







@[]
服务器资源监控告警处理方案总结
服务器监控指标
服务器日常监控巡检时,总会遇到不同服务器的不同告警,使用不同的监控工具,监控的指标有所不同,但最基础的服务器资源指标,基本都支持,比如zabbix + ,Prometheus + Grafana。
本文只针对服务器资源的相关告警,总结常用的处理方案,其他业务性指标(尤其与业务系统相关),需要针对具体业务再分析,不过处理方案的思想是相通的。
在这里插入图片描述
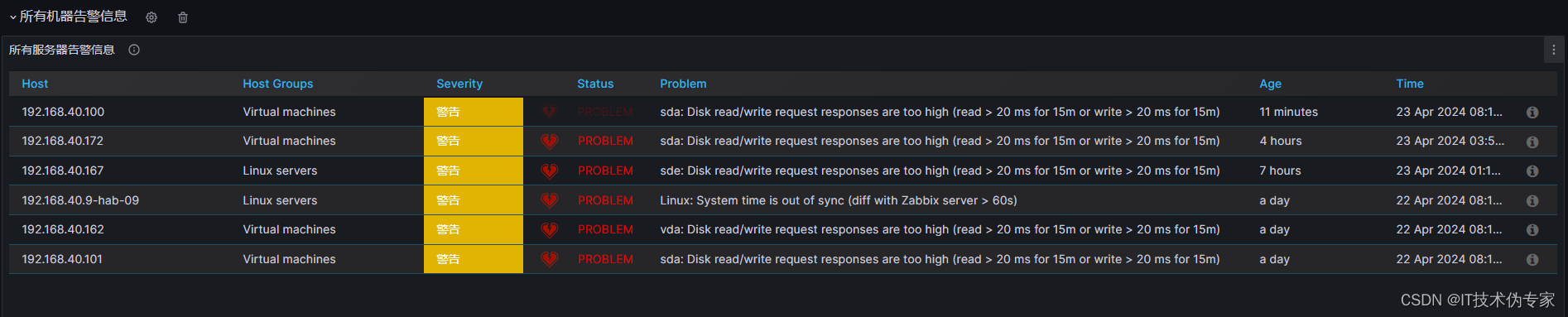
CPU告警
通过 top 命令,查看所有进程运行情况,在结果界面,通过 shift + p 切换视图,按照CPU使用率倒序排列,找出CPU使用率最高的进程依次分析(查看 %CPU 列)
特别关注:top命令显示的 CPU 使用率是按照单核计算的,即100%代表使用了单核的满负荷,如果服务器为4核,则理论最大为400%
Tasks: 358 total, 1 running, 357 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.1 us, 0.6 sy, 0.0 ni, 98.1 id, 0.2 wa, 0.0 hi, 0.0 si, 0.1 st
KiB Mem : 18327576 total, 420844 free, 11997648 used, 5909084 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 5464004 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14101 zabbix 20 0 10.7g 1.7g 19116 S 16.6 9.8 22967:27 java
16537 zabbix 20 0 9227468 1.3g 14528 S 7.3 7.7 12724:03 java
14523 zabbix 20 0 11.2g 377804 15408 S 4.0 2.1 8133:38 node
12051 root 20 0 7172228 412140 11080 S 3.3 2.2 5631:07 java
15477 root 20 0 10.3g 739676 9968 S 2.6 4.0 4516:16 java
27599 root 20 0 9.8g 786424 14836 S 1.7 4.3 2031:22 java
3457 root 20 0 10.0g 722916 11724 S 1.0 3.9 1737:01 java
6224 root 20 0 9.8g 718416 13736 S 1.0 3.9 1866:02 java
22316 polkitd 20 0 2772216 433672 9452 S 1.0 2.4 1432:26 mysqld
795 root 20 0 9988.7m 611724 13736 S 0.7 3.3 1675:01 java
11578 root 20 0 9.8g 726556 14612 S 0.7 4.0 1722:23 java
16215 root 20 0 9.9g 633748 9936 S 0.7 3.5 1449:49 java
31879 root 20 0 162348 2468 1524 R 0.7 0.0 0:00.25 top
9 root 20 0 0 0 0 S 0.3 0.0 403:06.81 rcu_sched
1568 root 20 0 9.9g 557656 10160 S 0.3 3.0 1136:07 java
1727 root 20 0 2935636 82540 17244 S 0.3 0.5 325:02.38 dockerd
2582 root 20 0 1528140 138604 11792 S 0.3 0.8 764:00.63 minio
8914 zabbix 20 0 12932 1332 776 S 0.3 0.0 197:37.27 zabbix_agentd
12226 root 20 0 7486532 703704 14784 S 0.3 3.8 312:37.20 java
13615 root 20 0 1558516 11072 1268 S 0.3 0.1 400:02.56 docker-proxy
13728 zabbix 20 0 2932484 96840 12328 S 0.3 0.5 478:41.03 java
17187 root 20 0 0 0 0 S 0.3 0.0 1:37.45 kworker/11:1
22261 root 20 0 1138504 10092 1492 S 0.3 0.1 79:47.35 docker-proxy
30068 polkitd 20 0 52812 9788 2932 S 0.3 0.1 513:49.70 redis-server
1 root 20 0 194220 6772 3648 S 0.0 0.0 109:32.85 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:12.19 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 2:09.14 ksoftirqd/0
7 root rt 0 0 0 0 S 0.0 0.0 6:04.58 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
11 root rt 0 0 0 0 S 0.0 0.0 2:52.98 watchdog/0
12 root rt 0 0 0 0 S 0.0 0.0 3:09.37 watchdog/1
根据不同进程的情况,可能会有以下现象
- CPU持续告警,一般为计算型应用程序,如数据清洗、转换、计算等,即该应用运行时本就会使用更多CPU资源
- 偶然告警,只要告警不超过CPU总资源的70%,不引起系统卡顿,原则上可以暂时不用处理
- 偶然告警,但告警频率逐渐增高,可能由于应用程序bug、漏洞引起
- 特定时间段告警,一般跟业务关联性较高,比如流量高峰
常用处理方案
- 根据实际业务需要,可以限制单应用的运行性能(如集群部署时,可以适当降低单节点性能),则调整应用相关配置,限制线程数、并发量等
- 如果公共组件该版本有相关漏洞缺陷,则根据官方指示,修补漏洞,或者升级版本
- 解决业务流量高的问题,使流量更均衡,如集群部署,消息缓存,负载均衡,定时任务调整等
- 扩容服务器资源,如增加CPU资源,或者将应用服务迁移至资源性能更高的服务器
内存告警
通过 top 命令,查看所有进程运行情况,在结果界面,通过 shift + M 切换视图,按照 内存 使用量倒序排列,找出内存使用量最高的进程依次分析(查看 RES 和 %MEM 列)
Tasks: 358 total, 1 running, 357 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.0 us, 0.5 sy, 0.0 ni, 98.2 id, 0.2 wa, 0.0 hi, 0.0 si, 0.1 st
KiB Mem : 18327576 total, 425460 free, 11992740 used, 5909376 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 5468936 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14101 zabbix 20 0 10.7g 1.7g 19140 S 14.6 9.8 22967:41 java
16537 zabbix 20 0 9227468 1.3g 14528 S 7.3 7.7 12724:13 java
27599 root 20 0 9.8g 786424 14836 S 1.0 4.3 2031:23 java
15477 root 20 0 10.3g 739676 9968 S 2.3 4.0 4516:20 java
11578 root 20 0 9.8g 726556 14612 S 1.0 4.0 1722:25 java
3457 root 20 0 10.0g 722916 11724 S 1.3 3.9 1737:02 java
6224 root 20 0 9.8g 718416 13736 S 1.0 3.9 1866:03 java
12226 root 20 0 7486532 703704 14784 S 0.7 3.8 312:37.69 java
16215 root 20 0 9.9g 633748 9936 S 1.0 3.5 1449:50 java
795 root 20 0 9988.7m 611724 13736 S 0.7 3.3 1675:02 java
1568 root 20 0 9.9g 557656 10160 S 0.7 3.0 1136:08 java
22316 polkitd 20 0 2772216 433672 9452 S 0.7 2.4 1432:27 mysqld
12051 root 20 0 7172228 412140 11080 S 3.3 2.2 5631:11 java
14523 zabbix 20 0 11.2g 376744 15408 S 5.0 2.1 8133:43 node
2582 root 20 0 1528140 138604 11792 S 0.0 0.8 764:01.04 minio
13728 zabbix 20 0 2932484 96840 12328 S 0.3 0.5 478:41.38 java
1727 root 20 0 2935636 82540 17244 S 0.0 0.5 325:02.48 dockerd
1709 root 20 0 1587736 38332 6172 S 0.0 0.2 138:19.30 containerd
840 root 20 0 363876 31456 4032 S 0.0 0.2 76:42.10 firewalld
1142 root 20 0 574288 17364 4016 S 0.0 0.1 44:16.78 tuned
2562 root 20 0 720496 14844 4272 S 0.0 0.1 28:36.88 containerd-shim
26369 root 20 0 720752 13992 4036 S 0.0 0.1 22:28.82 containerd-shim
10786 root 20 0 720496 13312 4248 S 0.0 0.1 31:09.25 containerd-shim
22289 root 20 0 720752 13256 4264 S 0.0 0.1 22:29.22 containerd-shim
14656 root 20 0 720496 12852 4296 S 0.0 0.1 23:51.85 containerd-shim
13658 root 20 0 720496 12620 4084 S 0.0 0.1 22:51.71 containerd-shim
5958 root 20 0 720496 12208 4056 S 0.0 0.1 22:48.34 containerd-shim
27466 root 20 0 720496 11996 4056 S 0.0 0.1 19:43.55 containerd-shim
10751 root 20 0 1055936 11880 1084 S 0.0 0.1 0:28.33 docker-proxy
10759 root 20 0 907960 11832 1104 S 0.0 0.1 0:23.66 docker-proxy
13615 root 20 0 1558516 11072 1268 S 0.3 0.1 400:02.84 docker-proxy
808 polkitd 20 0 613012 10816 2636 S 0.0 0.1 35:51.69 polkitd
32436 root 20 0 720496 10740 4260 S 0.0 0.1 22:56.39 containerd-shim
常用处理方案
- 调整应用服务相关参数,限制内存占用、缓存空间大小、缓存队列长度、缓存保留时间、内存管理参数等
- 扩容服务器内存资源,或将应用服务迁移至高性能服务器
磁盘空间容量告警
通过 df -h 命令,查看磁盘各分区占用量(查看 Use% 和 Mounted on 列),然后使用 du -sh 命令逐级查找分区内磁盘使用量最高的目录
[root@bogon ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 8.8G 0 8.8G 0% /dev
tmpfs 8.8G 0 8.8G 0% /dev/shm
tmpfs 8.8G 506M 8.3G 6% /run
tmpfs 8.8G 0 8.8G 0% /sys/fs/cgroup
/dev/mapper/centos-root 441G 52G 390G 12% /
/dev/mapper/centos-home 49G 2.8G 47G 6% /home
/dev/mapper/centos-var 9.8G 395M 9.4G 4% /var
/dev/sda1 397M 182M 216M 46% /boot
overlay 441G 52G 390G 12% /data/docker/overlay2/d48aa346d172da6cac497b88bf5e4bd8420f55fba5c6476c4ac7f5b1ec599cbe/merged
tmpfs 1.8G 0 1.8G 0% /run/user/0
overlay 441G 52G 390G 12% /data/docker/overlay2/3149f1eb647a6dbe8c574ce1a9aaa77d6d516c0524448a67ce7baaf4611c2a07/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/53294f8ff60bb8098c50c0c71bf34d62e0c56f9debac16b9aa675846afae6240/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/0d704f04276852c61df46a8d73a7e8fed0250265e73452bef570e61474ef11de/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/fa5243408f22602b5d456d37154d5dfc007130bc37d1454d781d87d88e9c3dbd/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/a798e48621340c853f25ff8fd8c097350644931608505cb8e9a9bb7b62a88638/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/23ee703ae7235ac816e61fe5a51aebabfde288d6a3c43c720c2ea017ef1d1604/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/bc5e7198411a0b38bd4888ac73f2fb9abada74c5484973cb37b6ca69e4440bf5/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/8e35c62d05ad5f392c239d346e432cec445d851a8b98dab5871b35880adac3b2/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/a8424ac5189826109db715ca49b47f93bd6de16a798d1bf4eadaaedb5fa9a4fa/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/cdce4db81f22eda2fcd820f199d157d803b91188667ee78fe30d4346800b5af6/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/f4645cf0fe12e645179bd7c978bfc19a40fdc0ca54369b5dde9e57eaf4bde59b/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/775153fcbba58e159e7bc0da16900954f881ed64ca08592dd6f529e781504fc3/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/3e534f206ae430bbfb6c73925d4f667356f915e6ec318d71145b1a2c7cfb3473/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/bed6ad70dee33de8626bb743bdbd5d186b65459eb6b9f790bcd01cb865c1eee5/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/2bbe7857ed798d14de1914d442b70eb291a1ed37d9aec92210e54d2c8bd14988/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/6c559eef6595ebddca10f2d9f0b3ca4d7c566470dda85f716c480ed1e6099b92/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/7e0de6bbcf8fc6a64dd41b62642cc53ecc40dcc3abaca6a3624d9c67e7b3a8e0/merged
overlay 441G 52G 390G 12% /data/docker/overlay2/fbc2c225d783cfc36e3409cb0fc5bbc7c2f8595f45afc7a1d1bd0e7dd01f6e4f/merged
常用解决方案
- 占用磁盘高的为日志文件,则可以参考 Linux日志管理经验总结(crontab+logrotate)
- 数据盘磁盘占用高(独立挂载磁盘的分区,如 /data),包括安装程序、数据文件等,则根据实际业务场景,调整相关参数,限制数据保存时间、数据压缩等
- 系统盘磁盘占用高(/ 根分区),则考虑将相关应用程序迁移至数据盘,如果应用程序支持,可以将安装目录整体迁移(如 修改Docker镜像存储目录,减轻系统盘负担,即配置到数据盘后,将现有数据迁移到数据盘,重启服务),否则调整相关参数,可以将数据存储目录、日志目录迁移至数据盘
- 扩容服务器磁盘资源,而且只能扩容数据盘,或者增加独立挂载磁盘,然后将相关业务迁移至新磁盘
磁盘IO告警
使用 iotop 命令(Linux系统默认没有集成,需要单独安装,CentOS可以使用 yum,也可以 官网下载安装包),查看磁盘IO最高的进程,其中 SWAPIN 列为swap交换百分比,IO> 列为IO等待所占用的百分比。
iotop使用可以参考 Iotop – Monitor Linux Disk I/O Activity and Usage Per-Process Basis 或 iotop 命令

[root@localhost ~]# iotop -o
Total DISK READ : 0.00 B/s | Total DISK WRITE : 388.00 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 633.68 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
518 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.16 % [xfsaild/dm-0]
20271 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/3:2]
2178 be/4 root 0.00 B/s 407.08 B/s 0.00 % 0.00 % java -jar V2XRawDataServer.jar
2229 be/4 root 0.00 B/s 407.08 B/s 0.00 % 0.00 % java -jar V2XRawDataServer.jar
2286 be/4 root 0.00 B/s 30.61 K/s 0.00 % 0.00 % java -jar msbus.jar
1801 be/4 root 0.00 B/s 407.08 B/s 0.00 % 0.00 % clickhouse-server --config-f~khouse-server.pid [BgSchPool]
23520 be/4 root 0.00 B/s 407.08 B/s 0.00 % 0.00 % clickhouse-server --config-f~khouse-server.pid [Collector]
1253 be/4 root 0.00 B/s 407.08 B/s 0.00 % 0.00 % java -jar V2XRealtimeServer.jar
1254 be/4 root 0.00 B/s 814.17 B/s 0.00 % 0.00 % java -jar msbus.jar
10253 be/4 root 0.00 B/s 407.08 B/s 0.00 % 0.00 % java -jar V2XStatisticsServer.jar
1698 be/4 root 0.00 B/s 142.72 K/s 0.00 % 0.00 % clickhouse-server --config-f~khouse-server.pid [Formatter]
1700 be/4 root 0.00 B/s 407.08 B/s 0.00 % 0.00 % clickhouse-server --config-f~khouse-server.pid [BgSchPool]
与 CPU告警场景类似,根据不同进程的情况,可能会有以下现象
- 磁盘IO持续告警,一般为存储型应用程序,如文件系统,数据库等,即该应用运行时本就会使用更多磁盘IO
- 偶然告警,只要告警不超过70%,不引起系统卡顿,原则上可以暂时不用处理
- 偶然告警,但告警频率逐渐增高,可能由于应用程序bug、漏洞引起
- 特定时间段告警,一般跟业务关联性较高,比如流量高峰
常用处理方案
- 根据实际业务需要,可以限制单应用的运行性能(如集群部署时,可以适当降低单节点性能),则调整应用相关配置,限制线程数、并发量、缓存参数等
- 如果公共组件该版本有相关漏洞缺陷,则根据官方指示,修补漏洞,或者升级版本
- 解决业务流量高的问题,使流量更均衡,如集群部署,消息缓存,负载均衡,定时任务调整等
- 提升服务器磁盘性能,如使用SSD磁盘,或者将应用服务迁移至资源性能更高的服务器
TCP连接告警
通过 netstat 命令,查看和统计不同状态的TCP连接数量,以及相应的应用程序。
TCP连接状态告警,一般只存在两种:ESTABLISHED(已连接状态)、TIME_WAIT(主动关闭端的最后状态,等待操作系统回收,其中,主动关闭可以是服务端,也可以是客户端),其他TCP连接的状态,几乎不会出现数量太多,本文将不考虑。
- ESTABLISHED,不管是服务端应用程序还是客户端应用程序,该状态的TCP连接过多,说明该应用服务的业务量已经不是单体服务可以处理的,所以需要扩展应用服务
- TIME_WAIT,服务端应用程序和客户端应用程序都可能会出现,而且这是TCP连接的最后一个状态,接下来只有等待操作系统回收(回收周期根据不同操作系统,可能为30秒 - 2分钟),但是,在被回收前,该连接仍然会占用操作系统一个套接字资源,如果短时间内出现过多TIME_WAIT,可能是因为高并发且持续的短连接业务场景,最终可能会逐步将操作系统套接字资源耗尽,从而无法再创建 TCP连接
常用解决方案
-
ESTABLISHED,服服务端的应用程序,可以考虑多节点部署,搭建集群或搭建负载均衡,或者将单服务拆分为多服务,分别部署到不同的服务器实现负载均衡
-
ESTABLISHED,客户端的应用程序,可以考虑使用连接池,避免所有请求都建立新的连接,也可以考虑多节点部署客户端,或者将客户端业务拆分为多个客户端,然后分别部署到不同的服务器
-
TIME_WAIT,可以考虑使用TCP长连接;如果是http服务端出现告警,可以考虑在客户端连接时将 connection 设置为 keep-alive,避免服务端主动断开连接;也可以从操作系统层调整相关参数,一方面开启套接字复用,一方面使操作系统更快的回收,调整方案如下
-
#vim /etc/sysctl.conf,增加或修改以下参数 net.ipv4.tcp_tw_reuse=1 net.ipv4.tcp_tw_recycle=1 net.ipv4.tcp_fin_timeout=30 #调整后刷新生效 sysctl -pTCP相关统计命令
1.使用netstat 统计不同状态TCP连接数量
特别关注:脚本中NR>2由于netstat命令前2行输出为描述信息
[root@localhost ~]# netstat -antp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:33071 0.0.0.0:* LISTEN 2105/mysqld
tcp 0 0 0.0.0.0:7379 0.0.0.0:* LISTEN 1090/redis-server 0
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1244/sshd
[root@localhost ~]# netstat -antp | awk -F '[ /]+' 'NR>2 {count[$6]++} END {for(state in count) print state,"\t\t",count[state] }'
LISTEN 16
CLOSE_WAIT 2
ESTABLISHED 273
FIN_WAIT2 1
TIME_WAIT 1
使用netstat统计指定状态TCP连接不同进程数量
[root@localhost ~]# netstat -antp | grep -i established | awk -F '[ /]+' '{count[$8]++} END {for(app in count) print app,"\t\t",count[app] }'
java 124
mysqld 109
clickhouse-ser 6
sshd: 1
redis-server 31
















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











