一致。因此是低可用性,高一致性,属于CP。
















 2024
2024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











