






Scrapy是一个为了爬取网站信息,提取结构性数据而编写的应用爬虫框架。本文将以拉勾网数据挖掘招聘信息(https://www.lagou.com/zhaopin/shujuwajue/?labelWords=label)为例介绍Scrapy shell的简单使用方法。
1.连接网址:
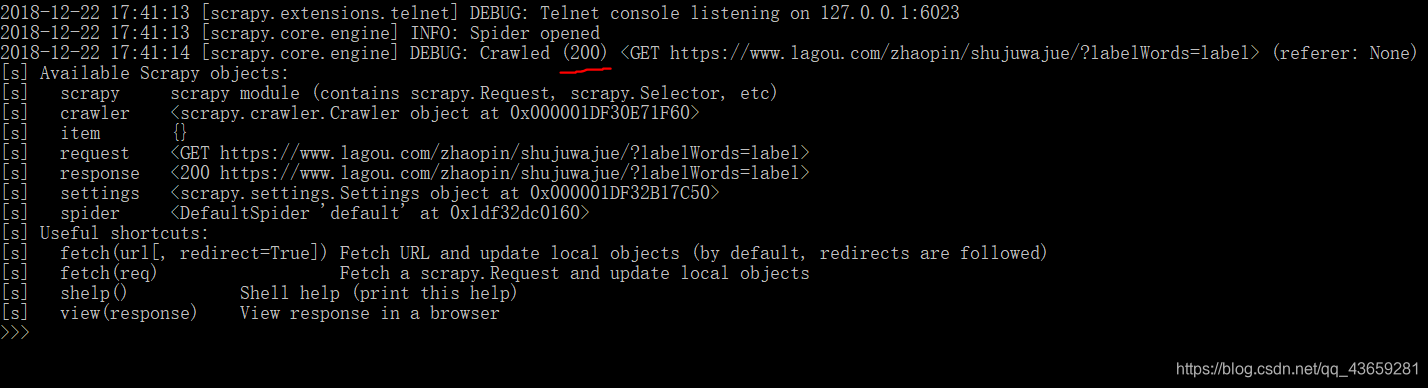
首先打开cmd命令行,输入scrapy shell “网址"命令,按回车,连接网址,进入调试模式。

可以看到获得的请求为200,表明网址连接请求成功。
然而,对于Scrapy刚使用者来说,网址的请求常常失败(403),这是由于Scrapy并不是浏览器,在请求连接网址时会被拒绝,因此我们需要设置请求头,添加Chrome浏览器的请求头使网址将Scrapy识别为浏览器从而允许访问。为此我们要修改Scrapy中user-agent的默认值:
找到python的安装目录下的default_settings.py文件(例如我的是"D:\Program Files (x86)\Python36_64\Lib\site-packages\scrapy\settings\default_settings.py”),将USER_AGENT = ‘Scrapy/%s (+http://scrapy.org)’ % import_module(‘scrapy’).__version__修改为USER_AGENT = ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36’

这样就可以正常访问了。
2.获取内容:
接下来我将使用Scrapy支持的xpath方法来提取拉勾网中数据挖掘招聘信息的内容。
首先在命令行输入sel.response来获取响应

然后我们就可以使用xpath方法了。我们要先用xpath提取大标签,以便于后续循环提取大标签中的每一个内容
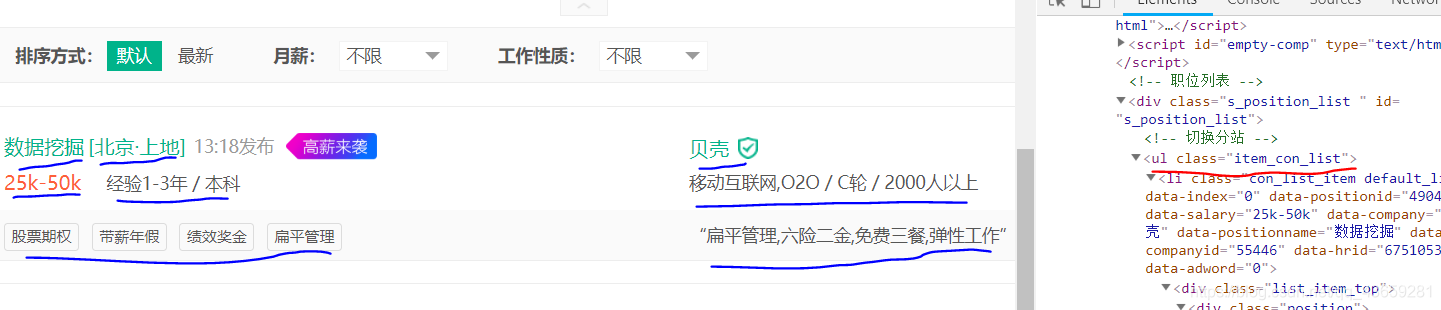
通过检查元素,获得大标签为//ul[@class=“item_con_list”],在命令行输入:

con为所有大标签组成的列表,下一步将在con中提取大标签所包含的内容(职位名称,工作地点,薪酬,工作要求,所属标签,公司名,公司简介,工作待遇)。
输入:

可以看到职位名称以列表的方式显示出来,我们还可以使用extract()方法提取关键内容:

提取到的内容更简洁了吧。
用同样的方法提取到其他内容:
工作地点:

薪酬:
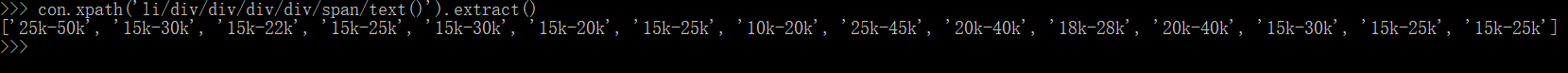
工作要求:

这个提取的内容有点问题,每个大标签中多提取了两个“\n”,在实际爬虫时可以用正则的方法来避免这个问题。
工作标签:

公司名称:

公司简介:

最后是工作待遇:

以上就是我所介绍的Scrapy shell的简单使用方法。在爬虫实战中,我们常常先注意的是提取内容的方法(Beautifulsoup,正则,xpath等)和内容所属地址的提取,而Scrapy shell正可以将提取内容代码运行的结果实时显示出来,以便于修改和调试代码,这样大大提高了获得数据提取方法的效率。
当然Scrapy shell不仅仅只有这点用法,更多的用法还需不断探索。














 2149
2149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









