







原文链接:https://blog.csdn.net/weixin_40871455/article/details/86084560
transformer模型在《Attention is all you need》论文中提出
这篇论文主要亮点在于:1)不同于以往主流机器翻译使用基于RNN的seq2seq模型框架,该论文用attention机制代替了RNN搭建了整个模型框架。2)提出了多头注意力(Multi-headed attention)机制方法,在编码器和解码器中大量的使用了多头自注意力机制(Multi-headed self-attention)。3)在WMT2014语料中的英德和英法任务上取得了先进结果,并且训练速度比主流模型更快。
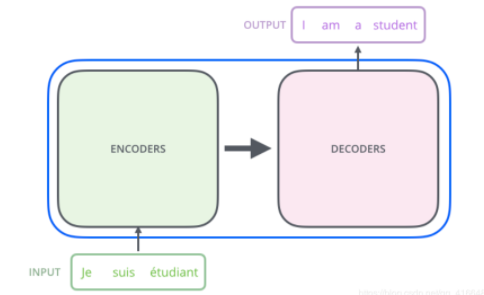
我们先把Transformer想象成一个黑匣子,在机器翻译的领域中,这个黑匣子的功能就是输入一种语言然后将它翻译成其他语言。如下图:

掀起The Transformer的盖头,我们看到在这个黑匣子由2个部分组成,一个Encoders和一个Decoders。
我们再对这个黑匣子进一步的剖析,发现每个Encoders中分别由6个Encoder组成(论文中是这样配置的)。而每个Decoders中同样也是由6个Decoder组成。

对于Encoders中的每一个Encoder,他们结构都是相同的,但是并不会共享权值。每层Encoder有2个部分组成,如下图:
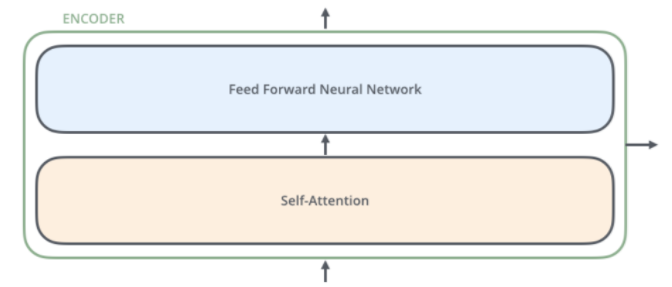
每个Encoder的输入首先会通过一个self-attention层,通过self-attention层帮助Endcoder在编码单词的过程中查看输入序列中的其他单词。
模型的整体结构如下图,由编码器和解码器组成,在编码器的一个网络块中,由一个多头attention子层和一个前馈神经网络子层组成,整个编码器栈式搭建了N个块。解码器类似于编码器,只是解码器的一个网络块中多了一个多头attention层。为了更好的优化深度网络,整个网络使用了残差连接和对层进行了规范化(Add&Norm)
我们在这里设定输入的句子为(x1,x2,x3,......xn);经过input embedding之后的序列为Z = (z1,z2,z3,......zn);经过encoder编码后输入decoder,然后输出的序列(y1,y2,y3,.......yn)

Encoder: 这里面有 N=6 个 一样的layers, 每一层包含了两个sub-layers. 第一个sublayer 就是多头注意力层(multi-head attention layer,在下一节会提到) 然后是一个简单的全连接层。 这里还有一个残差连接 (residual connection), 在这个基础上, 还有一个layer norm. 这里的注意力层会在下文详细解释。
Decoder: 这里同样是有六个一样的Layer是,但是这里的layer 和encoder 不一样, 这里的layer 包含了三个sub-layers, 其中有 一个self-attention layer, encoder-decoder attention layer ,最后是一个全连接层。 前两个sub-layer 都是基于multi-head attention layer. 这里有个特别点就是masking, masking 的作用就是防止在训练的时候 使用未来的输出的单词。 比如训练时, 第一个单词是不能参考第二个单词的生成结果的。 Masking就会把这个信息变成0, 用来保证预测位置 i 的信息只能参考比 i 小的输出。
现在我们以图示的方式来研究Transformer模型中各种张量/向量,观察从输入到输出的过程中这些数据在各个网络结构中的流动。

我们将每个单词编码为一个512维度的向量,我们用上面这张简短的图形来表示这些向量。词嵌入的过程只发生在最底层的Encoder。但是对于所有的Encoder来说,你都可以按下图来理解。输入(一个向量的列表,每个向量的维度为512维,在最底层Encoder作用是词嵌入,其他层就是其前一层的output)。另外这个列表的大小和词向量维度的大小都是可以设置的超参数。一般情况下,它是我们训练数据集中最长的句子的长度。

注意观察,在每个单词进入Self-Attention层后都会有一个对应的输出。Self-Attention层中的输入和输出是存在依赖关系的,而前馈层则没有依赖,所以在前馈层,我们可以用到并行化来提升速率。
Transformer中的每个Encoder接收一个512维度的向量的列表作为输入,然后将这些向量传递到‘self-attention’层,self-attention层产生一个等量512维向量列表,然后进入前馈神经网络,前馈神经网络的输出也为一个512维度的列表,然后将输出向上传递到下一个encoder。
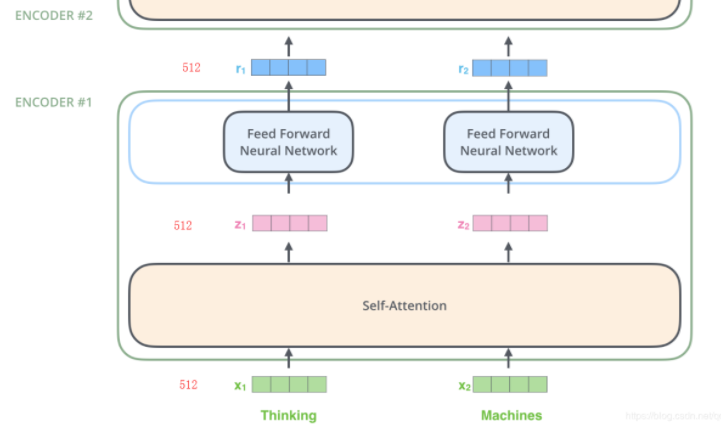
每个位置的单词首先会经过一个self attention层,然后每个单词都通过一个独立的前馈神经网络(这些神经网络结构完全相同)。
Self-Attention
计算self attention的第一步是从每个Encoder的输入向量上创建3个向量。对于每个单词,我们创建一个Query向量,一个Key向量和一个Value向量。这些向量是通过词嵌入乘以我们训练过程中创建的3个训练矩阵而产生的。
注意这些新向量的维度比嵌入向量小。我们知道嵌入向量的维度为512,而这里的新向量的维度只有64维。新向量并不是必须小一些,这是网络架构上的选择使得Multi-Headed Attention(大部分)的计算不变。
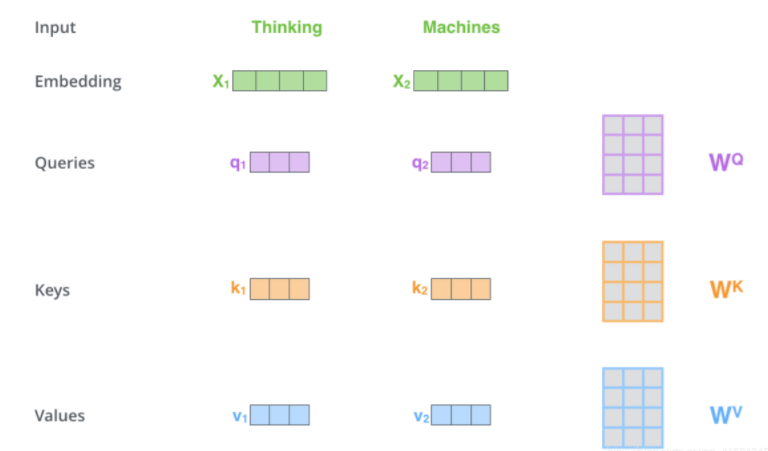

计算self attention的第二步是计算得分。以上图为例,假设我们在计算第一个单词“thinking”的self attention。我们需要根据这个单词对输入句子的每个单词进行评分。当我们在某个位置编码单词时,分数决定了对输入句子的其他单词的关照程度。
通过将query向量和key向量点击来对相应的单词打分。所以,如果我们处理开始位置的的self attention,则第一个分数为和的点积,第二个分数为和的点积。如下图
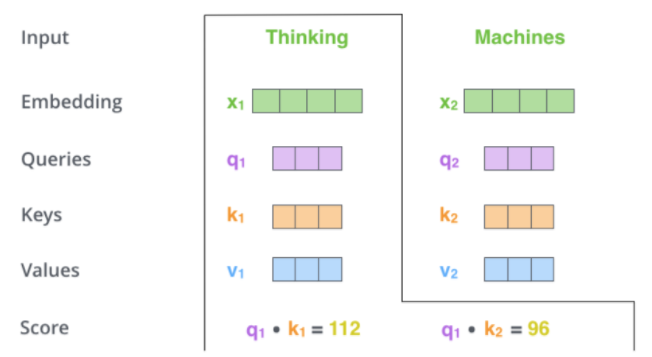
第三步和第四步的计算,是将第二部的得分除以8()(论文中使用key向量的维度是64维,其平方根=8,这样可以使得训练过程中具有更稳定的梯度。这个
并不是唯一值,经验所得)。然后再将得到的输出通过softmax函数标准化,使得最后的列表和为1。
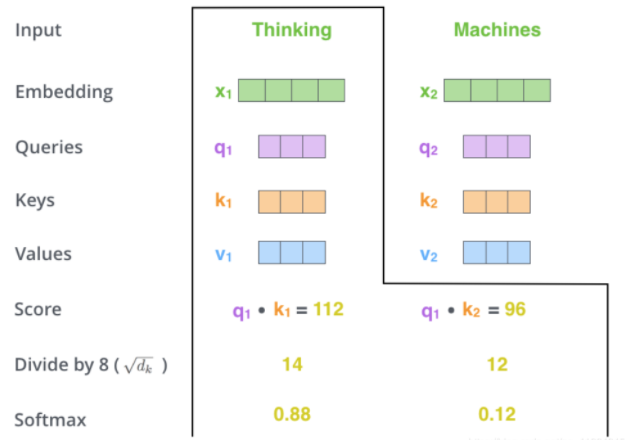
这个softmax的分数决定了当前单词在每个句子中每个单词位置的表示程度。很明显,当前单词对应句子中此单词所在位置的softmax的分数最高,但是,有时候attention机制也能关注到此单词外的其他单词,这很有用。
第五步是将每个Value向量乘以softmax后的得分。这里实际上的意义在于保存对当前词的关注度不变的情况下,降低对不相关词的关注。
第六步是 累加加权值的向量。 这会在此位置产生self-attention层的输出(对于第一个单词)。
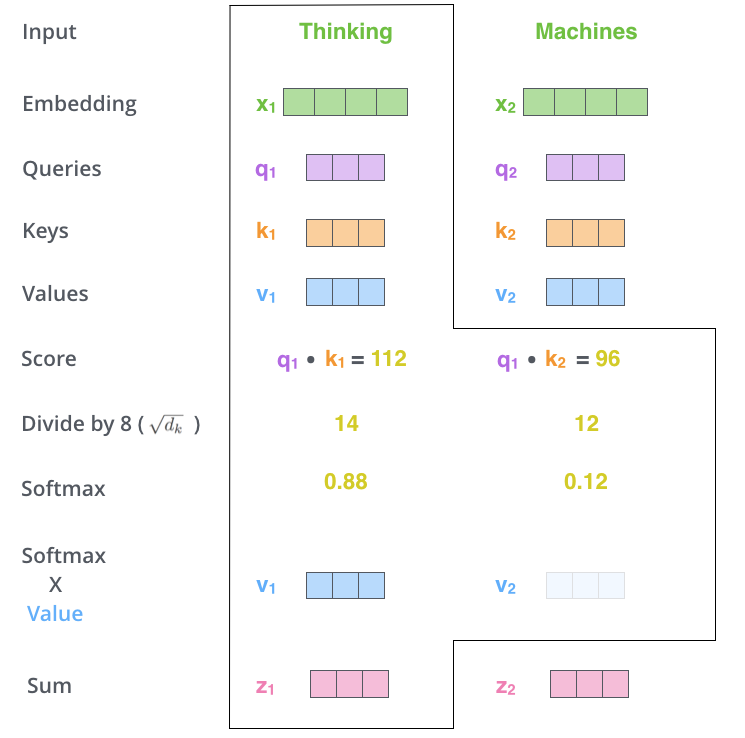
总结 Multi-Head Attention
在介绍多头attention之前,我们先看一下论文中提到的放缩点积attention(scaled dot-Product attention)。对比attention的一般形式,scaled dot-Product attention就是我们常用的使用点积进行相似度计算的attention,只是多除了一个(为K的维度)起到调节作用,使得内积不至于太大

多头attention(Multi-head attention)结构如下图,Query,Key,Value首先进过一个线性变换,然后输入到放缩点积attention (如上图),注意这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数W是不一样的。在input embedding结束后得到的Z直接赋值给Q,K,V,即Q=K=V=Z
每个头的计算方式:![]() 这里的W是三个不同的待训练的权值参数矩阵,由于有h个头,所以有h个维度,每个维度又是一个向量,
这里的W是三个不同的待训练的权值参数矩阵,由于有h个头,所以有h个维度,每个维度又是一个向量,![]() 指的是W矩阵的第i个维度,是一个向量。
指的是W矩阵的第i个维度,是一个向量。
然后将h次的放缩点积attention结果进行拼接(下图的黄色concat),再进行一次线性变换得到的值作为多头attention的结果。可以看到,google提出来的多头attention的不同之处在于进行了h次计算而不仅仅算一次,论文中说到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息

回看图一,encoder有N个子层叠加而成,encoder左边有个N,说明有n层,我们的论文中取N=6;对于encoder的每个子层中,进行multi-head attention计算后会进行残差连接以及归一化,然后送入全连接层,进行非线性变换,得到子层的输出,所用的激活函数为ReLU,注:这里在encoder的第一层会对Z拷贝head*3 份,分别作为K,V,Q的输入。然后在将上述的结构堆叠N层,就可以得到最终的Encoder的输出。
再次回看图一,我们发现Decoder也是由N层组成,将视野切换回单层的decoder中,我们发现decoder多了一个multi-head attention,该层的输入的Q为self-attention的输出,K和V来自Encoder(对应层)的输出,特别注意是对应层,什么意思呢,encoder的第一层的输出作为decoder第一层的输出,将图一立起来,从上往下,他们的堆叠关系如下图:
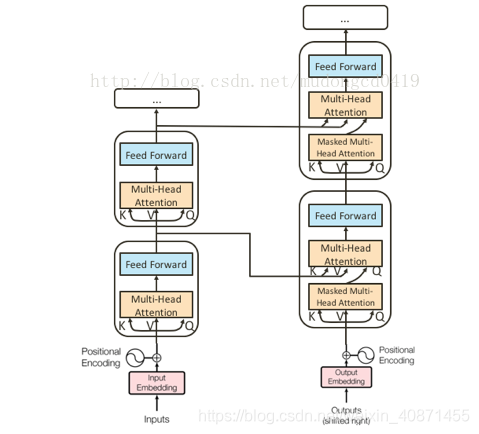
然后我们来看一些decoder中的masked multi head attention,所谓masked就是输出层在计算第j个词与其他词的attention时,只考虑j前面的词,因为j后面的词我们不知道是什么,我们需要预测后面的词,如果不掩盖的话,训练的时候相当于模型能看到后面的答案,而我们要求的是,decoder给定一个开始标志后,一步一步向后计算接下来的单词,所以需要mask
位置信息embedding
这里指的是 input embedding、output embedding 之后的有一个positional encoding

这里使用了两个函数, sin, cos, pos 用来表示单词的位置信息, 比如 第一个单词, 第二个单词什么的。 而 i 用来表达dimension。 论文中, d_{model} 是512, 那 i 应该是 0 到255. 这里呢, 为了好说明, 如果2i= d_{model}, PE 的函数就是sin(pos/10000), 那它的波长就是10000*2pi, 如果i =0, 那么他的波长 就是2pi. 这样的sin, cosin 的函数 是可以通过线性关系互相表达的。
Auto recursive decoding

这个图的encoding 过程, 主要是self attention, 有三层。 接下来是decoding过程, 也是有三层, 第一个预测结果 <start> 符号, 是完全通过encoding 里的attention vector 做出的决策。 而第二个预测结果Je, 是基于encoding attention vector & <start> attention vector 做出的决策。按照这个逻辑,新翻译的单词不仅仅依赖 encoding attention vector, 也依赖过去翻译好的单词的attention vector。 随着翻译出来的句子越来越多,翻译下一个单词的运算量也就会相应增加。 如果详细分析,复杂度是 (n^2d), 其中n是翻译句子的长度,d是word vector 的维度。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









