







前置知识,参考上一篇博客:CMU15-445-Spring-2023-Project #4 - 前置知识(lec15-20)
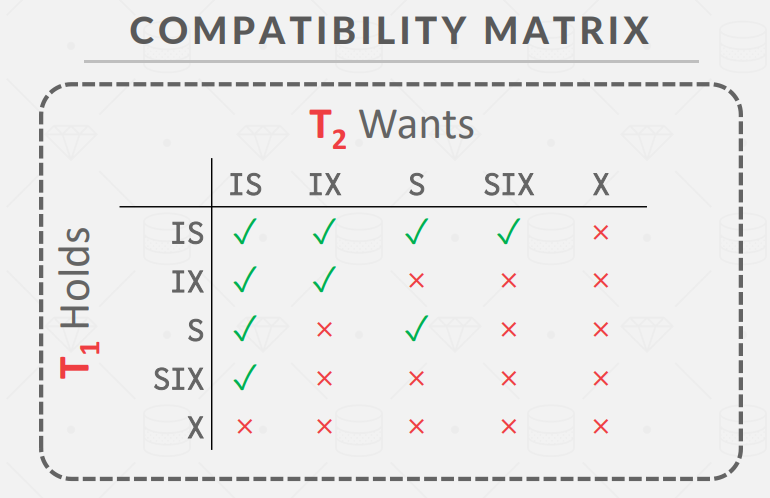
通过添加一个锁管理器在 BusTub 中支持事务,然后将其用于并发查询执行。锁管理器将支持五种锁模式下的表锁和元组锁:intention-shared、intention-exclusive、shared-intention-exclusive、shared、exclusive。锁管理器将处理来自事务的锁请求,向事务授予锁,并根据事务的隔离级别检查锁是否被适当释放。
Task #1 - Lock Manager
为确保事务操作的正确交错,DBMS 使用锁管理器(LM)来控制何时允许事务访问数据项。锁管理器的基本原理是维护一个内部数据结构,其中包含活动事务当前持有的锁。事务在访问数据项之前向 LM 发出锁请求,LM 要么授予锁,要么阻止事务直到锁可用,要么中止事务。
BusTub 系统将有一个全局 LM。当事务尝试访问或修改元组时,TableHeap 和 Executor 类将使用 LM 获取tuple record(通过 RID)上的锁。
LM 必须实现分层表级和元组级意向锁以及三个隔离级别:READ_UNCOMMITED、READ_COMMITTED 和 REPEATABLE_READ。LM 应根据事务的隔离级别授予或释放锁。
Isolation Levels (Strongest to Weakest)
- SERIALIZABLE: 无幻读,所有读取均可重复,并且无脏读
- Possible implementation: Index locks + Strict 2PL
- REPEATABLE READS:可能会有幻读
- Possible implementation: Strict 2PL
- READ-COMMITTED:可能会发生幻读和不可重复读
- Possible implementation: Strict 2PL for exclusive locks, immediate release of shared locks after a read
- READ-UNCOMMITTED:所有异常情况都可能发生
- Possible implementation: Strict 2PL for exclusive locks, no shared locks for reads
代码实现:
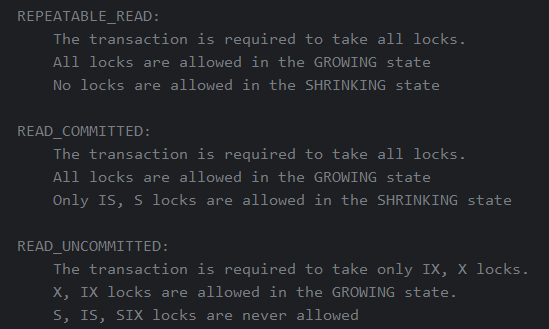
提供了一个事务上下文句柄(include/concurrency/transaction.h),该句柄带有隔离级别属性(即 READ_UNCOMMITED、READ_COMMITTED 和 REPEATABLE_READ)及其获取的锁的相关信息。LM 需要检查事务的隔离级别,并在lock/unlock请求中表现正确的行为。任何无效的加锁操作都会导致 ABORTED 事务状态(隐式终止)并引发异常。锁定尝试失败(如死锁)不会导致异常,但 LM 应对锁定请求返回 false。
Impl:
concurrency/lock_manager.cpp
include/concurrency/lock_manager.h
- LockTable(Transaction, LockMode, TableOID)
- 检查隔离级别,输出 LOCK_ON_SHRINKING 和 LOCK_SHARED_ON_READ_UNCOMMITTED 错误;
- 获得对应 table oid 的 lock request queue;
- 遍历 queue 看是否可以进行 lock upgrade;
- 若当前请求的 lock 与持有的 lock 相同,返回 true;
- 若多个 lock upgrade 并发,返回 UPGRADE_CONFLICT;
- 检查升级是否兼容,若兼容,则 drop 当前持有的锁,然后将其插入等待 granted。如果是新的锁请求,直接将其追加到 queue 的末尾。
- 使用 conditional variable 在 lock request queue 等待,直到拿到锁或者被abort(如果发生了死锁,task2中实现的死锁检测时有可能将该请求abort)
- 等待的条件是:
- 对于 granted 的 request,检查 compatibility table 是否兼容(升级兼容是指同一事务的,而这边的兼容检查是对于该 table 持有的 lock);
- 因为条件变量的 notify 通知的是所有等待的事务,需要确保 upgrade 的请求被优先处理,即有 upgrading 标记则优先 grant(事务即真正持有锁,通过set分类别存储)
- 将 granted 置为true。
- UnlockTable(Transction, TableOID)
- 只有当该事务不持有该表的任一row的锁,才能释放表粒度锁;
- 需要确保当前事务持有锁;
- 只有 unlock S 或 X 锁才能更新事务状态至 shrinking;
- 事务释放锁(set进行erase),条件变量通知阻塞的 upgrade;
- LockRow(Transaction, LockMode, TableOID, RID)
- 基本一致,除个别规则;
- UnlockRow(Transaction, TableOID, RID, force)
- 基本一致,除个别规则;
- force 参数:因为执行器实现可能需要先确定一个元组是否可访问,然后再决定是否包含它。如果 force 设为 true,操作将绕过所有 2PL 检查,就像元组没有被锁定一样,在代码中表现为不更新 txn 的状态为 shrinking;
note:request_queue_修改为共享指针类型的list。
Task #2 - Deadlock Detection
锁管理器应在后台线程中运行死锁检测,定期构建等待图(Waits-for graph),并根据需要中止事务以消除死锁。
- AddEdge(txn_id_t t1, txn_id_t t2): Adds an edge in your graph from
t1tot2, representing thatt1is waiting fort2. If the edge already exists, you don’t have to do anything. - RemoveEdge(txn_id_t t1, txn_id_t t2): Removes edge
t1tot2from your graph. If no such edge exists, you don’t have to do anything. - HasCycle(txn_id_t& txn_id): Looks for a cycle by using depth-first search (DFS). If it finds a cycle, HasCycle should store the transaction id of the **youngest **transaction in the cycle in txn_id and return true. Your function should return the first cycle it finds. If your graph has no cycles, HasCycle should return false.
- GetEdgeList(): Returns a list of tuples representing the edges in your graph. We will use this to test correctness of your graph. A pair
(t1,t2)corresponds to an edge fromt1tot2. - RunCycleDetection(): Contains skeleton code for running cycle detection in the background. You should implement your cycle detection algorithm here.
note:将 waits_for_修改为 map 类型,因为 unordered_map 是无序的。
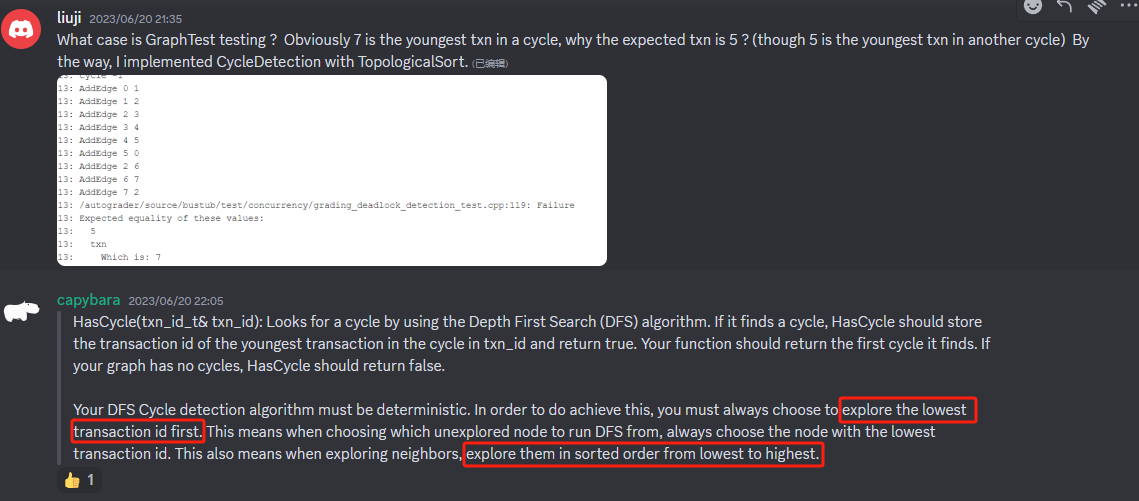
关于GraphTest测试,discord上的解释:
Task #3 - Concurrent Query Execution
为支持并发查询执行,执行器必须根据需要锁定和解锁表和元组,以实现事务中指定的隔离级别。为了简化这项工作,可以忽略并发索引执行,只关注堆文件中存储的数据。
更新 project 3 中实施的 executors(顺序扫描、插入和删除)的 Next() 方法。请注意,事务应在 lock/unlock 失败时中止。如果事务中止,则需要撤销先前的写操作;为此,需要维护每个事务中的 write_set,事务管理器的 Abort() 方法会使用该write_set。如果执行器无法获取锁,则应抛出 ExecutionException,以便执行引擎告知用户查询失败。
不应假设一个事务只包含一个查询。具体来说,这意味着一个元组可能在一个事务中被不同的查询访问不止一次。请考虑在不同隔离级别下应如何处理。(notes:这也就是为什么在遍历lock request queue时使用迭代器,因为remove删除了所有,而erase只删除当前迭代器指向的元素)
Impl:
- src/execution/seq_scan_executor.cpp
- src/execution/insert_executor.cpp
- src/execution/delete_executor.cpp
- src/concurrency/transaction_manager.cpp
隔离级别
一般来说在获取表粒度的锁时,遵守 Multilevel Locking 的规范,统一先获取意向锁。
- 无论隔离级别如何,事务都应为所有写操作加 X 锁,直到提交或终止。
- 对于 REPEATABLE_READ,事务应为所有读操作加 S 锁,直到提交或终止。
- 对于 READ_COMMITTED,事务应为所有读操作加 S 锁,但可以立即释放。
- 对于 READ_UNCOMMITTED,事务无需为读操作加任何 S 锁。
SeqScan Executor
- 在 Init 中,获取一个表锁。使用 MakeEagerIterator 而不是 MakeIterator 来获取迭代器(在 Project 3 的 UpdateExecutor 中引入了 MakeIterator 以避免万圣节问题,但现在不需要)。
- 在 Next 中:
- 获取表迭代器的当前位置。
- 根据隔离级别的需要锁定元组。
- 抓取元组。检查元组元,如果已执行过滤推送扫描,则检查谓词。
- 如果元组不应被该事务读取,则强制解锁该行。否则,根据隔离级别的需要解锁该行。
- 如果当前操作是删除(通过检查执行器上下文 IsDelete(),对于 DELETE 和 UPDATE,IsDelete() 将设为 true),则应假定扫描的所有元组都将被删除,并在第 2 步中根据需要对表和元组加 X 锁。
Insert Executor
- 在 Init 中获取表锁
- 在 Next 中将锁管理器、事务对象和表 id 传递给 InsertTuple,以便原子插入并锁定一个元组。请确保根据需要维护write set。
Delete Executor
- 如果在执行器上下文中基于 IsDelete() 正确实现了 SeqScanExecutor,则无需在此执行器中使用任何锁。
- 请确保在 Next 中维护 write set。
Transaction Manager
- 在 Commit 中,除了释放所有锁外,一般不需要做任何事情。
- 在 Abort 中,应根据write set还原该事务的所有更改(table和index)。
实验结果














 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









