







小白式教程,超详细 ,复现全过程以及出现的问题和对应解决方法。在自己电脑上复现的,非服务器复现,不过两者步骤差别不大。
一 安装配置anaconda(已装的可略过)
具体步骤参考 http://t.csdnimg.cn/d3Otl
二 配置项目虚拟环境
配置指令顺序、版本按项目文档中 READEME.md文件进行
1 打开Anaconda Prompt
2 创建环境 :输入 conda create -n poseformerv2 python=3.9 (poseformerv2为环境名,可自定义哦)
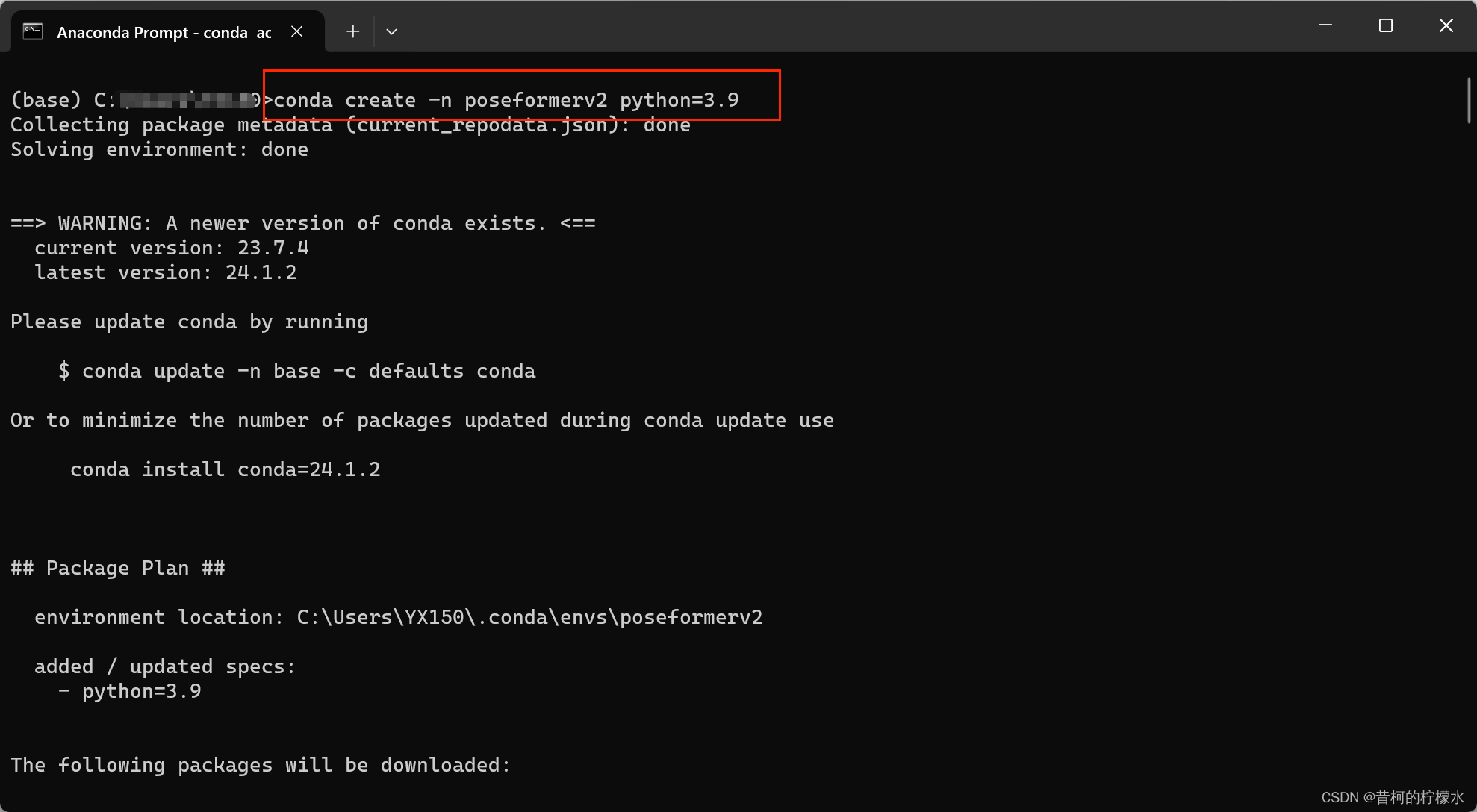
输入 y

3 激活项目环境 :输入 conda activate poseformerv2 ,前缀变为( poseformerv2)表示激活成功。

4 安装pytorch :输入 pip install torch==1.13.0+cu117 torchvision==0.14.0+cu117 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu117。

按照项目给出的配置指令我这出现了错误,安装成功的可以直接跳转下一步 5 配置 requirements.txt 文件。
满江红啊,,,主要原因是超时,,不过没关系,不走指令下载,我们直接下载原文件再安装也是可以的 >< 。
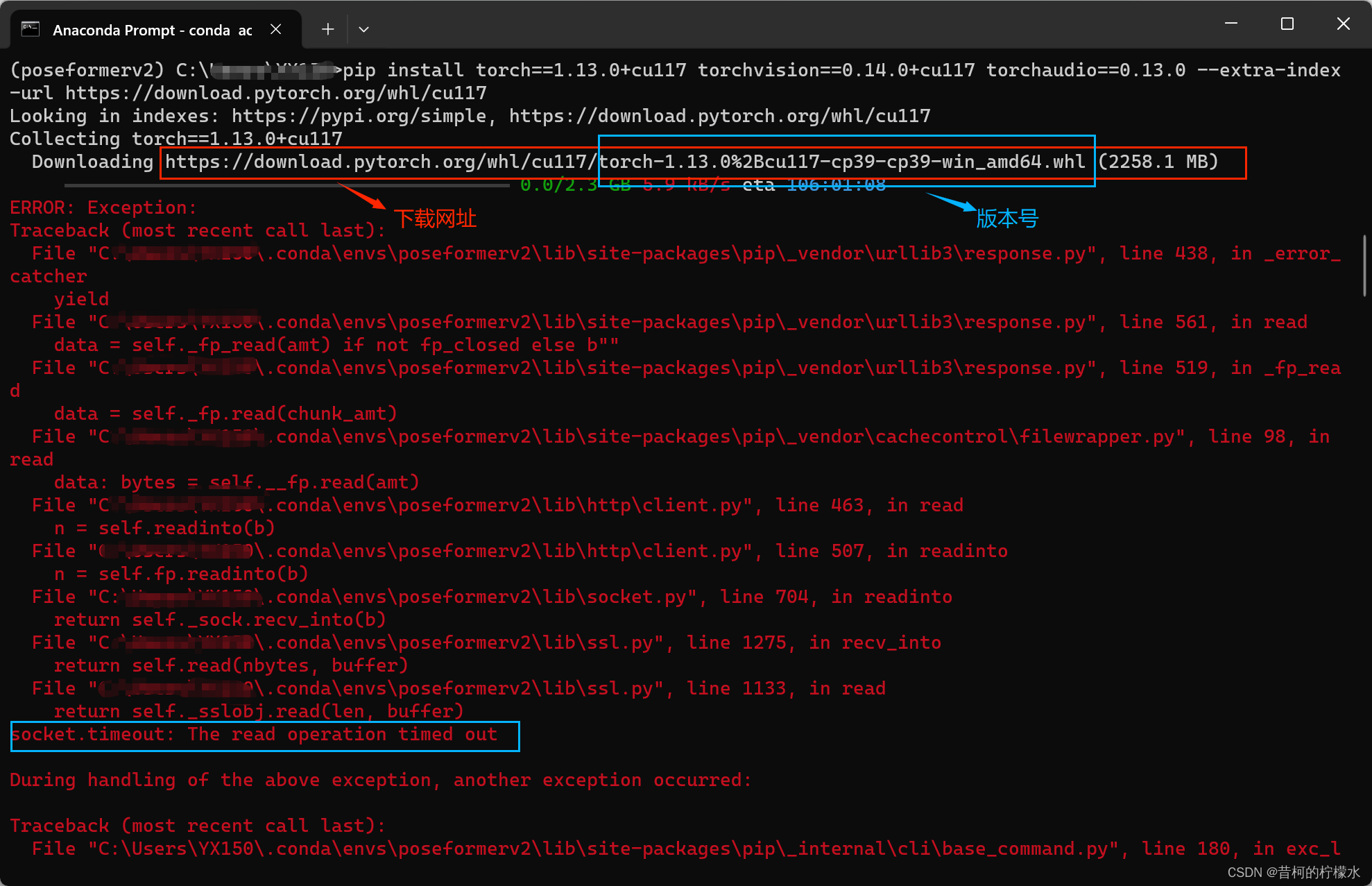
此处有两种下载方式。
(1)点击配置界面的提供的下载网址直接下载到本地
(2)或者点击 https://download.pytorch.org/whl/torch_stable.html 选择需要的版本号下载到本地(配置过程中有版本号信息)。
下载过程有点漫长~ 下载好后输入 pip install 此处替换为你自己文件的绝对路径 torchvision torchaudio

安装成功哈哈!!
5 配置 requirements.txt 文件(位置在项目代码文档里)。
直接输入指令 pip install -r requirements.txt的绝对路径(替换为自己的路径) ,配置出现了错误。

信息显示torch相关错误,这里我们去 requirements.txt 文件中将torch相关的35,37,38用 # 号注释掉。
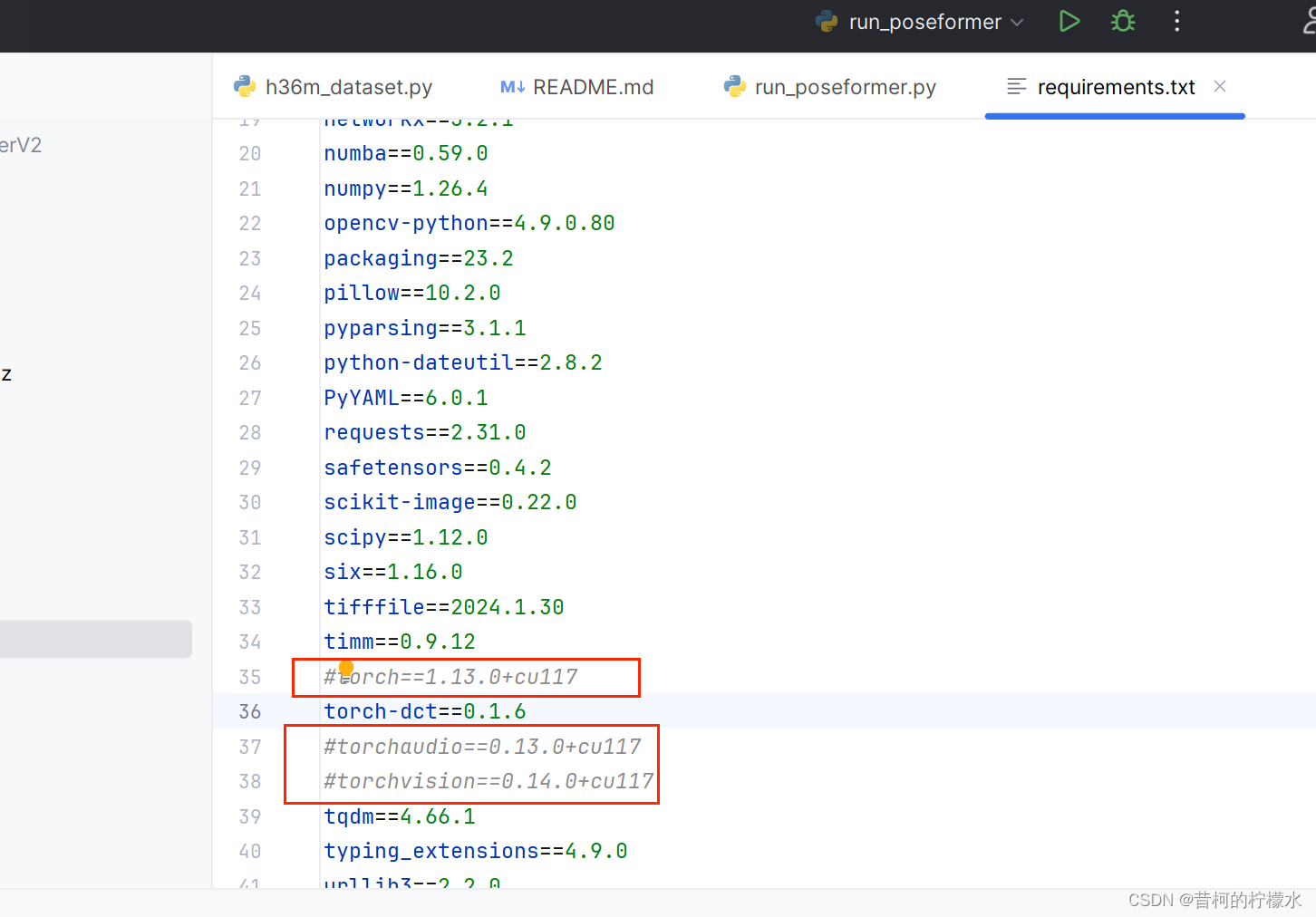
输入指令 pip install -r requirements.txt的绝对路径(替换为自己的路径),就可以成功啦!!!下图为我自己的路径,记得替换哦~

6 配置Pycharm。
用Pycharm打开项目文档,点击右下角 Add New Interpreter ,再点击 Add Local Interpreter...
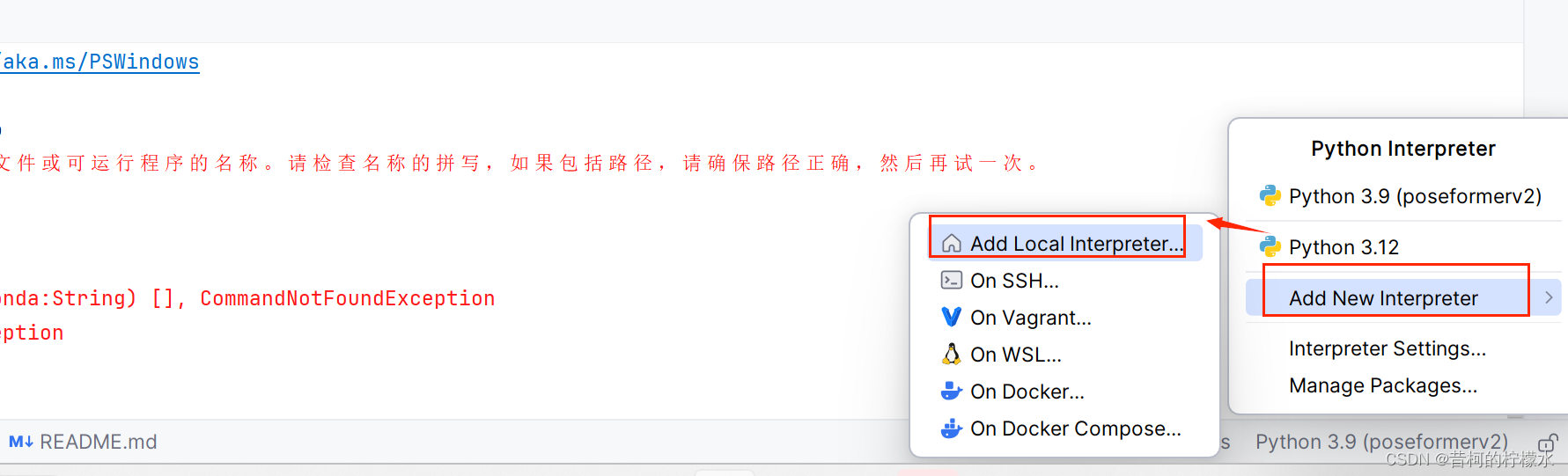
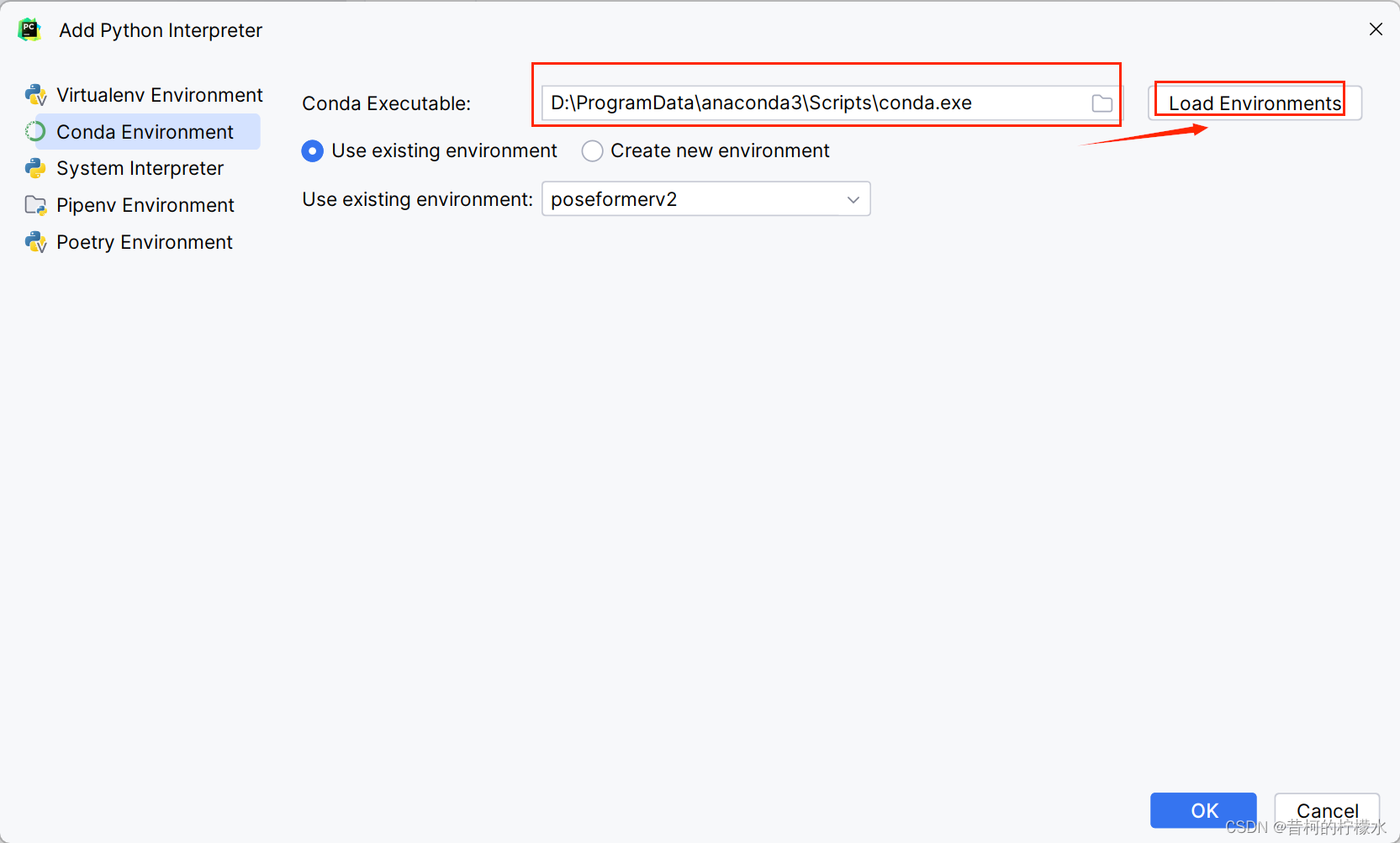
选择 Conda Environment , 再选择Use Existing ,再选择你anaconda安装目录下的conda.exe,j接着点击Load Environment ,接着你创建的项目的环境,最后点击OK,就完成啦!!!
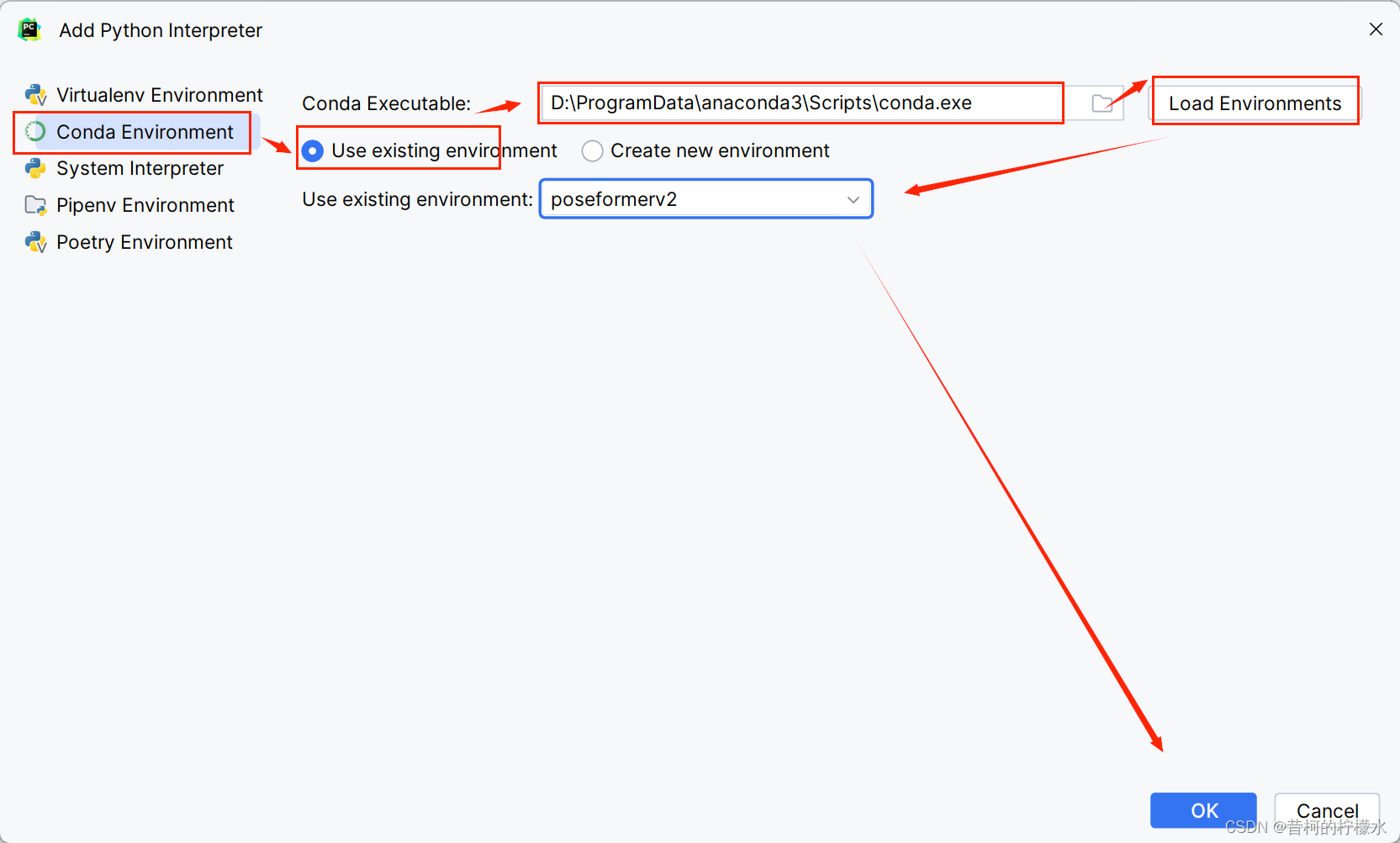
核对一下项目界面右下角信息
到这就配置完成啦!庆祝!!!
如果在配置中报错Conda executable is not found,请找到anaconda的安装目录,双击conda.exe
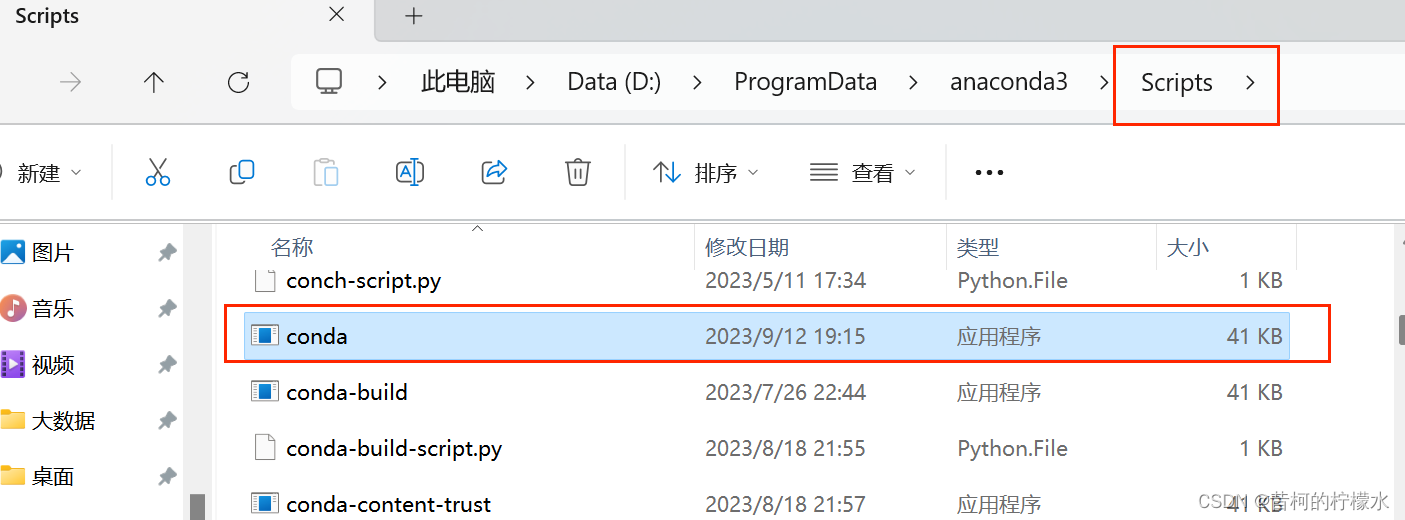
然后再复制conda.exe的地址到文件查找框里,再点击Load Environments,最后点击OK即可激活成功!!!
三 数据集下载
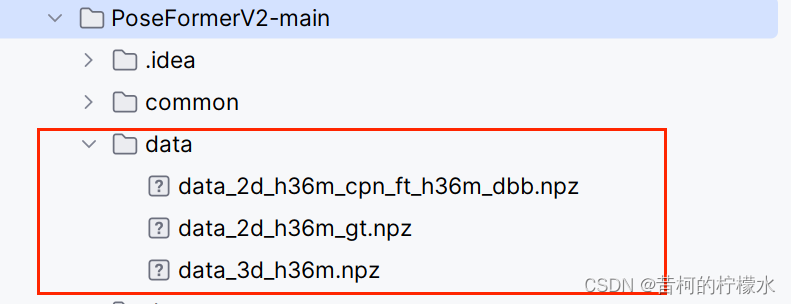
下载数据集 , 并保存到项目文挡中data(自己创建)目录下。
直接下载文件
data_2d_h36m_gt.npz data_2d_h36m_cpn_ft_h36m_dbb.npz data_3d_h36m.npz
或者自行复制下载地址,链接:https://pan.baidu.com/s/1ejE8THv_0IkXtiYRul0hPw
提取码:q03p
四 开始训练
(1)这里最简单的方法是,直接在README.md文件中点击运行按钮执行训练命令,就可以啦!!
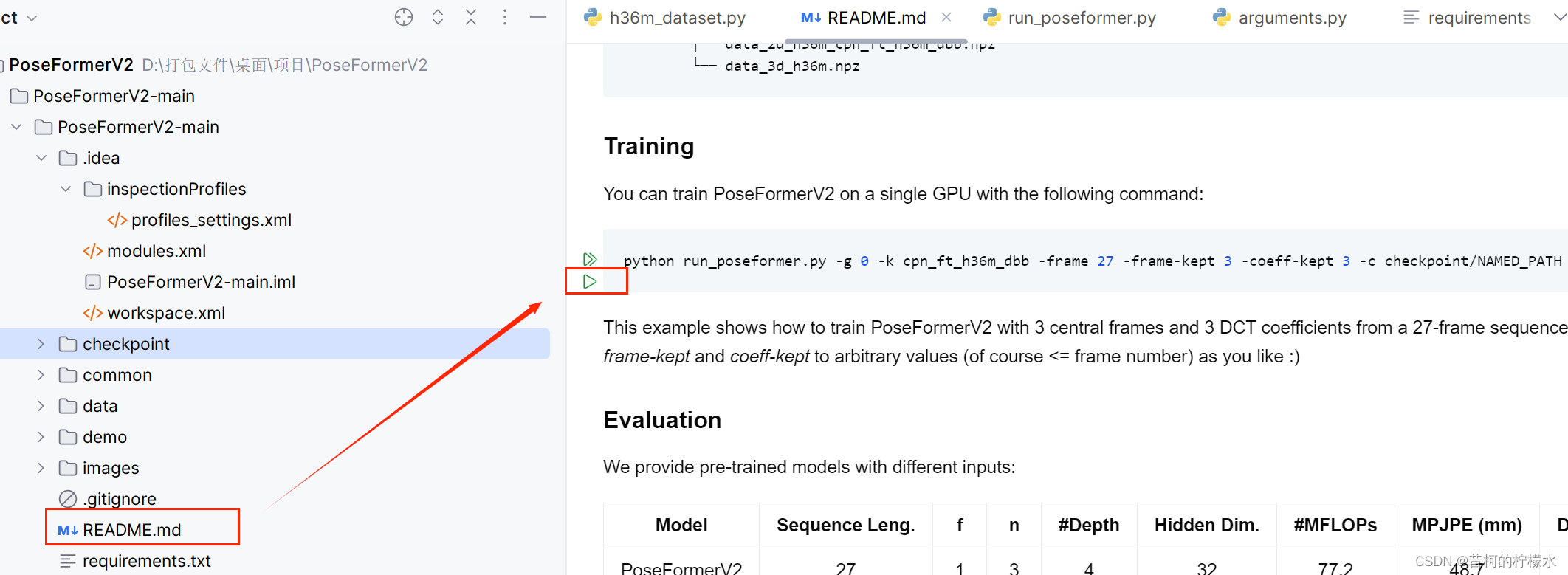
在我电脑上一个epoch大概18分钟,全程默认200个epoch。
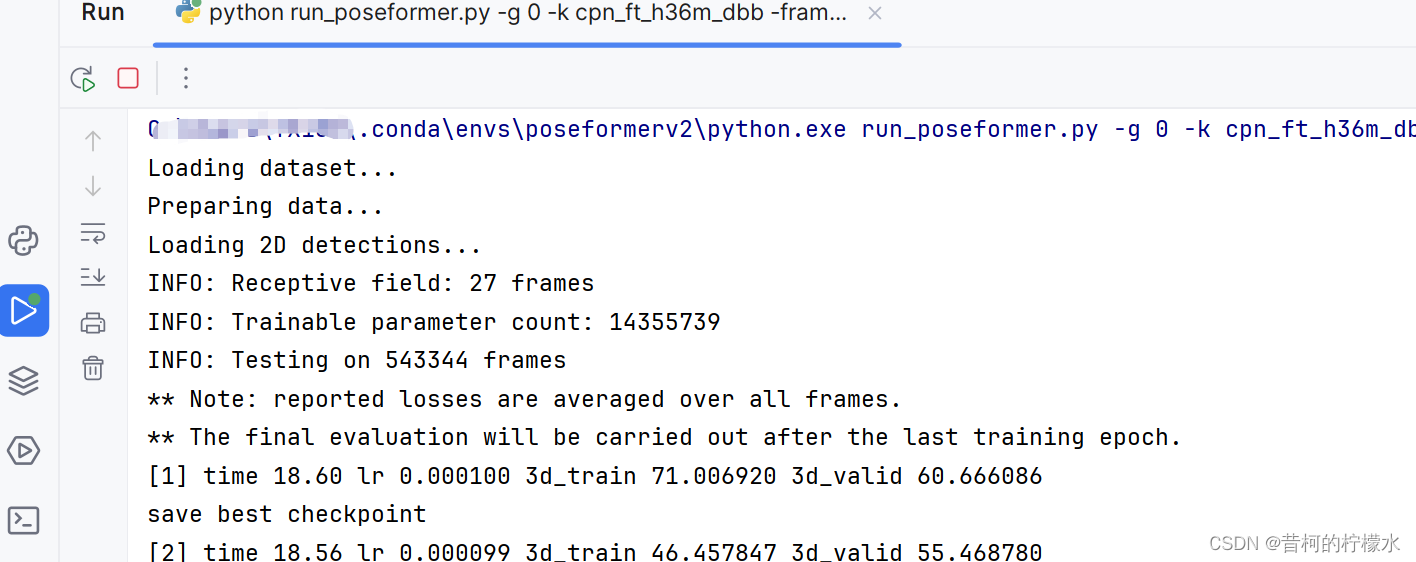
(2)第二种方法(第一种无问题的话,这个可略过)
复制README.md中的训练运行参数 -g 0 -k cpn_ft_h36m_dbb -frame 27 -frame-kept 3 -coeff-kept 3 -c checkpoint/NAMED_PATH

打开项目下的run_posrformer.py ,接着右击文件选择 More Run ,再选择 Modify Run Configuration 。
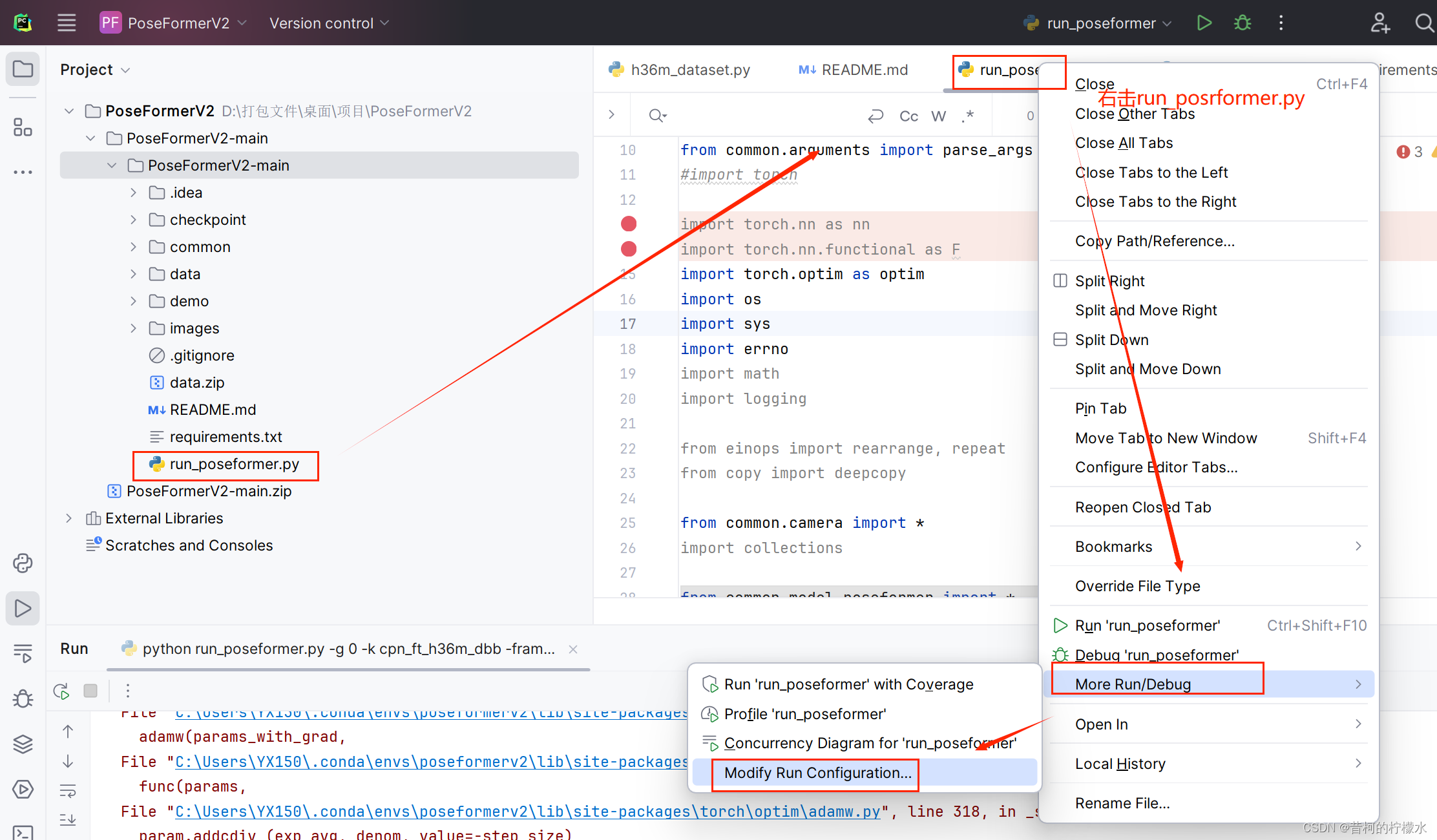
将 -g 0 -k cpn_ft_h36m_dbb -frame 27 -frame-kept 3 -coeff-kept 3 -c checkpoint/NAMED_PATH 复制到 对应框内 ,再选择Apply ,最后点击OK就完成啦!!!
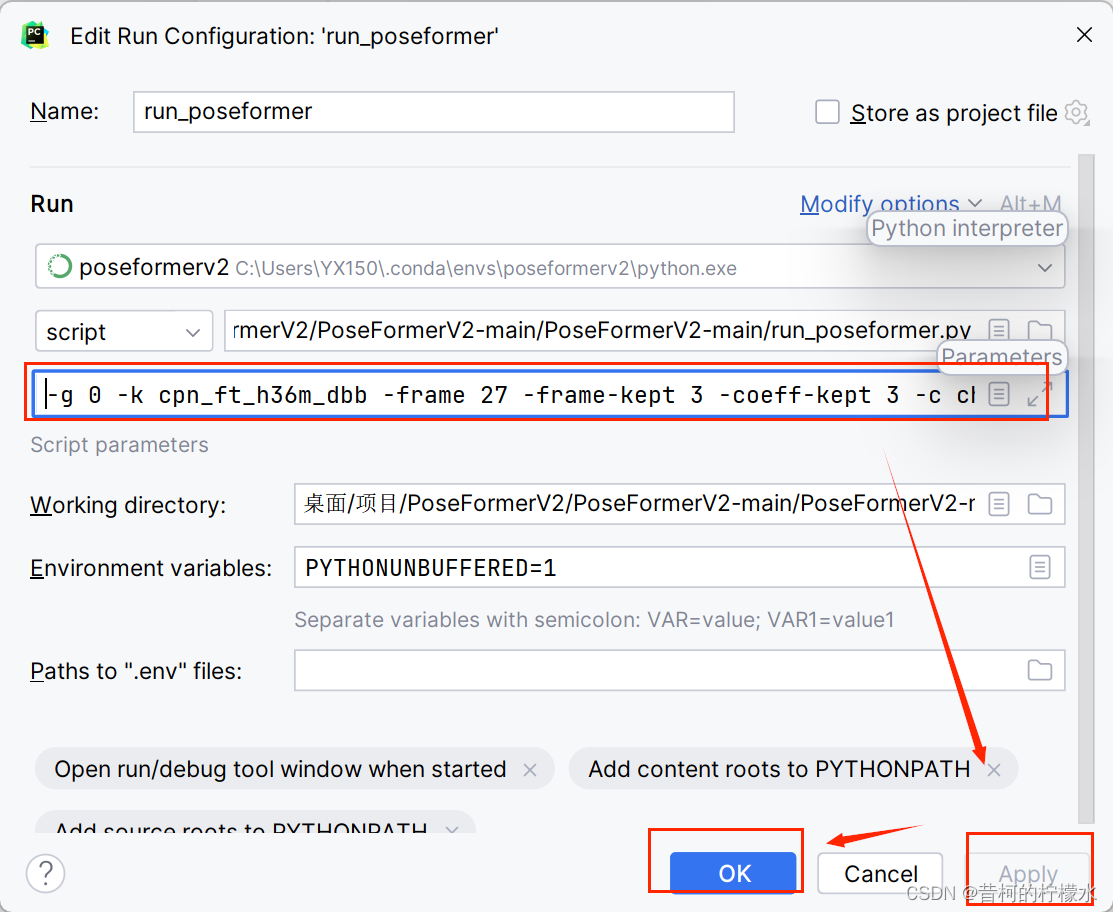
最后点击运行即可开始训练啦!!!
五 评估
在README.md中可以获得评估指令 python run_poseformer.py -g 0 -k cpn_ft_h36m_dbb -frame 27 -frame-kept 3 -coeff-kept 3 -c checkpoint/ --evaluate NAME_ckpt.bin
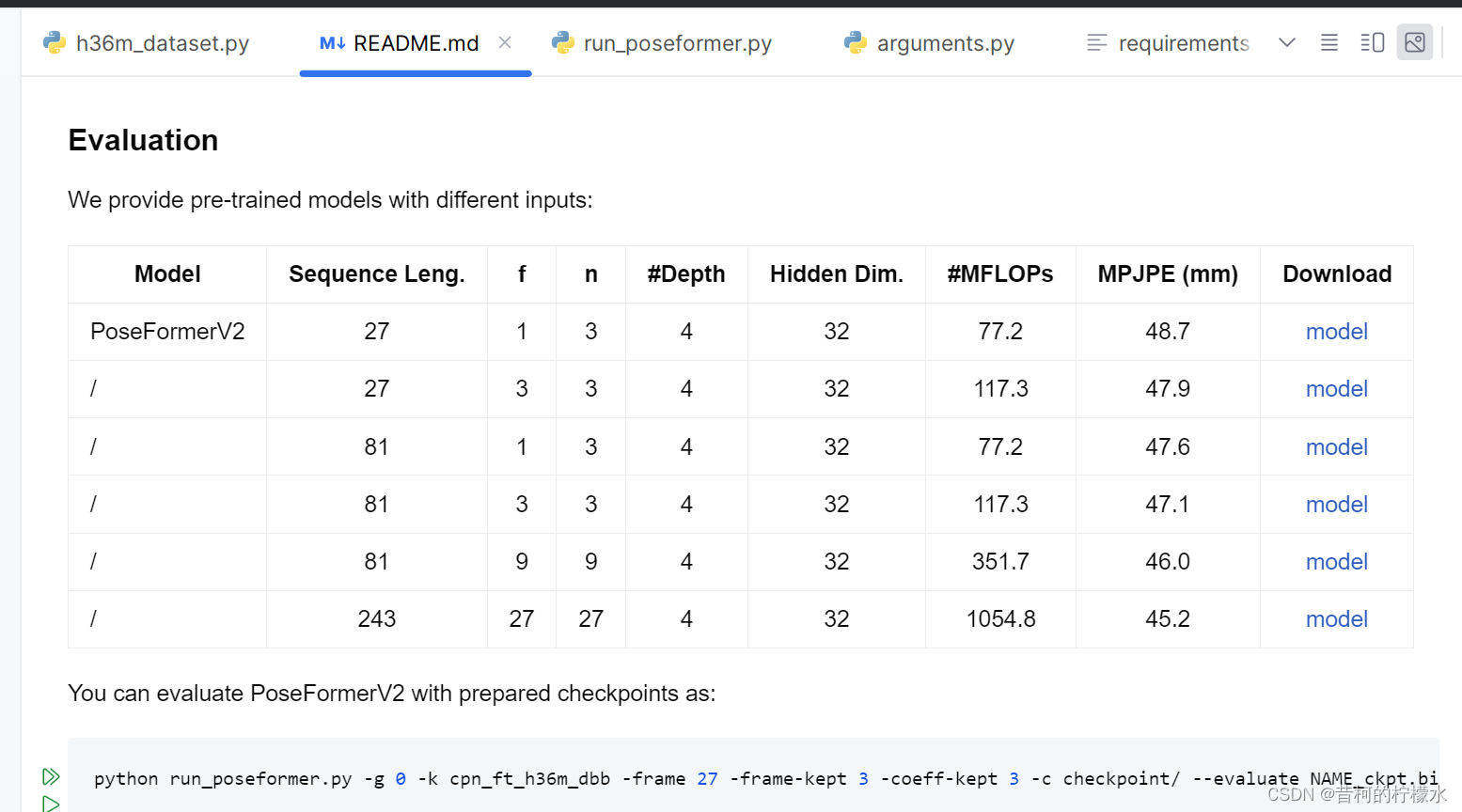
其中需要将 checkpoint/ 替换为你要评估文件所在的路径, NAME_ckpt.bin 替换为你要评估文件的名字。
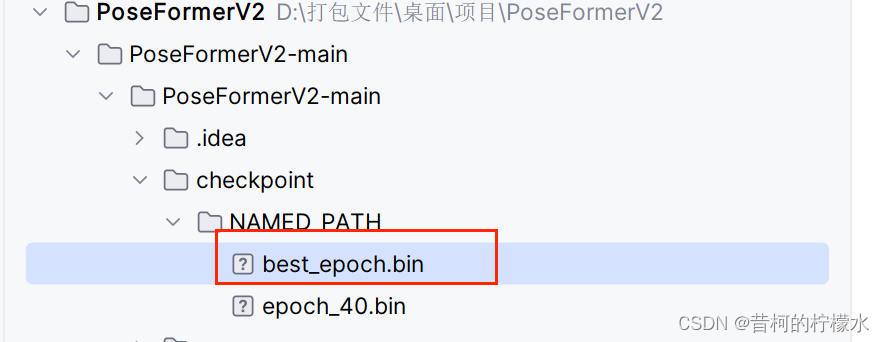
这里我要评估 best_epoch.bin 文件,因此命令应该为
python run_poseformer.py -g 0 -k cpn_ft_h36m_dbb -frame 27 -frame-kept 3 -coeff-kept 3 -c checkpoint/NAMED_PATH --evaluate best_epoch.bin
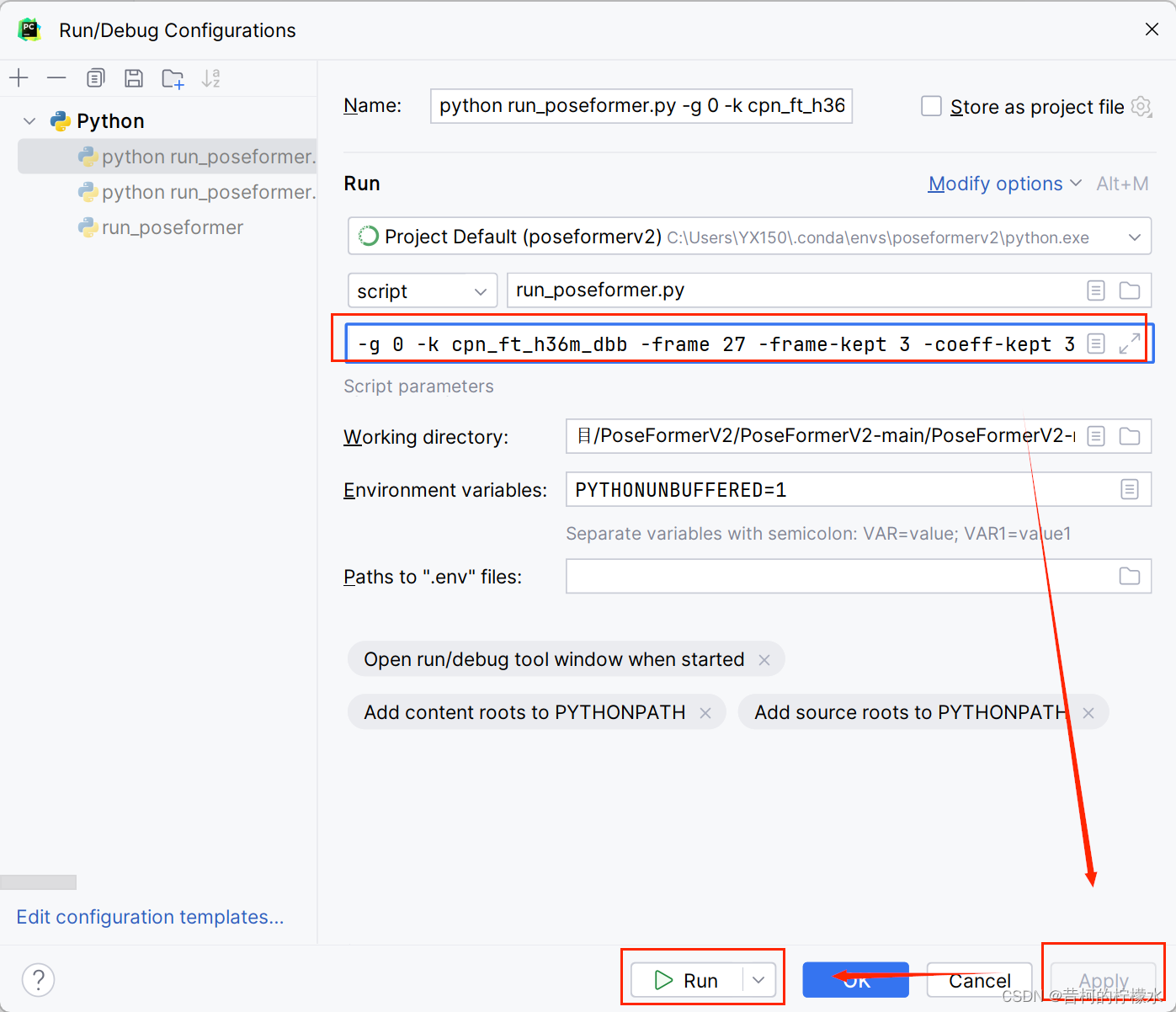
复制命令中的参数部分,即 -g 0 -k cpn_ft_h36m_dbb -frame 27 -frame-kept 3 -coeff-kept 3 -c checkpoint/NAMED_PATH --evaluate best_epoch.bin
打开项目下的run_posrformer.py ,接着右击文件选择 More Run ,再选择 Modify Run Configuration 。
将 参数 复制到 对应框内 ,再选择Apply ,最后点击运行即可开始评估啦!!!
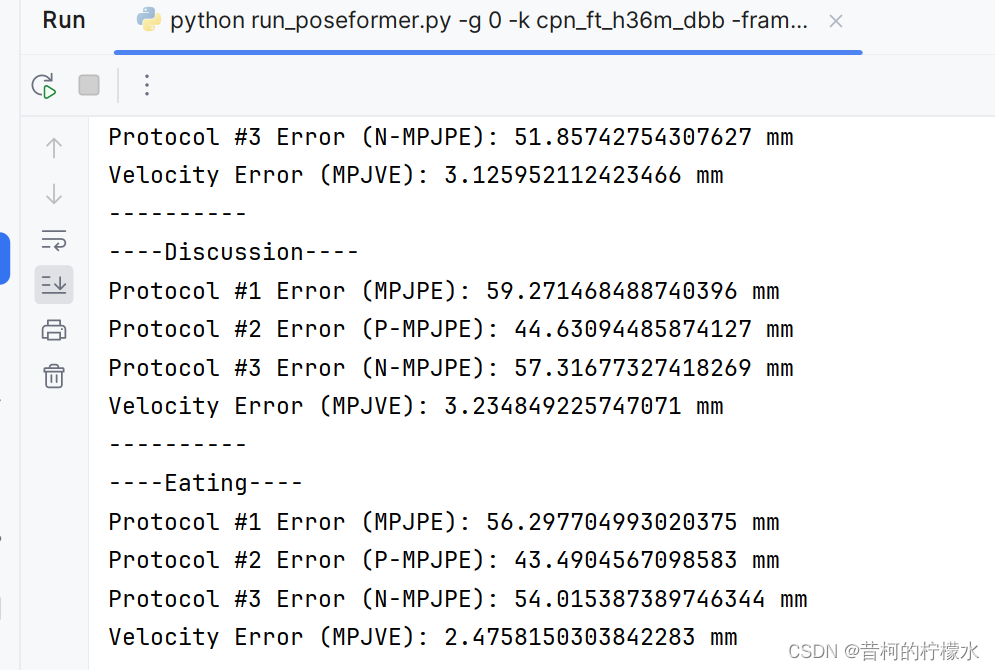
贴一个运行截图
六 demo
下载 YOLOv3 的预训练权重文件,https://drive.usercontent.google.com/download?id=1YgA9riqm0xG2j72qhONi5oyiAxc98Y1N&export=download&confirm=t&uuid=00779c6a-2c9c-45d4-b820-1b1a9252c48f
下载 HRNet 的预训练权重文件,
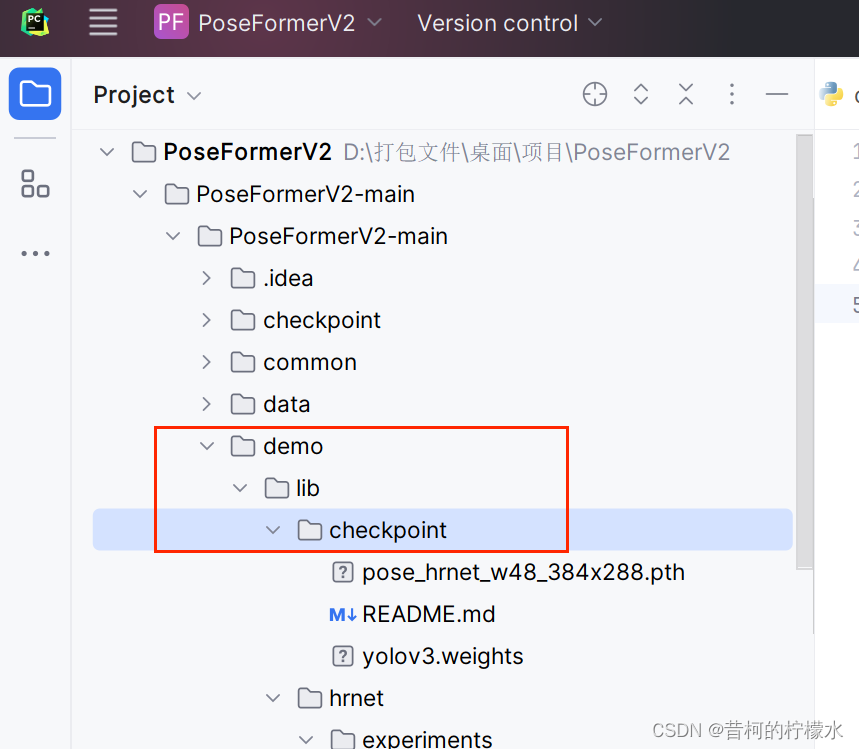
将文件保存到 ./demo/lib/checkpoint 目录中。
下载 PoseFormerV2 的权重文件27_243_45.2.bin
放在 ./checkpoint 目录下。
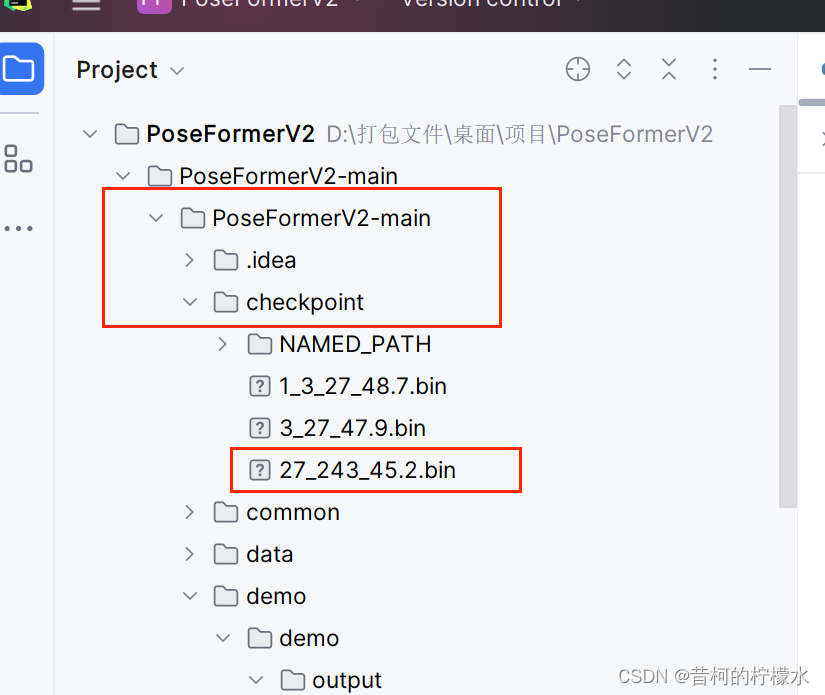
将您的视频放入 ./demo/video 目录中,项目提供了视频 sample_video.mp4 。
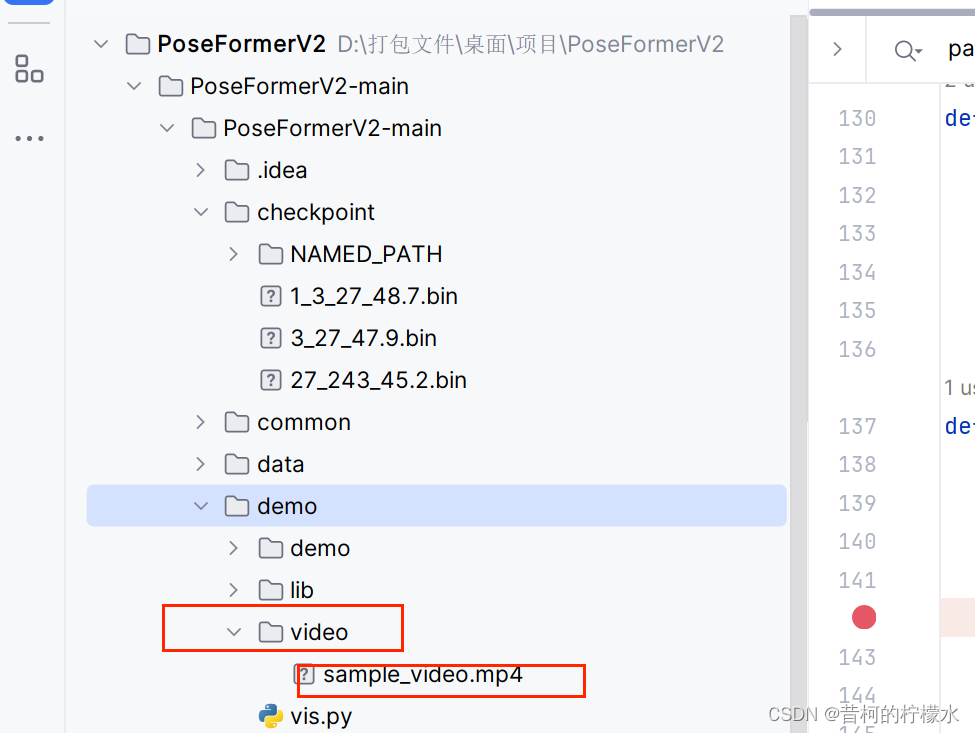
接着打开 demo下的vis.py文件
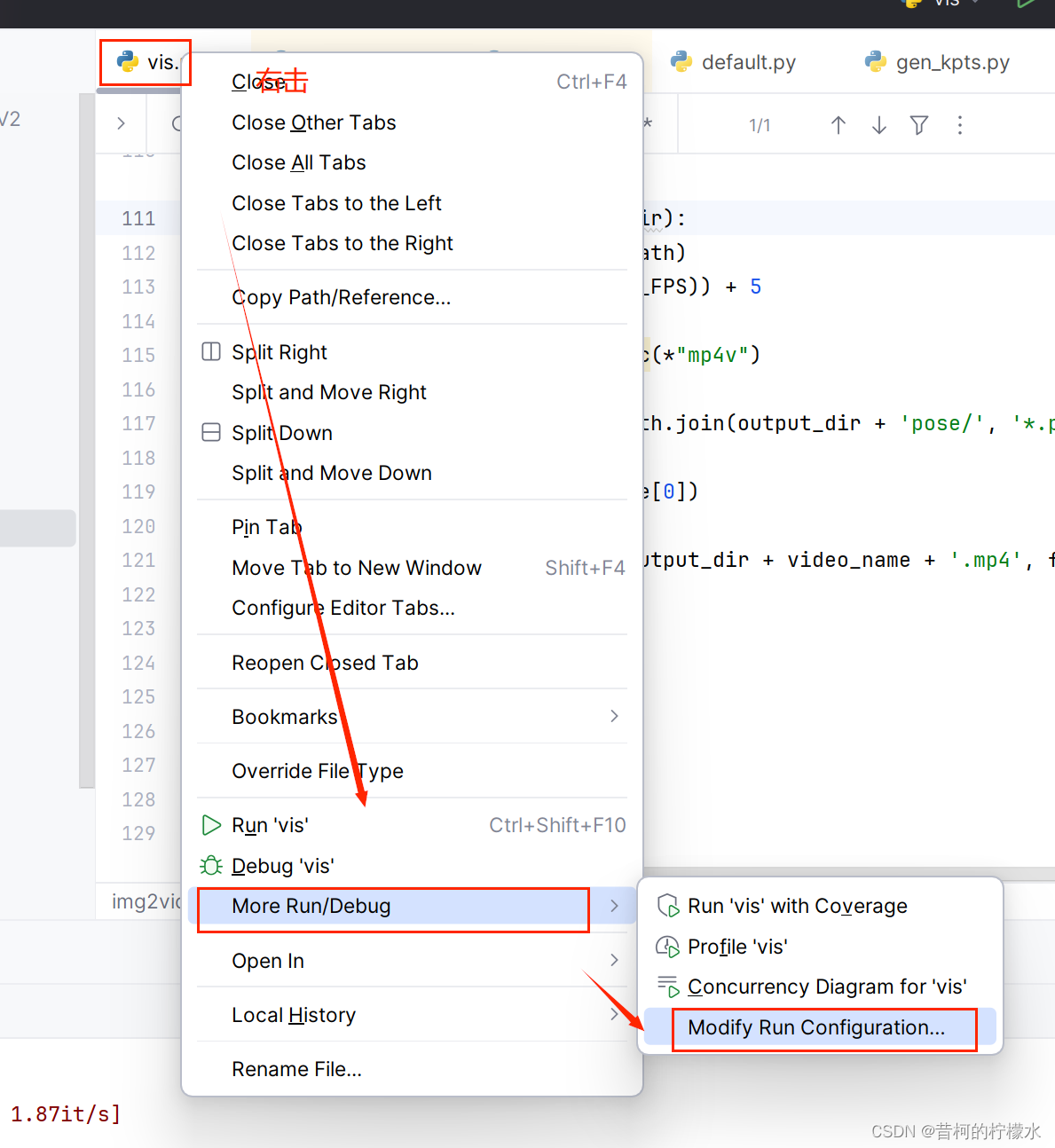
输入 参数 --video sample_video.mp4 到对应框内,再点击Apply , OK 。
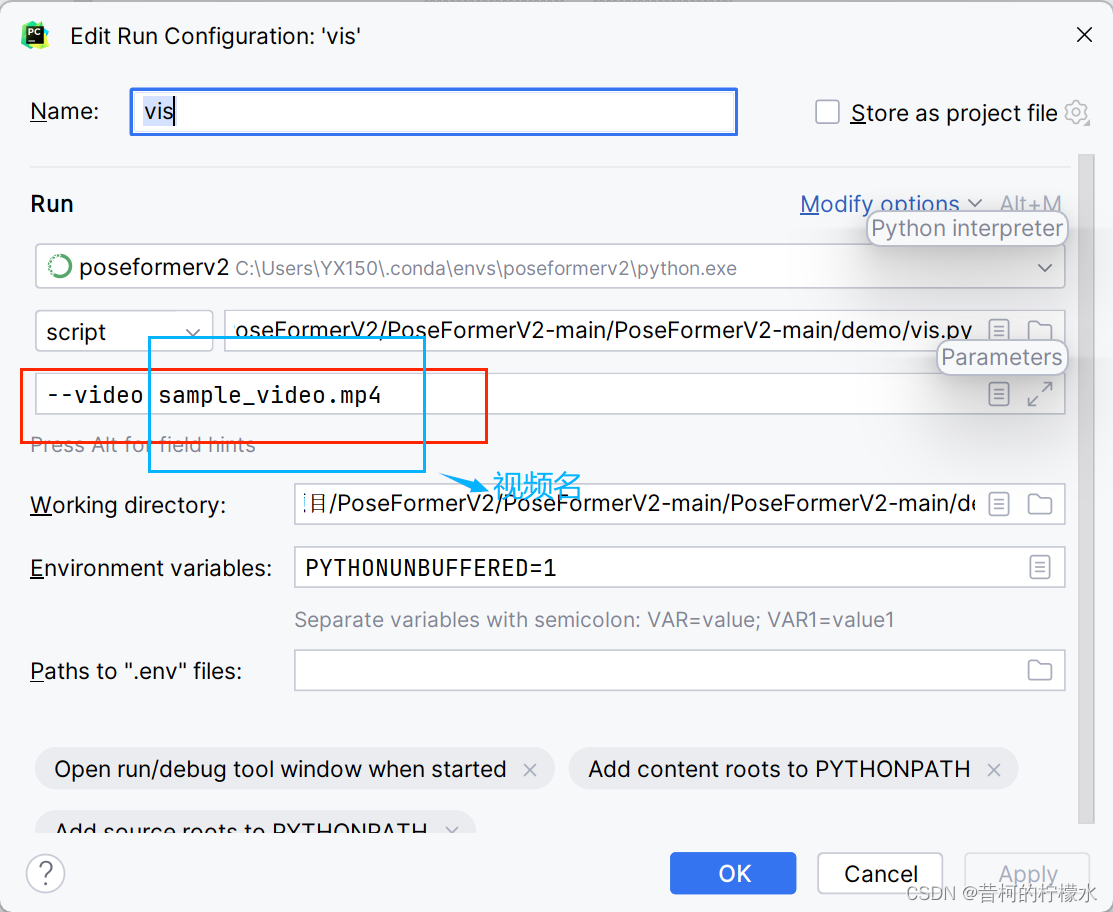
最后点击运行按钮
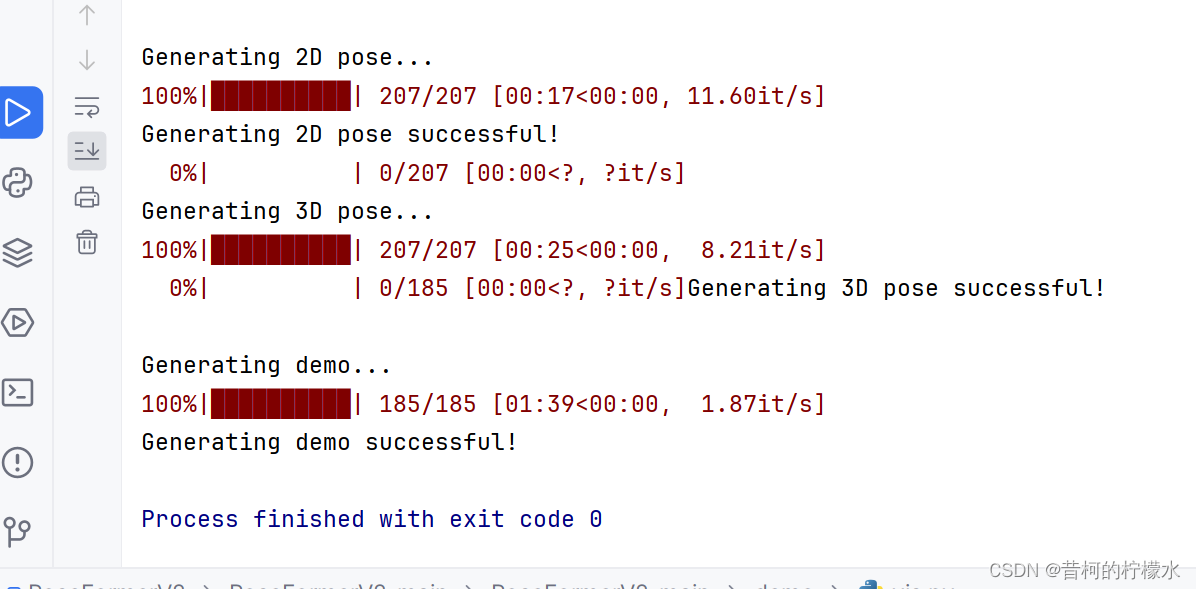
运行截图如下
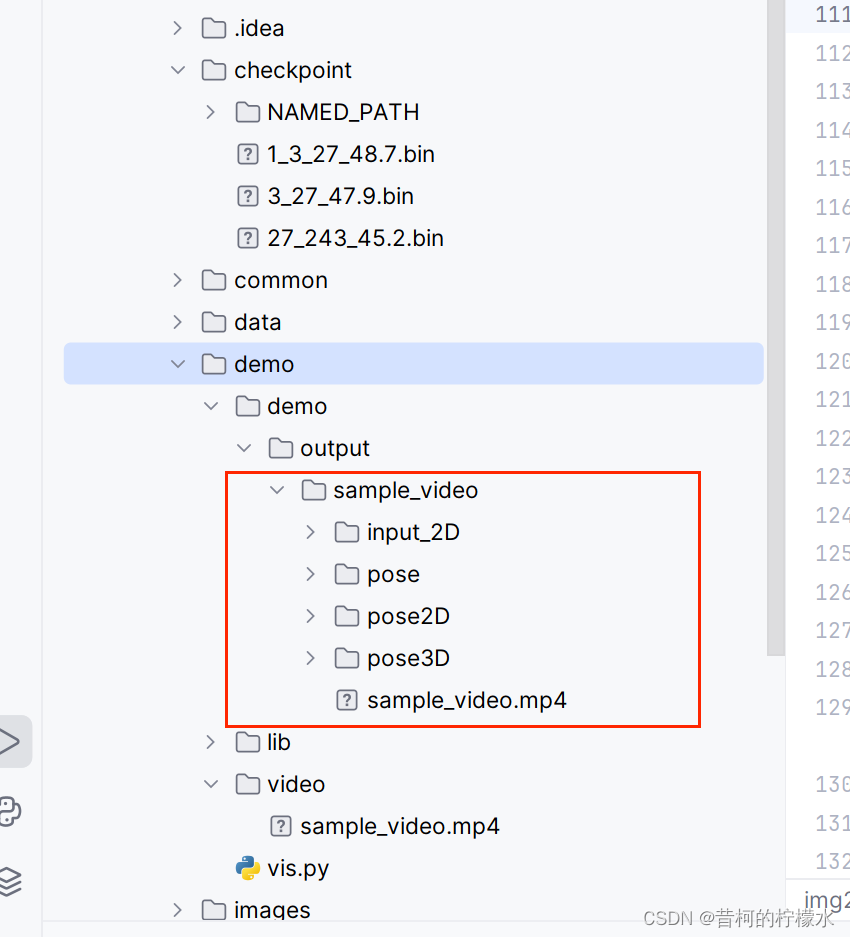
运行结果保存在以下路径中。
其中遇见了几个问题.......
如果成功运行的可以略过。
(1)ModuleNotFoundError: No module named 'common'

在 vis.py文件中加入 以下代码
import sys, os
base_path = os.path.dirname(os.path.dirname(
os.path.abspath(__file__)))
sys.path.append(base_path)
print(os.getcwd())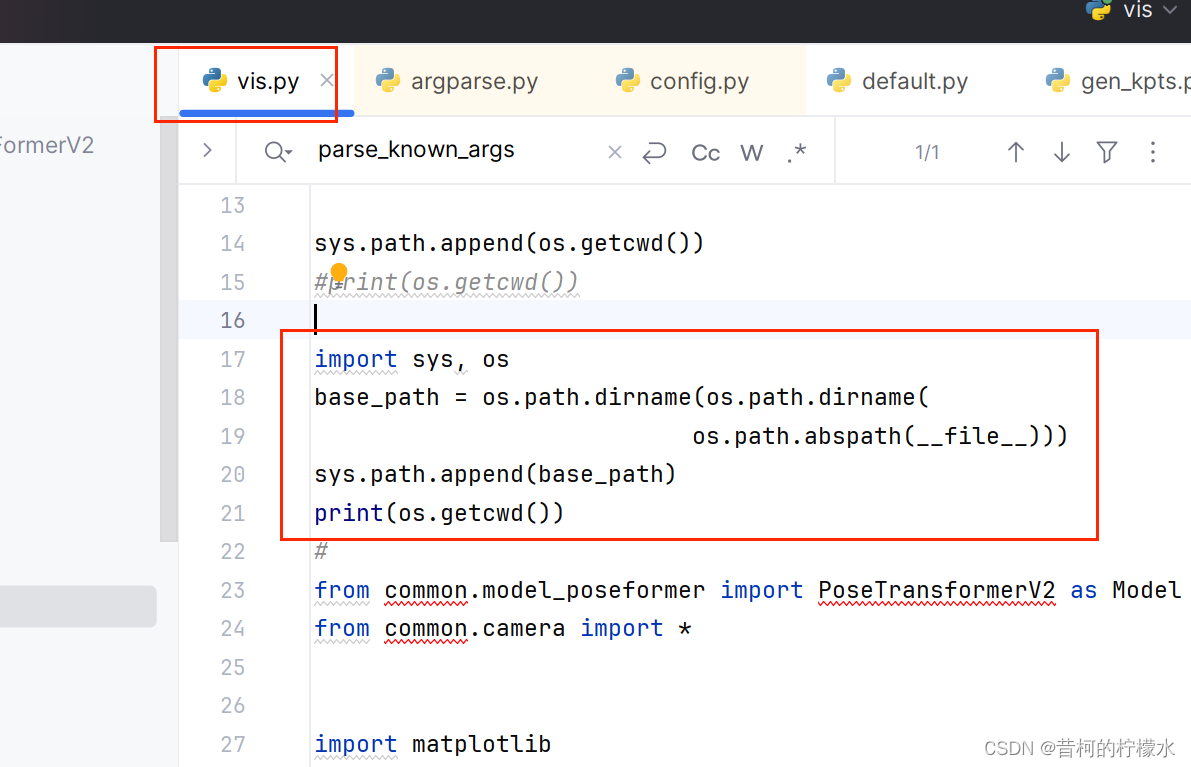
(2)FileNotFoundError: [Errno 2] No such file or directory: 'demo/lib/hrnet/experiments/w48_384x288_adam_lr1e-3.yaml'
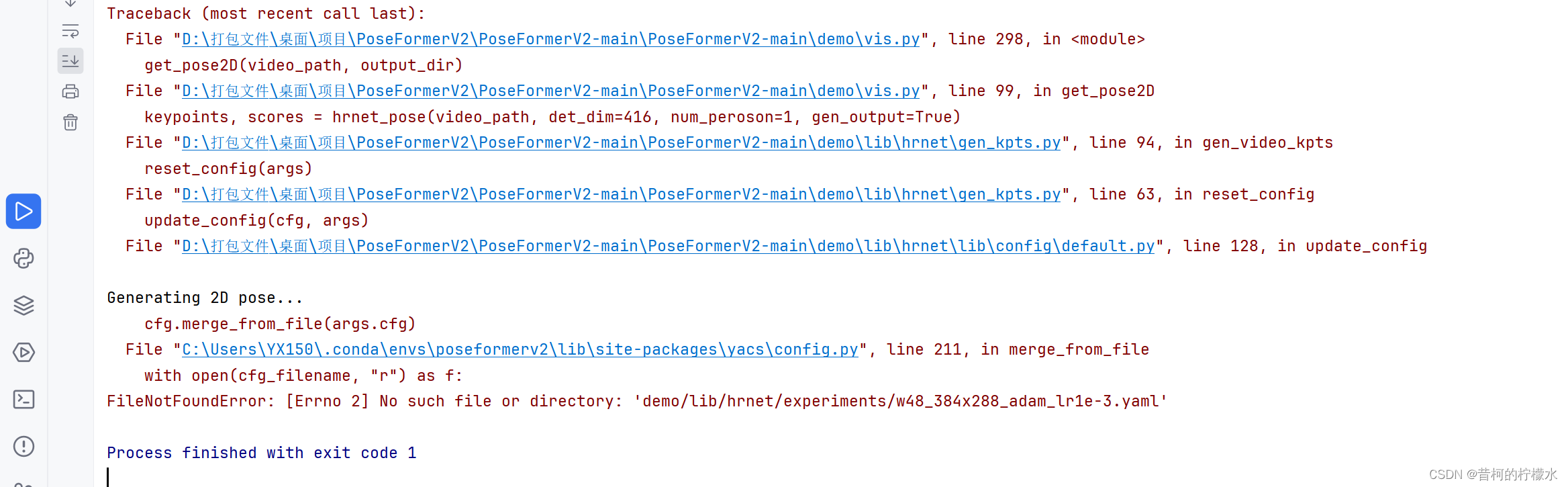
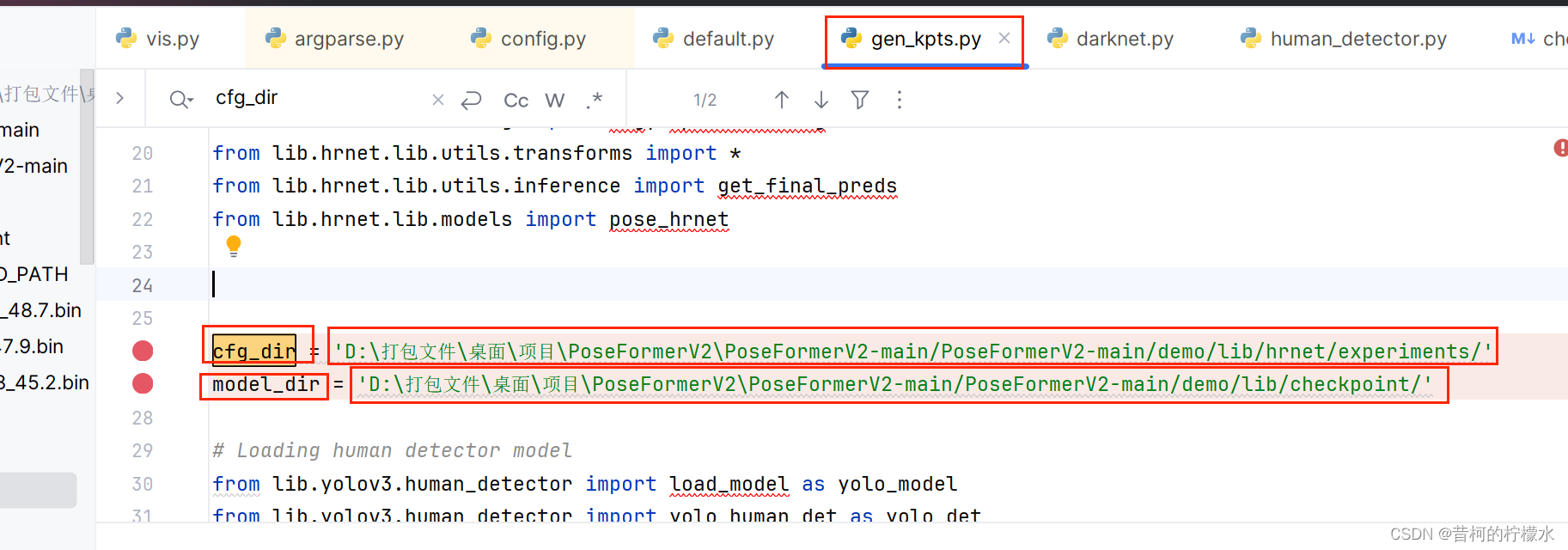
将gen_kpts.py z文件中的 cfg_dir 与model_dir 的相对路径替换为你自己的绝对路径
(3)FileNotFoundError: [Errno 2] No such file or directory: 'demo/lib/checkpoint/yolov3.weights'
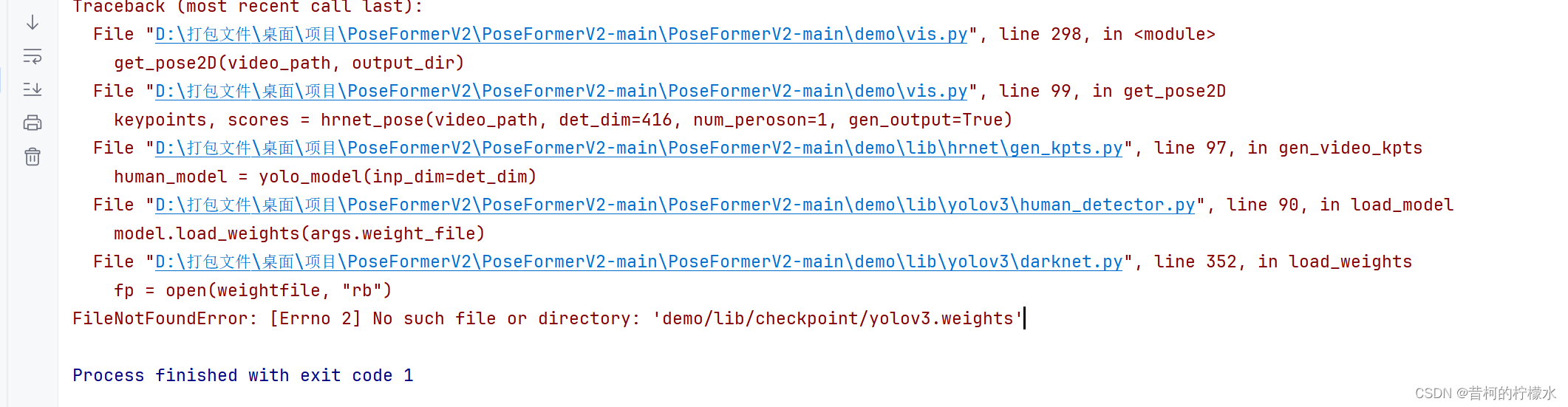
将human_detector.py 中 --weight-file 后面对应的default路径替换成你的绝对路径

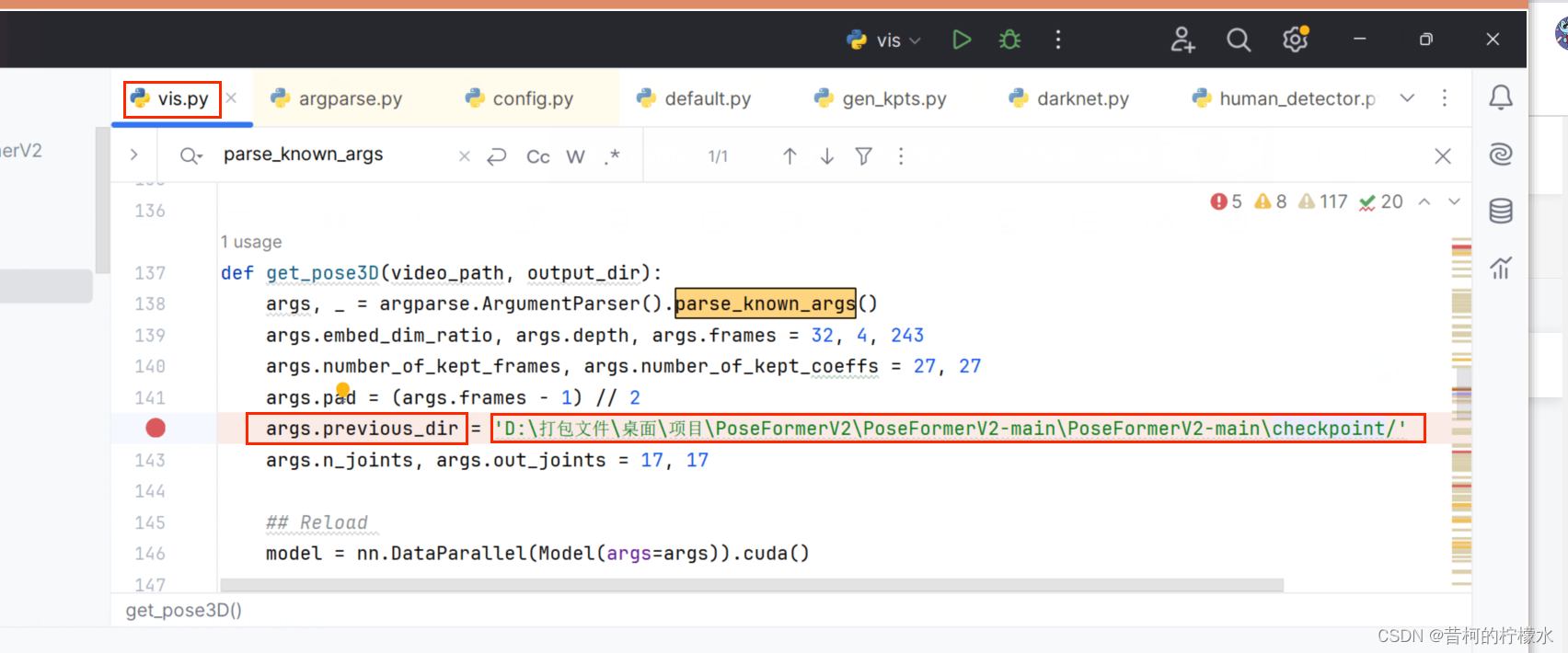
(4)IndexError: list index out of range
将vis.py 文件内的args.previous_dir 对应的路径替换为绝对路径
完结!!!撒花*★,°*:.☆( ̄▽ ̄)/$:*.°★* 。
有什么疑问欢迎提出。



















 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











