







目录
- 模型结构详解
- 数学原理与推导
- 代表性变体及改进
- 应用场景与优缺点
- PyTorch代码示例
1. 模型结构详解
1.1 核心架构
输入序列 → 词嵌入 → 位置编码 → 编码器堆叠 → 解码器堆叠 → 输出序列
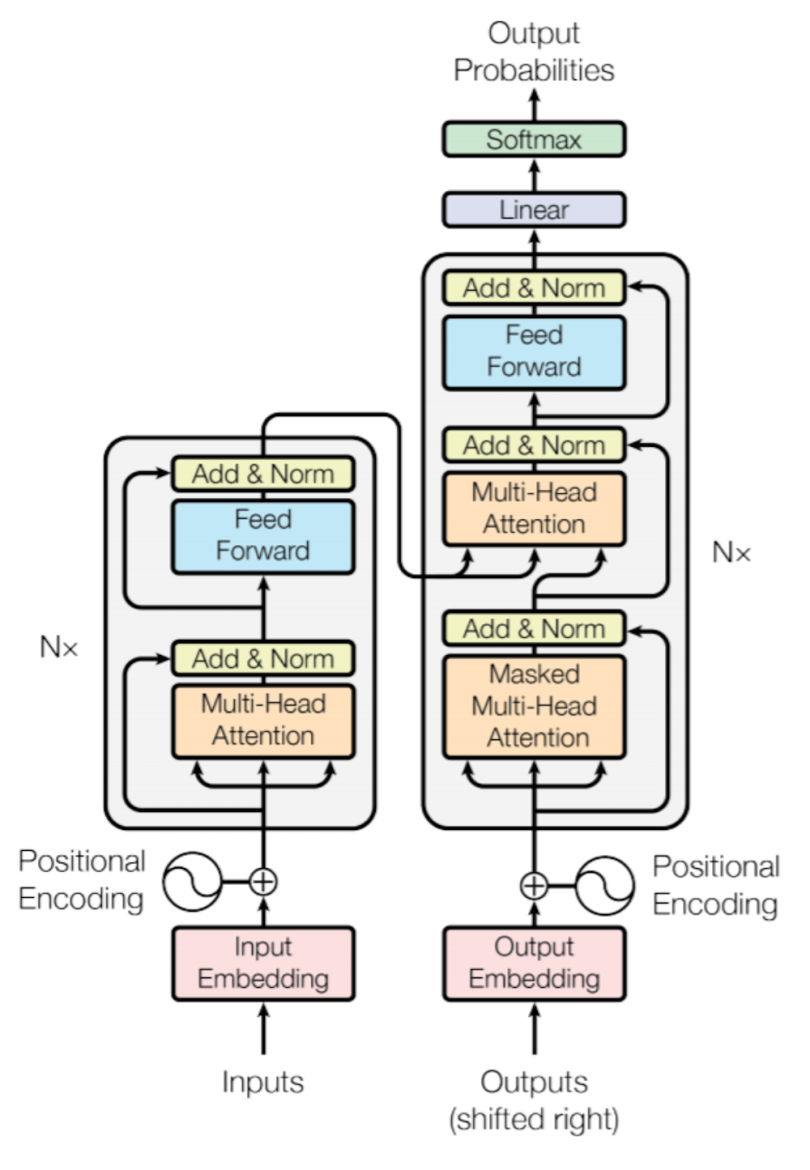
1.1.1 编码器-解码器结构
- 编码器:由N个相同层堆叠,每层含 多头自注意力 + 前馈网络
- 解码器:在编码器基础上增加 交叉注意力 层,用于关注编码器输出
1.1.2 核心组件
- 自注意力机制:计算序列元素间依赖关系
- 位置编码:注入序列位置信息(正弦函数或学习式)
- 残差连接 & 层归一化:每子层后应用
1.1.3 输入输出
- 输入:Token序列(如文本词ID或图像分块)
- 输出:
- 自回归任务(如GPT):逐个生成Token
- 非自回归任务(如BERT):全序列并行输出
2. 数学原理与推导
2.1 自注意力计算

其中:
- Q∈Rn×dk:查询矩阵
- K∈Rm×dk:键矩阵
- V∈Rm×dv:值矩阵
2.2 多头注意力
2.3 位置编码(正弦式)
2.4 前馈网络
3. 代表性变体及改进
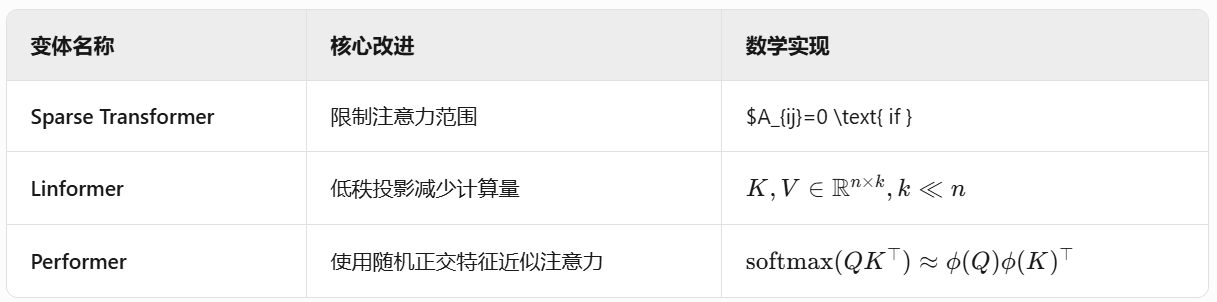
3.1 高效型Transformer
3.2 领域专用型Transformer
3.2.1 BERT(双向编码)
- 结构:仅编码器,MLM(掩码语言模型)+ NSP(下一句预测)
- 位置编码:可学习式
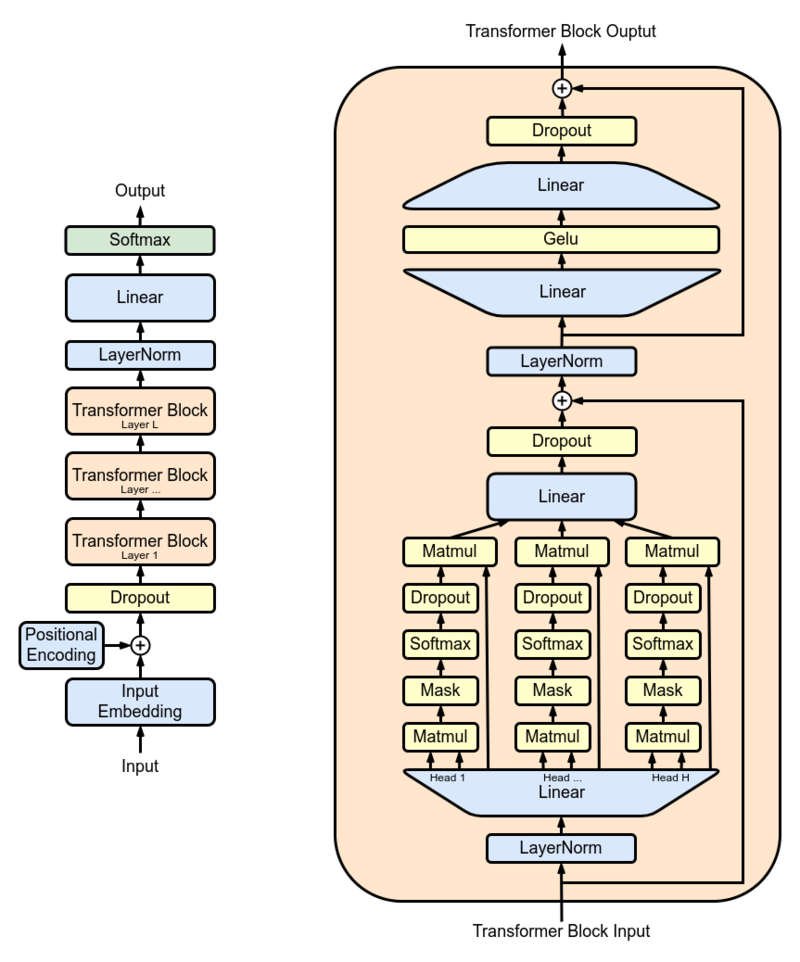
3.2.2 GPT系列(自回归解码)
- 结构:仅解码器,单向注意力掩码
- 训练目标:语言建模(最大似然估计)
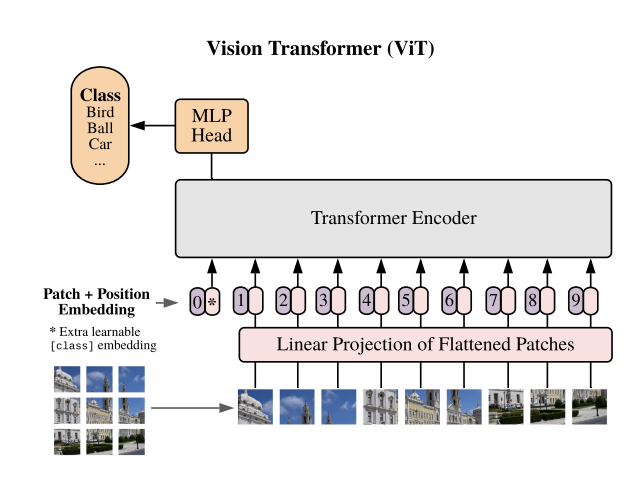
3.2.3 Vision Transformer (ViT)
- 输入处理:将图像分割为16x16块,线性投影为序列
- 分类头:添加可学习[CLS] Token
3.3 多模态Transformer
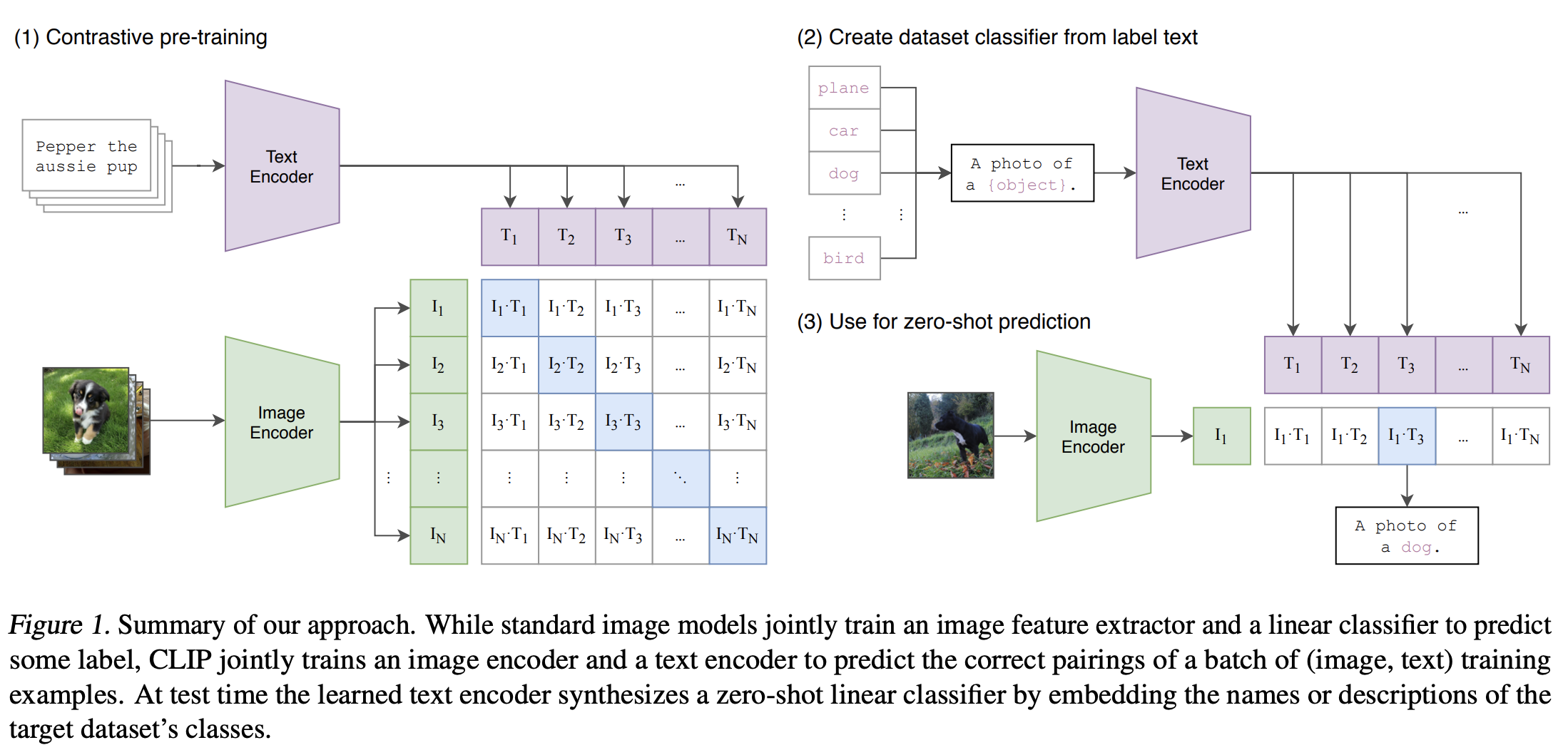
3.3.1 CLIP
- 双编码器:图像+文本编码器,对比学习对齐
- 损失函数:
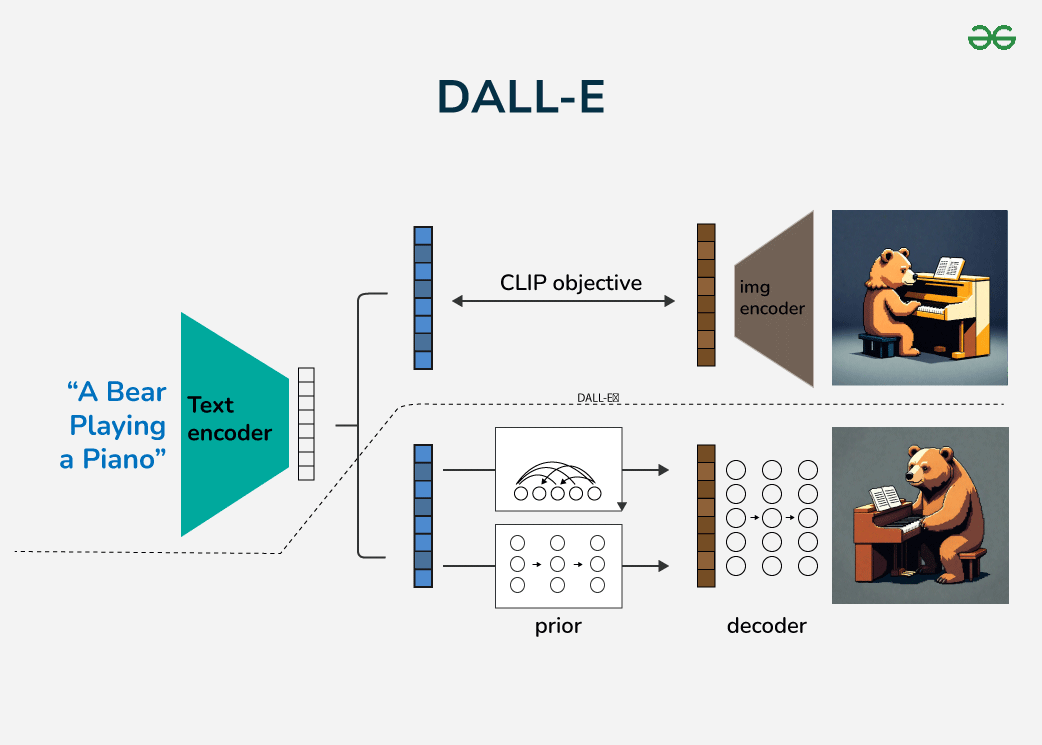
3.3.2 DALL-E
- 两阶段训练:
- 离散VAE压缩图像为Token
- Transformer建模文本-图像Token关系
4. 应用场景与优缺点
4.1 应用场景
| 领域 | 任务示例 |
|---|---|
| NLP | 机器翻译、文本摘要、问答系统 |
| CV | 图像分类、目标检测、图像生成 |
| 多模态 | 图文检索、视频描述生成 |
4.2 优缺点对比
| 优点 | 缺点 |
|---|---|
| 并行计算效率高 | 自注意力计算复杂度O(n²) |
| 长距离依赖建模能力强 | 需要大量训练数据 |
| 灵活适配多模态任务 | 位置编码对长度外推能力有限 |
5. PyTorch代码示例
import torch
import torch.nn as nn
from torch.nn import Transformer
class TransformerModel(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, nhead=8, num_layers=6):
super().__init__()
self.encoder_embed = nn.Embedding(src_vocab_size, d_model)
self.decoder_embed = nn.Embedding(tgt_vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model)
self.transformer = Transformer(d_model, nhead, num_layers)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
src = self.pos_encoder(self.encoder_embed(src))
tgt = self.pos_encoder(self.decoder_embed(tgt))
output = self.transformer(src, tgt, src_mask, tgt_mask)
return self.fc_out(output)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(1), :]
return x
# 示例:机器翻译任务
model = TransformerModel(src_vocab_size=10000, tgt_vocab_size=8000)
src = torch.randint(0, 10000, (32, 50)) # batch_size=32, 序列长度=50
tgt = torch.randint(0, 8000, (32, 40))
output = model(src, tgt)核心总结
- 架构革命:完全基于注意力机制,摆脱RNN/CNN的局部归纳偏置
- 数学本质:通过Query-Key-Value映射实现全局关系建模
- 演进方向:
- 效率优化(稀疏注意力、线性复杂度)
- 多模态融合(图文/音视频联合建模)
- 提示学习(Prompt Tuning)适配下游任务

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









