







维基百科的定义:
熵:

KL散度:

交叉熵:

发现与总结:
不难发现,假定给两个概率分布 p p p, q q q,其中 p p p是数据集潜在的真实分布,而 q q q是模型(神经网络等等)经过classifier输出的概率预测分布的话,则 H ( p , q ) = H ( p ) + D K L ( p ∣ ∣ q ) H(p, q) = H(p)+D_{KL}(p||q) H(p,q)=H(p)+DKL(p∣∣q)
Pytorch实践:
import torch
from torch import nn
import torch.nn.functional as F
torch.set_printoptions(
precision=2, # 精度,保留小数点后几位,默认4
threshold=1000,
edgeitems=0,
linewidth=150, # 每行最多显示的字符数,默认80,超过则换行显示
profile=None,
sci_mode=False # 用科学技术法显示数据,默认True
)
def cross_entropy(y_hat, y):
# print(len(y_hat))
return - torch.log(y_hat[range(len(y_hat)), y])
# o是未规范化的输出-对应网络backbone
o = torch.tensor([[20., 20., 0.]],requires_grad=True)
# o 经过softmax函数 输出概率分布-对应backbone后的classifier输出
softmax = torch.exp(o)/torch.sum(torch.exp(o))
# print('softmax(o): ',softmax,'\n')
print('p(x):',softmax,'\n')
# one-hot = [0, 1, 0]-这里我们假定该样本的真实标签是1(以0开始)
y = torch.tensor([1])
print('q(x): ', [0.0, 1.0, 0.0], '\n')
# 验证公式(4)和公式(10)-对应文献Interpretation of Softmax Regression
# print('log(sum(exp(o))): ',torch.log(torch.sum(torch.exp(o))), '\n') # log(sum(exp(o))) 约等于 argmax(o_1, o_2, ..., o_q)
print('reproduce CE: ',torch.log(torch.sum(torch.exp(o)))-o[range(len(o)), y])
loss = cross_entropy(softmax, y)
print('official CE: ',loss,'\n')# 对应20行,它们应该是等价的
# 验证公式(12)
# loss.backward()
# print(o.grad) # 0.5 - 1.0
# KL
logp_o = torch.log(softmax) # 拟合的概率分布
p_y = torch.tensor([0, 1, 0]) # 真实的概率分布,对于KL而言,其实我们更希望的是soft labels
KL = F.kl_div(logp_o, p_y, reduction='batchmean')
print('KL: ', KL) # 因为p_y是one-hot encoding, 所以此时等价于 cross- entropy
注意

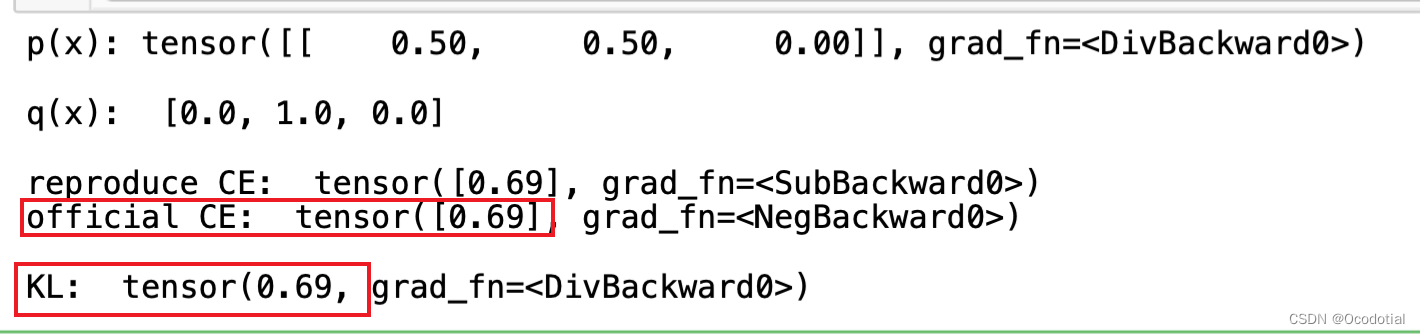
运行结果:
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











