










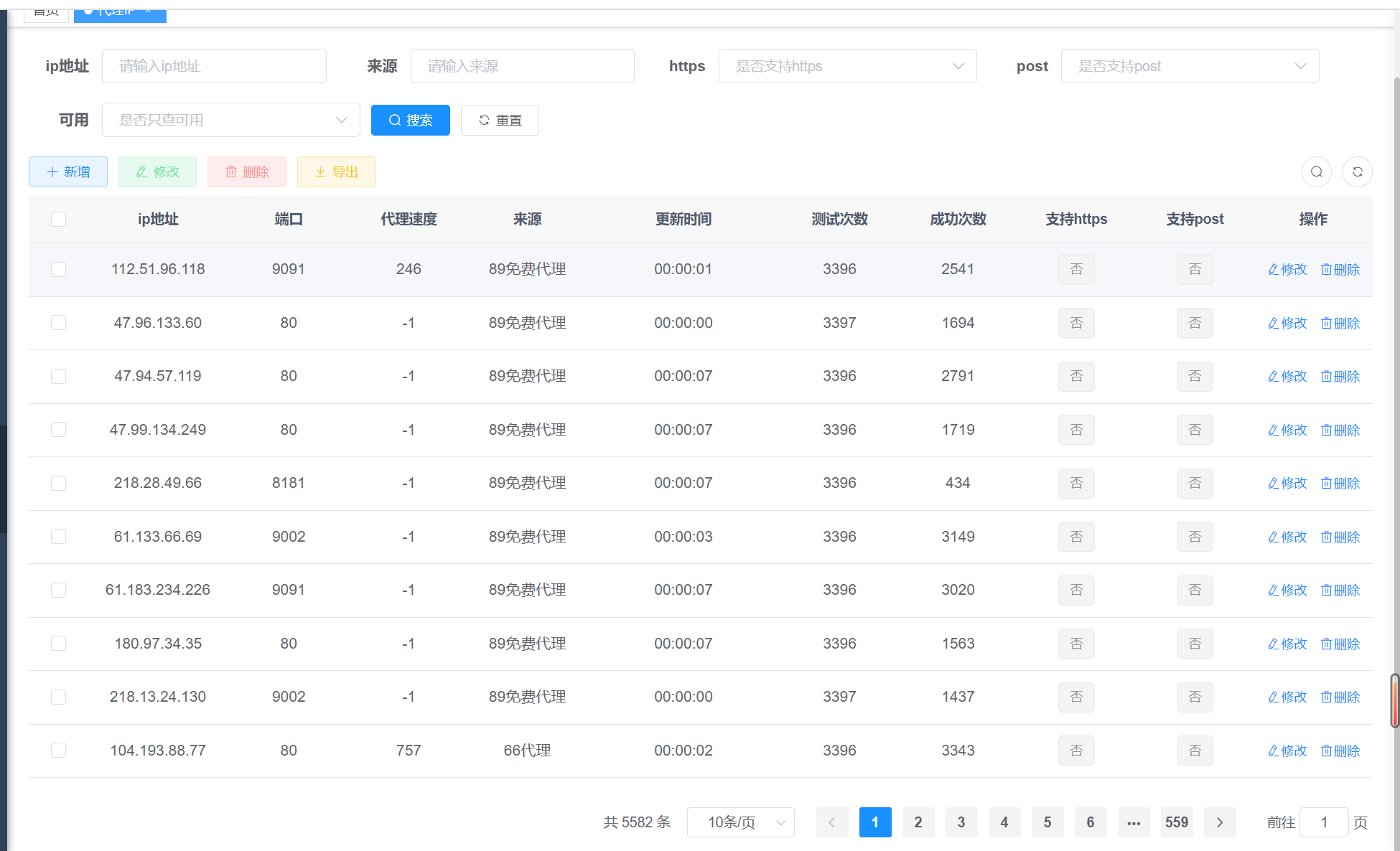
python爬取代理ip脚本,搭建自己的代理池
建议:爬取后尽量搭建自己的代理池,每天都测一下代理是否可用,开放接口时需测下是否可用
import queue
import time
from threading import Thread
from lxml import etree
import re
import requests
# 控制台不输出verify=False导致的安全警告
requests.packages.urllib3.disable_warnings()
def req_get_html(url, headers=None, retry_times=3):
"""
发送请求获取网页源代码
:param url: 链接地址
:param retry_times:重试次数
:return: 响应对象
"""
flag = False
res = ""
while not flag and retry_times > 0:
try:
res = requests.get(url, headers=headers, verify=False)
encode = get_encode(res.headers)
if encode != "":
res.encoding = encode
else:
pass
flag = True
except Exception as e:
print(e)
retry_times -= 1
return res
def get_encode(headers):
"""
获取headers中的Content-Type里携带的网页编码信息
:param headers:
:return:
"""
encode = ""
encod_str = headers["Content-Type"]
if encod_str is not None:
com_encode = re.compile("charset=(.*)")
encode = re.search(com_encode, encod_str)
else:
pass
return encode
def analyze_response(res):
"""
解析网页结构,提取代理信息
:param res:
:return:
"""
ip_msg_lis = []
tree = etree.HTML(res)
lis = tree.xpath(
"//div[@id='list']//tr|//div[@class='fly-panel']//tr|//div[@class='layui-form']//tr|//div[@align='center']//tr|//div[@class='top']//tr|//div[@class='container']//tr|//div[@class='list']/div[@class='tr ip_tr']|//tbody/tr")
for i in lis:
li = i.xpath('./td/text()|./div/text()')
# print(li)
if len(li) > 0:
if li[0] != "ip":
ip_msg_lis.append(li)
return ip_msg_lis
def rm_character(str_wait):
"""
剔除获取的代理中的特殊符号
:param str_wait:
:return:
"""
re_rm = re.compile("\\n|\\t")
res = re.sub(re_rm, "", str_wait)
return res
def try_response_speed(name,url, ip, port, retry_time=3, timeout=3):
"""
测速
:param ip:
:param port:
:param retry_time:
:return:
"""
flag = False
# try_url = "https://www.baidu.com"
try_url = "http://www.baidu.com"
response_status = 500
speed = retry_time * timeout
http_flag = False
https_flag = False
while not flag and retry_time > 0:
try:
proxy = {
"http": "http://{}:{}".format(ip, port),
"https": "https://{}:{}".format(ip, port)
}
# print(proxy)
time_start = time.time()
response = requests.get(
url=try_url, proxies=proxy, timeout=timeout)
time_end = time.time()
speed = time_end - time_start
response_status = response.status_code
# print(response_status)
flag = True
http_flag = True
except Exception as e:
# print(e)
retry_time -= 1
try_url = "https://www.baidu.com"
try:
proxy = {
"http": "http://{}:{}".format(ip, port),
"https": "https://{}:{}".format(ip, port)
}
response = requests.get(
url=try_url, proxies=proxy, timeout=timeout)
if response.status_code == 200:
https_flag = True
except Exception as e:
s = 1
# print()
# retry_time -= 1
ip_msg = {
"source": str(name).split('-')[0],
"ip": ip,
"port": port,
"status": response_status,
"sourceUrl": url,
"sendTime": int(speed * 1000),
"http": http_flag,
"https": https_flag
}
if response_status == 200:
que.put(ip_msg)
# return response_status,speed
def post_art_ip(s):
try:
headers = {
"Content-Type": 'application/json;charset=UTF-8'
}
# 记录所抓ip,发送到自己后台
content = requests.post('https://xxxx', json=s)
print(content.text)
except Exception as e:
print('e')
if __name__ == '__main__':
que = queue.Queue()
ip_free_dic = {
"快代理_高匿": "https://www.kuaidaili.com/free/inha/1/",
"快代理_普通": "https://www.kuaidaili.com/free/intr/1/",
"89免费代理-1": "https://www.89ip.cn/index_1.html",
"89免费代理-2": "https://www.89ip.cn/index_2.html",
"89免费代理-3": "https://www.89ip.cn/index_3.html",
"89免费代理-4": "https://www.89ip.cn/index_4.html",
"89免费代理-5": "https://www.89ip.cn/index_5.html",
"89免费代理-6": "https://www.89ip.cn/index_6.html",
"89免费代理-7": "https://www.89ip.cn/index_7.html",
"89免费代理-8": "https://www.89ip.cn/index_8.html",
"89免费代理-9": "https://www.89ip.cn/index_9.html",
"89免费代理-10": "https://www.89ip.cn/index_10.html",
"高可用全球免费代理ip库": "https://ip.jiangxianli.com/",
"66代理-1": "http://www.66ip.cn/1.html",
"66代理-2": "http://www.66ip.cn/2.html",
"66代理-3": "http://www.66ip.cn/3.html",
"站大爷": "https://www.zdaye.com/daxue_ip.html",
"站大爷-1": "https://www.zdaye.com/free/1/?https=1&post=%E6%94%AF%E6%8C%81",
"站大爷-2": "https://www.zdaye.com/free/2/?https=1&post=%E6%94%AF%E6%8C%81",
"站大爷-3": "https://www.zdaye.com/free/1/?cunhuo=7&px=3",
"站大爷-4": "https://www.zdaye.com/free/2/?cunhuo=7&px=3",
"蜜蜂代理-1": "https://www.beesproxy.com/free/page/1",
"蜜蜂代理-2": "https://www.beesproxy.com/free/page/2",
"蜜蜂代理-3": "https://www.beesproxy.com/free/page/3",
"蜜蜂代理-4": "https://www.beesproxy.com/free/page/4",
"seofangfa": "https://proxy.seofangfa.com/"
}
for k, v in ip_free_dic.items():
# print("开始" + k + "爬取,url=" + v)
headers = {
"user-agent": "PostmanRuntime-ApipostRuntime/1.1.0"
}
res = req_get_html(url=v, headers=headers)
if res != "":
ip_list = analyze_response(res.text)
if len(ip_list) > 0:
res = [[rm_character(j) for j in i] for i in ip_list]
for msg in res:
ip = msg[0]
port = msg[1]
test_speed = Thread(
target=try_response_speed, args=(
k, v, ip, port))
test_speed.start()
s = '['
x = 1
my_list = []
que2 = queue.Queue()
while not que.empty():
data = que.get()
que2.put(data)
my_list.append(data)
if x == 1:
s = s + str(data)
else:
s = s + ',' + str(data)
x = 2
s = s + ']'
# 发送自己后台 搭建代理池用
# post_my_ip(my_list)
print('开始写入。。。')
print('数量:' + str(que2.qsize()))
with open('output.txt', 'w', encoding='utf-8') as file:
# 从队列中获取数据并写入文件
file.write('[')
xx = 1
while not que2.empty():
data = que2.get()
# print(data)
if xx == 1:
file.write(str(data))
else:
file.write(',' + str(data))
xx = 2
file.write(']')
print('写入完成。。。')
















 7894
7894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









