






文章目录
1、大数据简介
工程角度定义:是采、传、存、算和用的一系列解决方案。

2、Linux
2.1 安装部署
工具:centos 7.7 、 vm 15.0 pro
-
将hadoop01.zip解压到某个目录,我的解压路径为:D:\vmwork\jxlg\hadoop01\ 。windows解压省略。
-
使用vm去打开刚解压的镜像文件。vm->文件->打开->找到个第一步的解压路径中的.vmx文件。
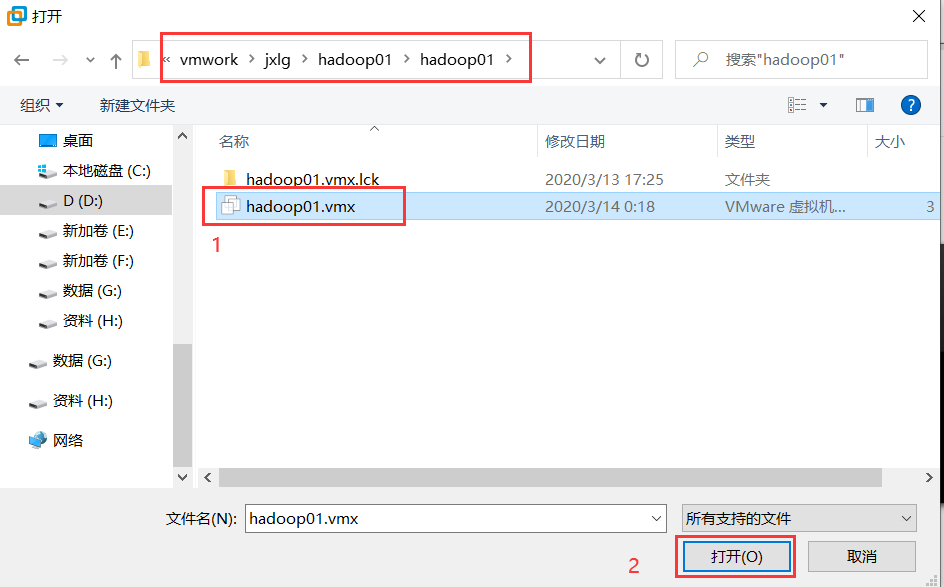
-
启动刚打开的虚拟机
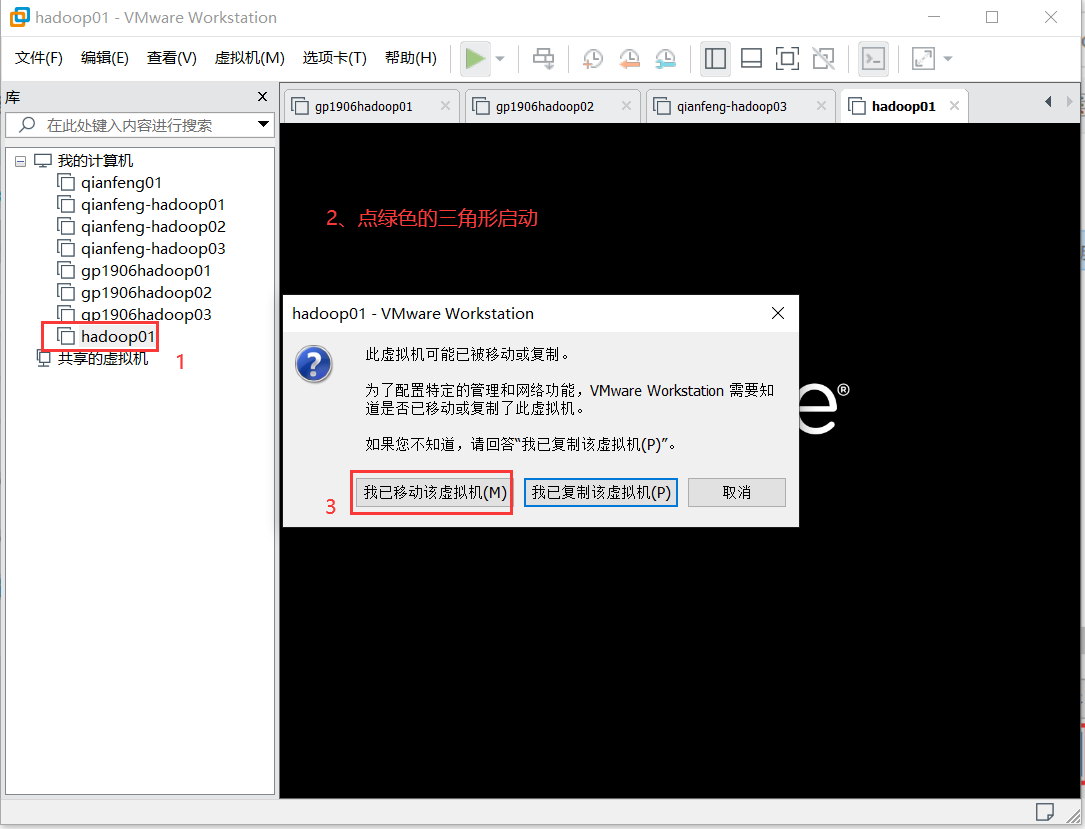
登陆用户名和密码:root/root
2.2 windows连接虚拟机
-
安装省略,也可以参考资料中的文档。
-
设置vm的net-8的网段为192.168.216.0
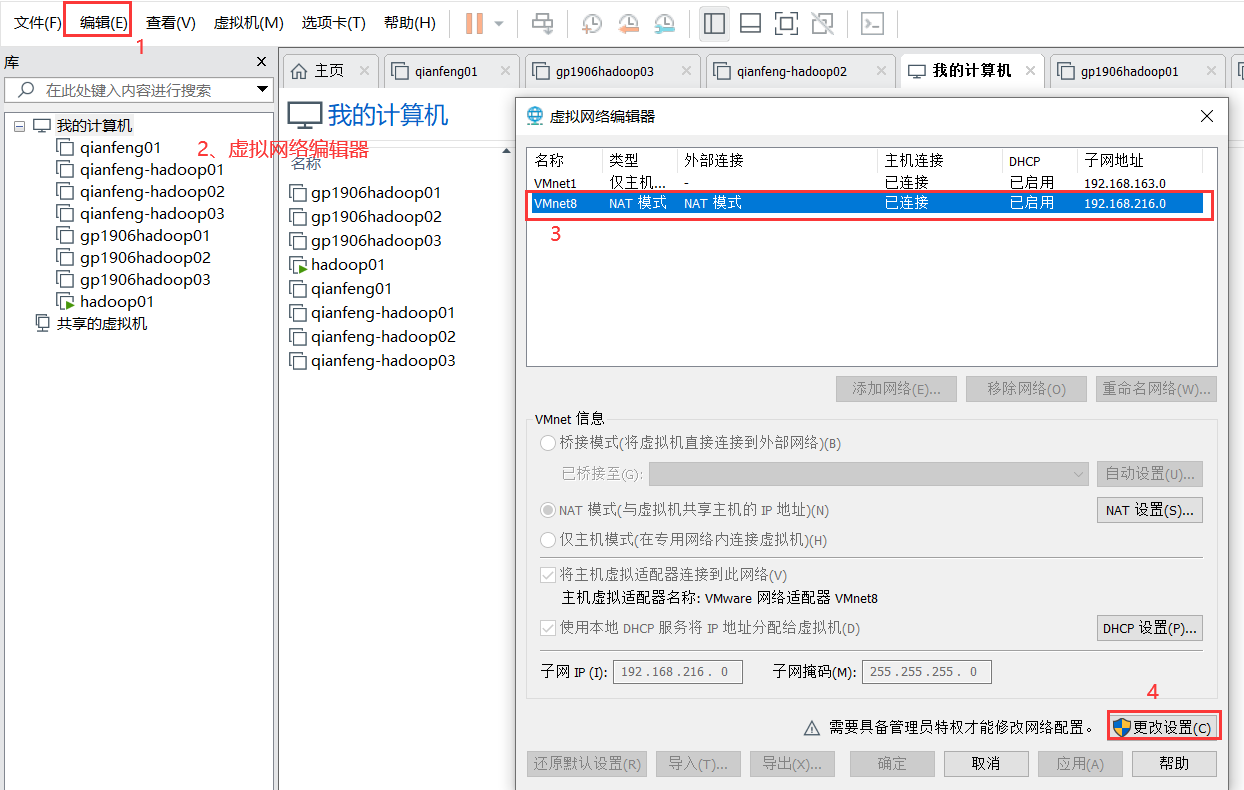
网段设置如下:
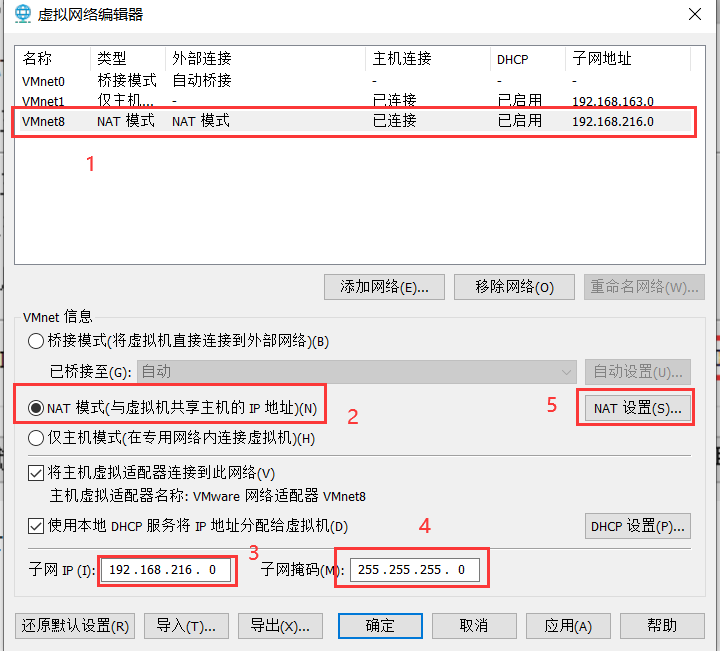
网关设置如下:
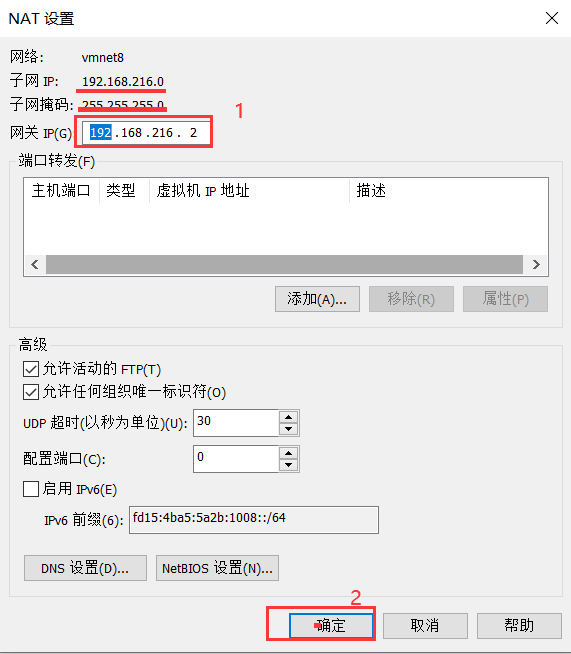
设置好之后一路确定。
-
连接服务器之前,先在windows中ping服务器的ip,通了之后才能连接。如下图片为通:
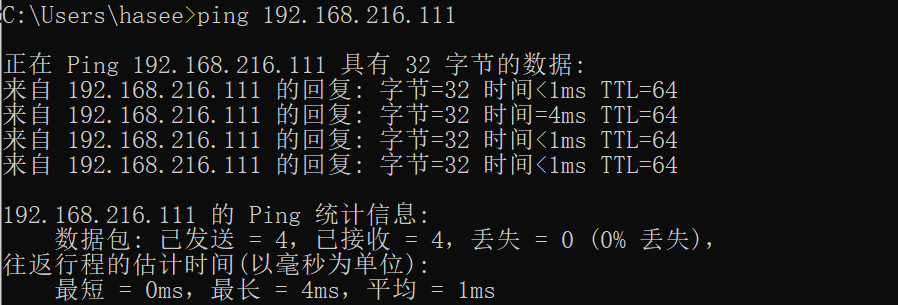
-
创建session连接
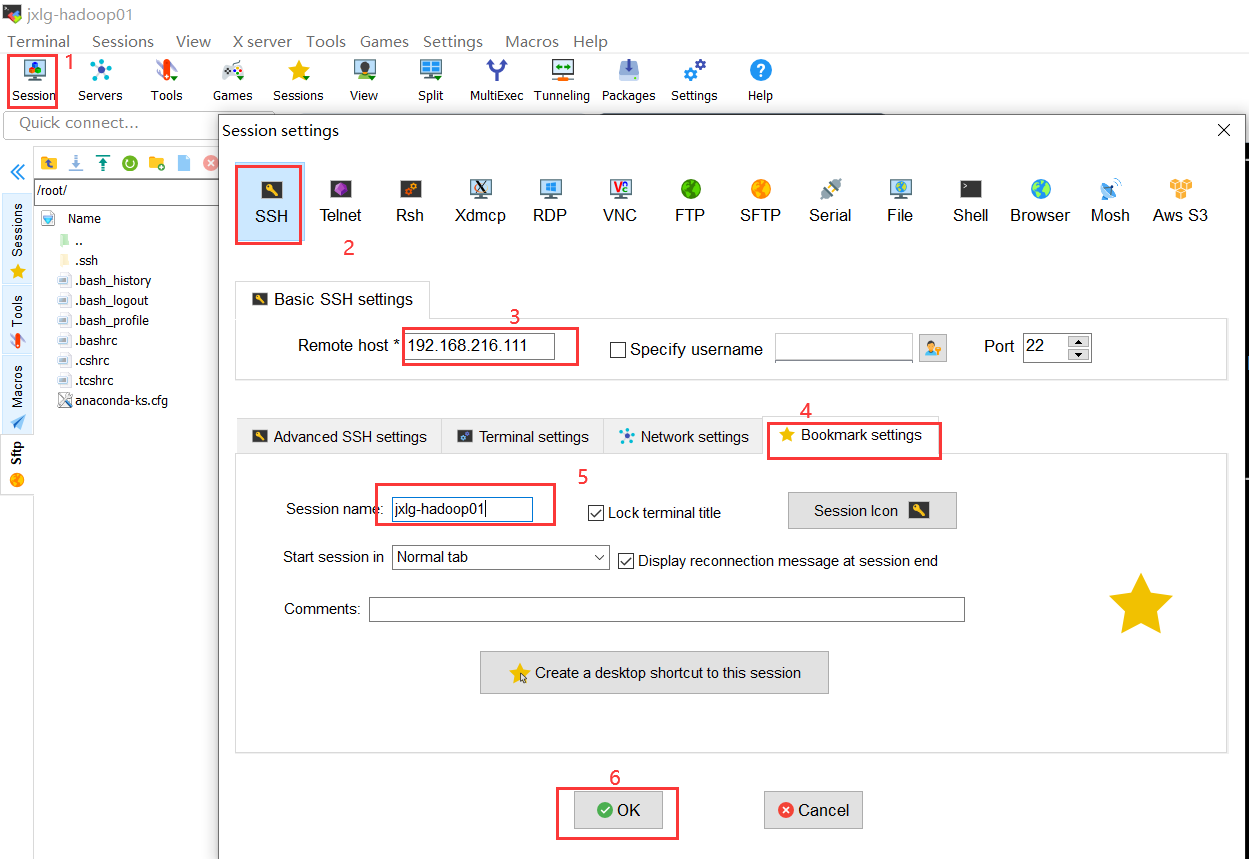
连接后,需要输入用户名和密码。如果带有一堆信息的时候,你需要输入yes,这样的操作仅第一次。成功效果如下:
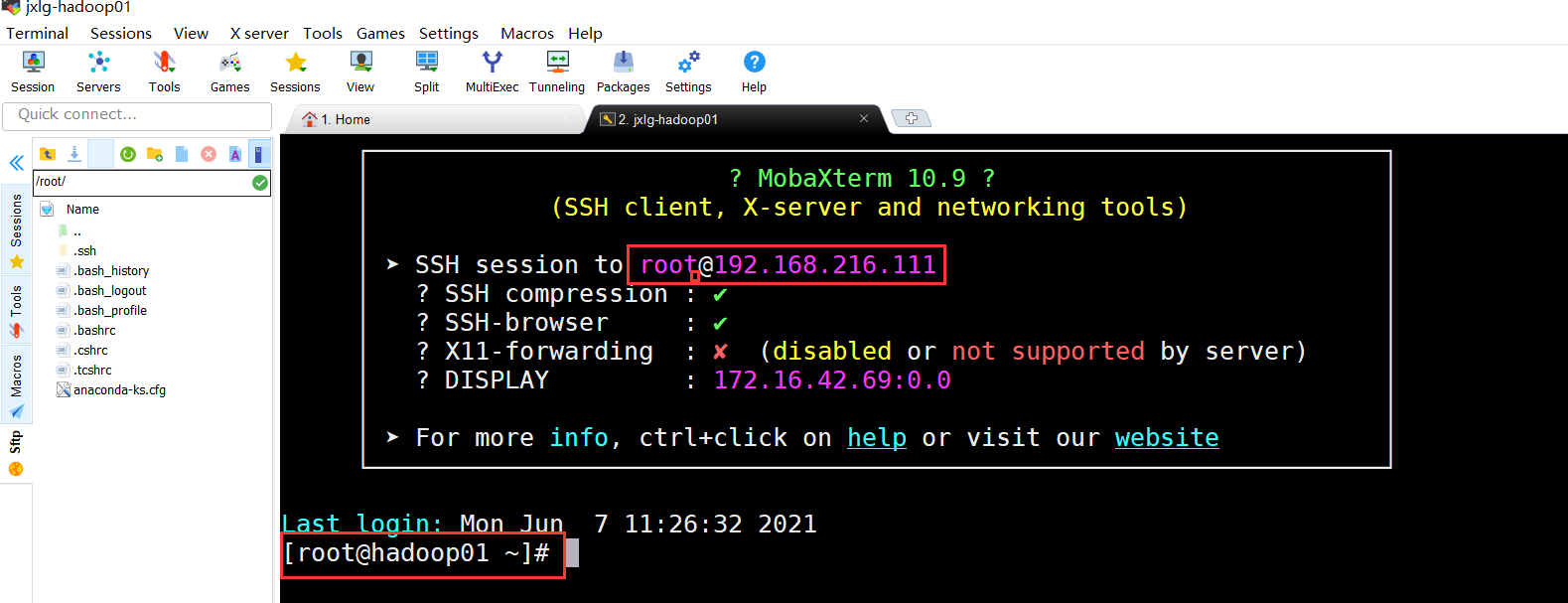
注意事项:
1、实在连不上,请将windows中的防火墙、杀毒软件关闭掉。
作业
1、将centos7.7的镜像安装好,需要能在windows中使用工具连接
2、预习linux中文件系统操作、软件安装操作、服务器启停类相关命令
2.3 常用命令
系统相关命令
命令 [操作] [文件路径]
--帮助命令1(推荐使用)
man uname
--帮助命令2(不是特别推荐)
--帮助命令3(不建议使用)
info uname
-- 系统相关
[root@hadoop01 ~]# uname -a
Linux hadoop01 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
[root@hadoop01 ~]# cat /etc/redhat-release
CentOS Linux release 7.7.1908 (Core)
[root@hadoop01 ~]# hostname
hadoop01
修改ip
[root@hadoop01 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
[root@hadoop01 ~]# vi /etc/hosts
添加用户名
[root@hadoop01 ~]# useradd jx
[root@hadoop01 ~]# passwd jx
Changing password for user jx.
磁盘情况
[root@hadoop01 ~]# df
文件相关命令
-- 递归创建
[root@hadoop01 home]# mkdir -p /home/bigdata/jxlg
-- 创建文件
vi /home/bigdata/jxlg/1
[root@hadoop01 bigdata]# echo 0 >> /home/bigdata/jxlg/0
[root@hadoop01 bigdata]# for i in `seq 1 10`; do echo $i >> /home/bigdata/jxlg/${i}.log ;done
-- 递归复制
[root@hadoop01 bigdata]# cp -r /home/bigdata/jxlg/ /home/jx/
-- 多源复制
[root@hadoop01 bigdata]# cp -r /home/bigdata/jxlg/ /home/bigdata/123 /home/jx/
--移动改名
[root@hadoop01 bigdata]# mv /home/bigdata/123 /home/bigdata/666
--批量重命名
[root@hadoop01 bigdata]# rename .log .doc ./jxlg/*.log
-- 递归强制删除(删除命令一定要谨慎---尤其适用root用户)
[root@hadoop01 bigdata]# rm -rf /home/jx/jxlg/
软件安装操作
原则:最小化安装,够用就好;不要轻易卸载和更新。
- 二进制的安装
相当于windows中的绿色版安装。通常是解压并配置相关文件和环境变量即可。
[root@hadoop01 bigdata]# tar -zxvf /home/jdk-8u152-linux-x64.tar.gz -C /usr/local/
[root@hadoop01 bigdata]# vi /etc/profile
在文件末尾追加如下内容
#my settings
export JAVA_HOME=/usr/local/jdk1.8.0_152/
export PATH=$PATH:$JAVA_HOME/bin
刷新环境变量
[root@hadoop01 bigdata]# source /etc/profile
测试
[root@hadoop01 bigdata]# java
-
rpm安装
rpc相当于windows的.exe或者.msi程序。rpm是一个包管理器命令。rpm的包形式如下: 包名-版本.发现版本.el6.支持系统版本.rpm 优点:离线安装,也简单。rpm安装一般不强制指定安装路径,rpm打包时就已经默认不同文件存储不同路径。 缺点:不能自动解决依赖问题。 什么时候用:有的自动依赖总是安装不上的时候则使用手动。 安装命令 [root@hadoop01 bigdata]# rpm -ivh /home/nc-1.84-22.el6.x86_64.rpm 更新命令 [root@hadoop01 bigdata]# rpm -Uvh /home/nc-1.84-22.el6.x86_64.rpm 查询并过滤命令 [root@hadoop01 bigdata]# rpm -qa | grep nc 卸载命令 [root@hadoop01 bigdata]# rpm -e nc-1.84-22.el6.x86_64 忽略依赖卸载 [root@hadoop01 bigdata]# rpm -e --nodeps nc-1.84-22.el6.x86_64 -
yum安装
yum也是一个对rpm做升级的软件管理工具。
优点:1、能够自动解决依赖安装;2、比较容易升级
缺点:1、需要外网;2、如果没有外网,则需要自己构建本地yum源
查看yum源配置文件
[root@hadoop01 bigdata]# ll /etc/yum.repos.d/
total 32
-rw-r--r--. 1 root root 1664 Sep 5 2019 CentOS-Base.repo --默认使用该文件
-rw-r--r--. 1 root root 1309 Jun 7 11:32 CentOS-CR.repo
-rw-r--r--. 1 root root 649 Sep 5 2019 CentOS-Debuginfo.repo
-rw-r--r--. 1 root root 314 Sep 5 2019 CentOS-fasttrack.repo
-rw-r--r--. 1 root root 630 Sep 5 2019 CentOS-Media.repo
-rw-r--r--. 1 root root 1331 Sep 5 2019 CentOS-Sources.repo
-rw-r--r--. 1 root root 6639 Sep 5 2019 CentOS-Vault.repo
列出包及groups包
[root@hadoop01 bigdata]# yum list | grep sh
列出包
[root@hadoop01 bigdata]# yum grouplist
[root@hadoop01 bigdata]# yum groups
查看可用源
[root@hadoop01 bigdata]# yum repolist
搜索包
[root@hadoop01 bigdata]# yum search ifconfig
查看包信息
[root@hadoop01 bigdata]# yum info zsh
安装指定包
[root@hadoop01 bigdata]# yum -y install zsh
[root@hadoop01 bigdata]# yum -y groupinstall ''
更新包
[root@hadoop01 bigdata]# yum -y update 包名 只更新包
[root@hadoop01 bigdata]# yum -y upgreade 包名 不仅会更新包,可能会更新系统版本
卸载包
[root@hadoop01 bigdata]# yum -y remove zsh
清空缓存
[root@hadoop01 bigdata]# yum clean all
制作缓存
[root@hadoop01 bigdata]# yum makecache
下载自己的yum源
[root@hadoop01 bigdata]# cd /etc/yum.repos.d/
[root@hadoop01 yum.repos.d]# wget http://mirrors.aliyun.com/repo/Centos-7.repo
制作本地yum源?--自己联系
制作在线yum源?--自己联系
-
源码安装
通过包的源码进行编译和安装。 优点: 1 用户可以自己定制软件功能,安装需要的模块,不需要的功能可以不用安装。 2 用户还可以自己选择安装路径,方便管理。 3 卸载软件也很方便,只需删除对应的安装目录即可。 4 能最大程度和服务器平台融合,效率稍微比其他方式高。 5 没有windows所谓的注册表之说。 缺点: 1 安装较为繁琐,需要自己配置 2 安装较为耗时,需要自己编译源码 3 安装较为容易出错,出错也难以解决 源码安装软件一般有以下几个步骤组成:下载解压源码、分析安装平台环境(configure)、编译安装软件(make,make install)。 解压源码 root@hadoop01 home]# tar -zxvf /home/bashdb-4.4-0.92.tar.gz 分析环境 [root@hadoop01 bashdb-4.4-0.92]# ./configure --prefix 安装路径 编译安装 [root@hadoop01 bashdb-4.4-0.92]# make && make install
shell脚本
[root@hadoop01 home]# vi ./auto.sh
#!/bin/bash
#删除文件
dir=/home
#删除文件
rm -rf $dir/bigdata/Centos-7.repo
#创建文件
echo 123 >> $dir/bigdata/myshell.sh
for i in `ls /home`
do
echo $i
done
for i in `ls /home`
do
if [ -f /home/$i ]
then
echo $i
else
echo 'no file'
fi
done
[root@hadoop01 home]# vi ./auto1.sh
#!/bin/bash
#accese input params
param=$1
echo $param
echo $0
echo $#
echo $@
echo $$
for i in $@
do
echo $i
done
# define function
myfunc(){
echo "start func==============="
echo 'now time: '`date`
echo "stop func============="
}
# call myfunc
myfunc
执行权限
[root@hadoop01 home]# chmod a+x ./auto.sh
脚本中注意几个符号:
'' : 单引号中的内容将会被全部打印或者使用
`` : 反引号中的会被当成linux命令来执行
"" : 双引号中的内容会被转义或者取值
$ : 取值
$#:参数个数
$$:当前进程号
$@:全部参数
取第n个位置的参数时,n为2位数的需要使用{}括起来
shell脚本中没有++ 和 --
shell脚本中的么有elseif 只有elif
脚本定时
crontab -e
* * * * * /home/auto1.sh >> /home/auto.log
凌晨2点半
30 2 * * * /home/auto1.sh >> /home/auto.log
每一分钟执行
*/1 * * * * /home/auto1.sh >> /home/auto.log
30 2,3 * * * /home/auto1.sh >> /home/auto.log
注意:
共有六部分组成,分别表示:
* * * * *
分 时 日 月 星期 要运行的命令
解析:
minute: 一小时中的哪一分钟 [0~59]
hour: 一天中的哪个小时 [0~23]
day: 一月中的哪一天 [1~31]
month: 一年中的哪一月 [1~12]
week: 一周中的哪一天 [0~6] 0表示星期天
commands: 执行的命令
书写注意事项
1 全都不能为空,必须填入,不知道的值使用通配符*表示任何时间
2 每个时间字段都可以指定多个值,不连续的值用,间隔,连续的值用-间隔。
3 命令应该给出绝对路径
4 用户必须具有运行所对应的命令或程序的权限
5 */num 表示频率
[root@hadoop01 home]# crontab -l
*/1 * * * * /home/auto1.sh >> /home/auto.log
作业
1、将/home/bigdata/jxlg/下的所有.doc的后缀用脚本修改为.log后缀,不能使用rename命令
#!/bin/bashbasedir=/home/bigdata/jxlg/for i in `find /home/bigdata/jxlg/ -name *.doc | awk -F "." '{print $0}'`do#update suffix of filemv ${i}.doc ${i}.logdone
2、编写shell脚本实现如下功能:
输入数字,如果输入的值是1到5之间,则打印并退出;不在1-5之间则继续输入数字。
提示:使用while循环、使用case … in语法、read语法等
#!/bin/bashwhile:doecho "请输入1-5之间的数字"read num# use casecase $num in1|2|3|4|5) echo "你输入的数字为:${num}"echo "游戏结束"break;;*) echo "你输入的数字:${num}不在1-5之间,请重新输入1-5之间的数字"continueesacdone
3、Hadoop
3.1 为什么要用hadoop
现在的我们,生活在数据大爆炸的年代。国际数据公司已经预测在2020年,全球的数据总量将达到44ZB,经过单位换算后,至少在440亿TB以上,也就是说,全球每人一块1TB的硬盘都存储不下。
扩展:数据大小单位:Byte,KB,MB,GB,TB,PB,EB,ZB,YB,DB,NB
一些数据集的大小更远远超过了1TB,也就是说,数据的存储是一个要解决的问题。同时,硬盘技术也面临一个技术瓶颈,就是硬盘的传输速度(读数据的速度)的提升远远低于硬盘容量的提升。我们看下面这个表格:
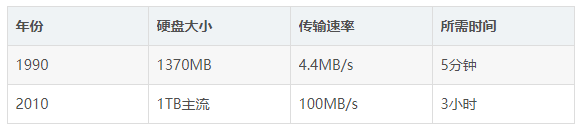
可以看到,容量提升了将近1000倍,而传输速度才提升了20倍,读完一个硬盘的所需要的时间相对来说,更长更久了(已经违反了数据价值的即时性)。读数据都花了这么长时间,更不用说写数据了。
对于如何提高读取数据的效率,我们已经想到解决的方法了,那就是将一个数据集存储到多个硬盘里,然后并行读取。比如1T的数据,我们平均100份存储到100个1TB硬盘上,同时读取,那么读取完整个数据集的时间用不上两分钟。至于硬盘剩下的99%的容量,我们可以用来存储其他的数据集,这样就不会产生浪费。解决读取效率问题的同时,我们也解决了大数据的存储问题。
但是,我们同时对多个硬盘进行读/写操作时,又有了新的问题需要解决:
1、硬件故障问题。一旦使用多个硬件,相对来说,个别硬件产生故障的几率就高,为了避免数据丢失,最常见的做法就是复制(replication):文件系统保存数据的多个复本,一旦发生故障,就可以使用另外的复本。2、读取数据的正确性问题。大数据时代的一个分析任务,就需要结合大部分数据来共同完成分析,因此从一个硬盘上读取的数据要与从其他99个硬盘上读取的数据结合起来使用。那么,在读取过程中,如何保证数据的正确性,就是一个很大的挑战。
针对于上述几个问题,Hadoop为我们提供了一个可靠的且可扩展的存储和分析平台,此外,由于Hadoop运行在商用硬件上且是开源的,因此Hadoop的使用成本是比较低了,在用户的承受范围内。
3.2 Hadoop的简要介绍
Hadoop是一个Apache开源的、免费、分布式的存储和计算平台。
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储
Apache lucene是一个应用广泛的文本搜索系统库。该项目的创始人道格·卡丁在2002年带领团队开发该项目中的子项目Apache Nutch,想要从头打造一个网络搜索引擎系统,在开发的过程中,发现了两个问题,一个是硬件的高额资金投入,另一个是存储问题。2003年和2004年Google先后发表的《GFS》和《MapReduce》论文,给这个团队提供了灵感,并进行了实现,于是NDFS(Nutch分布式文件系统)和MapReduce相继问世。2006年2月份,开发人员将NDFS和MapReduce移出Nutch形成一个独立的子项目,命名为Hadoop(该名字据Doug Cutting所说,是借用了他的孩子给毛绒玩具取得名字)。
3.3 谷歌的三篇论文
- 2003年发表的《GFS》---> Hadoop中的HDFS 基于硬盘不够大、数据存储单份的安全隐患问题,提出的分布式文件系统用于存储的理论思想。 · 解决了如何存储大数据集的问题- 2004年发表的《MapReduce》---> Hadoop中的MapReduce 基于分布式文件系统的计算分析的编程框架模型。移动计算而非移动数据,分而治之。 · 解决了如何快速分析大数据集的问题- 2006年发表的《BigTable》---> Hadoop生态中的Hbase 针对于传统型关系数据库不适合存储非结构化数据的缺点,提出了另一种适合存储大数据集的解决方案
3.4 Hadoop的发展历史
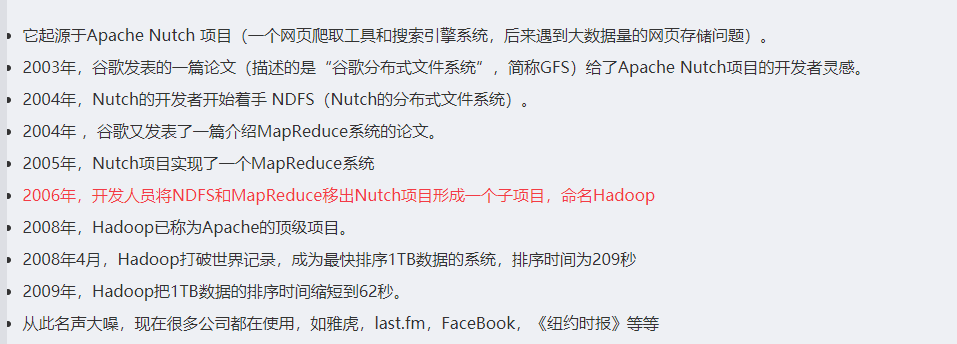
3.5 Hadoop的版本介绍
Hadoop是Apache的一个开源项目,所以很多公司在这个基础上都进行了商业化,加入了自己的特色。Hadoop的发行版中除了有Apache社区提供的hadoop之外,比较出名的公司如cloudera,hortonworks,mapR,华为,DKhadoop等都提供了自己的商业版本,主要是大型公司提供更为专业的技术支持,多数都收费。
- Apache Hadoop(社区版): 原生的Hadoop、开源、免费、社区活跃,更新速度快,适合学习阶段。
0.x
1.x
2.x 建议
3.x 次之建议
- Cloudera Hadoop(CDH版):最成型的商业发行版本。有免费版和收费版本。版本划分清晰,版本更新速度快,对生态圈的其他软件做了很好的兼容性,安全性、稳定性都有增强。支持多种安装方式(Cloudera Manager、YUM、RPM、Tarball)
- Hortonworks Hadoop(HDP):完全开源,安装方便,提供了直观的用户安装界面和配置工具
3.6 Hadoop的官网介绍
2.6.1 apache官网地址和如何进入项目列表
2.6.2 找到Hadoop项目
2.6.3 Hadoop的模块和生态圈
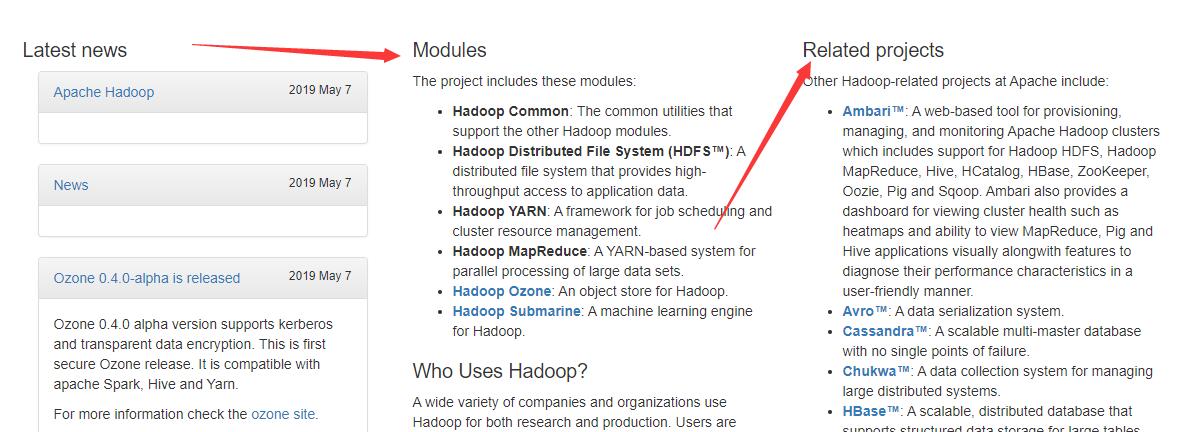
2.6.4 Hadoop的历史版本入口
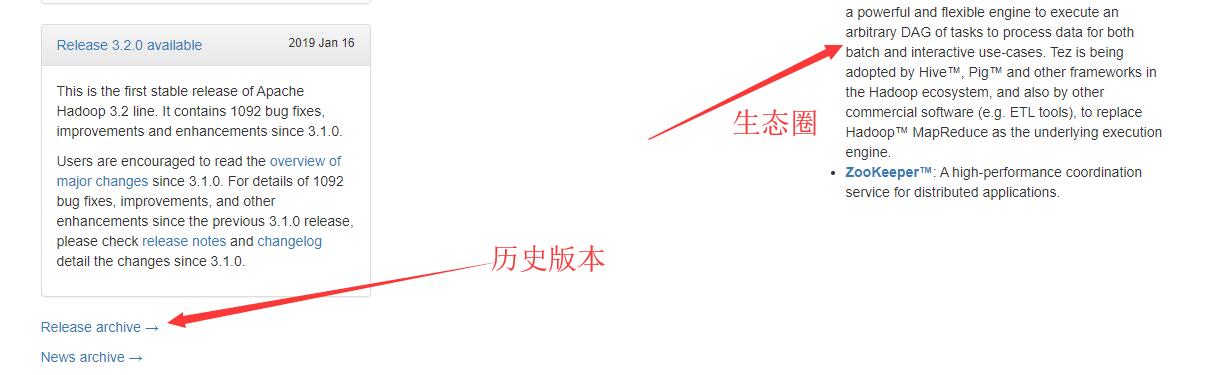
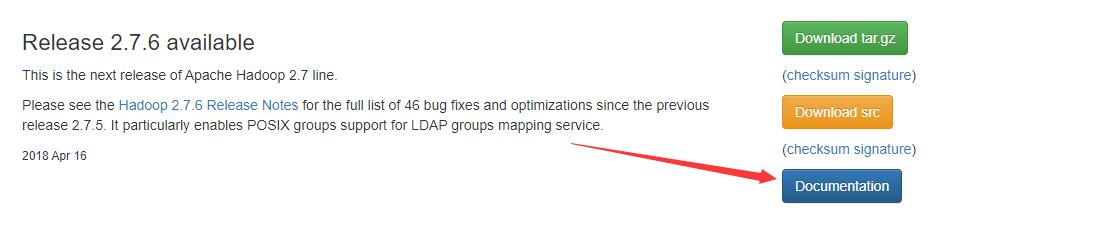
2.6.5 找到Hadoop2.7.6,以及文档入口
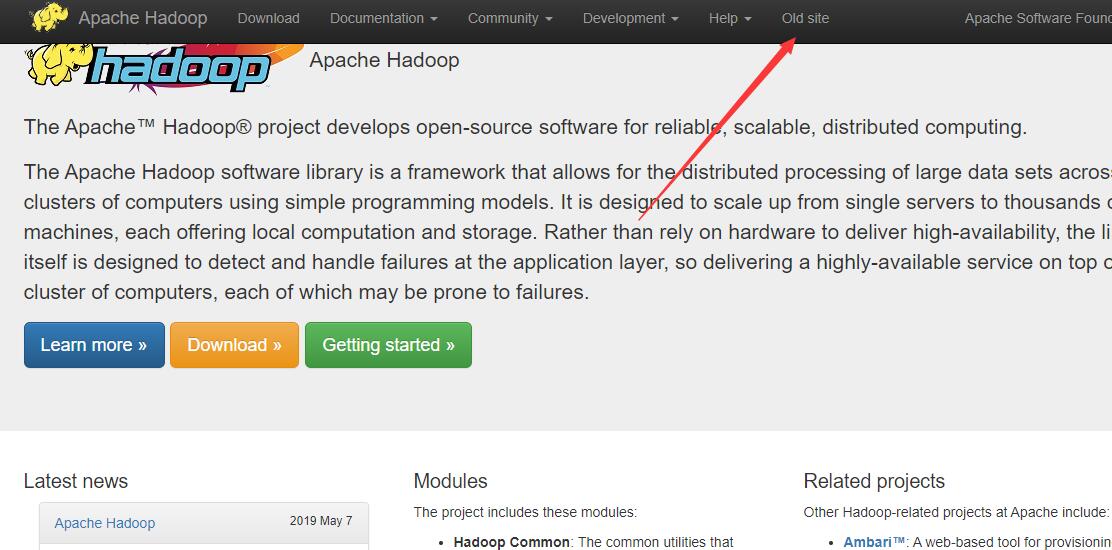
2.6.6 老版本官网入口
3.7 Hadoop的组成部分
hadoop2.0以后的四个模块: - Hadoop Common:Hadoop的通用组件 - Hadoop Distributed File System(HDFS):分布式文件存储系统 - Hadoop YARN:作业调度和资源管理框架 - Hadoop MapReduce:基于YARN的大型数据集并行计算处理框架hadoop3.0新扩展的一个模块: - Hadoop Ozone:Hadoop的对象存储机制 hadoop的核心:HDFS、YARN、MapReduce
3.8 Hadoop的生态系统
参考apache官网:http://hadoop.apache.org/
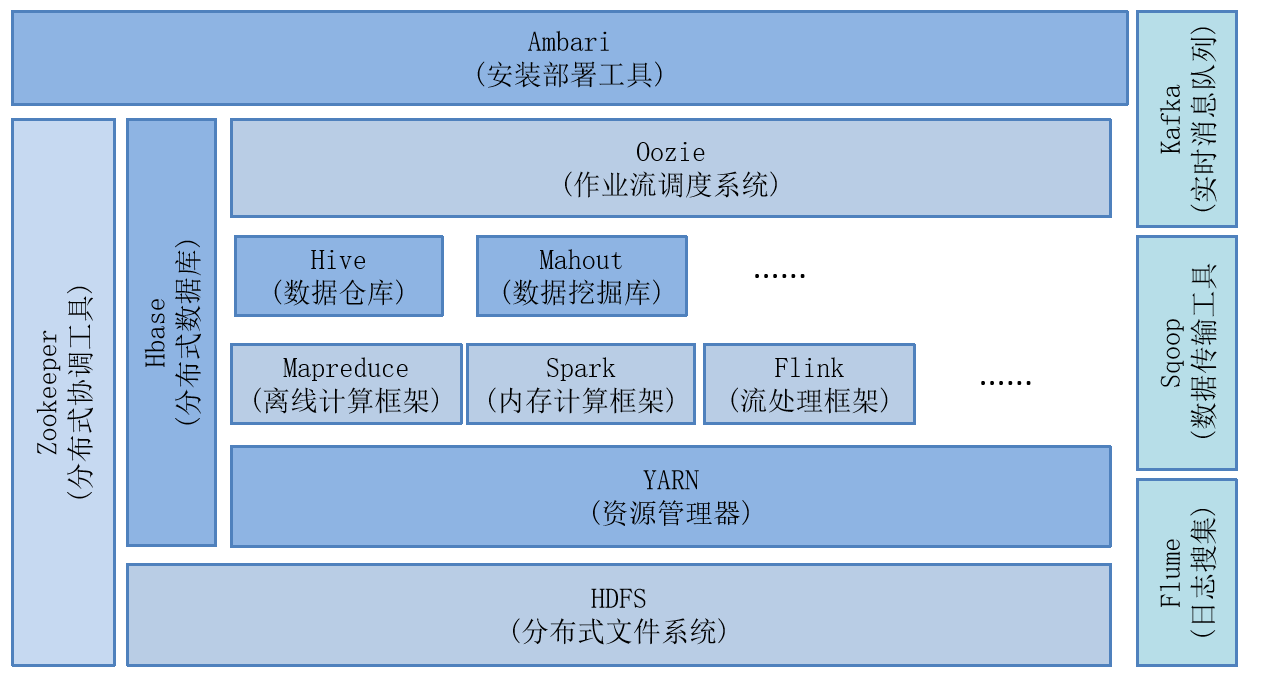
* Hbase
是一个可扩展的分布式数据库,支持大型表格的结构化数据存储。 HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的,而不是基于行的模式。
* Hive
数据仓库基础架构,提供数据汇总和临时查询,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。Hive提供的是一种结构化数据的机制,定义了类似于传统关系数据库中的类SQL语言:Hive QL,通过该查询语言,数据分析人员可以很方便地运行数据分析
业务。
* Spark
Hadoop数据的快速和通用计算引擎。 Spark提供了一个简单而富有表现力的编程模型,支持广泛的应用程序,包括ETL,机器学习,流处理和图计算。
* ZooKeeper
一个面向分布式应用程序的高性能协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
* Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
* Flume(日志收集工具)
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。
* Kafka(分布式消息队列)
Kafka是Linkedin于2010年12月份开源的消息系统,它主要用于处理活跃的流式数据。这些数据包括网站的pv、用户访问了什么内容,搜索了什么内容等。这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计处理。
* Ambari
用于供应,管理和监控Apache Hadoop集群的基于Web的工具。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等。Ambari还提供了一个用于查
看集群健康状况的仪表板,例如热图以及可视化查看MapReduce,Pig和Hive应用程序的功能以及用于诊断其性能特征的功能,以方便用户使用。
* Avro
数据序列化系统。可以将数据结构或者对象转换成便于存储和传输的格式,其设计目标是用于支持数据密集型应用,适合大规模数据的存储与交换。Avro提供了丰富的数据结构类型、快速可压缩的二进制数据格式、存储持久性数据的文件集、远程调用RPC和简单动态语言集成等功能。
* Cassandra
可扩展的多主数据库,没有单点故障。是一套开源分布式NoSQL数据库系统。
* Chukwa
于管理大型分布式系统的数据收集系统(2000+以上的节点, 系统每天产生的监控数据量在T级别)。它构建在Hadoop的HDFS和MapReduce基础之上,继承了Hadoop的可伸缩性和鲁棒性。Chukwa包含一个强大和灵活的工具集,提供了数据的生成、收集、排序、去重、分析和展示等一系列功能,是Hadoop使用者、集群运营人员和管理人员的必备工具。
* Mahout
Apache旗下的一个开源项目,可扩展的机器学习和数据挖掘库
* Pig
用于并行计算的高级数据流语言和执行框架。它简化了使用Hadoop进行数据分析的要求,提供了一个高层次的、面向领域的抽象语言:Pig Latin。
* Tez
一个基于Hadoop YARN的通用数据流编程框架,它提供了一个强大而灵活的引擎,可执行任意DAG任务来处理批处理和交互式用例的数据Hado™生态系统中的Hive™,Pig™和其他框架以及其他商业软件(例如ETL工具)正在采用Tez,以替代Hadoop™MapReduce作为底层执行引擎。
* Oozie(工作流调度器)
一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
* Pig(ad-hoc脚本)
由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具,通常用于进行离线分析。它定义了一种数据流语言—Pig Latin,它是MapReduce编程的复杂性的抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
3.9 Hadoop的安装部署
hadoop必须要依赖jdk,也就是必须要先安装jdk。
1、单机版 : 所有的服务运行在一个jvm中,存储的文件也在linux文件系统中。
2、伪分布式:所有的服务运行在一台服务器中,存储文件在hdfs的集群中。
3、全分布式:不同的服务运行在不同的服务器上,存储文件hdfs的集群中。
3.9.1 单机版
安装步骤:
1、解压hadoop
[root@hadoop01 ~]# tar -zxvf /home/hadoop-2.7.6.tar.gz -C /usr/local/
[root@hadoop01 ~]# ll /usr/local/hadoop-2.7.6/
total 112
drwxr-xr-x. 2 20415 101 194 Apr 18 2018 bin
drwxr-xr-x. 3 20415 101 20 Apr 18 2018 etc
drwxr-xr-x. 2 20415 101 106 Apr 18 2018 include
drwxr-xr-x. 3 20415 101 20 Apr 18 2018 lib
drwxr-xr-x. 2 20415 101 239 Apr 18 2018 libexec
-rw-r--r--. 1 20415 101 86424 Apr 18 2018 LICENSE.txt
-rw-r--r--. 1 20415 101 14978 Apr 18 2018 NOTICE.txt
-rw-r--r--. 1 20415 101 1366 Apr 18 2018 README.txt
drwxr-xr-x. 2 20415 101 4096 Apr 18 2018 sbin
drwxr-xr-x. 4 20415 101 31 Apr 18 2018 share
--1. bin: hadoop的二进制执行命令文件存储目录
--2. sbin: hadoop的执行脚本存储目录
--3. etc: hadoop的配置文件存储目录
--4. lib/libexec: hadoop的资源库存储目录
--5. share: hadoop的共享资源、开发工具和案例存储目录
--6. include: hadoop的工具脚本存储目录
2、配置hadoop的环境变量
[root@hadoop01 ~]# vi /etc/profile
#my settings
export JAVA_HOME=/usr/local/jdk1.8.0_152/
export HADOOP_HOME=/usr/local/hadoop-2.7.6/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新环境变量
[root@hadoop01 ~]# source /etc/profile
测试hadoop环境变量
[root@hadoop01 ~]# hadoop version
Hadoop 2.7.6
3、配置hadoop的hadoop-env.sh文件中的jdk路径
[root@hadoop01 hadoop-2.7.6]# vi ./etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_152/
4、直接测试案例
a. 统计多个文件的单词出现个数 wordcount
[root@hadoop01 hadoop-2.7.6]# mkdir -p /home/data/input
[root@hadoop01 hadoop-2.7.6]# cp ./etc/hadoop/*.xml /home/data/input/
#提交mr的程序
[root@hadoop01 hadoop-2.7.6]# yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /home/data/input/ /home/data/output/00
yarn : 使用yarn命令来提交mapreduce的应用程序
jar : mapreduce程序是jar包
./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar : 需要运行的jar的路径
wordcount : 执行的jar包中包含的类,该类就是做单词个数统计的功能java类
/home/data/input/ : 输入数据,可以是单个文件也可以是目录
/home/data/output/00 : 输出结果数据路径,这个路径一定不能提前创建好
#查看结果
[root@hadoop01 ~]# more /home/data/output/01/*#
b.从多个文件中找出已dfs字符串开头的单词
[root@hadoop01 hadoop-2.7.6]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep /home/data/input /home/data/output/02 'dfs[a-z.]+'
[root@hadoop01 ~]# more /home/data/output/02/*
::::::::::::::
/home/data/output/02/part-r-00000
::::::::::::::
1 dfsadmin
3.9.2 伪分布式
hdfs模块的服务:NameNode、DataNode、SecondaryNameNode
Yarn模块的服务:ResourceManager、NodeManager
自行解压hadoop的压缩包。
-
配置hadoop-env.sh
[root@hadoop01 hadoop-2.7.6]# vi ./etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/local/jdk1.8.0_152/ -
配置core-site.xml
<configuration><!--将如下的内容放到configuration标签中<!-- 配置分布式文件系统的schema和ip以及port,默认8020--><property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000/</value></property></configuration> -
配置hdfs-site.xml
<configuration> <!-- 配置副本数,注意,伪分布模式只能是1。--> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> -
配置mapred-site.xml
[root@hadoop01 hadoop-2.7.6]# mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml<configuration> <!--指定mapreduce程序运行的框架名称--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
配置yarn-site.xml
<configuration> <!--指定mapreduce程序运行的shuffle服务--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> -
配置slaves文件
localhost -
ssh免密登陆
[root@hadoop01 hadoop-2.7.6]# ssh-keygen -t rsaGenerating public/private rsa key pair.Enter file in which to save the key (/root/.ssh/id_rsa):/root/.ssh/id_rsa already exists.Overwrite (y/n)? yEnter passphrase (empty for no passphrase):Enter same passphrase again:Your identification has been saved in /root/.ssh/id_rsa.Your public key has been saved in /root/.ssh/id_rsa.pub.The key fingerprint is:SHA256:HJ1qObJvbfrTXrP5lB21m9XJrJey2xT7bnD0YDj7wdg root@hadoop01The key's randomart image is:+---[RSA 2048]----+| || . . || . o . .|| . + o = *|| . S B X+|| + . o E &|| . . . +o%o|| .. + ..B=o|| .o+.o.o+=+|+----[SHA256]-----+[root@hadoop01 hadoop-2.7.6]# ssh-copy-id hadoop01 -
格式化hdfs
#只需要第一次搭建hdfs的时候执行,以后不能执行。如果执行会将所有数据的数据清除[root@hadoop01 hadoop-2.7.6]# hadoop namenode -format -
测试
--a.启动hdfs和yarn的相关服务[root@hadoop01 hadoop-2.7.6]# start-all.sh[root@hadoop01 hadoop-2.7.6]# jps78369 Jps77556 SecondaryNameNode77175 NameNode77801 ResourceManager77912 NodeManager77308 DataNode--b.查看webui的情况namenode的web ui : 浏览器输入 http://192.168.216.111:50070SecondaryNameNode的web ui :浏览器输入 http://192.168.216.111:50090ResourceManager的web ui :浏览器输入 http://192.168.216.111:8088web ui访问效果如下:
--c. 测试hdfs的读写
[root@hadoop01 hadoop-2.7.6]# hdfs dfs -put /home/data/input/stu /
[root@hadoop01 hadoop-2.7.6]# hdfs dfs -cat /stu
hello ganzhou ganzhou is nice
ganzhou is better
jxlg gxlg jxlg jxlg
[root@hadoop01 hadoop-2.7.6]# hdfs dfs -get /stu ./stu1
[root@hadoop01 hadoop-2.7.6]# cat ./stu1
hello ganzhou ganzhou is nice
ganzhou is better
jxlg gxlg jxlg jxlg
--d.测试yarn是否ok
[root@hadoop01 hadoop-2.7.6]# yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /stu /output/01
[root@hadoop01 hadoop-2.7.6]# hdfs dfs -cat hdfs://hadoop01:9000/output/01/*
better 1
ganzhou 3
gxlg 1
hello 1
is 2
jxlg 3
nice 1
作业
1、安装部署好hadoop的伪分布式。上传我们的ods_user_fanslist文件在hdfs的/data目录下,data目录自己创建,然后上传将文件名字修改未ods_user_fanslist.log。
[root@hadoop01 ~]# hdfs dfs -mkdir /data[root@hadoop01 ~]# hdfs dfs -put /home/ods_user_fanslist /data/ods_user_fanslist.log
2、将发给大家的ods_user_fanslist数据文件使用伪分布式来统计词频个数,跑完之后截图(无论对错)
[root@hadoop01 ~]# yarn jar /usr/local/hadoop-2.7.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /data/ods_user_fanslist.log /output/02
3.9.3 全分布式
-
规划
ip host 服务 备注 192.168.216.111 hadoop01 NameNode、DataNode、ResourceManager、NodeManager、historyserver 192.168.216.112 hadoop02 SecondaryNameNode、DataNode、NodeManager 192.168.216.113 hadoop03 DataNode、NodeManager -
克隆服务器
将虚拟机关闭,选中一个虚拟机,右键->管理->克隆,如下图所示:
-
克隆后修改
1、修改hadoop02的主机名 #临时修改 hostnamectl set-hostname hadoop02 #永久修改 vi /etc/hostname hadoop02 2、修改ip vi /etc/sysconfig/network-script/ifcfg-ens33 将192.168.216.111修改为192.168.216.112 ===== hadoop03参考如上的两部就可以hadoop02和hadoop03进行远程连接:
-
免登录配置
原则:老大到小弟需要免登录。基于上述的hdfs的架构,免登录方向为: hadoop01->hadoop01 hadoop01->hadoop02 hadoop01->hadoop03 hadoop01之上操作 [root@hadoop01 ~]# ssh-keygen -t rsa #分发 [root@hadoop01 ~]# ssh-copy-id hadoop01 [root@hadoop01 ~]# ssh-copy-id hadoop02 [root@hadoop01 ~]# ssh-copy-id hadoop03 #测试,不需要输入密码即可 [root@hadoop01 ~]# ssh hadoop01 Last login: Thu Jun 10 09:37:17 2021 from hadoop01 [root@hadoop01 ~]# exit logout Connection to hadoop01 closed. [root@hadoop01 ~]# ssh hadoop02 Last login: Thu Jun 10 09:37:34 2021 from hadoop01 [root@hadoop02 ~]# exit logout Connection to hadoop02 closed. [root@hadoop01 ~]# ssh hadoop03 Last login: Thu Jun 10 09:23:03 2021 from 192.168.216.1 [root@hadoop03 ~]# exit logout Connection to hadoop03 closed. -
删除原有的hadoop
[root@hadoop01 ~]# rm -rf /usr/local/hadoop-2.7.6/share/doc/ [root@hadoop02 ~]# rm -rf /usr/local/hadoop-2.7.6/ [root@hadoop03 ~]# rm -rf /usr/local/hadoop-2.7.6/ -
配置hadoop-env.sh
[root@hadoop01 hadoop-2.7.6]# vi ./etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/local/jdk1.8.0_152/ -
配置core-site.xml
<configuration> <!-- hdfs的地址名称:schame,ip,port--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000/</value> </property> <!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-2.7.6/tmp</value> </property> </configuration> -
配置hdfs-site.xml
<!-- namenode守护进程管理的元数据文件fsimage存储的位置--> <property> <name>dfs.namenode.name.dir</name> <value>/data/dfs/name</value> </property> <!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处--> <property> <name>dfs.datanode.data.dir</name> <value>/data/dfs/data</value> </property> <!-- 块的副本数--> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 块的大小(128M),下面的单位是字节--> <property> <name>dfs.blocksize</name> <value>134217728</value> </property> <!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop02:50090</value> </property> <!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局--> <property> <name>dfs.namenode.http-address</name> <value>hadoop01:50070</value> </property> -
配置mapred-site.xml
<configuration> <!-- 指定mapreduce使用yarn资源管理器--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 配置作业历史服务器的地址--> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop01:10020</value> </property> <!-- 配置作业历史服务器的http地址--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop01:19888</value> </property> </configuration> -
配置yarn-site.xml
<!-- 指定yarn的shuffle技术--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定resourcemanager的主机名--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <!--下面的可选--> <!--指定shuffle对应的类 --> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <!--配置resourcemanager的内部通讯地址--> <property> <name>yarn.resourcemanager.address</name> <value>hadoop01:8032</value> </property> <!--配置resourcemanager的scheduler的内部通讯地址--> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoop01:8030</value> </property> <!--配置resoucemanager的资源调度的内部通讯地址--> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoop01:8031</value> </property> <!--配置resourcemanager的管理员的内部通讯地址--> <property> <name>yarn.resourcemanager.admin.address</name> <value>hadoop01:8033</value> </property> <!--配置resourcemanager的web ui 的监控页面--> <property> <name>yarn.resourcemanager.webapp.address</name> <value>hadoop01:8088</value> </property> -
配置slaves
hadoop01hadoop02hadoop03 -
将hadoop01的hadoop整个安装目录分发到其他服务器中
集群中保障每个服务器配置一样。[root@hadoop01 ~]# scp -r /usr/local/hadoop-2.7.6/ hadoop02:/usr/local/[root@hadoop01 ~]# scp -r /usr/local/hadoop-2.7.6/ hadoop03:/usr/local/ -
格式化namenode
因为集群第一次启动需要格式化,以后不能格式化。[root@hadoop01 ~]# hadoop namenode -format -
启动命令
-- 全启动(启动hdfs和yarn模块)[root@hadoop01 ~]# start-all.sh[root@hadoop01 ~]# stop-all.sh-- 模块化启动[root@hadoop01 ~]# start-dfs.sh[root@hadoop01 ~]# start-yarn.sh[root@hadoop01 ~]# stop-dfs.sh[root@hadoop01 ~]# stop-yarn.sh-- 单个启动[root@hadoop01 ~]# hadoop-daemon.sh start [namenode、datanode、secondarynamenode][root@hadoop01 ~]# yarn-daemon.sh start [resourcemanager、nodemanager][root@hadoop01 ~]# hadoop-daemon.sh stop [namenode、datanode、secondarynamenode][root@hadoop01 ~]# yarn-daemon.sh stop [resourcemanager、nodemanager][root@hadoop01 ~]# mr-jobhistory-daemon.sh start historyserver[root@hadoop01 ~]# mr-jobhistory-daemon.sh stop historyserver--多个启动[root@hadoop01 ~]# yarn-daemons.sh start [datanode、namenode][root@hadoop01 ~]# yarn-daemons.sh start [nodemanager] -
启动脚本
start-all.sh里面封装的是两个模块启东脚本。 -
启动测试
[root@hadoop01 ~]# start-all.sh 1、查看进程 [root@hadoop01 hadoop-2.7.6]# jps 18592 NodeManager 17426 JobHistoryServer 18468 ResourceManager 17909 DataNode 14742 NameNode 22301 Jps [root@hadoop02 ~]# jps 2673 DataNode 2773 SecondaryNameNode 3303 Jps 3085 NodeManager [root@hadoop03 ~]# jps 6944 NodeManager 6629 DataNode 7145 Jps 2、再windows中配置主机名和ip的映射 C:\Windows\System32\drivers\etc\hosts 再末尾追加如下内容并保存 192.168.216.111 hadoop01 192.168.216.112 hadoop02 192.168.216.113 hadoop03 3、查看webui,都能看到页面 namenode:http://hadoop01:50070 secondarynamenode:http://hadoop02:50090 resourcemanager:http://hadoop01:8088 historyserver:http://hadoop01:19888 4、操作hdfs [root@hadoop03 ~]# hdfs dfs -put /home/bigdata/myshell.sh /myshell [root@hadoop03 ~]# hdfs dfs -cat /myshell 123 123 5、判断yarn是否能ok [root@hadoop03 ~]# yarn jar /usr/local/hadoop-2.7.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /myshell /output/01 [root@hadoop03 ~]# hdfs dfs -cat /output/01/* 123 2
3.10 hdfs shell操作
同城两种形式访问文件系统:
1、hdfs dfs -命令
2、hadoop fs -命令
上传、下载、删除、创建目录、列出、查看,更多可以查看帮组:
[root@hadoop01 home]# hdfs dfs -help
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
#上传
[root@hadoop01 home]# hdfs dfs -put /home/bigdata /
[root@hadoop01 home]# hdfs dfs -copyFromLocal /home/bigdata /
[root@hadoop01 home]# hdfs dfs -moveFromLocal /home/bigdata / #会删除本地源
#下载
[root@hadoop01 home]# hdfs dfs -get /myshell /home/myshell1
[root@hadoop01 home]# hdfs dfs -copyToLocal /home/bigdata /
#查看
[root@hadoop01 home]#hdfs dfs -cat /myshell
[root@hadoop01 home]#hdfs dfs -text /myshell
[root@hadoop01 home]#hdfs dfs -tail /myshell
#复制修改
[root@hadoop01 home]#hdfs dfs -cp /myshell /myshell1
[root@hadoop01 home]# hdfs dfs -mv /myshell /myshell.sh
#创建目录
root@hadoop01 home]# hdfs dfs -mkdir -p /data/01/02
#列出
[root@hadoop01 home]# hdfs dfs -ls /output
[root@hadoop01 home]# hadoop fs -ls /
#递归列出
[root@hadoop01 home]# hdfs dfs -ls -R /
#删除
[root@hadoop01 home]# hdfs dfs -rm /myshell1
[root@hadoop01 home]# hdfs dfs -rmr /output
#修改副本
[root@hadoop01 home]# hdfs dfs -setrep 2 /myshell.sh
Replication 2 set: /myshell.sh
3.11 HDFS块概念
3.11.1 HDFS的块
HDFS与其他普通文件系统一样,同样引入了块(Block)的概念,并且块的大小是固定的。但是不像普通文件系统那样小,而是根据实际需求可以自定义的。块是HDFS系统当中的最小存储单位,在hadoop2.x中默认大小为128MB(hadoop1.x中的块大小为64M,hadoop 3.x中块大小为256M)。在HDFS上的文件会被拆分成多个块,每个块作为独立的单元进行存储。多个块存放在不同的DataNode上,整个过程中 HDFS系统会保证一个块存储在一个数据节点上 。但值得注意的是 如果某文件大小或者文件的最后一个块没有到达128M,则不会占据整个块空间 。
我们来看看HDFS的设计思想:以下图为例,来进行解释。
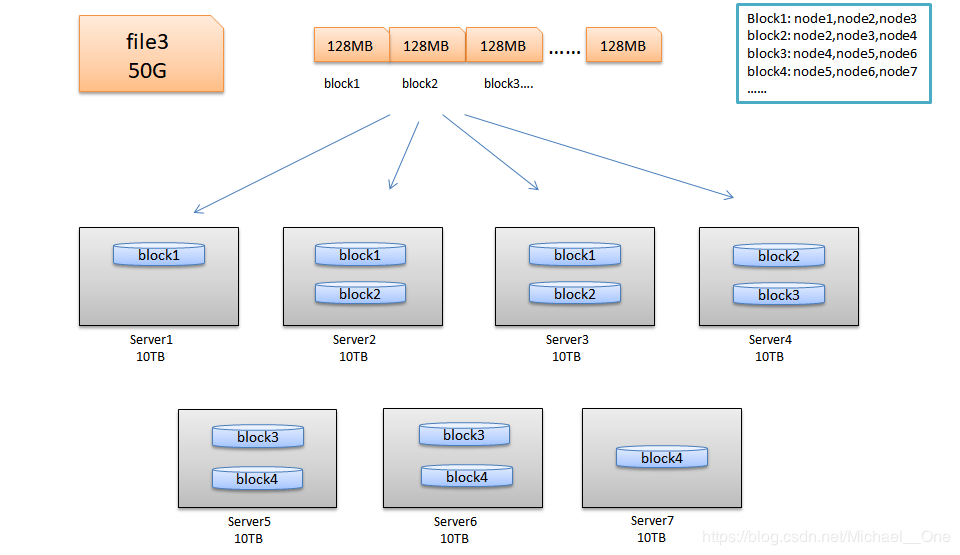
查看块数据:
[root@hadoop02 ~]# cat /data/dfs/data/current/BP-151581512-192.168.216.111-1623291901655/current/finalized/subdir0/subdir0/blk_1073741832
3.11.2 HDFS的块大小
HDFS上的块大小为什么会远远大于传统文件?
1. 目的是为了最小化寻址开销时间。
在I/O开销中,机械硬盘的寻址时间是最耗时的部分,一旦找到第一条记录,剩下的顺序读取效率是非常高的,因此以块为单位读写数据,可以尽量减少总的磁盘寻道时间。
HDFS寻址开销不仅包括磁盘寻道开销,还包括数据块的定位开销,当客户端需要访问一个文件时,首先从名称节点获取组成这个文件的数据块的位置列表,然后根据位置列表获取实际存储各个数据块的数据节点的位置,最后,数据节点根据数据块信息在本地Linux文件系统中找到对应的文件,并把数据返回给客户端,设计成一个比较大的块,可以减少每个块儿中数据的总的寻址开销,相对降低了单位数据的寻址开销
磁盘的寻址时间为大约在5~15ms之间,平均值为10ms,而最小化寻址开销时间普遍认为占1秒的百分之一是最优的,那么块大小的选择就参考1秒钟的传输速度,比如2010年硬盘的传输速率是100M/s,那么就选择块大小为128M。
2. 为了节省内存的使用率
一个块的元数据大约150个字节。1亿个块,不论大小,都会占用20G左右的内存。因此块越大,集群相对存储的数据就越多。所以暴漏了HDFS的一个缺点,不适合存储小文件(杀鸡用牛刀的感觉)
3.11.3 块的相关参数设置
当然块大小在默认配置文件hdfs-default.xml中有相关配置,我们可以在hdfs-site.xml中进行重置
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>默认块大小,以字节为单位。可以使用以下后缀(不区分大小写):k,m,g,t,p,e以重新指定大小(例如128k, 512m, 1g等)</description>
</property>
<property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value>1048576</value>
<description>以字节为单位的最小块大小,由Namenode在创建时强制执行时间。这可以防止意外创建带有小块的文件降低性能。</description>
</property>
<property>
<name>dfs.namenode.fs-limits.max-blocks-per-file</name>
<value>1048576</value>
<description>每个文件的最大块数,由写入时的Namenode执行。这可以防止创建降低性能的超大文件</description>
</property>
3.11.4 HDFS块的存储位置
在hdfs-site.xml中我们配置过下面这个属性,这个属性的值就是块在linux系统上的存储位置
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dfs/data</value>
</property>
自己可以去实际目录里看一下哦
3.11.5 HDFS的优点
1. 高容错性(硬件故障是常态):数据自动保存多个副本,副本丢失后,会自动恢复
2. 适合大数据集:GB、TB、甚至PB级数据、千万规模以上的文件数量,1000以上节点规模。
3. 数据访问: 一次性写入,多次读取;保证数据一致性,安全性
4. 构建成本低:可以构建在廉价机器上。
5. 多种软硬件平台中的可移植性
6. 高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
7. 高可靠性:Hadoop的存储和处理数据的能力值得人们信赖.
3.11.6 HDFS的缺点
1. 不适合做低延迟数据访问:
HDFS的设计目标有一点是:处理大型数据集,高吞吐率。这一点势必要以高延迟为代价的。因此HDFS不适合处理用户要求的毫秒级的低延迟应用请求
2. 不适合小文件存取:
一个是大量小文件需要消耗大量的寻址时间,违反了HDFS的尽可能减少寻址时间比例的设计目标。第二个是内存有限,一个block元数据大内存消耗大约为150个字节,存储一亿个block和存储一亿个小文件都会消耗20G内存。因此相对来说,大文件更省内存
3. 不适合并发写入,文件随机修改:
HDFS上的文件只能拥有一个写者,仅仅支持append操作。不支持多用户对同一个文件的写操作,以及在文件任意位置进行修改
作业
1、将hadoop的分布式集群安装部署好。测试能上传文件和跑mr的作业即可。
2、先再windows中安装maven、idea两个软件,如果windows中没有jdk的则自行安装jdk1.8版本。
3.12 HDFS的体系结构
3.12.1 体系结构解析
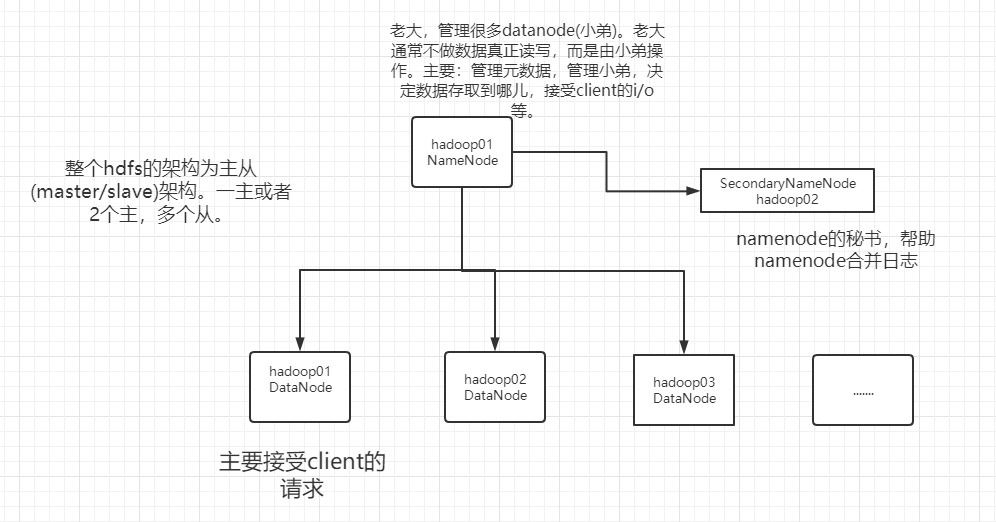
HDFS采用的是master/slaves这种主从的结构模型来管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端)、Namenode(名称节点)、Datanode(数据节点)和SecondaryNameNode。
真正的一个HDFS集群包括一个Namenode(或者多个)和若干数目的Datanode。
Namenode是一个中心服务器,负责管理文件系统的命名空间 (Namespace ),它在内存中维护着命名空间的最新状态,同时并持久性文件(fsimage和edit)进行备份,防止宕机后,数据丢失。namenode还负责管理客户端对文件的访问,比如权限验证等。
集群中的Datanode一般是一个节点运行一个Datanode进程,真正负责管理客户端的读写请求,在Namenode的统一调度下进行数据块的创建、删除和复制等操作。数据块实际上都是保存在Datanode本地的Linux文件系统中的。每个Datanode会定期的向Namenode发送数据,报告自己的状态(我们称之为心跳机制)。没有按时发送心跳信息的Datanode会被Namenode标记为“宕机”,不会再给他分配任何I/O请求。
用户在使用Client进行I/O操作时,仍然可以像使用普通文件系统那样,使用文件名去存储和访问文件,只不过,在HDFS内部,一个文件会被切分成若干个数据块,然后被分布存储在若干个Datanode上。
比如,用户在Client上需要访问一个文件时,HDFS的实际工作流程如此:客户端先把文件名发送给Namenode,Namenode根据文件名找到对应的数据块信息及其每个数据块所在的Datanode位置,然后把这些信息发送给客户端。之后,客户端就直接与这些Datanode进行通信,来获取数据(这个过程,Namenode并不参与数据块的传输)。这种设计方式,实现了并发访问,大大提高了数据的访问速度。
HDFS集群中只有唯一的一个Namenode,负责所有元数据的管理工作。这种方式保证了Datanode不会脱离Namenode的控制,同时,用户数据也永远不会经过Namenode,大大减轻了Namenode的工作负担,使之更方便管理工作。通常在部署集群中,我们要选择一台性能较好的机器来作为Namenode。当然,一台机器上也可以运行多个Datanode,甚至Namenode和Datanode也可以在一台机器上,只不过实际部署中,通常不会这么做的
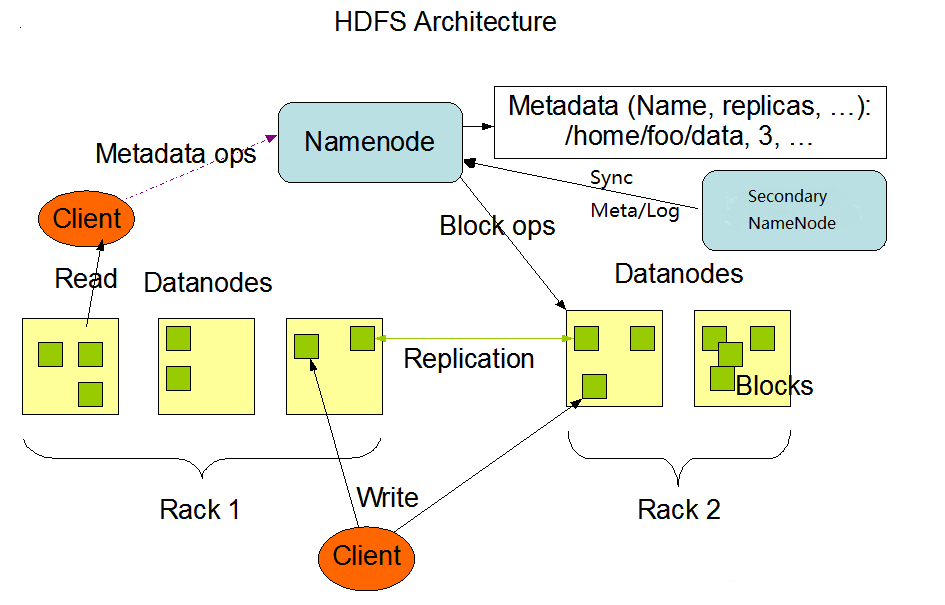
3.12.2 HDFS进程之NameNode
- namenode进程只有一个(HA除外)
- 管理HDFS的命名空间,并以fsimage和edit进行持久化保存。
- 在内存中维护数据块的映射信息
- 实施副本冗余策略
- 处理客户端的访问请求
3.12.3 HDFS进程之DataNode
- 存储真正的数据(块进行存储)
- 执行数据块的读写操作
- 心跳机制(3秒)
3.12.4 HDFDS进程之SecondaryNamennode
- 帮助NameNode合并fsimage和edits文件
- 不能实时同步,不能作为热备份节点
3.12.5 HDFS的Client接口
- HDFS实际上提供了各种语言操作HDFS的接口。
- 与NameNode进行交互,获取文件的存储位置(读/写两种操作)
- 与DataNode进行交互,写入数据,或者读取数据
- 上传时分块进行存储,读取时分片进行读取
3.12.6 映像文件fsimage
命名空间指的就是文件系统树及整棵树内的所有文件和目录的元数据,每个Namenode只能管理唯一的一命名空间。HDFS暂不支持软链接和硬连接。Namenode会在内存里维护文件系统的元数据,同时还使用fsimage和edit日志两个文件来辅助管理元数据,并持久化到本地磁盘上。
- fsimage
命名空间镜像文件,它是文件系统元数据的一个完整的永久检查点,内部维护的是最近一次检查点的文件系统树和整棵树内部的所有文件和目录的元数据,如修改时间,访问时间,访问权限,副本数据,块大小,文件的块列表信息等等。
fsimage默认存储两份,是最近的两次检查点
- 使用XML格式查看fsimage文件:
[root@qianfeng01 current]# hdfs oiv -i 【fsimage_xxxxxxx】 -o 【目标文件路径】 -p XML
案例如下:
[root@hadoop01 ~]# hdfs oiv -i /data/dfs/name/current/fsimage_0000000000000000155 -o /home/meta.xml -p XML
[root@hadoop01 ~]# more /home/meta.xml
3.12.7 日志文件edit
集群正常运行时,客户端的所有更新操作(如打开、关闭、创建、删除、重命名等)除了在内存中维护外,还会被写到edit日志文件中,而不是直接写入fsimage映像文件。
因为对于分布式文件系统而言,fsimage映像文件通常都很庞大,如果客户端所有的更新操作都直接往fsimage文件中添加,那么系统的性能一定越来越差。相对而言,edit日志文件通常都要远远小于fsimage,一个edit日志文件最大64M,更新操作写入到EditLog是非常高效的。
那么edit日志文件里存储的到底是什么信息呢,我们可以将edit日志文件转成xml文件格式,进行查看
查看editlog文件的方式:
[root@qianfeng01 current]# hdfs oev -i 【edits_inprogress_xxx】 -o 【目标文件路径】-p XML
参考xml文件后,我们可以知道日志文件里记录的内容有:
1. 行为代码:比如 打开、创建、删除、重命名、关闭
2. 事务id
3. inodeid
4. 副本个数
5. 修改时间
6. 访问时间
7. 块大小
8. 客户端信息
9. 权限等
10. 块id等
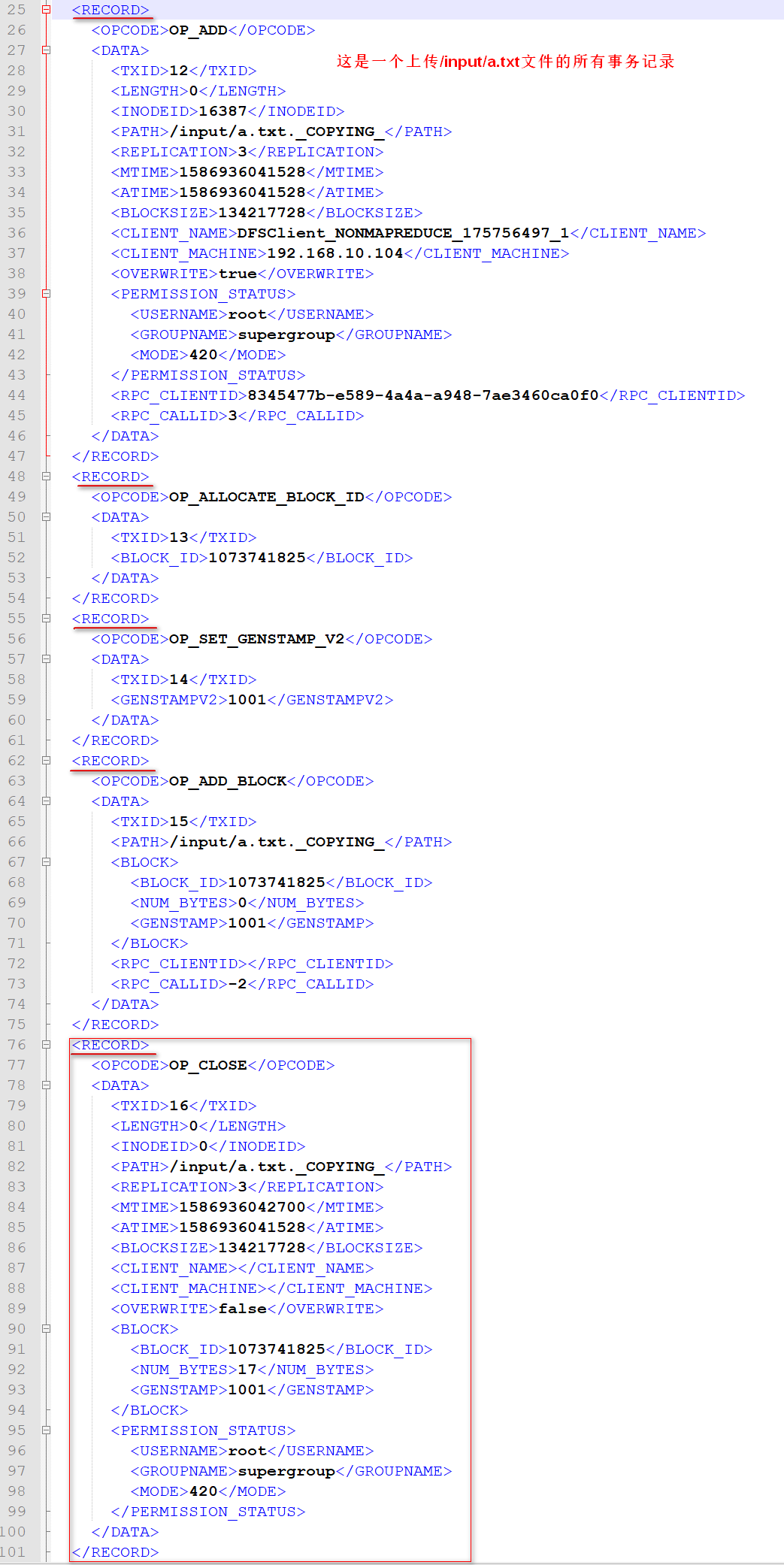
3.13 HDFS的工作机制(重点)
3.13.1 开机启动Namenode过程
非第一次启动集群的启动流程
我们应该知道,在启动namenode之前,内存里是没有任何有关于元数据的信息的。那么启动集群的过程是怎样的呢?下面来叙述一下:
第一步:Namenode在启动时,会先加载name目录下最近的fsimage文件.
将fsimage里保存的元数据加载到内存当中,这样内存里就有了之前检查点里存储的所有元数据。但是还少了从最近一次检查时间点到关闭系统时的部分数据,也就是edit日志文件里存储的数据。
第二步:加载剩下的edit日志文件
将从最近一次检查点到目前为止的所有的日志文件加载到内存里,重演一次客户端的操作,这样,内存里就是最新的文件系统的所有元数据了。
第三步:进行检查点设置(满足条件会进行)
namenode会终止之前正在使用的edit文件,创建一个空的edit日志文件。然后将所有的未合并过的edit日志文件和fsimage文件进行合并,产生一个新的fsimage.
第四步:处于安全模式下,等待datanode节点的心跳反馈,当收到99.9%的块的至少一个副本后,退出安全模式,开始转为正常状态。
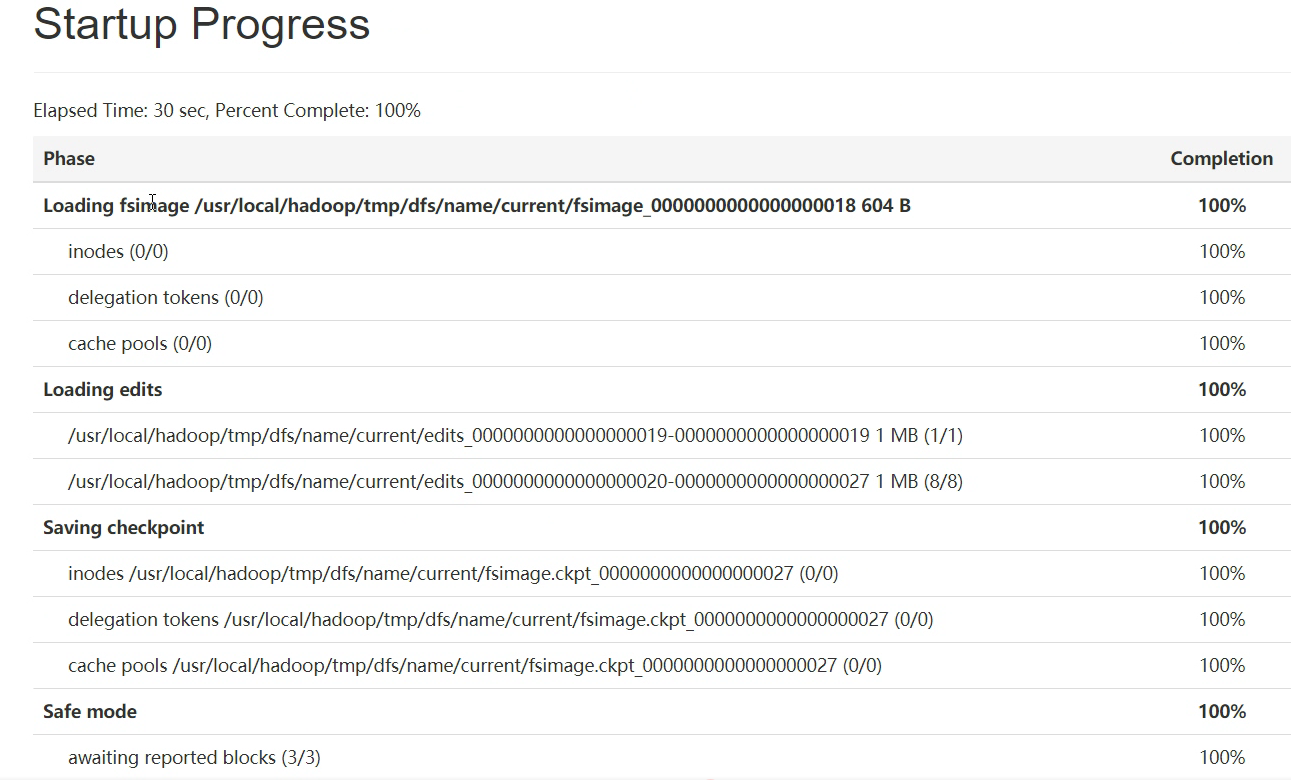
注意:格式化集群后,第一次启动集群的特点,参考下图
小知识:
(1) 滚动编辑日志(前提必须启动集群)
1.可以强制滚动
[bigdata@hadoop102 current]$ hdfs dfsadmin -rollEdits
2.可以等到edits.inprogress满64m生成edits文件
3.可以等操作数量达到100万次
4.时间到了,默认1小时
注意:在2,3,4时发生滚动,会进行checkpoint
(2) 镜像文件什么时候产生
可以在namenode启动时加载镜像文件和编辑日志
也可以在secondarynamenode生成的fsimage.chkpoint文件重新替换namenode原来的fsimage文件时
(3) namenode目录说明
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jwW1lC1o-1624008373527)(E:\01 江西理工\文档\02 千锋大数据技术栈之hdfs\hdfs.assets\edits文件.png)]
3.13.2 安全模式介绍
Namenode启动时,首先要加载fsimage文件到内存,并逐条执行editlog文件里的事务操作,在这个期间一但在内存中成功建立文件系统元数据的映像,就会新创建一个fsimage文件(该操作不需要SecondaryNamenode)和一个空的editlog文件。在这个过程中,namenode是运行在安全模式下的,Namenode的文件系统对于客户端来说是只读的,文件修改操作如写,删除,重命名等均会失败。
系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中。在系统的正常操作期间,namenode会在内存中保留所有块位置的映射信息。在安全模式下,各个datanode会向namenode发送最新的块列表信息,如果满足“最小副本条件”,namenode会在30秒钟之后就退出安全模式,开始高效运行文件系统.所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。
PS:启动一个刚刚格式化完的集群时,HDFS还没有任何操作呢,因此Namenode不会进入安全模式。
9.2.1 查看namenode是否处于安全模式:
[root@qianfeng01 current]# hdfs dfsadmin -safemode get
Safe mode is ON
9.2.2 管理员可以随时让Namenode进入或离开安全模式,这项功能在维护和升级集群时非常关键
[root@hadoop01 ~]# hdfs dfsadmin -safemode get
Safe mode is OFF
[root@hadoop01 ~]# hdfs dfsadmin -safemode enter
Safe mode is ON
[root@hadoop01 ~]# hdfs dfs -put /home/auto.log /
put: Cannot create file/auto.log._COPYING_. Name node is in safe mode.
[root@hadoop01 ~]# hdfs dfs -ls /auto.log
ls: `/auto.log': No such file or directory
[root@hadoop01 ~]# hdfs dfsadmin -safemode leave
9.2.3 将下面的属性的值设置为大于1,将永远不会离开安全模式
<property>
<name>dfs.namenode.safemode.threshold-pct</name>
<value>0.999f</value>
</property>
9.2.4 有时,在安全模式下,用户想要执行某条命令,特别是在脚本中,此时可以先让安全模式进入等待状态
[root@qianfeng01 current]# hdfs dfsadmin -safemode wait
# command to read or write a file
3.13.3 DataNode与NameNode通信(心跳机制)
整个Hadoop的是基于RPC作为通信框架的。
1. hdfs是qianfeng01/slave结构,qianfeng01包括namenode和resourcemanager,slave包括datanode和nodemanager
2. qianfeng01启动时会开启一个IPC服务,等待slave连接
3. slave启动后,会主动连接IPC服务,并且每隔3秒链接一次,这个时间是可以调整的,设置heartbeat,这个每隔一段时间连接一次的机制,称为心跳机制。Slave通过心跳给qianfeng01汇报自己信息,qianfeng01通过心跳下达命令。
4. Namenode通过心跳得知datanode状态。Resourcemanager通过心跳得知nodemanager状态
5. 当qianfeng01长时间没有收到slave信息时,就认为slave挂掉了。
注意:超长时间计算结果:默认为10分钟30秒
属性:dfs.namenode.heartbeat.recheck-interval 的默认值为5分钟 #Recheck的时间单位为毫秒
属性:dfs.heartbeat.interval 的默认值时3秒 #heartbeat的时间单位为秒
计算公式:2*recheck+10*heartbeat
3.13.4 SecondayNamenode的工作机制(检查点机制)
SecondaryNamenode,是HDFS集群中的重要组成部分,它可以辅助Namenode进行fsimage和editlog的合并工作,减小editlog文件大小,以便缩短下次Namenode的重启时间,能尽快退出安全模式。
两个文件的合并周期,称之为检查点机制(checkpoint),是可以通过hdfs-default.xml配置文件进行修改的:
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>两次检查点间隔的秒数,默认是1个小时</description>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>txid执行的次数达到100w次,也执行checkpoint</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description>60秒一检查txid的执行次数</description>
</property>
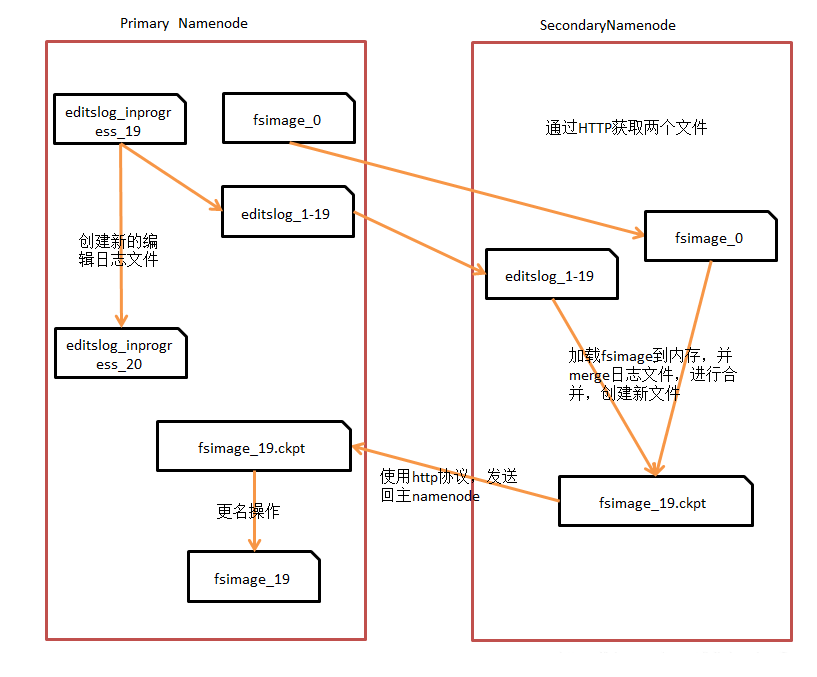
通过上图,可以总结如下:
1. SecondaryNamenode请求Namenode停止使用正在编辑的editlog文件,Namenode会创建新的editlog文件(小了吧),同时更新seed_txid文件。
2. SecondaryNamenode通过HTTP协议获取Namenode上的fsimage和editlog文件。
3. SecondaryNamenode将fsimage读进内存当中,并逐步分析editlog文件里的数据,进行合并操作,然后写入新文件fsimage_x.ckpt文件中。
4. SecondaryNamenode将新文件fsimage_x.ckpt通过HTTP协议发送回Namenode。
5. Namenode再进行更名操作。
3.13.5 HDFS 管理命令
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZZClo2bh-1624008373529)(E:\01 江西理工\文档\02 千锋大数据技术栈之hdfs\hdfs.assets\20190924200505.jpg)]
3.14 数据流(重点)
3.14.1 读流程的详解
读操作:
- hdfs dfs -get /file02 ./file02
- hdfs dfs -copyToLocal /file02 ./file02
- FSDataInputStream fsis = fs.open("/input/a.txt");
- fsis.read(byte[] a)
- fs.copyToLocal(path1,path2)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sd0mgDuj-1624008373530)(E:\01 江西理工\文档\02 千锋大数据技术栈之hdfs\hdfs.assets\20190117100039726.png)]
1. 客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象是DistributedFileSystem,它通过使用远程过程调用(RPC)来调用namenode,以确定文件起始块的位置
2. 对于每一个块,NameNode返回存有该块副本的DataNode地址,并根据距离客户端的远近来排序。
3. DistributedFileSystem实例会返回一个FSDataInputStream对象(支持文件定位功能)给客户端以便读取数据,接着客户端对这个输入流调用read()方法
4. FSDataInputStream随即连接距离最近的文件中第一个块所在的DataNode,通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端
5. 当读取到块的末端时,FSInputStream关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode
6. 客户端从流中读取数据时,块是按照打开FSInputStream与DataNode的新建连接的顺序读取的。它也会根据需要询问NameNode来检索下一批数据块的DataNode的位置。一旦客户端完成读取,就对FSInputStream调用close方法
注意:在读取数据的时候,如果FSInputStream与DataNode通信时遇到错误,会尝试从这个块的最近的DataNode读
取数据,并且记住那个故障的DataNode,保证后续不会反复读取该节点上后续的块。FInputStream也会通过校验和
确认从DataNode发来的数据是否完整。如果发现有损坏的块,FSInputStream会从其他的块读取副本,并且将损坏的块通知给NameNode
3.14.2 写流程的详解
写操作:
- hdfs dfs -put ./file02 /file02
- hdfs dfs -copyFromLocal ./file02 /file02
- FSDataOutputStream fsout = fs.create(path);fsout.write(byte[])
- fs.copyFromLocal(path1,path2)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RgLyv6Ia-1624008373531)(E:\01 江西理工\文档\02 千锋大数据技术栈之hdfs\hdfs.assets\20190117142943610.png)]
1. 客户端通过对DistributedFileSystem对象调用create()方法来新建文件
2. DistributedFileSystem对namenode创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时该文件中还没有相应的数据块
3. namenode执行各种不同的检查,以确保这个文件不存在以及客户端有新建该文件的权限。如果检查通过,namenode就会为创建新文件记录一条事务记录(否则,文件创建失败并向客户端抛出一个IOException异常)。DistributedFileSystem向客户端返回一个FSDataOuputStream对象,由此客户端可以开始写入数据,
4. 在客户端写入数据时,FSOutputStream将它分成一个个的数据包(packet),并写入一个内部队列,这个队列称为“数据队列”(data queue)。DataStreamer线程负责处理数据队列,它的责任是挑选出合适存储数据复本的一组datanode,并以此来要求namenode分配新的数据块。这一组datanode将构成一个管道,以默认复本3个为例,所以该管道中有3个节点.DataStreamer将数据包流式传输到管道中第一个datanode,该datanode存储数据包并将它发送到管道中的第2个datanode,同样,第2个datanode存储该数据包并且发送给管道中的第三个datanode。DataStreamer在将一个个packet流式传输到第一个Datanode节点后,还会将此packet从数据队列移动到另一个队列确认队列(ack queue)中。
5. datanode写入数据成功之后,会为ResponseProcessor线程发送一个写入成功的信息回执,当收到管道中所有的datanode确认信息后,ResponseProcessoer线程会将该数据包从确认队列中删除。
如果任何datanode在写入数据期间发生故障,则执行以下操作:
1. 首先关闭管道,把确认队列中的所有数据包都添加回数据队列的最前端,以确保故障节点下游的datanode不会漏掉任何一个数据包
2. 为存储在另一正常datanode的当前数据块制定一个新标识,并将该标识传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块
3. 从管道中删除故障datanode,基于两个正常datanode构建一条新管道,余下数据块写入管道中正常的datanode
4. namenode注意到块复本不足时,会在一个新的Datanode节点上创建一个新的复本。
注意:在一个块被写入期间可能会有多个datanode同时发生故障,但概率非常低。只要写入了dfs.namenode.replication.min的复本数(默认1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标复本数dfs.replication的数量(默认3)
3.15 HDFS编程
3.15.1 编程准备
-
windows中安装jdk,建议1.8系列,安装步骤省略。
-
安装maven,安装配置参考文档。
-
创建项目
File->new->project:
如上图所示,则创建项目成果。
-
idea和maven整合
file->settings,如下图所示:
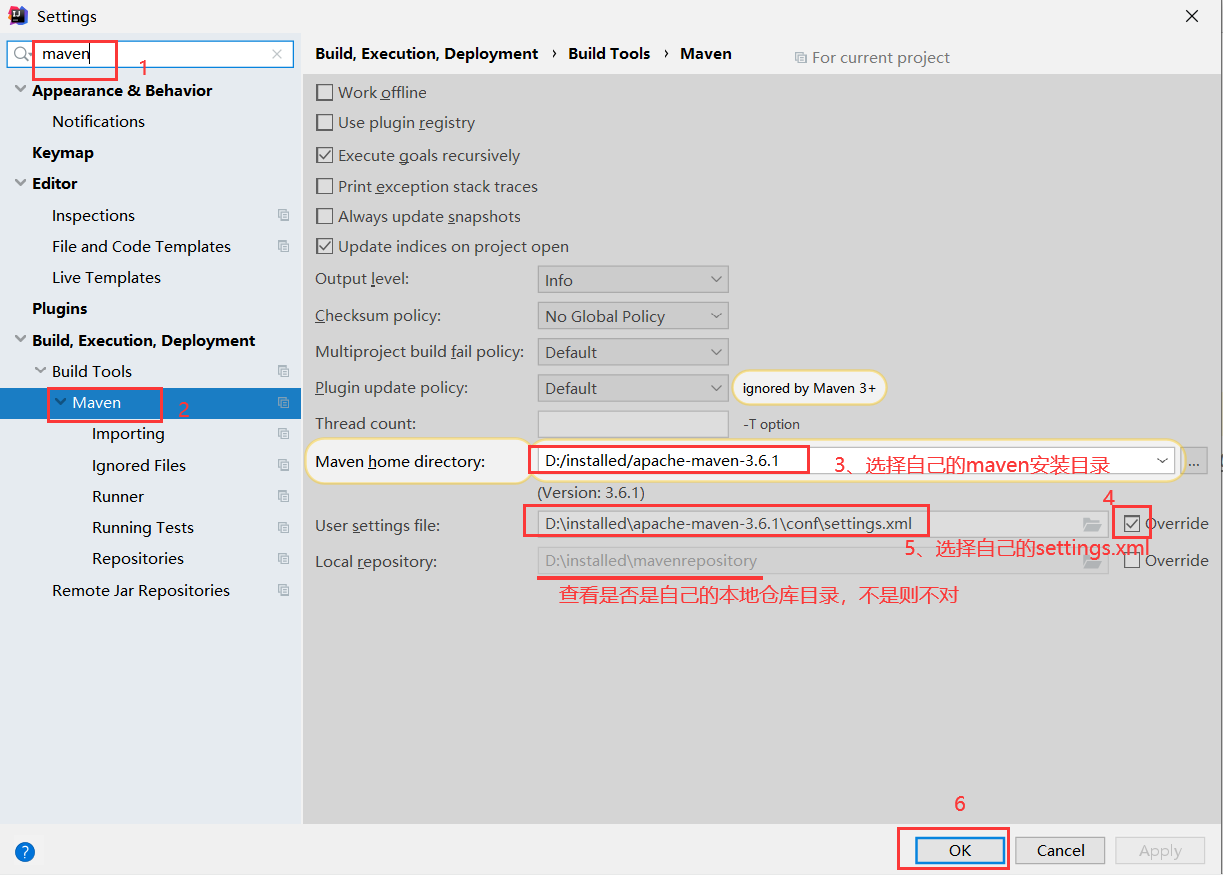
idea和maven的整合完成。
-
idea为新项目做默认设置
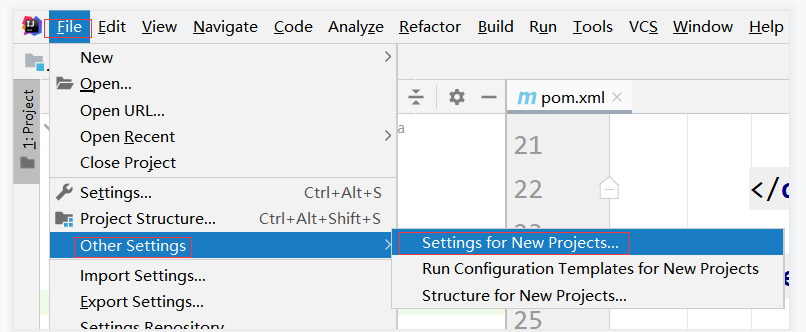
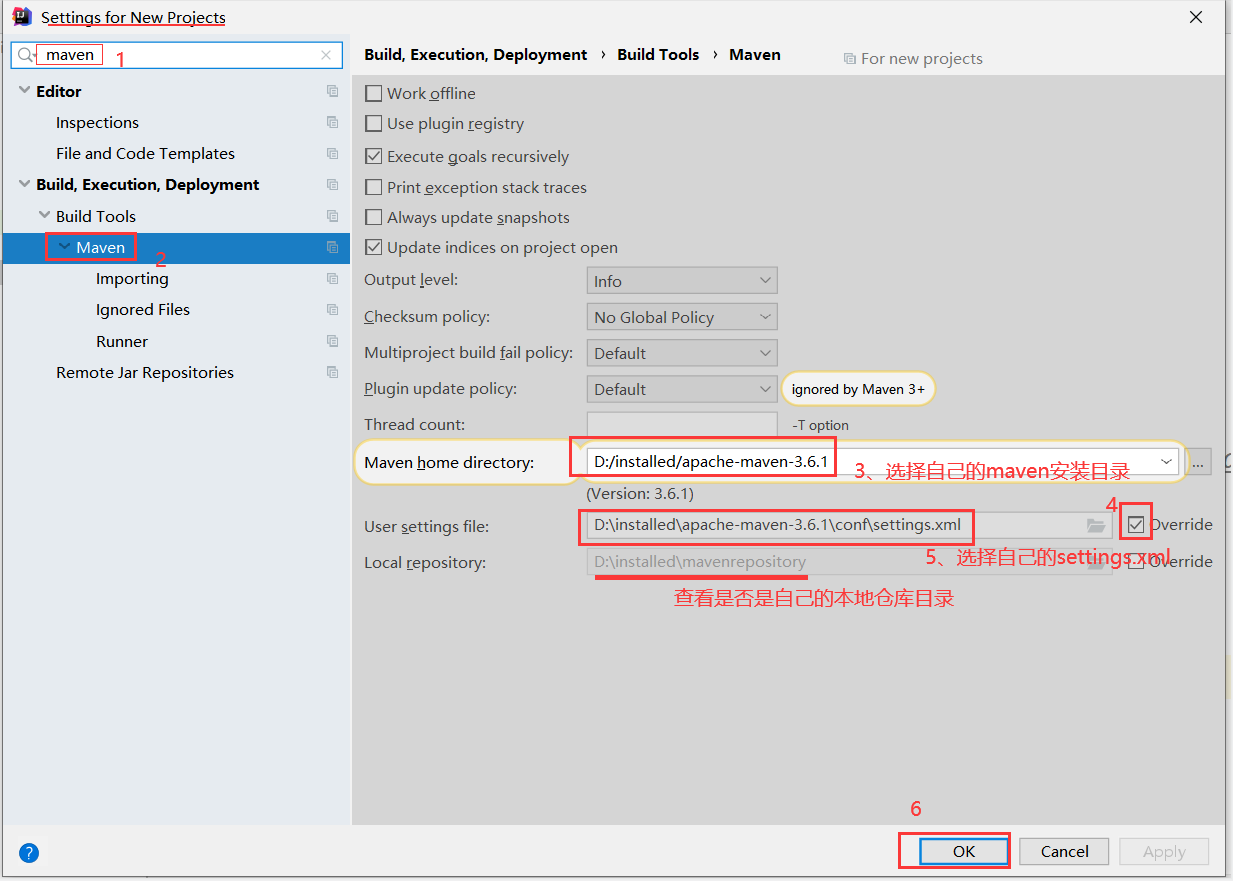
-
引入pom.xml中的依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>edu.bigdata</groupId> <artifactId>jxlg-bigdata</artifactId> <version>1.0</version> <!--配置项目中某些jar包的版本--> <properties> <hadoop.version>2.7.6</hadoop.version> </properties> <!--项目jar包的依赖配置--> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> </project> -
如果包没有下载好的解决方案
1、首先需要电脑联网状态
2、如果依赖是红色的:
a.重新剪切和粘贴pom.xml中的内容
b.刷新mavne中的刷新按钮
c.点击pom.xml右键,找到mavne选项,找到reimort。从新引入。
d.找到本地仓库中对应的包、项目、版本,将其删除,重新执行a、b、c等步骤即可。
-
创建包
点击java包右键,new->package->输入edu.bigdata.hdfs
3.15.2 java的API操作HDFS
-
获取FileSystem对象
package edu.bigdata.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; /** * javaapi操作hdfs.通常编程步骤如下: * 1、获取conf对象 * 2、获取FileSystem对象 * 3、使用FileSystem对象对hdfs的文件操作 * 4、关闭FileSystem对象 */ public class HDFSTest { public static void main(String[] args) throws IOException { //获取fs对象 FileSystem fs = getFS(); //System.out.println(fs); //使用fs对象上传数据 fs.copyFromLocalFile(new Path("E:\\hadoopdata\\words"),new Path("/")); //关闭对象 fs.close(); } public static FileSystem getFS(){ FileSystem fs = null; //捕捉io异常 try { //1、获取configuration对象 Configuration conf = new Configuration(); //2、为conf设置对应的hdfs的入口 //conf.set("fs.defaultFS","hdfs://hadoop01:9000"); //伪装用户 //conf.set("hadoop.user.name","root"); //获取hdfs的filesystem对象 //fs = FileSystem.get(conf); fs = FileSystem.get(new URI("hdfs://hadoop01:9000"),conf,"root"); } catch (IOException e){ e.printStackTrace(); } catch (URISyntaxException e1){ e1.printStackTrace(); } catch (InterruptedException e2){ e2.printStackTrace(); } //返回fs对象 return fs; } } -
上传文件
public class HDFSTest { public static void main(String[] args) throws IOException { //获取fs对象 FileSystem fs = getFS(); //System.out.println(fs); //使用fs对象上传数据 fs.copyFromLocalFile(new Path("E:\\hadoopdata\\words"),new Path("/")); //关闭对象 fs.close(); } } -
下载文件
fs.copyToLocalFile(new Path("/words"),new Path("E:\\hadoopdata\\words1")); -
其他操作
/** * javaapi操作hdfs.通常编程步骤如下: * 1、获取conf对象 * 2、获取FileSystem对象 * 3、使用FileSystem对象对hdfs的文件操作 * 4、关闭FileSystem对象 */ public class HDFSTest { public static void main(String[] args) throws IOException { //获取fs对象 FileSystem fs = getFS(); //System.out.println(fs); //使用fs对象上传数据 //fs.copyFromLocalFile(new Path("E:\\hadoopdata\\words"),new Path("/")); //下载数据 //fs.copyToLocalFile(new Path("/words"),new Path("E:\\hadoopdata\\words1")); //创建目录 --- 递归创建也行 //boolean mkdirs = fs.mkdirs(new Path("/jxlg/data/")); //创建文件,并输入数据进去 /*FSDataOutputStream fsoutput = fs.create(new Path("/jxlg/data/test.txt")); FileInputStream inputStream = new FileInputStream(new File("E:\\hadoopdata\\words")); IOUtils.copyBytes(inputStream,fsoutput,4096,true);*/ //判断存在,并删除 String deletefile="/jxlg/data/test.txt"; if(fs.exists(new Path(deletefile))){ //如果存在删除 fs.delete(new Path(deletefile),true); //true是递归删除 } else { System.out.println(deletefile+":文件或者目录不存在!!!"); } //关闭对象 fs.close(); } } -
获取块位置
package edu.bigdata.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.io.IOUtils; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStream; import java.net.URI; import java.net.URISyntaxException; import java.util.Arrays; /** * javaapi操作hdfs.通常编程步骤如下: * 1、获取conf对象 * 2、获取FileSystem对象 * 3、使用FileSystem对象对hdfs的文件操作 * 4、关闭FileSystem对象 */ public class HDFSTest { public static void main(String[] args) throws IOException { //获取fs对象 FileSystem fs = getFS(); //System.out.println(fs); //使用fs对象上传数据 //fs.copyFromLocalFile(new Path("E:\\hadoopdata\\words"),new Path("/")); //下载数据 //fs.copyToLocalFile(new Path("/words"),new Path("E:\\hadoopdata\\words1")); //创建目录 --- 递归创建也行 //boolean mkdirs = fs.mkdirs(new Path("/jxlg/data/")); //创建文件,并输入数据进去 /*FSDataOutputStream fsoutput = fs.create(new Path("/jxlg/data/test.txt")); FileInputStream inputStream = new FileInputStream(new File("E:\\hadoopdata\\words")); IOUtils.copyBytes(inputStream,fsoutput,4096,true);*/ //判断存在,并删除 String deletefile="/jxlg/data/test.txt"; if(fs.exists(new Path(deletefile))){ //如果存在删除 fs.delete(new Path(deletefile),true); //true是递归删除 } else { System.out.println(deletefile+":文件或者目录不存在!!!"); } //获取指定文件的块位置 String file = "/myshell.sh"; getBlockofFile(fs,file); //关闭对象 fs.close(); } public static FileSystem getFS(){ FileSystem fs = null; //捕捉io异常 try { //1、获取configuration对象 Configuration conf = new Configuration(); //2、为conf设置对应的hdfs的入口 //conf.set("fs.defaultFS","hdfs://hadoop01:9000"); //伪装用户 //conf.set("hadoop.user.name","root"); //获取hdfs的filesystem对象 //fs = FileSystem.get(conf); fs = FileSystem.get(new URI("hdfs://hadoop01:9000"),conf,"root"); } catch (IOException e){ e.printStackTrace(); } catch (URISyntaxException e1){ e1.printStackTrace(); } catch (InterruptedException e2){ e2.printStackTrace(); } //返回fs对象 return fs; } /** * 根据传入fs文件路径获取在hdfs中的块的位置 * @param fs * @param filePath */ public static void getBlockofFile(FileSystem fs,String filePath) throws IOException { //获取文件所对应的块的位置 RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fs.listLocatedStatus(new Path(filePath)); //迭代迭代器 while (locatedFileStatusRemoteIterator.hasNext()){ //获取下一个 LocatedFileStatus status = locatedFileStatusRemoteIterator.next(); //获取对应的块位置信息 BlockLocation[] blockLocations = status.getBlockLocations(); //循环数组 for(BlockLocation blockLocation : blockLocations){ System.out.println("当前块的所有副本位置:"+ Arrays.toString(blockLocation.getHosts())); System.out.println("当前块大小:"+blockLocation.getLength()); System.out.println("当前块的副本的ip地址信息:"+Arrays.toString(blockLocation.getNames())); } System.out.println("系统的块大小:"+status.getBlockSize()); System.out.println("文件总长度:"+status.getLen()); } } }
错误1
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=hasee, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
解决方法:
1、伪装用户
fs = FileSystem.get(new URI("hdfs://hadoop01:9000"),conf,"root");
错误2
null ...... winutil.exe
解决方案:
1、在window安装hadoop,其实就是解压一下,并配置环境变量
2、将我拷贝给你们的winutil.exe程序放到hadoop安装目录bin目录下面
3、将我拷贝给你们的hadoop.dll文件放到c盘的C:\Windows\System32目录
作业
1、在window创建一个目录,下面2个及以上的小文件,然后使用java代码合并上传到hdfs中的一个文件中。
outstream = fs.create("/data/123");
//循环输入目录
for(){
//读到每一个文件,将文件流写入hdfsDataOutput流中,
outstream.write();
outstream.flush();
}
2、将hdfs中的数据读取,并打印到idea控制台。
//读hdfs的文件
ins = fs.read();
//打印到控制台
IOUtil.copyByte(ins,System.Out.Print,4096,true)
3、预习mapreduce文档
4 MapReduce编程模型
4.1 mapreduce的定义
MapReduce是一个离线、并行、分布式、海量数据的计算框架(模型)。
MapReduce:分为两个阶段,map阶段和reduce阶段。
map:映射。
reduce:减少(合并、聚合)
使用背景:
1、比较不容易升级切换其他框架,任然在维护的mr代码。
2、有海量数据的企业(通信、制造业),很多时候还需要mr。
3、是一个经典分布式计算模型。
优点:
易于编程
高容错性
良好扩展性
适合pb级别
缺点:
不适合实时
不适合流式计算
不适合DAG
4.2 mapreduce的简单工作流程
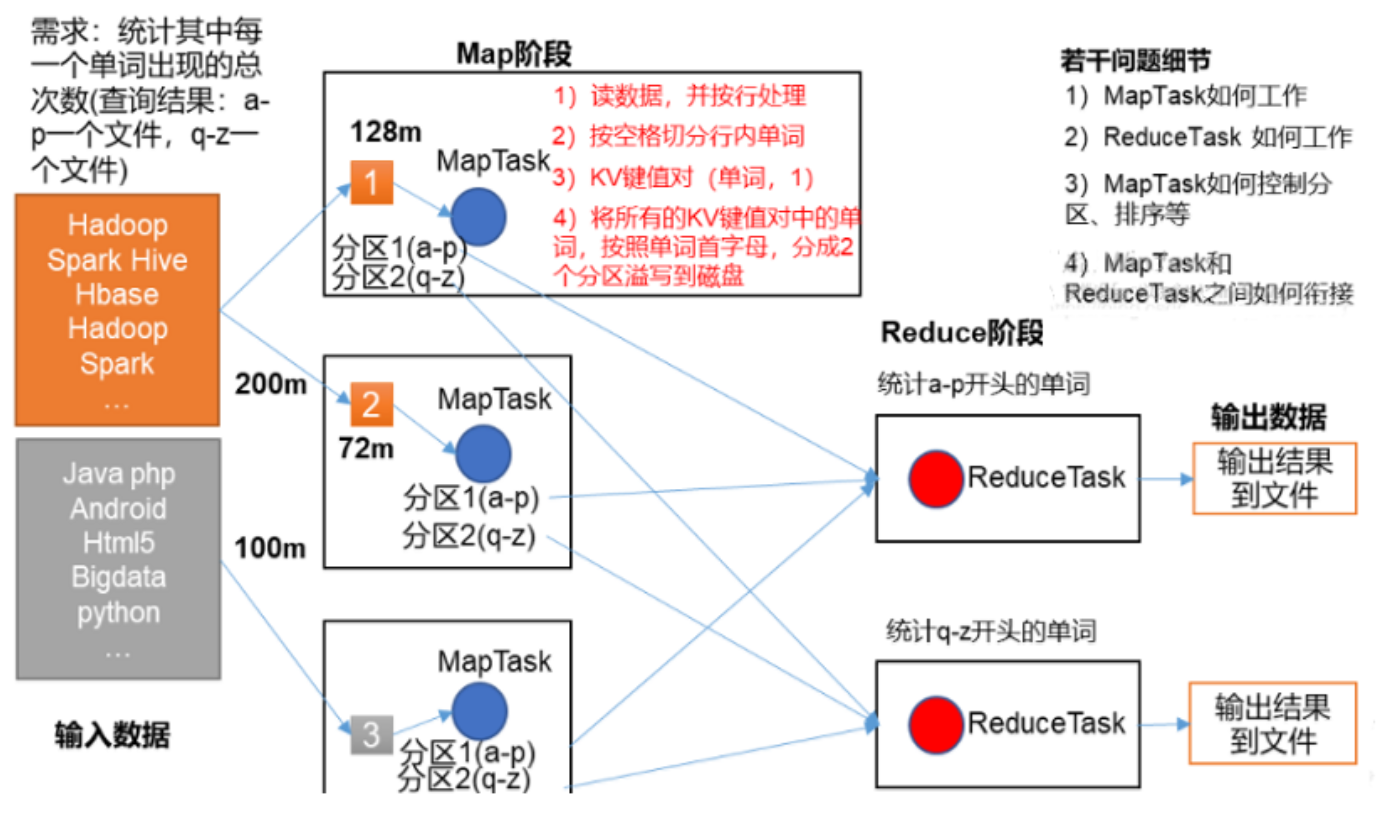
4.3 mapreduce阶段
MapReduce的运算程序一般分为2个阶段。
第一阶段
1)概述:
第一阶段,也称之为Map阶段。这个阶段会有若干个MapTask实例,完全并行运行,互不相干。每个MapTask会读取分析一个InputSplit(输入分片,简称分片)对应的原始数据。计算的结果数据会临时保存到所在节点的本地磁盘里。
2)数据扭转
该阶段的编程模型中会有一个map函数需要开发人员重写,map函数的输入是一个<key,value>对,map函数的输出也是一个<key,value>对,key和value的类型需要开发人员指定。参考下图:

第二阶段
1)概述
第二阶段,也称为Reduce阶段。这个阶段会有若干个ReduceTask实例并发运行,互不相干。但是他们的数据依赖于上一个阶段的所有maptask并发实例的输出。一个ReudceTask会从多个MapTask运行节点上fetch自己要处理的分区数据。经过处理后,输出到HDFS上。
2)数据扭转
该阶段的编程模型中有一个reduce函数需要开发人员重写,reduce函数的输入也是一个<key,value>对,reduce函数的输出也是一个<key,value>对。这里要强调的是,reduce的输入其实就是map的输出,只不过map的输出经过shuffle技术后变成了<key,List>而已。参考下图:

注意: mapreduce程序一般指一个map阶段和一个reduce阶段,如果程序不需要合并,也可以只有map阶段,但是不能只有reduce阶段而没有map阶段。如果程序复杂,可以写过mapreduce程序。
4.4 MapReduce编程规范
用户编写的程序分为3个部分:Mapper、Reducer、Driver(提交mr程序的客户端)
Mapper部分
- 1、自定义类,继承Mapper类型
- 2、定义K1,V1,K2,V2的泛型(K1,V1是Mapper的输入数据类型,K2,V2是Mapper的输出数据类型)
- 3、重写map方法(处理逻辑)
- 4、
参考下图:

注意: map方法,每一个KV对都会调用一次。
Reducer部分
- 自定义类,继承Reducer类型
- 定义K2,V2,K3,V3的泛型(K2,V2是Reducer的输入数据类型,K3,V3是Reducer的输出数据类型)
- 重写reduce方法的处理逻辑
参考下图:

注意: reduce方法,默认按key分组,每一组都调用一次。
Driver部分
整个程序需要一个Driver来进行提交,提交的是一个描述了各种必要信息的job对象,如下
1. 获取Job对象
2. 指定驱动类
3. 设置Mapper和Reducer类型
4. 设置Mapper的输出K2、V2的类型(如果类型和K3,V3相同,可省略)
5. 设置Reducer的输出K3、V3的类型
6. 设置Reduce的个数(默认为1)
7. 设置Mapper的输入数据的路径
8. 设置Reducer的输出数据的路径
9. 提交作业
参考下图:
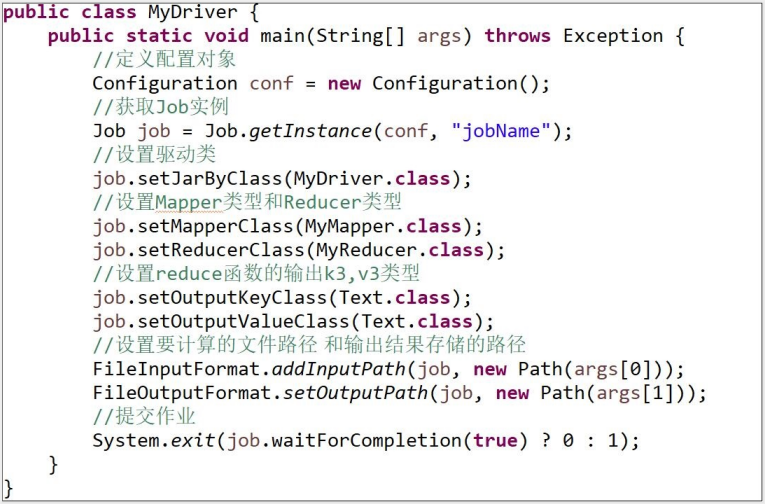
作业
1、自己编写wordcount的代码,并在本地能正常运行测试,也能在本地看到输出结果。
2、将1的操作打成jar包,放到服务器中提交运行测试。
4.5 案例
package edu.bigdata.mr;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 使用mr统计wc
*
* 需求:
* a.txt
* hello jxlg jxlg is nice
* jxlg is good jxlg gxlg
* hello
* jxlg
*
* map阶段:
* 行偏移量 正行数据 输出key类型 输出value类型(和reduce输入value类型一致)
* 类型:LongWritable, Text ,Text ,Text
* 输入key—value数据:0 hello jxlg jxlg is nice
* 输出:
* hello 1
* jxlg 1
* jxlg 1
* is 1
* nice 1
* map输入:24 jxlg is good jxlg gxlg
* jxlg 1
* is 1
* good 1
* ...
*
* reduce阶段: reduce阶段输入key类型 reduce输入的value类型 reduce阶段输出key类型(满足需求即可) reduce输出value类型
* 类型: <Text, LongWritable, Text, IntWritable>
*reduce阶段输入(和map阶段相同,经过处理之后为如下):
* hello 迭代器(1)
* jxlg 迭代器(1,1,1,1,1,1)
* ...
* 输出:
* hello 1
* jxlg 6
* is 1
* good 1
* ...
*
*/
public class Demo02_WC {
//map阶段
public static class MyMappper extends Mapper<LongWritable, Text,Text,IntWritable>{
public Text k = new Text();
public IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//super.map(key, value, context); //注释掉
//获取k-v中的value值
String line = value.toString();
//判断整行数据是否为空
if(StringUtils.isNotEmpty(line)){
String[] fileds = line.split(" ");
//循环
for(String filed :fileds){
//设置k-v并输出
k.set(filed);
context.write(k,v); //输出,需要类型一致
}
}
}
}
//reduce阶段
public static class MyReducer extends Reducer<Text,IntWritable,Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//super.reduce(key, values, context); //需要注释
/**
* * hello 迭代器(1)
* * jxlg 迭代器(1,1,1,1,1,1)
*/
//定义一个计数器
int sum = 0;
//循环迭代器
for (IntWritable val : values){
sum += val.get();
}
//输出
context.write(key,new IntWritable(sum));
}
}
//驱动程序
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//配置、job、job运行类设置、map阶段设置、reduce阶段设置、提交作业
Configuration conf = new Configuration();
//获取job实例
Job job = Job.getInstance(conf, "my-wc");
//为job设置运行类
job.setJarByClass(Demo02_WC.class);
//设置map阶段
job.setMapperClass(MyMappper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce阶段
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//将作业提交并打印信息
boolean isok = job.waitForCompletion(true);
System.out.println(isok);
//退出
System.exit(isok?0:1);
}
}
本地测试:
1、准备好数据,传递好参数,右键运行
服务器运行测试
1、打包,clean->package/install
2、上传服务器
3、命令提交
yarn jar /home/jxlg-bigdata-1.0.jar eud.bigdata.mr.Demo02_WC /a.txt /out/00
4.6 Partitoner简介
Partitoner是将map阶段输出的数据根据分区规则输出不同的reducer中去。每个reducer对应一个分区。目的:将结果数据分布到不同的目录中或者较少输出压力。
1. partitioner的作用是将mapper 输出的key/value划分成不同的partition,每个reducer对应一个
partition。
2. 默认情况下,partitioner先计算key的散列值(hash值)。然后通过reducer个数执行取模运算:
key.hashCode%(reducer个数)。这样能够随机地将整个key空间平均分发给每个reducer,同时也能确保不同
mapper产生的相同key能被分发到同一个reducer。
3. 目的:
可以使用自定义Partitioner来达到reducer的负载均衡, 提高效率。
4. 适用范围:
需要非常注意的是:必须提前知道有多少个分区。比如自定义Partitioner会返回4个不同int值,而reducer number设置了小于4,那就会报错。所以我们可以通过运行分析任务来确定分区数。例如,有一堆包含时间戳的数据,但是不知道它能追朔到的时间范围,此时可以运行一个作业来计算出时间范围。
注意:在自定义partitioner时一定要注意防止数据倾斜。
案例
package edu.bigdata.mr;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 使用mr统计wc
*
* 需求:
* a.txt
* hello jxlg jxlg is nice
* jxlg is good jxlg gxlg
* hello
* jxlg 1234567@qq.com
* @163.com 666 999 666 666
* ABC HELLO JXLG JXLG
*
* 将如上的输出结果按照首字母输出到不同的结果中:
* 分区规则:
* a-z : 首字母a-z的输出到一个文件
* A-Z : 输出到一个文件
* 其它输出一个文件:首字母不为上述的两种的输出一个文件中
*
*
*/
public class Demo03_WC {
//map阶段
public static class MyMappper extends Mapper<LongWritable, Text,Text,IntWritable>{
public Text k = new Text();
public IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//super.map(key, value, context); //注释掉
//获取k-v中的value值
String line = value.toString();
//判断整行数据是否为空
if(StringUtils.isNotEmpty(line)){
String[] fileds = line.split(" ");
//循环
for(String filed :fileds){
//设置k-v并输出
k.set(filed);
context.write(k,v); //输出,需要类型一致
}
}
}
}
//reduce阶段
public static class MyReducer extends Reducer<Text,IntWritable,Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//super.reduce(key, values, context); //需要注释
/**
* * hello 迭代器(1)
* * jxlg 迭代器(1,1,1,1,1,1)
*/
//定义一个计数器
int sum = 0;
//循环迭代器
for (IntWritable val : values){
sum += val.get();
}
//输出
context.write(key,new IntWritable(sum));
}
}
//驱动程序
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//配置、job、job运行类设置、map阶段设置、reduce阶段设置、提交作业
Configuration conf = new Configuration();
//获取job实例
Job job = Job.getInstance(conf, "my-wc-partitioner");
//为job设置运行类
job.setJarByClass(Demo03_WC.class);
//设置map阶段
job.setMapperClass(MyMappper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce阶段
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//设置分区信息
job.setPartitionerClass(MyPartitioner.class);
//reducer的个数一般等价于partitioner个数
job.setNumReduceTasks(3);
//将作业提交并打印信息
boolean isok = job.waitForCompletion(true);
System.out.println(isok);
//退出
System.exit(isok?0:1);
}
}
package edu.bigdata.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* mr中的分区,分区规则
* * 分区规则:
* * a-z : 首字母a-z的输出到一个文件
* * A-Z : 输出到一个文件
* * 其它输出一个文件:首字母不为上述的两种的输出一个文件中
*
* 1、继承Partitioner ,长包中的
* 2、泛型为map阶段输出泛型
* 3、需要实现getPartition()该方法,只能返回int类,int值就是分区编号
*/
public class MyPartitioner extends Partitioner<Text, IntWritable> {
/**
* 实现获取分区编号方法
* @param text
* @param intWritable
* @param i
* @return
*/
public int getPartition(Text text, IntWritable intWritable, int i) {
//获取首字符
String firstStr = text.toString().substring(0, 1);
//匹配规则并返回分区编号
if(firstStr.matches("[a-z]")){
return 0%i;
} else if(firstStr.matches("[A-Z]")){
return 1%i;
} else {
return 2%i;
}
}
}
4.7 常用类型的简介
常用的数据类型对应的hadoop数据序列化类型
| Java类型 | Hadoop Writable类型 | 释义 |
|---|---|---|
| boolean | BooleanWritable | 标准布尔型数值 |
| byte | ByteWritable | 单字节数值 |
| int | IntWritable | 整型数值 |
| float | FloatWritable | 单精度数 |
| long | LongWritable | 长整型数值 |
| double | DoubleWritable | 双精度数 |
| string | Text | 使用UTF8格式存储的文本 |
| map | MapWritable | 以键值对的形式存储Writable类型的数据 |
| array | ArrayWritable | 以数组的形式存储Writable类型的数据 |
| null | NullWritable | 当<key,value>中的key或value为空时使用 |
NullWritable说明:

4.8 MapReduce运行流程简述
一个完整的MapReduce程序在分布式运行时有三类实例进程:
1) MRAppMaster:负责整个程序的过程调度及状态协调
2) MapTask:负责map阶段的整个数据处理流程
3) ReduceTask:负责reduce阶段的整个数据处理流程
当一个作业提交后(mr程序启动),大概流程如下:
1) 一个mr程序启动的时候,会先启动一个进程Application Master,它的主类是MRAppMaster
2) appmaster启动之后会根据本次job的描述信息,计算出inputSplit的数据,也就是MapTask的数量
3) appmaster然后向resourcemanager来申请对应数量的container来执行MapTask进程。
4) MapTask进程启动之后,根据对应的inputSplit来进行数据处理,处理流程如下
-利用客户指定的inputformat来获取recordReader读取数据,形成kv键值对。
-将kv传递给客户定义的mapper类的map方法,做逻辑运算,并将map方法的输出kv收集到缓存。
-将缓存中的kv数据按照k分区排序后不断的溢出到磁盘文件
5) appmaster监控maptask进程完成之后,会根据用户指定的参数来启动相应的reduceTask进程,并告知reduceTask需要处理的数据范围
6) reducetask启动之后,根据appmaster告知的待处理的未知数据,从若干的已经存到磁盘的数据中拿到数据,并在本地进行一个归并排序,然后,再按照相同的key的kv为一组,调用客户自定义的reduce方法,并收集输出结果kv,然后按照用户指定的outputFormat将结果存储到外部设备。
MapReduce执行流程图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wJeHWuQw-1624008373547)(E:\01 江西理工\文档\03 千锋大数据技术栈之mr\MapReduce.assets\yarn介绍4.jpg)]
执行详细参考下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a8s6L9FS-1624008373547)(E:\01 江西理工\文档\03 千锋大数据技术栈之mr\MapReduce.assets\MapReduce.png)]
4.9 shuffle整体流程图
shuffle:将数据打乱重新编排。将数据乱序。mapreduce中 常说成业shuffle败也shuffle。
shuffle中key是有顺序,key为Text时的 顺序为key的字典排序。其它类型根据对应类型的比较方式。
从map函数输出到reduce函数接受输入数据,这个过程称之为shuffle。直接看如下图所示:
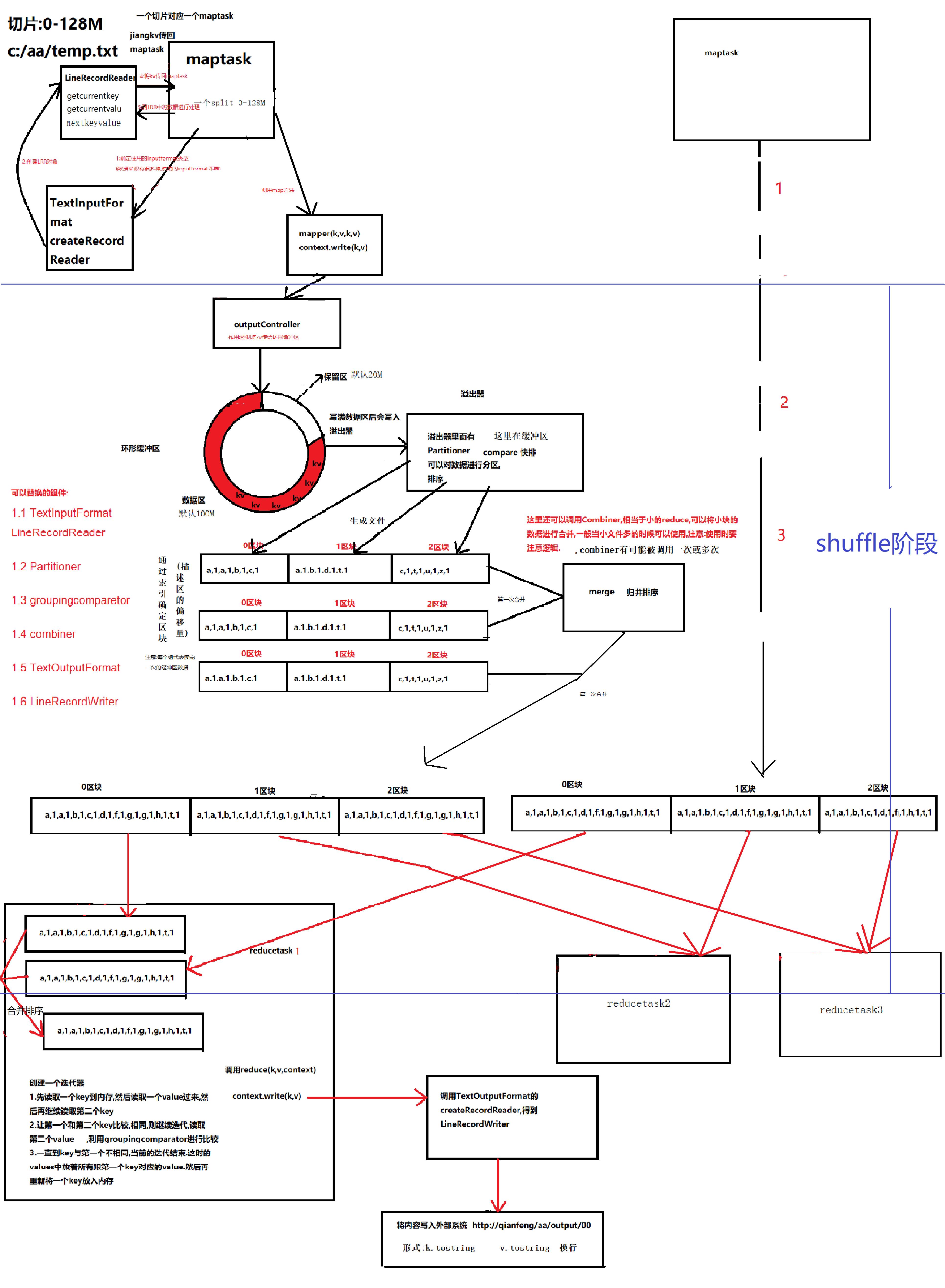
- 细节分析
在Hadoop这样的集群环境中,大部分map task与reduce task的执行是在不同的节点上。当然很多情况下Reduce执行时需要跨节点去拉取其它节点上的map task结果。如果集群正在运行的job有很多,那么task的正常执行对集群内部的网络资源消耗会很严重。这种网络消耗是正常的,我们不能限制,能做的就是最大化地减少不必要的消耗。还有在节点内,相比于内存,磁盘IO对job完成时间的影响也是可观的。从最基本的要求来说,我们对shuffle过程的期望可以有:
a) 完整地从map task端拉取数据到reduce 端。
b) 在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
c) 减少磁盘IO对task执行的影响。
2)细节分析
1. 从map函数输出到reduce函数接受输入数据,这个过程称之为shuffle.
2. map函数的输出,存储环形缓冲区(默认大小100M,阈值80M)
环形缓冲区:其实是一个字节数组kvbuffer. 有一个sequator标记,kv原始数据从左向右填充(顺时针),
kvmeta是对kvbuffer的一个封装,封装成了int数组,用于存储kv原始数据的对应的元数据valstart,
keystart,partition,vallen信息,从右向左(逆时针)。参考(环形缓冲区的详解一张)
3. 当达到阈值时,准备溢写到本地磁盘(因为是中间数据,因此没有必要存储在HDFS上)。在溢写前要进行对元数据分区(partition)整理,然后进行排序(quick sort,通过元数据找到出key,同一分区的所有key进行排序,排序完,元数据就已经有序了,在溢写时,按照元数据的顺序寻找原始数据进行溢写)
4. 如果有必要,可以在排序后,溢写前调用combiner函数进行运算,来达到减少数据的目的
5. 溢写文件有可能产生多个,然后对这多个溢写文件进行再次合并(也要进行分区和排序)。当溢写个数>=3时,可以再次调用combiner函数来减少数据。如果溢写个数<3时,默认不会调用combiner函数。
6. 合并的最终溢写文件可以使用压缩技术来达到节省磁盘空间和减少向reduce阶段传输数据的目的。(存储在本地磁盘中)
7. Reduce阶段通过HTTP写抓取属于自己的分区的所有map的输出数据(默认线程数是5,因此可以并发抓取)。
8. 抓取到的数据存在内存中,如果数据量大,当达到本地内存的阈值时会进行溢写操作,在溢写前会进行合并和排序(排序阶段),然后写到磁盘中,
9. 溢写文件可能会产生多个,因此在进入reduce之前会再次合并(合并因子是10),最后一次合并要满足10这个因子,同时输入给reduce函数,而不是产生合并文件。reduce函数输出数据会直接存储在HDFS上。
OK,看到这里时,大家可以先停下来想想,如果是自己来设计这段shuffle过程,那么你的设计目标是什么。能优化的地方主要在于减少拉取数据的量及尽量使用内存而不是磁盘。shuffle过程横跨map与reduce两端,下面我会先说明总体流程,在详细说明map task和reduce task阶段.
4.10 YARN简介
Yarn:全局资源管理和作业调度框架。只能管理集群。
为克服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的,针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARN.
Apache YARN(Yet another Resource Negotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序。
yarn被引入Hadoop2,最初是为了改善MapReduce的实现,但是因为具有足够的通用性,同样可以支持其他的分布式计算模式,比如Spark,Tez等计算框架。
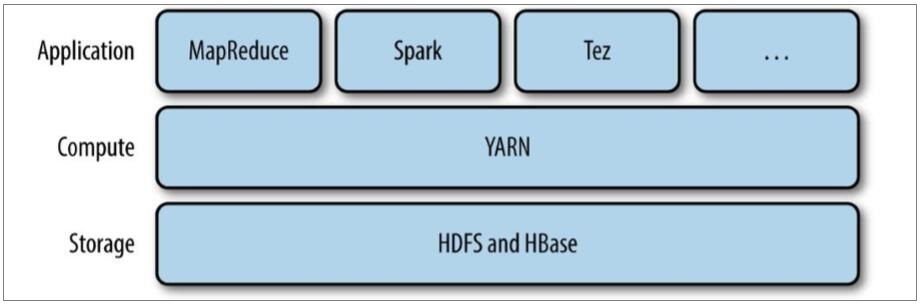
注意:还有一层应用是运行在MapReduce,Spark或者Tez之上的处理框架,如Pig,Hive和Crunch等。
4.11 YARN的设计思想(重点)
yarn的基本思想是将资源管理和作业调度/监视功能划分为单独的守护进程。其思想是拥有一个全局ResourceManager (RM),以及每个应用程序拥有一个ApplicationMaster (AM)。应用程序可以是单个作业,也可以是一组作业
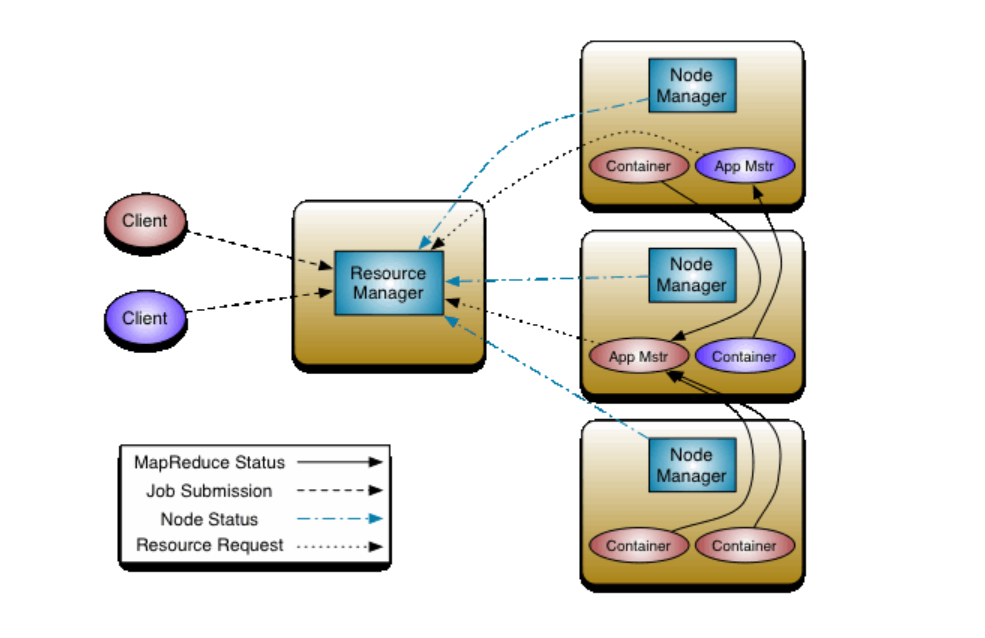
一个ResourceManager和多个NodeManager构成了yarn资源管理框架。他们是yarn启动后长期运行的守护进程,来提供核心服务。
ResourceManager,是在系统中的所有应用程序之间仲裁资源的最终权威,即管理整个集群上的所有资源分配,内部含有一个Scheduler(资源调度器)
NodeManager,是每台机器的资源管理器,也就是单个节点的管理者,负责启动和监视容器(container)资源使用情况,并向ResourceManager及其 Scheduler报告使用情况
container:即集群上的可使用资源,包含cpu、内存、磁盘、网络等
ApplicationMaster(简称AM)实际上是框架的特定的库,每启动一个应用程序,都会启动一个AM,它的任务是与ResourceManager协商资源,并与NodeManager一起执行和监视任务
**扩展)**YARN与MapReduce1的比较
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nfD4wiCC-1624008373551)(E:\01 江西理工\文档\03 千锋大数据技术栈之mr\mapreduce.assets\20191016063209.jpg)]
4.12 YARN的Job提交
在MR程序运行时,有五个独立的进程:
- YarnRunner:用于提交作业的客户端程序
- ResourceManager:yarn资源管理器,负责协调集群上计算机资源的分配
- NodeManager:yarn节点管理器,负责启动和监视集群中机器上的计算容器(container)
- Application Master:负责协调运行MapReduce作业的任务,他和任务都在容器中运行,这些容器由资源管理器分配并由节点管理器进行管理。
- HDFS:用于共享作业所需文件。
整个过程如下图描述:
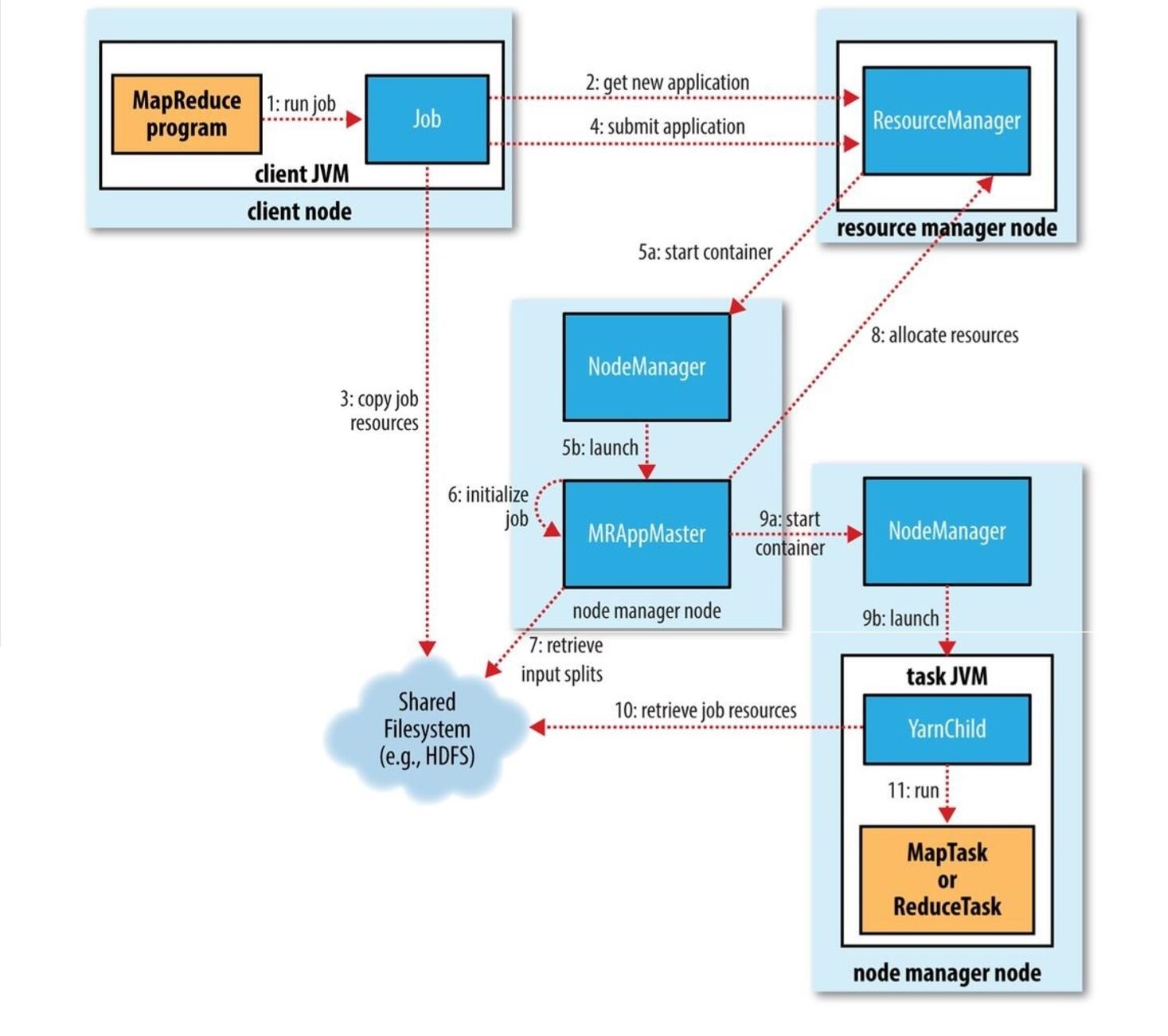
1. 调用waitForCompletion方法每秒轮询作业的进度,内部封装了submit()方法,用于创建JobCommiter实例,并且调用其的submitJobInternal方法。提交成功后,如果有状态改变,就会把进度报告到控制台。错误也会报告到
控制台
2. JobCommiter实例会向ResourceManager申请一个新应用ID,用于MapReduce作业ID。这期间JobCommiter也会进行检查输出路径的情况,以及计算输入分片。
3. 如果成功申请到ID,就会将运行作业所需要的资源(包括作业jar文件,配置文件和计算所得的输入分片元数据文件)上传到一个用ID命名的目录下的HDFS上。此时副本个数默认是10.
4. 准备工作已经做好,再通知ResourceManager调用submitApplication方法提交作业。
5. ResourceManager调用submitApplication方法后,会通知Yarn调度器(Scheduler),调度器分配一个容器,在节点管理器的管理下在容器中启动 application master进程。
6. application master的主类是MRAppMaster,其主要作用是初始化任务,并接受来自任务的进度和完成报告。
7. 然后从HDFS上接受资源,主要是split。然后为每一个split创建MapTask以及参数指定的ReduceTask,任务ID在此时分配
8. 然后Application Master会向资源管理器请求容器,首先为MapTask申请容器,然后再为ReduceTask申请容器。(5%)
9. 一旦ResourceManager中的调度器(Scheduler),为Task分配了一个特定节点上的容器,Application Master就会与NodeManager进行通信来启动容器。
10. 运行任务是由YarnChild来执行的,运行任务前,先将资源本地化(jar文件,配置文件,缓存文件)
11. 然后开始运行MapTask或ReduceTask。
12. 当收到最后一个任务已经完成的通知后,application master会把作业状态设置为success。然后Job轮询时,知道成功完成,就会通知客户端,并把统计信息输出到控制台
4.13 YARN的三种调度器
什么是Scheduler(调度器)
Scheduler即调度器,根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
YARN提供的三种内置调度器:
1) FIFO Scheduler(FIFO调度器):
FIFO 为 First Input First Output 的缩写,先进先出。FIFO 调度器将应用放在一个队列中,按照先 后顺序
运行应用。这种策略较为简单,但不适合共享集群,因为大的应用会占用集群的所有资源,每个应用必须等待直到轮到自己。
优点:简单易懂,不需要任何配置
缺点:不适合共享集群,大的应用会占据集群中的所有资源,所以每个应用都必须等待,直到轮到自己执行。
如下图所示,只有当job1全部执行完毕,才能开始执行job2
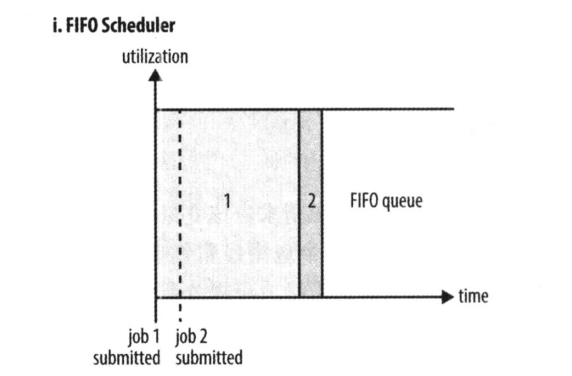
2) Capacity Scheduler(容量调度器):
容量调度器 Capacity Scheduler 允许多个组织共享一个 Hadoop 集群。使用容量调度器时,一个独立的专门队列保证小作业一提交就可以启动。
优点:小任务不会因为前面有大任务在执行,而只能一直等下去
缺点:这种策略是以整个集群利用率为代价的,这意味着与使用FIFO调度器相比,大作业执行的时间要长上一些。
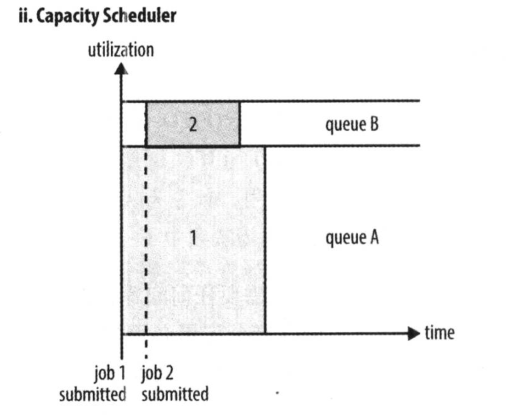
如图所示,专门留了一部分资源给小任务,可以在执行job1的同时,不会阻塞job2的执行,但是因为这部分资源是一直保留给其他任务的,所以就算只有一个任务,也无法为其分配全部资源,只能让这部分保留资源闲置着,有着一定的资源浪费问题。
3) Fair Scheduler(公平调度器):
公平调度器的目的就是为所有运行的应用公平分配资源。使用公平调度器时,不需要预留一定量的资源,因为调度器
会在所有运行的作业之间动态平衡资源,第一个(大)作业启动时,它也是唯一运行的作业,因而获得集群中的所有
资源,当第二个(小)作业启动时,它被分配到集群的一半资源,这样每个作业都能公平共享资源。
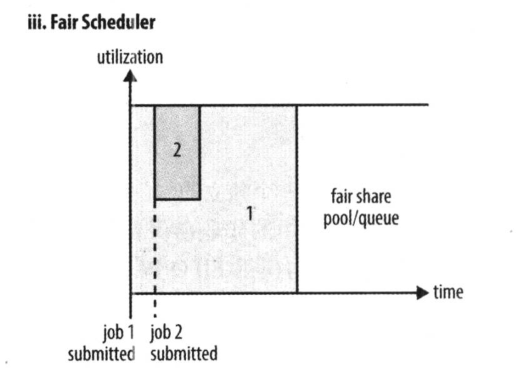
如图所示,就像是把好几个任务拼接成了一个任务,可以充分利用资源,同时又不会因为大任务在前面执行而导致小任务一直无法完成。
5 Hive数仓工具
4.1 Hive定义
1.1 出现原因
Hive最早来源于FaceBook ,因为FaceBook网站每天产生海量的结构化日志数据,为了对这些数据进行管理,并且因为机器学习的需求,产生了Hive这门技术,并继续发展成为一个成功的Apache项目。
1.2 定义
Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射成一张数据表,并可以使用类似SQL的方式来对数据文件进行读写以及管理。这套Hive SQL 简称HQL。Hive的执行引擎可以是MR、Spark、Tez。
1.3 本质
Hive的本质是将HQL转换成MapReduce任务,完成整个数据的分析查询,减少编写MapReduce的复杂度 。
优点
- 学习成本低:提供了类SQL查询语言HQL,使得熟悉SQL语言的开发人员无需关心细节,可以快速上手.
- 海量数据分析:底层是基于海量计算到MapReduce实现.
- 可扩展性:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统),Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
- 延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 良好的容错性:某个数据节点出现问题HQL仍可完成执行。
- 统计管理:提供了统一的元数据管理
缺点
- Hive的HQL表达能力有限
- 迭代式算法无法表达.
- Hive的效率比较低.
- Hive自动生成的MapReduce作业,通常情况下不够智能化.
- Hive调优比较困难,粒度较粗.
作业
1、对如下数据求最高温度
输入数据(温度):
2020100636.6
2020100733.12
2020100827.33
2020100937.66
2020101036.12
2021060621.61
2021060733.12
2021600827.33
2021060936.68
2021061036.12
计算出每年的最高温度:
2020 10-09 37.66
2021 06-09 36.68
2、提前安装hive,参考文档。将元数据保存到mysql中。
3、hive两个文档的提前预习。
4.2 hive架构
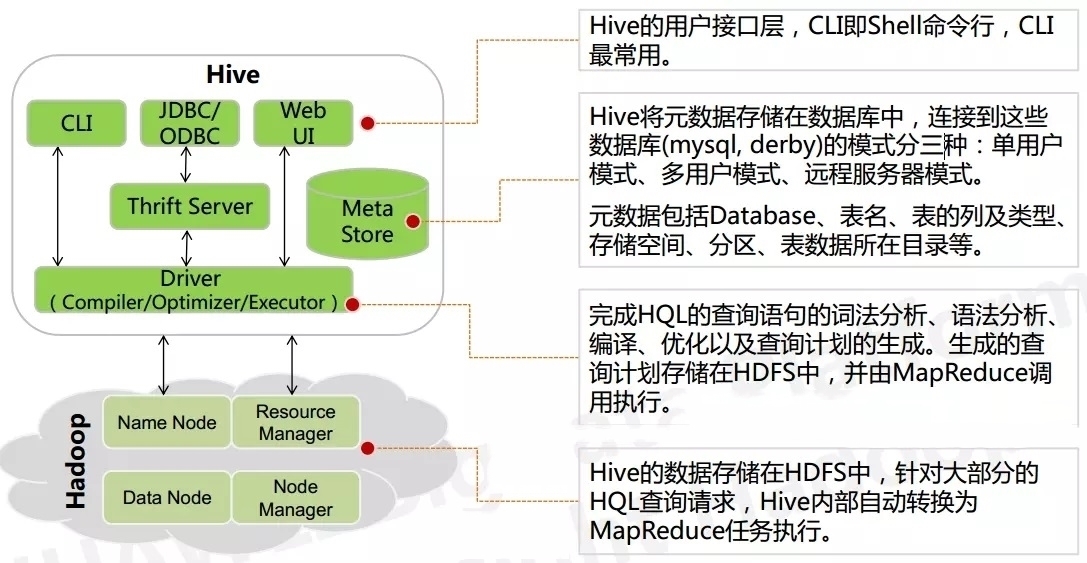
核心结构如下图
4.3 Hive和传统数据库的区别
4.4 安装部署
一般分为:内嵌模式(元数据存储到自带的derby中)和本地模式(元数据存储到mysql或者其他关系数据库中)
元数据存储在derby中的优点:快、简单、少配置;缺点:derby仅支持单session回话。
元数据存储在关系型数据库中的优点:支持多session;缺点:麻烦一些。
-
解压hive
[root@hadoop01 ~]# tar -zxvf /root/apache-hive-2.3.7-bin.tar.gz -C /usr/local/ [root@hadoop01 local]# mv /usr/local/apache-hive-2.3.7-bin/ /usr/local/hive-2.3.7 -
环境变量配置
[root@hadoop01 local]# vi /etc/profile #追加修改如下 export HIVE_HOME=/usr/local/hive-2.3.7/ export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin: [root@hadoop01 local]# source /etc/profile #验证环境变量 [root@hadoop01 local]# which hive /usr/local/hive-2.3.7/bin/hive -
配置hive-env.sh
[root@hadoop01 hive-2.3.7]# cp ./conf/hive-env.sh.template ./conf/hive-env.sh [root@hadoop01 hive-2.3.7]# vi ./conf/hive-env.sh #mysettings export HIVE_CONF_DIR=/usr/local/hive-2.3.7/conf/ export JAVA_HOME=/usr/local/jdk1.8.0_152/ export HADOOP_HOME=/usr/local/hadoop-2.7.6/ export HIVE_AUX_JARS_PATH=/usr/local/hive-2.3.7/lib -
配置hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 该参数主要指定Hive的数据存储目录 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <!--配置mysql的连接字符串--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value> </property> <!--配置mysql的连接驱动--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!--配置登录mysql的用户--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <!--配置登录mysql的密码--> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> <!--hive慢查询的日志目录--> <property> <name>hive.querylog.location</name> <value>hdfs://192.168.216.111:9000/user/hive/log</value> </property> <!--hive的server2的连接端口--> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <!--hive的server2的主机名--> <property> <name>hive.server2.thrift.bind.host</name> <value>192.168.216.111</value> </property> <!--hive的元数据服务的uri--> <property> <name>hive.metastore.uris</name> <value>thrift://192.168.216.111:9083</value> </property> </configuration> -
安装mysql
[root@hadoop01 home]# rpm -qa | grep mariadb #卸载 [root@hadoop01 home]# rpm -e --nodeps mariadb-libs-5.5.64-1.el7.x86_64 #安装 [root@hadoop01 hive-2.3.7]# tar -xvf /root/mysql-5.7.18-1.el7.x86_64.rpm-bundle.tar -C /home/ #将相关包按照顺序依次安装 [root@qianfeng01 soft]# rpm -ivh mysql-community-common-5.7.18-1.el7.x86_64.rpm [root@qianfeng01 soft]# rpm -ivh mysql-community-libs-5.7.18-1.el7.x86_64.rpm [root@qianfeng01 soft]# rpm -ivh mysql-community-client-5.7.18-1.el7.x86_64.rpm [root@qianfeng01 soft]# rpm -ivh mysql-community-server-5.7.18-1.el7.x86_64.rpm # 3. 启动mysql服务 #查看数据库状态 [root@hadoop01 home]# systemctl status mysqld # 启动数据库 [root@hadoop01 home]# systemctl start mysqld # 设置开机自启数据库 [root@hadoop01 home]# systemctl enable mysqld #查看密码 [root@hadoop01 home]# grep 'password' /var/log/mysqld.log 2021-06-17T01:40:37.560401Z 1 [Note] A temporary password is generated for root@localhost: WZlz3ycqWb.b 2021-06-17T01:41:23.306177Z 3 [Note] Access denied for user 'root'@'localhost' (using password: NO) #进入数据库 [root@hadoop01 home]# mysql -uroot -pWZlz3ycqWb.b #修改密码和授权 mysql> USE mysql; mysql> flush privileges; mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root123456!'; (备注 mysql5.7默认密码策略要求密码必须是大小写字母数字特殊字母的组合,至少8位) 设置允许远程登录 mysql> grant all privileges on *.* to 'root'@'%' identified by 'Root123456!'; mysql> flush privileges; mysql> quit; -
初始化
#拷贝mysql的驱动 [root@hadoop01 home]# cp /home/mysql-connector-java-5.1.28-bin.jar /usr/local/hive-2.3.7/lib/ #执行初始化 [root@hadoop01 home]# schematool -initSchema -dbType mysql -- 初始化后你能看到mysql元数据有大概57张表。初始化只需要一次,如果hive升级一般需要先执行升级sql脚本
作业
1、部署好hive,然后 操作创建数据库、创建表、创建分区、查询语句练习。
2、安装好sqoop,请按照之前文档安装即可。
-
测试
-- hadoop必须要启动 [root@hadoop01 ~]# start-all.sh --启动metastore服务 -- 过一会回车回车键即可 [root@hadoop01 ~]# hive --service metastore & --验证metastore服务 [root@hadoop01 ~]# jps 1824 NameNode 1955 DataNode 2371 ResourceManager 3959 Jps 2490 NodeManager 3581 RunJar --metastore服务 --验证metastore服务 [root@hadoop01 ~]# ps -ef | grep metastore --进入hive的命令行 [root@hadoop01 ~]# hive ... hive> 是否在命令行展示当前数据库: 追加hive-site.xml配置如下: <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> 追加后重启hive的命令行;启动如下: [root@hadoop01 ~]# hive ... hive (default)> #启动hiveserver的命令,一般是连接hive的jdbc或者使用beeline时使用 [root@hadoop01 ~]# hive --service hiveserver2 &
4.5 库表操作
较为重要的概念
-- 1、所有的sql语句均需要使用;来结束。
-- 2、创建库表的本质,其实是在hdfs中创建对应的目录。
-- 3、location后面跟hdfs的目录,不能是文件
-- 基本操作
show databases;
use default; --hive的默认数据库,如果创建表不指定库,将会默认放到default库中。
create database jxlg;
-- 创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] TABLENAME
[COLUMNNAME COLUMNTYPE [COMMENT 'COLUMN COMMENT'],...]
[COMMENT 'TABLE COMMENT']
[PARTITIONED BY (COLUMNNAME COLUMNTYPE [COMMENT 'COLUMN COMMENT'],...)]
[CLUSTERED BY (COLUMNNAME COLUMNTYPE [COMMENT 'COLUMN COMMENT'],...) [SORTED BY (COLUMNNAME [ASC|DESC])...] INTO NUM_BUCKETS BUCKETS]
[ROW FORMAT ROW_FORMAT]
[STORED AS FILEFORMAT]
[LOCATION HDFS_PATH];
-- 列的类型如下:
类型表格:
-
内部表和外部表的区别
1、创建方式 默认创建的内部表,创建外部表必须使用EXTERNAL。 2、使用场景 内部表一般多用于临时表;外部表一般多用永久性存储的表。 3、删除效果不一样 内部表删除后,将会删除元数据和hdfs中的数据;外部表删除后,将只会删除元数据,不删除hdfs中数据内容。 -- 创建内部表 ==表名不能使用关键字,比如user create table if not exists stu( stu_id int, stu_name string, age int, sex tinyint ) ; -- 创建外部表 create external table if not exists stu_ext( stu_id int comment 'this is id of student', stu_name string, age int, sex tinyint comment '1:男,2:女,3:未知' ) comment 'this is table of student' ; -- 指定库创建 hive (jxlg)> create table default.a(name string); hive (jxlg)> create table default.b(name string) location 'hdfs://hadoop01:9000//out/02'; #查询表数据 hive (jxlg)> create table default.b(name string) location 'hdfs://hadoop01:9000/out/02'; OK Time taken: 0.21 seconds hive (jxlg)> select * from default.b; OK good 1 gxlg 1 hello 2 is 2 jxlg 5 nice 1 Time taken: 3.541 seconds, Fetched: 6 row(s) -- 通过元数据验证其表的类型 查看如下图几张表所示。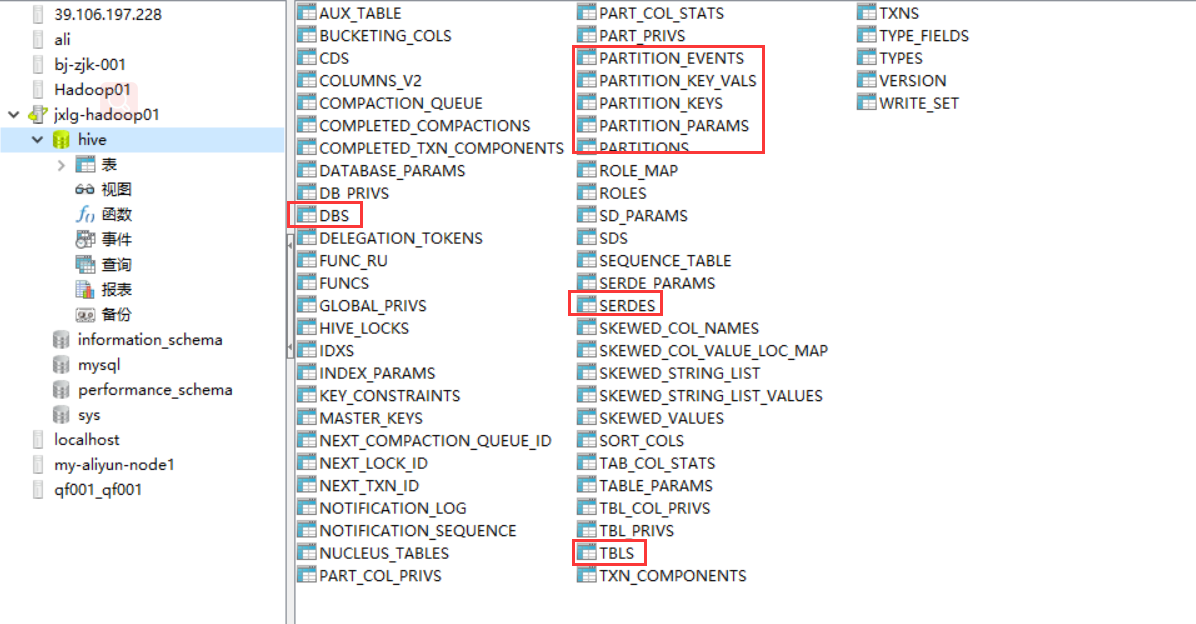
-- 删除内外部表查看效果
[root@hadoop01 ~]# hdfs dfs -cp /words /user/hive/warehouse/jxlg.db/stu
[root@hadoop01 ~]# hdfs dfs -cp /words /user/hive/warehouse/jxlg.db/stu_ext
#查看表描述
hive (jxlg)> desc stu;
hive (jxlg)> describe stu;
hive (jxlg)> show create table stu;
#删除表
hive (jxlg)> drop table if exists stu;
hive (jxlg)> drop table if exists stu_ext;
4.6 数据装载
hive的表数据加载,其实本质来说就是向hive表目录添加数据文件即可。注意:字段与字段之间分隔符默认为^A
-
1、直接使用hdfsput方式
[root@hadoop01 ~]# vi /home/hivedata/stu_ext 数据内容: 1^Agoudan^A16^A1 2,mazi,18,1 3 laotie 16 3 #直接put添加数据 [root@hadoop01 ~]# hdfs dfs -put /home/hivedata/stu_ext /user/hive/warehouse/jxlg.db/stu_ext #创建表 create table if not exists stu1( stu_id int, stu_name string, age int, sex tinyint ) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile ; #直接put添加数据 [root@hadoop01 ~]# hdfs dfs -put /home/hivedata/stu_ext /user/hive/warehouse/jxlg.db/stu1 #查看数据 hive (jxlg)> select * from stu1; OK NULL NULL NULL NULL 2 mazi 18 1 NULL NULL NULL NULL Time taken: 0.223 seconds, Fetched: 3 row(s) -
load加载数据方式
-- load data [local] inpath '/hivedata/user.txt' [overwrite] into table t_user; local代表从linux直接把数据装载到hive表中。如果不加则表示从hdfs文件系统把数据装载到hive表中,该方式会删除元数据。 overwrite代表将数据覆盖到hive表中。如果 不加则表示将数据追加到hive表中。 #追加数据 hive (jxlg)> load data local inpath '/home/hivedata/stu_ext' into table stu1; hive (jxlg)> select * from stu1; OK NULL NULL NULL NULL 2 mazi 18 1 NULL NULL NULL NULL NULL NULL NULL NULL 2 mazi 18 1 NULL NULL NULL NULL Time taken: 0.222 seconds, Fetched: 6 row(s) #覆盖数据 hive (jxlg)> load data local inpath '/home/hivedata/stu_ext' overwrite into table stu1; hive (jxlg)> select * from stu1; OK NULL NULL NULL NULL 2 mazi 18 1 NULL NULL NULL NULL #从hdfs中load数据 hive (jxlg)> load data inpath '/words' into table stu1; hive (jxlg)> select * from stu1; OK NULL NULL NULL NULL 2 mazi 18 1 NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL Time taken: 0.159 seconds, Fetched: 9 row(s) -
insert into方式加载
create table if not exists stu2( stu_id int, stu_name string, age int, sex tinyint ) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile ; create table if not exists stu3( stu_id int, stu_name string ) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile ; #加载数据 insert into stu2 select * from stu1 where stu_id is not null; #也可以使用如下方式写 from stu1 insert into stu2 select * insert into stu3 select stu_id,stu_name ; #覆盖数据 insert overwrite table insert overwrite table stu2 select * from stu1 where stu_id is not null; -
其他数据加载方式
-- like克隆 create table stu4 like stu2; --只克隆表结构 create table stu4 like stu2; --只克隆表结构加数据 -- location指定数据,只能指定目录 create table stu5 like stu2 location 'hdfs://hadoop01:9000/user/hive/warehouse/jxlg.db/stu2'; -- ctas形式加载数据 create table stu6 as select stu_id,stu_name from stu2 where stu_id is null;
4.7 分区
为什么分区
随着系统运行的时间越来越长,表的数据量越来越大,而hive查询通常是使用全表扫描,这样会导致大量不必要的数据扫描,从而大大降低了查询的效率。
为了提高查询的效率,从而引进分区技术,使用分区技术,能避免hive做全表扫描,从而提交查询效率。可以将用户的整个表在存储上分成多个子目录(子目录以分区变量的值来命名)
怎么分区
根据业务需求,通常以年、月、日、小时、地区等进行分区。
一般分为时间分区和业务分区
分区语法
-- 在创建Hive表时加上下面分区语法
[PARTITIONED BY (COLUMNNAME COLUMNTYPE [COMMENT 'COLUMN COMMENT'],...)]
分区的注意事项:
1、hive的分区名不区分大小写
2、hive的分区字段是一个伪字段,但是可以用来进行操作
3、一张表可以有一个或者多个分区,并且分区下面也可以有一个或者多个分区。
分区的意义
可以让用户在做数据统计的时候缩小数据扫描的范围,因为可以在select是指定要统计哪个分区,譬如某一天的数据,某个地区的数据等.
分区本质
在表的目录或者是分区的目录下在创建目录,分区的目录名为指定字段=值
分区操作
--创建分区表
create table if not exists stu7(
stu_id int,
stu_name string,
age int,
sex tinyint
)
partitioned by (class string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
;
#构造数据
[root@hadoop01 ~]# vi /home/hivedata/c1
1,zs,16,1
2,ls,18,2
3,ww,20,1
[root@hadoop01 ~]# vi /home/hivedata/c2
1,goudan,15,2
2,haoge,16,2
3,jige,18,1
#加载分区数据
load data local inpath "/home/hivedata/c1" into table stu7 partition(class="c1");
load data local inpath "/home/hivedata/c2" into table stu7 partition(class="c2");
#查询分区数据
hive (jxlg)> select * from stu7 where class='c1';
OK
1 zs 16 1 c1
2 ls 18 2 c1
3 ww 20 1 c1
#列出分区
hive (jxlg)> show partitions stu7;
OK
class=c1
class=c2
#增加分区
load data local inpath "/home/hivedata/c2" into table stu7 partition(class="c3");
hive (jxlg)> show partitions stu7;
#新增空分区
alter table stu7 add partition(class='c4');
hive (jxlg)> show partitions stu7;
OK
class=c1
class=c2
class=c3
class=c4
#删除分区
alter table stu7 drop partition(class='c4');
多级分区
#多级分区
create table if not exists stu8(
stu_id int,
stu_name string,
cost double,
dt bigint
)
partitioned by (year string,month string,day string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
;
#加载数据
[root@hadoop01 ~]# vi /home/hivedata/cs
1,goudan,456.6,1623986167126
2,haiyang,30.0,1623986167128
3,jian,22.2,1623986167166
#加载数据
load data local inpath "/home/hivedata/cs" into table stu8 partition(year="2021",month="06",day="18");
[root@hadoop01 ~]# vi /home/hivedata/cs
4,asong,36,1623899767000
5,xiangze,66,1623899767006
6,danni,80,1623899767008
#加载数据
load data local inpath "/home/hivedata/cs" into table stu8 partition(year="2021",month="06",day="17");
#查询数据
hive (jxlg)> select * from stu8 where day='18';
OK
1 goudan 456.6 1623986167126 2021 06 18
2 haiyang 30.0 1623986167128 2021 06 18
3 jian 22.2 1623986167166 2021 06 18
Time taken: 0.686 seconds, Fetched: 3 row(s)
hive (jxlg)> select * from stu8 where month='06';
OK
4 asong 36.0 1623899767000 2021 06 17
5 xiangze 66.0 1623899767006 2021 06 17
6 danni 80.0 1623899767008 2021 06 17
1 goudan 456.6 1623986167126 2021 06 18
2 haiyang 30.0 1623986167128 2021 06 18
3 jian 22.2 1623986167166 2021 06 18
#设置严格模式 下对分区表查询必须使用分区字段来过滤数据
hive (jxlg)> set hive.mapred.mode=strict;
hive (jxlg)> select * from stu8; -- 会报错
hive (jxlg)> select * from stu8 where day='18';--正确
hive (jxlg)> select * from stu8 where stu_id='1'; -- 会报错
4.8 常见函数
-- hive函数大致分为两类:自带函数和自定义函数。
常用自带
hive (jxlg)> show functions; -- 列出已有的函数
-- 随机数
hive (jxlg)> select rand()*100;
-- 保留小数
hive (jxlg)> select round(rand()*100,2);
-- 切分
hive (jxlg)> select split(rand()*100,'\\.')[0];
-- 切分
hive (jxlg)> select substring(rand()*100,0,2);
-- 拼接
hive (jxlg)> select "1"+"2";
OK
3.0
Time taken: 0.078 seconds, Fetched: 1 row(s)
hive (jxlg)> select concat(1,2);
hive (jxlg)> select concat_ws('_','1','2','3');
OK
1_2_3
-- 类型转换
hive (jxlg)>select cast('2.0' as int);
OK
2
-- 字符串长度
hive (jxlg)> select length("abcdd");
OK
5
作业
将两周的hadoop基础和hive基础全部弄完。如果有问题随时联系我。
t exists stu7(
stu_id int,
stu_name string,
age int,
sex tinyint
)
partitioned by (class string)
row format delimited fields terminated by ‘,’
lines terminated by ‘\n’
stored as textfile
;
#构造数据
[root@hadoop01 ~]# vi /home/hivedata/c1
1,zs,16,1
2,ls,18,2
3,ww,20,1
[root@hadoop01 ~]# vi /home/hivedata/c2
1,goudan,15,2
2,haoge,16,2
3,jige,18,1
#加载分区数据
load data local inpath “/home/hivedata/c1” into table stu7 partition(class=“c1”);
load data local inpath “/home/hivedata/c2” into table stu7 partition(class=“c2”);
#查询分区数据
hive (jxlg)> select * from stu7 where class=‘c1’;
OK
1 zs 16 1 c1
2 ls 18 2 c1
3 ww 20 1 c1
#列出分区
hive (jxlg)> show partitions stu7;
OK
class=c1
class=c2
#增加分区
load data local inpath “/home/hivedata/c2” into table stu7 partition(class=“c3”);
hive (jxlg)> show partitions stu7;
#新增空分区
alter table stu7 add partition(class=‘c4’);
hive (jxlg)> show partitions stu7;
OK
class=c1
class=c2
class=c3
class=c4
#删除分区
alter table stu7 drop partition(class=‘c4’);
**多级分区**
```sql
#多级分区
create table if not exists stu8(
stu_id int,
stu_name string,
cost double,
dt bigint
)
partitioned by (year string,month string,day string)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
;
#加载数据
[root@hadoop01 ~]# vi /home/hivedata/cs
1,goudan,456.6,1623986167126
2,haiyang,30.0,1623986167128
3,jian,22.2,1623986167166
#加载数据
load data local inpath "/home/hivedata/cs" into table stu8 partition(year="2021",month="06",day="18");
[root@hadoop01 ~]# vi /home/hivedata/cs
4,asong,36,1623899767000
5,xiangze,66,1623899767006
6,danni,80,1623899767008
#加载数据
load data local inpath "/home/hivedata/cs" into table stu8 partition(year="2021",month="06",day="17");
#查询数据
hive (jxlg)> select * from stu8 where day='18';
OK
1 goudan 456.6 1623986167126 2021 06 18
2 haiyang 30.0 1623986167128 2021 06 18
3 jian 22.2 1623986167166 2021 06 18
Time taken: 0.686 seconds, Fetched: 3 row(s)
hive (jxlg)> select * from stu8 where month='06';
OK
4 asong 36.0 1623899767000 2021 06 17
5 xiangze 66.0 1623899767006 2021 06 17
6 danni 80.0 1623899767008 2021 06 17
1 goudan 456.6 1623986167126 2021 06 18
2 haiyang 30.0 1623986167128 2021 06 18
3 jian 22.2 1623986167166 2021 06 18
#设置严格模式 下对分区表查询必须使用分区字段来过滤数据
hive (jxlg)> set hive.mapred.mode=strict;
hive (jxlg)> select * from stu8; -- 会报错
hive (jxlg)> select * from stu8 where day='18';--正确
hive (jxlg)> select * from stu8 where stu_id='1'; -- 会报错
4.8 常见函数
-- hive函数大致分为两类:自带函数和自定义函数。
常用自带
hive (jxlg)> show functions; -- 列出已有的函数
-- 随机数
hive (jxlg)> select rand()*100;
-- 保留小数
hive (jxlg)> select round(rand()*100,2);
-- 切分
hive (jxlg)> select split(rand()*100,'\\.')[0];
-- 切分
hive (jxlg)> select substring(rand()*100,0,2);
-- 拼接
hive (jxlg)> select "1"+"2";
OK
3.0
Time taken: 0.078 seconds, Fetched: 1 row(s)
hive (jxlg)> select concat(1,2);
hive (jxlg)> select concat_ws('_','1','2','3');
OK
1_2_3
-- 类型转换
hive (jxlg)>select cast('2.0' as int);
OK
2
-- 字符串长度
hive (jxlg)> select length("abcdd");
OK
5
作业
将两周的hadoop基础和hive基础全部弄完。如果有问题随时联系我。















 2292
2292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









