







原文链接:https://blog.csdn.net/stu_shanghui/article/details/91491596
FCN(fully convolution net)
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全连接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像(为什么?因为全连接层的输入要求是个定值,这样层层向前推进,输入也就是固定的了),采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。

(1)在CNN中, 猫的图片输入到AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高, 用来做分类任务。
(2)FCN与CNN的区别在于把CNN最后的全连接层转换成卷积层,输出的是一张已经带有标签的图片, 而这个图片就可以做语义分割。
(3)CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征: 较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。高层的抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高, 所以我们常常可以将卷积层看作是特征提取器。

(1)全连接层转化为全卷积层 : 在CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个不同类别的概率。FCN将这3层表示为卷积层,卷积核的大小分别为 (1,1,4096)、(1,1,4096)、(1,1,1000)。
(2)经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。上图中7*78channel之后对原图像进行unpooling,把图像进行放大几次到原图像的大小。
UnPooling Unsampling和Deconvolution的区别:
unpooling是填充0,unsampling是填充相同的值

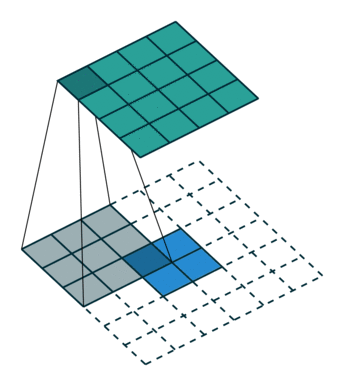
上图是full卷积,full卷积:输入(蓝色2*2大小的图形)为N1*N1,卷积核(灰色的3*3)大小为N2*N2,卷积后图像大小为N1+N2-1(绿色4*4)
图像的deconvolution实现过程:

输入:2X2, 卷积核4X4,滑动步长:3,输出7X7
输入与输出的关系为:outputSize = (input - 1) * stride + kernel_size
1.先对每一个像素做full卷积,卷积后输出大小为1+4-1=4,得到4*4大小的特征图(2*2大小分开卷积,相当于4个1*1的图形做卷积)
2.对四个特征图进行步长为3的fusion(相加),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第一行第四列是由红色特征图的第一行第四列与绿色特征图第一行第一列相加得到,其他的依此类推
反卷积说明
反卷积(deconvolutional)运算的参数和CNN的参数一样是在训练FCN模型的过程中通过bp算法学习得到。反卷积层也是卷积层,不关心input大小,滑窗卷积后输出output。deconv并不是真正的deconvolution(卷积的逆变换),最近比较公认的叫法应该是transposed convolution,deconv的前向传播就是conv的反向传播。
反卷积参数: 利用卷积过程filter的转置(先水平翻转,再竖直方向上翻转filter)作为计算卷积前的特征图。
蓝色是反卷积层的input,绿色是output


跳级(skip)结构
对CNN的结果做处理,得到了dense prediction,而作者在试验中发现,得到的分割结果比较粗糙,所以考虑加入更多前层的细节信息,也就是把倒数第几层的输出和最后的输出做一个fusion,就是对应元素相加

FCN例子: 输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为:20类目标+背景=21,模型基于AlexNet。
蓝色:卷积层。
绿色:Max Pooling层。
黄色: 求和运算, 使用逐数据相加,把三个不同深度的预测结果进行融合:较浅的结果更为精细,较深的结果更为鲁棒。
灰色: 裁剪, 在融合之前,使用裁剪层统一两者大小, 最后裁剪成和输入相同尺寸输出。
对于不同尺寸的输入图像,各层数据的尺寸(height,width)相应变化,深度(channel)不变。

FCN缺点
(1)得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
(2)对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。















 7666
7666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









