







今天的话题,要给大家分享的大厂面试题是:千万级唯一ID如何生成?!看起来这是一个非常具体的问题,没错!分布式项目中,无法避免这个问题,但是我想说的是,面试官通过打开这个问题,是可以从这个角度了解面试者在分布式应用中是否有丰富经验的,分布式大型项目才会有这个问题吧,看似一个具体的问题,背后却是面试官密谋最佳人选的经验,今天威哥就来聊一聊这个话题。
为了让小伙伴们有身临其境的感觉,威哥会以场景化的面试方式来讲解,小伙伴们准备好了吗,马上开整。
首先来看一下互联网大厂必问题 :
-
做过分布式项目吗?
-
知道分布式 ID 生成策略吗?
-
如何实现的?
注意面试官的预期
-
是否有分布式项目经验
-
对分布式 ID 生成算法研究的深度

面试官老哥:
“一条大河向东流,ID 策略惹闲愁”
在分布式项目中,你使用的分布式 ID 策略是什么?
面试者小哥哥:
“我敬岁月三杯酒,雪花算法来出头”
是的,我在分布式项目采用当前主流的雪花算法来实现。
SnowFlake 算法,是 Twitter 开源的分布式 id 生成算法。其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id,在分布式系统中的应用十分广泛。
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。
概括下来,那业务系统对ID号的要求有哪些呢?
-
全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
-
趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
-
单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
-
信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则。
常见方法生成 ID 带来的问题?
1.UUID:示例:550e8400-e29b-41d4-a716-446655 440000
-
优点:性能非常高
-
缺点:不易于存储、信息不安全、不适合作为主键
2.数据库生成:以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增。
-
优点:非常简单、ID号单调自增
-
缺点:强依赖DB、ID发号性能瓶颈限制在单台MySQL的读写性能
分布式id生成器-雪花算法
JAVA实现雪花算法:https://github.com/beyond fengyu/SnowFlake
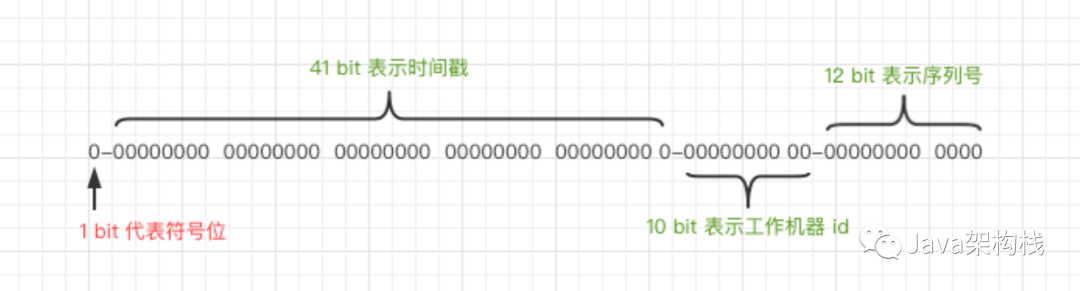
这 64 个 bit 中:
其中1个bit是不用的,然后用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号。
面试官老哥:
你们项目中是怎样使用雪花算法的,可以讲一讲吗?
面试者小哥哥:
关于这个问题,我们可以直接切入正题,以下以Leaf解决方案来展开,Leaf方案(https://github.com /Meituan-Dianping/Leaf)
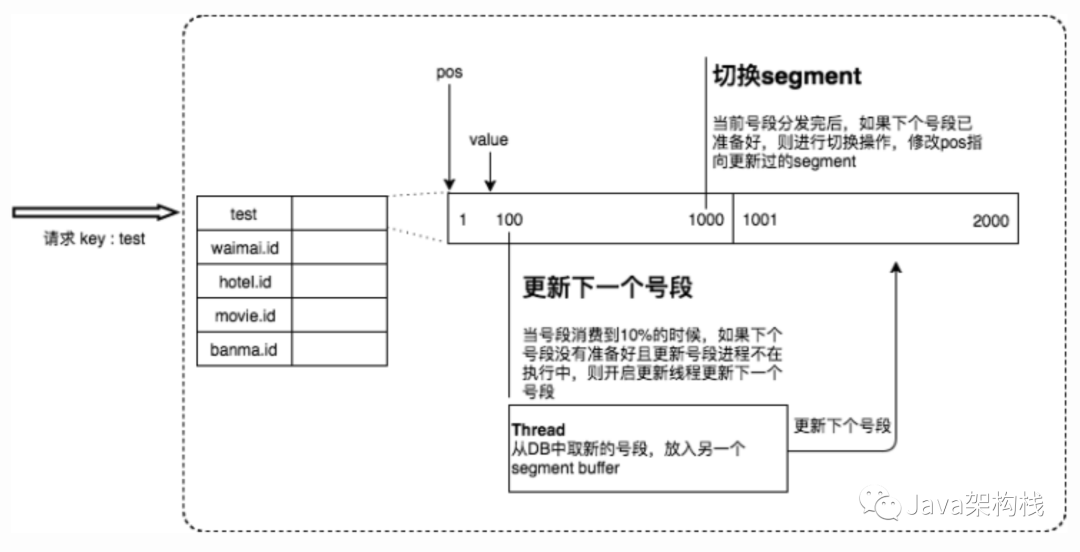
Leaf方案实现
Leaf这个名字是来自德国哲学家、数学家莱布尼茨的一句话:世界上没有两片相同的树叶(There are no two identical leaves in the world )
Leaf实现了Leaf-segment(号段模式)和Leaf-snowflake方案(雪花算法)
第一种Leaf-segment方案,在使用数据库的方案上,做了如下改变:-原方案每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step。
test_tag在第一台Leaf机器上是1~1000的号段,当这个号段用完时,会去加载另一个长度为step=1000的号段,假设另外两台号段都没有更新,这个时候第一台机器新加载的号段就应该是3001~4000。同时数据库对应的biz_tag这条数据的max_id会从3000被更新成4000。
Leaf 还采用双buffer对号段模式进行优化
简单的说就是:Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢。
这样DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。
采用双buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复。
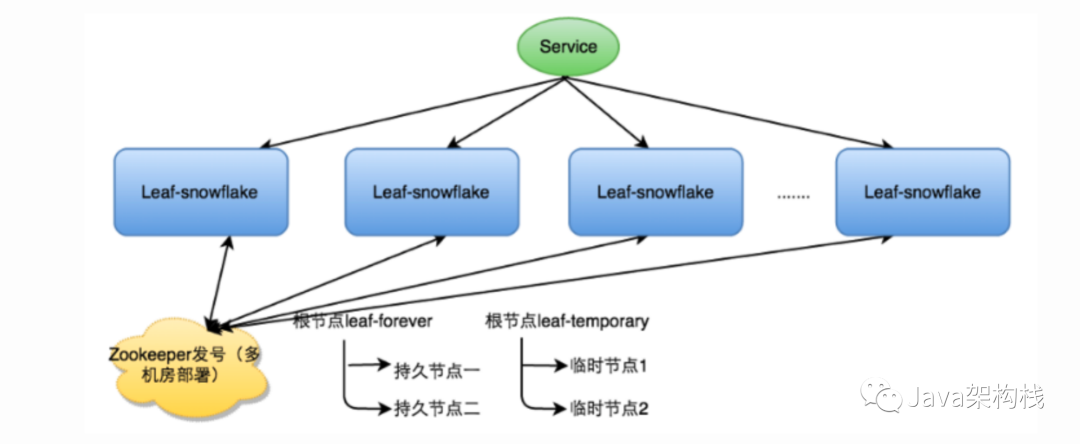
Leaf-segment方案可以生成趋势递增的ID,同时ID号是可计算的,不适用于订单ID生成场景,比如竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。面对这一问题,美团提供了 Leaf-snowflake方案。
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即是“1+41+10+12”的方式组装ID号。对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。Leaf-snowflake是按照下面几个步骤启动的:
-
启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
-
如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
-
如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
解决时钟问题
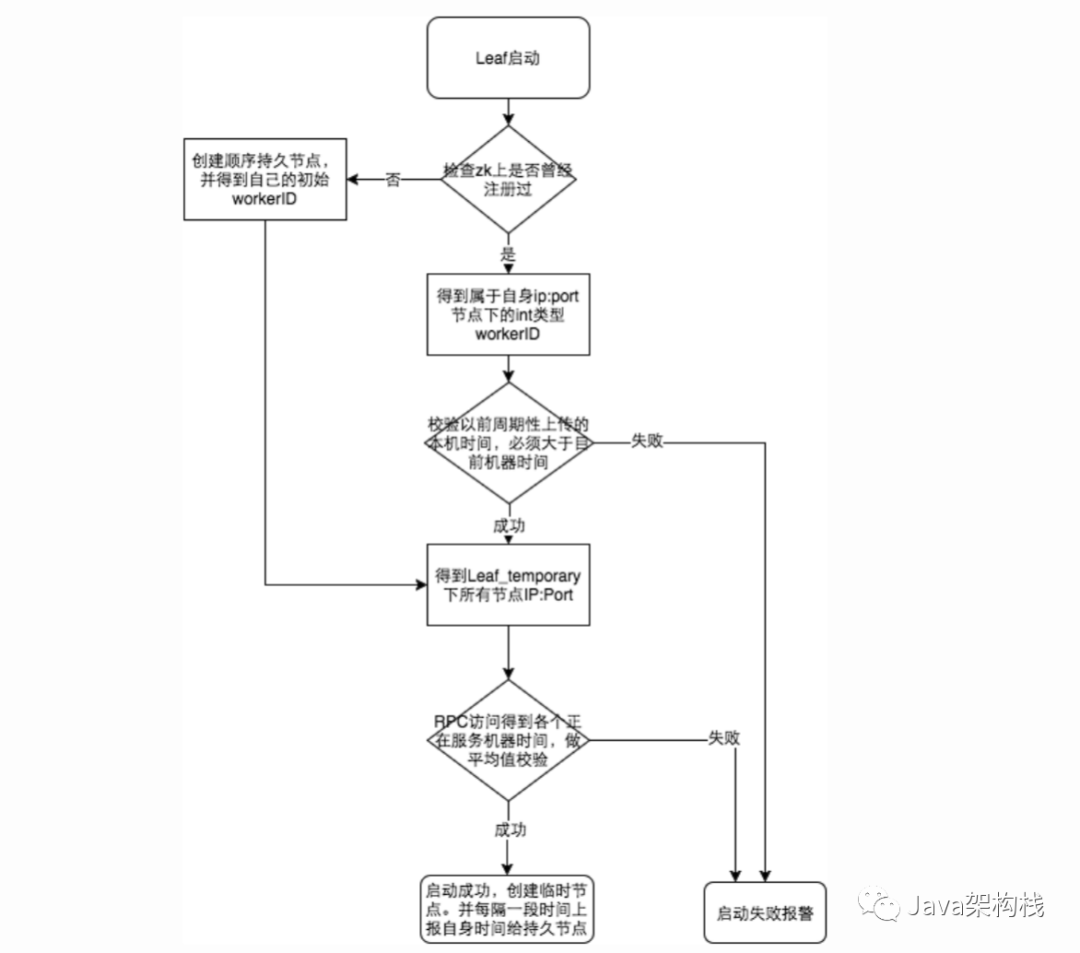
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。
参见上图整个启动流程图,服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点:
-
若写过,则用自身系统时间与leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警。
-
若未写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。
-
若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约。
-
否则认为本机系统时间发生大步长偏移,启动失败并报警。
-
每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}。
Leaf在美团点评公司内部服务包含金融、支付交易、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。目前Leaf的性能在4C8G的机器上QPS能压测到近5w/s,TP999 1ms,已经能够满足大部分的业务的需求。每天提供亿数量级的调用量。
其他ID生产策略
百度uid-generator
https://github.com/baidu/uid-generator
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
滴滴 Tinyid
https://github.com/didi/tinyid
Tinyid是用Java开发的一款分布式id生成系统,基于数据库号段算法实现,关于这个算法可以参考美团leaf或者tinyid原理介绍。Tinyid扩展了leaf-segment算法,支持了多db(master),同时提供了java-client(sdk)使id生成本地化,获得了更好的性能与可用性。Tinyid在滴滴客服部门使用,均通过tinyid-client方式接入,每天生成亿级别的id。
最后小结一下
本文我们一起聊了分布式 ID 生成策略,Snowflake算法的原理,实现方案,和国内大厂的开源实现,这点很重要,在面试过程,可以按照这个思路:找到问题,以及如何解决问题,这个思路不仅仅是在搞技术写代码上,在日常工作中的任何事情都可以有这个思路,你想啊,如果只提问题,不提解决问题的方法,那就成了抱怨了,这不是一个积极努力向上的人应该有的状态。
代码人生,从代码中还能领悟到做事的道理,你学会了吗?欢迎各位前进路上的兄弟们评论关注,每天进步一点点,威哥与你同在。
更多Java学习面试题可加我微信领取




面试题库文档,加微信免费领取















 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









