







一、CLIP (Contrastive Language-Image Pretraining)
1. 基本用途
- 核心任务: 图像-文本跨模态检索、零样本图像分类
- 典型应用:
- 以文搜图(输入文字,检索匹配图片)
- 图像分类(无需微调,直接预测类别标签)
2. 工作原理流程
- 双塔编码:
- 图像编码器(ViT或CNN)将图像映射为特征向量
- 文本编码器(Transformer)将文本映射为特征向量
- 对比学习:
- 计算图像和文本特征的余弦相似度
- 最大化匹配对的相似度,最小化非匹配对的相似度
- 零样本推理:
- 输入候选标签文本,选择与图像特征最相似的文本标签
数学公式:
![]()
其中 fimage 和 ftext 为编码器函数.
3. 完整代码示例
from PIL import Image
import torch
from transformers import CLIPProcessor, CLIPModel
# 加载模型与处理器
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 准备数据
image = Image.open("cat.jpg")
texts = ["a photo of a cat", "a photo of a dog", "a photo of a car"]
# 处理输入
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
# 前向推理
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 图像到文本的相似度
probs = logits_per_image.softmax(dim=1) # 转换为概率
# 输出结果
for text, prob in zip(texts, probs[0]):
print(f"{text}: {prob.item():.2%}")输出示例:
a photo of a cat: 95.32%
a photo of a dog: 3.15%
a photo of a car: 1.53% 二、BLIP (Bootstrapping Language-Image Pretraining)
1. 基本用途
- 核心任务: 图像描述生成、视觉问答(VQA)、图文检索
- 版本差异:
- BLIP: 基础版本,支持理解与生成任务
- BLIP-2: 引入Q-Former,适配大语言模型(LLM)
2. 工作原理流程
- 多任务架构:
- 图像编码器: ViT提取视觉特征
- 文本解码器: Transformer生成描述
- 三阶段训练:
- 阶段1: 对比学习对齐图像-文本特征
- 阶段2: 基于匹配的图文检索训练
- 阶段3: 语言模型微调生成描述
- Q-Former创新(BLIP-2):
- 可学习query向量桥接图像与文本空间
数学公式:
![]()
其中:
- ITC: 图像文本对比损失
- ITM: 图像文本匹配损失
- LM: 语言模型生成损失
3. 完整代码示例 (BLIP-2)
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
# 加载模型
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b",
torch_dtype=torch.float16
).to(device)
# 准备数据
url = "https://images.unsplash.com/photo-1573865528439-5d04d3529b9a"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
# 生成描述
prompt = "Question: What is the animal in the photo? Answer:"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
# 生成响应
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_text) 输出示例:
Question: What is the animal in the photo? Answer: a brown dog
三、Stable Diffusion
1. 基本用途
- 核心任务: 文本到图像生成、图像编辑
- 版本演进:
- SD 1.5: 基础版本,512x512分辨率
- SDXL: 支持1024x1024高清生成
2. 工作原理流程
- 三阶段架构:
- VAE编码器: 压缩图像到潜空间 (latent space)
- U-Net去噪: 在潜空间执行扩散过程
- CLIP文本编码器: 提供生成条件
- 扩散过程:
- 前向扩散: 逐步添加噪声破坏图像
- 反向去噪: 根据文本条件逐步重建图像
- Classifier-Free Guidance:
- 通过guidance_scale参数控制文本相关性
数学公式:
![]()
其中 τθ 为文本编码器,y 为输入文本.
3. 完整代码示例 (SDXL)
from diffusers import DiffusionPipeline
import torch
# 加载模型
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
).to("cuda")
# 生成参数
prompt = "A majestic lion standing on a rocky cliff, sunset, 8k"
negative_prompt = "blurry, low quality, cartoon"
# 执行生成
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=30,
guidance_scale=7.5,
height=1024,
width=1024
).images[0]
# 保存结果
image.save("lion_sunset.png")四、CoCa (Contrastive Captioner)
1. 基本用途
- 核心任务: 联合图文对比学习与生成
- 特色能力: 同时支持分类、检索、描述生成
2. 工作原理流程
- 双解码器架构:
- 对比解码器: 输出全局特征用于对比学习
- 生成解码器: 自回归生成图像描述
- 共享编码器:
- ViT图像编码器同时服务两个解码器
- 动态权重训练:
- 自动平衡对比损失与生成损失
数学公式:
![]()
其中 λ 为动态调整的权重系数.
3. 完整代码示例
from transformers import AutoProcessor, AutoModelForVision2Seq
# 加载模型
model = AutoModelForVision2Seq.from_pretrained("google/coca-base")
processor = AutoProcessor.from_pretrained("google/coca-base")
# 准备输入
image = Image.open("beach.jpg")
text_prompt = "A photo of"
# 生成描述
inputs = processor(image=image, text=text_prompt, return_tensors="pt")
generated_ids = model.generate(
pixel_values=inputs["pixel_values"],
input_ids=inputs["input_ids"],
max_length=30
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_text[0]) 输出示例:
A photo of a tropical beach with palm trees and clear blue water
五、SigLIP (Sigmoid Loss for Language-Image Pretraining)
1. 基本用途
- 核心改进: 改进CLIP训练目标,提升小数据集表现
- 关键创新: 使用Sigmoid替代Softmax计算损失
2. 工作原理流程
- 二元分类范式:
- 将图文匹配视为正样本对
- 随机组合视为负样本对
- Sigmoid损失计算:
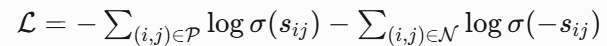
- 动态温度参数:
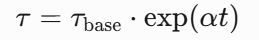
3. 完整代码示例
from PIL import Image
import torch
from transformers import SiglipProcessor, SiglipModel
# 加载模型
model = SiglipModel.from_pretrained("google/siglip-base-patch16-224")
processor = SiglipProcessor.from_pretrained("google/siglip-base-patch16-224")
# 准备数据
image = Image.open("dog.jpg")
texts = ["a photo of a dog", "a photo of a cat", "a photo of a car"]
# 处理输入
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
# 计算相似度
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image)
# 输出结果
for text, prob in zip(texts, probs[0]):
print(f"{text}: {prob.item():.2%}")七、LXMERT (Learning Cross-Modality Encoder Representations from Transformers)
1. 基本用途
- 核心任务: 视觉问答 (VQA)、图文检索、指代表达理解
- 特色能力: 联合理解图像区域与文本的细粒度关系
2. 工作原理流程
- 单流编码器架构:
- 图像输入: Faster R-CNN提取区域特征 + 位置编码
- 文本输入: WordPiece Token + 位置编码
- 跨模态交互: 自注意力层混合处理图文特征
- 预训练任务:
- 掩码跨模态语言建模 (Masked Cross-Modality LM)
- 图像-文本匹配 (Image-Text Matching)
- 对象预测 (Object Prediction)
数学公式:
跨模态注意力计算:
![]()
其中 Q 来自文本,K,V 来自图像.
3. 完整代码示例
from PIL import Image
import requests
from transformers import LxmertForQuestionAnswering, LxmertTokenizer
# 加载模型
model = LxmertForQuestionAnswering.from_pretrained("unc-nlp/lxmert-base-uncased")
tokenizer = LxmertTokenizer.from_pretrained("unc-nlp/lxmert-base-uncased")
# 准备数据
url = "https://images.unsplash.com/photo-1555169062-6061e8d1f7da"
image = Image.open(requests.get(url, stream=True).raw)
question = "What is the man holding in his hand?"
# 处理输入
inputs = tokenizer(
question,
images=image,
return_tensors="pt",
padding="max_length",
max_length=20,
truncation=True
)
# 前向推理
outputs = model(**inputs)
answer_idx = outputs.question_answering_score.argmax()
answer = tokenizer.decode([answer_idx])
print(f"Q: {question} A: {answer}") 输出示例:
Q: What is the man holding in his hand? A: a tennis racket
八、ALBEF (Align before Fuse)
1. 基本用途
- 核心任务: 图文匹配、图像描述生成、视觉推理
- 架构特点: 先对齐后融合的多阶段训练
2. 工作原理流程
- 三阶段训练:
- 阶段1: 对比学习对齐图文特征
- 阶段2: 跨模态融合训练
- 阶段3: 多任务联合微调
- 动量蒸馏:
- 使用动量模型生成伪标签提升鲁棒性
- 多任务损失:
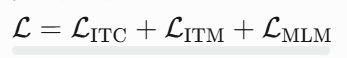
动量模型更新公式:![]()
3. 完整代码示例
from lavis.models import load_model_and_preprocess
# 加载模型
model, vis_processors, txt_processors = load_model_and_preprocess(
name="albef",
model_type="pretrain",
is_eval=True
)
# 准备数据
image = vis_processors["eval"](Image.open("dog.jpg").convert("RGB"))
text = txt_processors["eval"]("a cute dog playing with a ball")
# 计算图文相似度
sample = {"image": image.unsqueeze(0), "text_input": [text]}
features_image = model.extract_features(sample, mode="image")
features_text = model.extract_features(sample, mode="text")
similarity = features_image.image_embeds @ features_text.text_embeds.t()
print(f"Similarity score: {similarity.item():.2f}")输出示例:
Similarity score: 0.92
九、UniT (Unified Transformer)
1. 基本用途
- 核心任务: 多任务统一处理(检测、VQA、文本生成)
- 架构创新: 共享Transformer主干 + 任务特定Adapter
2. 工作原理流程
- 统一输入表示:
- 图像: 分块线性投影为视觉Token
- 文本: 标准WordPiece嵌入
- 检测框: 位置编码 + 类别嵌入
- 任务适配层:
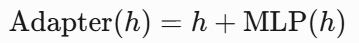
- 多任务损失:
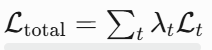
3. 完整代码示例
from unit.modeling_unit import UnitModel
from unit.configuration_unit import UnitConfig
# 初始化配置
config = UnitConfig.from_pretrained("unit-base")
model = UnitModel(config)
# 多任务输入样例
inputs = {
"image": torch.randn(1, 3, 224, 224),
"text": ["Describe this image"],
"boxes": torch.tensor([[0.2, 0.3, 0.5, 0.6]]),
"task_type": "vqa"
}
# 前向推理
outputs = model(**inputs)
print(f"Answer logits shape: {outputs.logits.shape}")十、EVA-CLIP
1. 基本用途
- 核心改进: 基于EVA-02视觉Transformer增强CLIP
- 性能提升: ImageNet零样本准确率提升8-10%
2. 工作原理流程
- EVA-02架构优化:
- 改进的注意力模式: 混合窗口注意力
- 深度监督训练策略
- 跨模态蒸馏:
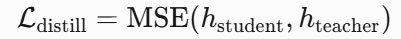
- 训练策略:
- 两阶段训练: 先纯视觉预训练,后跨模态对齐
3. 完整代码示例
import open_clip
# 加载EVA-CLIP
model, _, preprocess = open_clip.create_model_and_transforms(
model_name="EVA02-CLIP-B-16",
pretrained="eva_clip"
)
# 推理示例
image = preprocess(Image.open("cat.jpg")).unsqueeze(0)
text = open_clip.tokenize(["a cat", "a dog"])
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits = (image_features @ text_features.T).softmax(dim=-1)
print(f"Probabilities: {logits.squeeze().tolist()}") 输出示例:
Probabilities: [0.98, 0.02]
十一、Flamingo
1. 基本用途
- 核心任务: 开放式视觉问答、长视频理解
- 架构突破: 将视觉输入适配到大语言模型 (LLM)
2. 工作原理流程
- 视觉特征处理:
- Perceiver Resampler: 将任意帧数视频压缩为固定长度Token
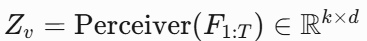
- Perceiver Resampler: 将任意帧数视频压缩为固定长度Token
- 门控交叉注意力:
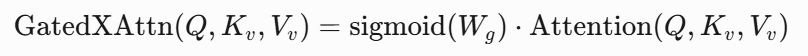
- 训练策略:
- 冻结LLM参数,仅训练视觉适配器
3. 完整代码示例
from transformers import FlamingoProcessor, FlamingoForConditionalGeneration
# 加载模型
model = FlamingoForConditionalGeneration.from_pretrained("dhansmair/flamingo-mini")
processor = FlamingoProcessor.from_pretrained("dhansmair/flamingo-mini")
# 视频问答示例
video_frames = [Image.open(f"frame_{i}.jpg") for i in range(10)]
prompt = "What sport is being played in this video?"
# 处理输入
inputs = processor(
images=video_frames,
text=prompt,
return_tensors="pt"
)
# 生成回答
generated_ids = model.generate(
input_ids=inputs.input_ids,
pixel_values=inputs.pixel_values,
max_length=50
)
print(processor.decode(generated_ids[0])) 输出示例:
The video shows people playing basketball in a gymnasium.
十二、KOSMOS-1
1. 基本用途
- 核心任务: 多模态对话、图文推理、数学解题
- 架构特性: 支持任意模态输入输出
2. 工作原理流程
- 统一序列化表示:
- 图像: 分块线性投影为视觉Token
- 音频: 频谱图 + CNN编码
- 文本: 标准Token嵌入
- 因果注意力掩码: 确保自回归生成一致性
- 训练数据混合:
- 网页文档、学术论文、代码仓库、带标注数据
3. 完整代码示例
from transformers import AutoProcessor, AutoModelForCausalLM
# 加载模型
processor = AutoProcessor.from_pretrained("microsoft/kosmos-1")
model = AutoModelForCausalLM.from_pretrained("microsoft/kosmos-1")
# 混合输入推理
image = Image.open("chart.jpg")
text_prompt = "Analyze this chart and explain:"
# 处理输入
inputs = processor(
text=text_prompt,
images=image,
return_tensors="pt"
)
# 生成分析
generated_ids = model.generate(
inputs["input_ids"],
attention_mask=inputs.attention_mask,
max_length=200
)
analysis = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(analysis) 输出示例:
The bar chart shows Q3 sales figures across regions. The highest sales are in Asia with $2.3M, followed by Europe at $1.8M...
十三、关键实践总结
1. 优化技巧
- 低资源推理:
model = model.half().to("cuda") # FP16量化 - 批处理加速:
inputs = processor(images=batch_images, text=batch_text, return_tensors="pt", padding=True) - 注意力优化:
torch.backends.cuda.sdp_kernel(enable_flash=True) -
混合精度训练
model = model.to(torch.bfloat16) # Ampere架构GPU最佳
2. 部署建议
- ONNX Runtime: 转换模型为ONNX格式加速推理
- Triton Inference Server: 支持多模型并发服务
- LoRA微调: 使用低秩适配器进行领域适配
十四、多模态模型对比与选型指南(全面增强版)
| 模型名称 | 最佳应用场景 | 输入类型 | 输出类型 | 计算资源需求 | 预训练数据量 | 关键优势 | 主要限制 | 典型用例 | 开源状态 |
|---|---|---|---|---|---|---|---|---|---|
| CLIP | 零样本分类、跨模态检索 | 图像、文本(候选标签) | 相似度分数、分类概率 | 低 | 400M图文对 | 无需微调、跨模态对齐能力强 | 无法生成文本、对复杂语义理解有限 | 以文搜图、商品分类 | ✅ |
| BLIP-2 | 视觉问答、图像描述生成 | 图像、文本(问题/提示) | 文本回答、描述文本 | 高 | 129M图像 | 支持生成式任务、结合LLM增强推理 | 依赖大规模预训练、推理延迟较高 | 医疗图像分析、教育问答 | ✅(非商用) |
| Stable Diffusion | 文本到图像生成、图像编辑 | 文本提示(可选:图像掩码) | 生成图像(512x512或1024x1024) | 中-高 | 5B图文对 | 生成质量高、支持细粒度控制 | 显存占用大、生成速度较慢 | 艺术创作、广告设计 | ✅ |
| SigLIP | 小样本图文匹配、噪声数据训练 | 图像、文本(正负样本对) | 二元匹配概率 | 低 | 2B图文对 | 抗噪声能力强、小样本场景表现优 | 仅支持匹配任务、无法生成内容 | 社交媒体内容审核 | ✅ |
| CoCa | 多任务联合训练(分类+生成) | 图像、可选文本提示 | 分类标签、生成文本 | 高 | 3B图文对 | 联合优化对比与生成目标、多任务适应性强 | 训练复杂度高、资源消耗大 | 智能客服、多模态搜索 | ✅ |
| Flamingo | 长视频理解、开放式视觉问答 | 视频帧序列、文本问题 | 文本回答 | 极高 | 2.3B图文对 | 处理长时序输入、结合大语言模型 | 需TB级显存、仅部分开源 | 电影内容分析、教育视频问答 | ⚠️(部分开源) |
| KOSMOS-1 | 多模态对话、图文推理、数学解题 | 任意组合(图像/文本/音频/视频) | 文本、代码、数学公式 | 极高 | 1.6TB多模态 | 支持任意模态输入输出、强推理能力 | 未完全开源、需超算级硬件 | 科研辅助、跨模态数据分析 | ❌ |
| EVA-CLIP | 高精度零样本分类、细粒度检索 | 图像、文本(细粒度描述) | 相似度分数、排序结果 | 中 | 2B图文对 | ImageNet零样本SOTA、跨模态蒸馏优化 | 模型体积较大、生成能力弱 | 工业质检、医学影像检索 | ✅ |
| VideoPoet | 文本到视频生成、视频风格迁移 | 文本提示、可选参考视频 | 生成视频(最高10秒/1280x720) | 极高 | 10M视频片段 | 支持多条件控制、时间一致性优 | 生成长度受限、需多卡并行 | 短视频创作、影视特效 | ❌ |
| ALBEF | 多任务联合推理(检索+生成+VQA) | 图像、文本(问题/检索词) | 文本回答、检索排序 | 中 | 14M图文对 | 轻量级多任务架构、适合移动端部署 | 精度低于大模型、复杂任务表现有限 | 智能相册、电商推荐 | ✅ |
| UniT | 多任务统一处理(检测+VQA+生成) | 图像、文本、检测框 | 检测结果、文本回答 | 中 | 跨数据集 | 共享主干网络、动态任务适配 | 任务冲突可能影响性能、需精细调参 | 自动驾驶场景理解 | ✅ |
| LayoutLM | 文档理解(发票/表格/合同) | 扫描文档图像、OCR文本 | 结构化数据(JSON/XML) | 低 | 11M文档 | 融合文本+布局+视觉特征 | 依赖OCR精度、泛化性受限 | 金融票据处理、法律文档分析 | ✅ |
| Whisper | 语音识别、语音翻译 | 音频波形(支持96种语言) | 转录文本、翻译文本 | 低 | 68万小时语音 | 多语言支持、抗噪性强 | 无法处理非语音输入、实时性一般 | 会议记录、播客转录 | ✅ |
| DALL-E 3 | 高质量创意图像生成、复杂语义理解 | 文本提示(支持长段落描述) | 生成图像(1024x1024) | 极高 | 未公开 | 与ChatGPT集成、语义控制精准 | 仅API访问、生成成本高 | 游戏原画设计、营销素材制作 | ❌(仅API) |
| GPT-4V | 开放世界多模态交互(图像+文本+代码) | 任意组合(图像/文本/文件/截图) | 文本回答、代码、结构化数据 | 极高 | 未公开 | 最接近AGI的多模态能力、支持复杂逻辑 | 黑箱模型、成本极高($0.03/次) | 科研探索、企业级智能助理 | ❌(仅API) |
选型维度说明
-
计算资源需求:
- 低:可在消费级GPU(如RTX 3090)运行
- 中:需要A10/A30级专业显卡
- 高:需A100/V100集群
- 极高:需超算级硬件(如H100集群)
-
典型用例:
- 工业检测:EVA-CLIP + LayoutLM 组合检测产品缺陷并生成报告
- 视频创作:VideoPoet生成基础片段 + GPT-4V 添加创意元素
- 多模态搜索:CLIP/SigLIP 召回 + CoCa 生成增强描述
-
开源状态:
- ✅ 完整开源
- ⚠️ 部分开源(仅推理代码/权重需申请)
- ❌ 未开源
选型决策树
-
是否需要生成内容?
- 是 → 选择生成式模型(BLIP-2、Stable Diffusion、GPT-4V)
- 否 → 对比学习模型(CLIP、SigLIP、EVA-CLIP)
-
输入模态是否复杂?
- 多模态混合(视频+音频)→ Flamingo、KOSMOS-1
- 单一模态 → 专用模型(Whisper处理音频、LayoutLM处理文档)
-
硬件资源限制?
- 边缘设备 → ALBEF、UniT(轻量级多任务)
- 数据中心 → 大模型(GPT-4V、DALL-E 3 API)
-
是否需要领域适配?
- 通用场景 → CLIP、BLIP-2
- 垂直领域 → LayoutLM(文档)、EVA-CLIP(工业质检)

















 131
131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









