







前言
西瓜书作为机器学习的入门书籍,许多人慕名而来,但是稍微阅读一下,发现其也没有想象中那么入门。本人作为一名“傻瓜”,会在此记录自己傻瓜式的啃书过程和学习过程,希望能够对基础不好的朋友有一定的帮助。
希望在学习西瓜书的时候,你可以在之前学习过高数,概率论,线代(遗忘没有关系,时常翻阅使自己很快想起来),并且有西瓜书的pdf或者纸质书。
同时,本书存在一些各个方面的知识,第一遍的学习抓住重点,不理解的做个标记即可,有些知识可能是你用不到的。
同时,本人能力有限,理解难免出错,希望各位大佬指点和交流。
第一章绪论
1.1引言
y=f(x)
以上是一个普通的函数,但是也就是1.1引言关于机器学习过程最直观的表现。**我们已知x和y,通过学习算法求出一个f。**以上是最简单的理解。
x称为经验或者数据;y在西瓜问题中是分为好瓜/坏瓜,f术语代表一个模型(model.)。
关于第一页最后一句话:我们只需要了解关于本书的模型:泛指从数据中学到的结果
其余的模式和模型的含义不用考虑,在本书也见不到
机器学习形式化的定义(读懂即可):用P来衡量机器在某任务类T上的性能指标,若机器通过利用经验E在任务T上的性能P得到改善,我们认为机器对E进行了学习
1.2基本术语
1.2的内容介意大家将专业术语整理起来,遗忘时候进行查阅。
实例:
(色泽=青绿;跟蒂=蜷缩;敲声=浊响)
(色泽=乌黑;跟蒂=稍缩;敲声=沉闷)
(色泽=浅白;跟蒂=硬挺;敲声=清脆)
关于三维样本空间:
三个属性值张成三维属性空间,图中每个坐标点(向量)代表一个示例
| 术语名称 | 含义 |
|---|---|
| 数据集(data set) | 数据记录的集合,对应于x |
| 示例(instance)/样本(sample) | 单个的一个记录 |
| 属性(attribute)/特征(feature) | 反映事件或对象在某方面的表现或特质的事项 |
| 属性值(attribute value) | 属性的取值 |
| 样本空间/属性空间 | 属性张成的空间 |
| 假设(hypothesis) | 学得模型关于数据的某种潜在的规律,就是1.1中的h |
| 真相/真实(ground-truth) | 潜在规律的本身,对应于1.1中的f |
| 标记(label) | 实例结果的信息,对应于y |
| 分类(classification) | 预测的是离散值 |
| 回归(regression) | 预测的是连续值 |
| 二分类(binary classification) | 两个类别的分类,预期的称为正类,另一个称为反类 |
| 多分类(mutil-class classification) | 涉及到多个类别的分类 |
| 聚类(clustering) | 其目标是将数据集中的样本分成不同的组(或称为簇),使得同一组内的样本相互相似,而不同组间的样本差异较大。属于无监督学习 |
| 监督学习(supervised learning) | 模型从带标签的数据中学习,并尝试在新的未标记数据上预测正确的标签。 |
| 无监督学习(unsupervised learning) | 模型在没有预先标记的类别或结果的情况下学习数据的结构和模式 |
补充:独立同分布(independent and identically distributed)i.i.d.
独立(Independence): 指的是每一个随机变量与其他随机变量的取值无关,即一个随机变量的观测结果不会影响其他随机变量的观测结果。
同分布(Identically Distributed): 表示所有随机变量都来自同一个概率分布,它们具有相同的概率特性,如均值、方差等。
一般来说,训练样本越多,我们对于全体样本服从的未知分布D了解就越多。
训练样本越能反映样本空间的分布情况,训练出来的效果越好
1.3假设空间
1.3的内容主要是了解概念学习(后面有一章内容,现在不理解没事)和假设空间(重点)
首先,我们学习的从经验到模型,其实就是特殊到一般的过程,是归纳学习。
归纳学习分为两类:
- 广义的归纳学习:西瓜书学到的大部分都是广义的,是黑箱模型,不清楚具体的过程
- 狭义的归纳学习:概念学习,从假设空间中筛出版本空间,知道具体的过程

假设空间:假设空间是所有可能解的集合,这些解可以用来解释给定输入和输出之间的关系。
书中4x4x4+1=65,4是颜色的可能取值3+1,3代表能取三种颜色(西瓜有三种颜色),1代表可以取任意颜色都不影响是否是好瓜,其余几项同理,+1代表不存在好瓜这种东西。
以上有65种假设空间的模型,我们的学习目的就是在65种里面选一种尽可能满足训练集好瓜标准的模型。
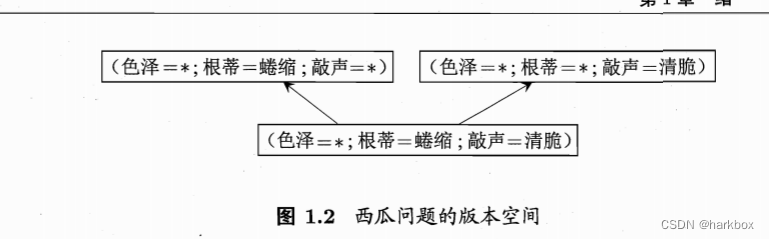
怎么样选取呢?我们将假设空间中与正例(训练集中好瓜就是正例)不一致的去掉,与反例(坏瓜就是反例)一致的去掉,就会获得一个版本空间。包含了基于本训练集的所有可能假设。
版本空间是概念学习的一种理论框架,特别是在符号主义或基于知识的人工智能方法中。
1.4归纳偏好
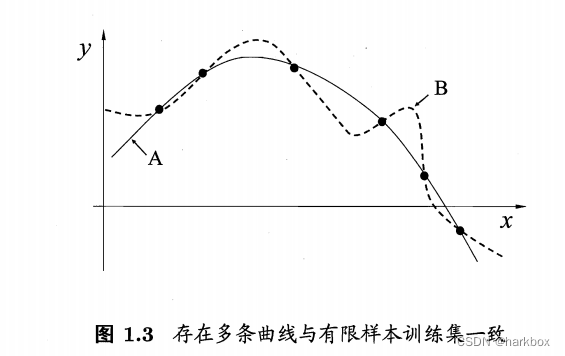
归纳偏好看作学习算法自身在一个可能很庞大的假设空间中对假设进行选择的“价值观”。或者可以说是在上述获得版本空间时,根据自己的归纳偏好选取最终的模型。
奥卡姆剃刀原理(剃刀剃成光头自然洗头什么的就简单了):若有多个假设与观察一致,选择最简单的那个。
但是什么是最简单的?又需要我们对其进行定义。
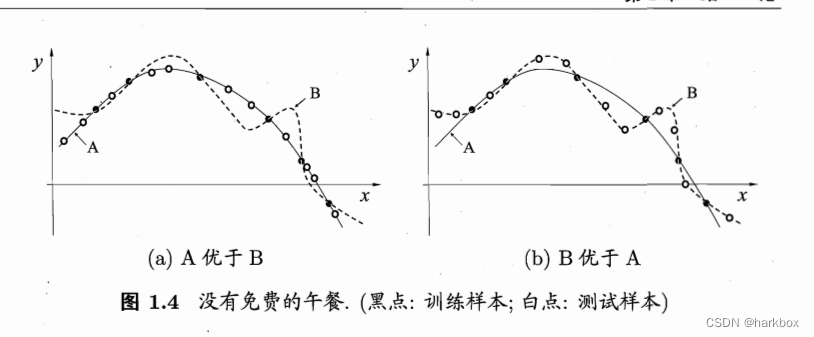
没有免费午餐定理(NFT):一个算法在某个数据集表现优秀,那么在另一个数据集表现一定很差。没有那个算法可以适用于任何情况。实事求是

从左到右:
E:数学期望,本问题西瓜在样本空间中是离散分布的,所以是离散型变量的数学期望
ote:out traning error训练集外误差
(|)在给定X和f的情况下看看学习算法a的训练集误差
P(h|):这是一个条件概率,在X下用学习算法a产生h的概率,这么默认h是多个,所以是一个概率
求和h:所有的h都要考虑到,所以求和
求和x:下标表示x(向量)取的是训练集外的数据,求和是要考虑所有的训练集外数据
P(x):表示去到该x的概率
II(x):相等为0,不计入,不相等产生误差,为1
以上可以看看离散型数学期望是怎么算的,理解起来应该会更容易


求和f:将所有的真实目标函数都考虑进来,我们本来的真实函数是存在某个规则判断好瓜,所有的真实函数可以理解为不仅仅是好瓜坏瓜,还包括判断瓜的种类,瓜的成熟与否等真理。。意思就是,将所有情况考虑进来。
第二行,f只有II中有,所以将求和f写到II旁边,其余同类
第三行:|x|表示特征空间/样本空间所有点的数量,II存在两种状况(0一样,1不一样)则2的|x|的平方表示所有样本点一共有多少种情况,比如2个样本点,4种情况(0,0)(1,0)(1,1)(0,1)(假设函数,真实函数)0是坏,1是好(从全局来看是1/2)1/2代表一半的概率是误差(假设真实不一样)。
第四行:一定会产生假设h,所以求和后概率为1
综上;NFT就是马原的实事求是
后两节省略,谢谢大家!















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









