







目录
1 数据仓库基础概念
数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。数据仓库具有以下几个关键特征:
- 面向主题:数据仓库围绕企业的主要主题领域(如客户、产品、销售等)组织数据,而不是围绕应用程序或功能
- 集成性:数据仓库中的数据来自多个操作型系统,经过清洗、转换和整合
- 非易失性:数据一旦进入仓库就不会频繁更改,主要进行读操作
- 时变性:数据仓库中的数据包含时间维度,可以反映历史变化
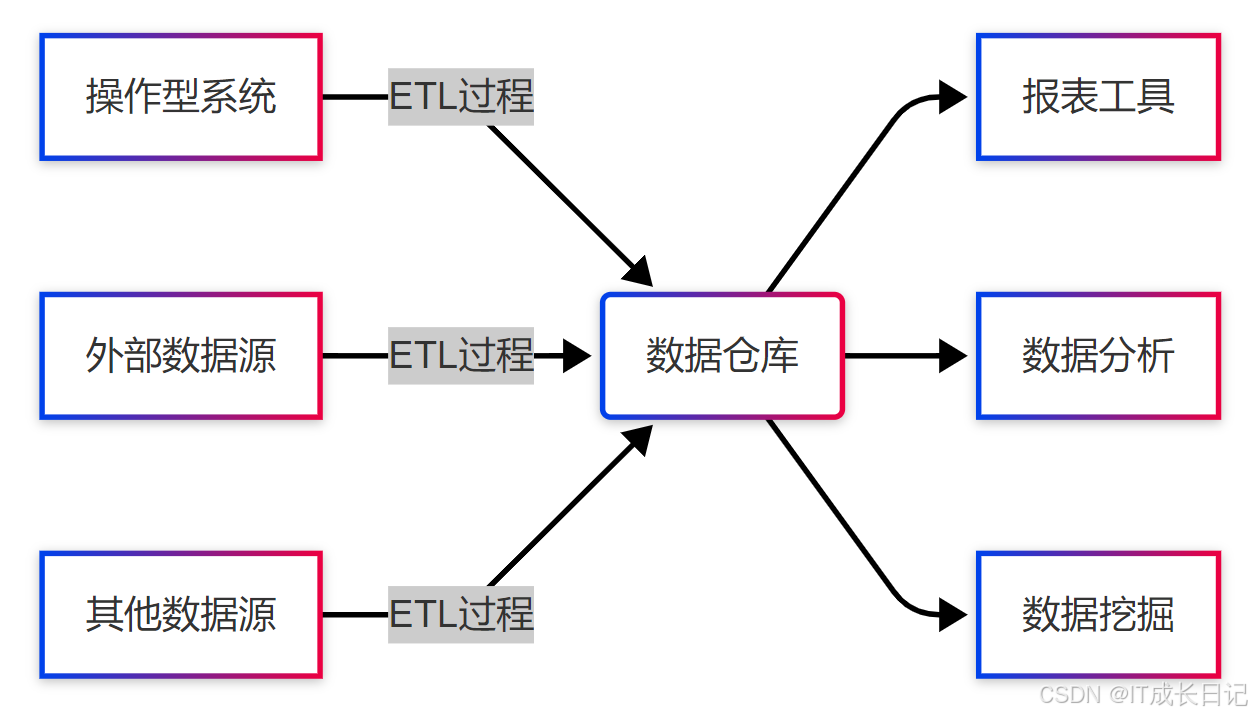
2 Hive的定位与核心架构
2.1 Hive在数据仓库生态系统中的定位
Hive是构建在Hadoop生态系统之上的数据仓库基础设施,它提供了以下核心功能:
- 数据存储:利用HDFS实现大规模数据的可靠存储
- 数据管理:通过表、分区、分桶等概念组织数据
- 数据查询:提供类SQL(HiveQL)接口进行数据分析
- 数据转换:支持ETL(Extract-Transform-Load)操作
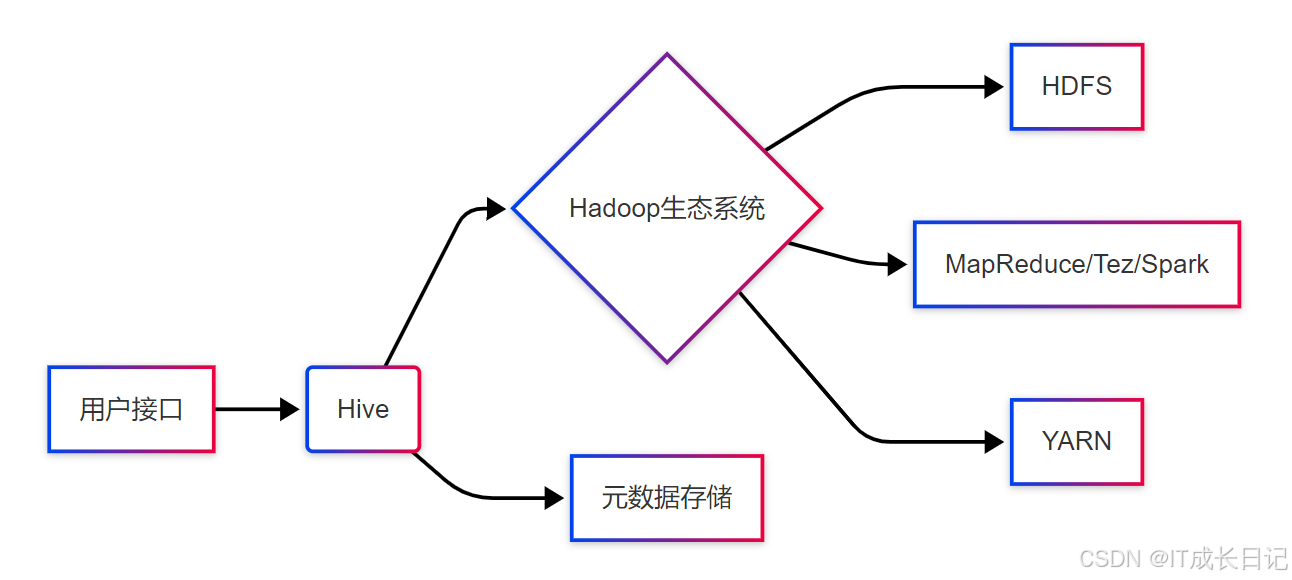
2.2 Hive的核心架构
Hive的架构主要包含以下组件:
- 用户接口:CLI、JDBC/ODBC、Web UI等
- 驱动引擎:解释器、编译器、优化器和执行器
- 元数据存储:通常使用关系型数据库(如MySQL)存储表结构等信息
- 执行引擎:默认使用MapReduce,也可配置为Tez或Spark

3 Hive作为数据仓库工具的特点
3.1 类SQL查询接口(HiveQL)
Hive提供了一种名为HiveQL的查询语言,它与SQL高度相似,这使得传统数据库开发人员能够相对容易地过渡到大数据环境。HiveQL支持:
- 数据定义语言(DDL):CREATE、ALTER、DROP等
- 数据操作语言(DML):INSERT、UPDATE、DELETE(有限支持)
- 数据查询语言(DQL):SELECT及其各种复杂查询
- 数据控制语言(DCL):GRANT、REVOKE等
-- HiveQL示例
CREATE TABLE IF NOT EXISTS employee (
id INT,
name STRING,
salary FLOAT,
department STRING
)
PARTITIONED BY (year INT, month INT)
STORED AS ORC;3.2 强大的数据组织能力
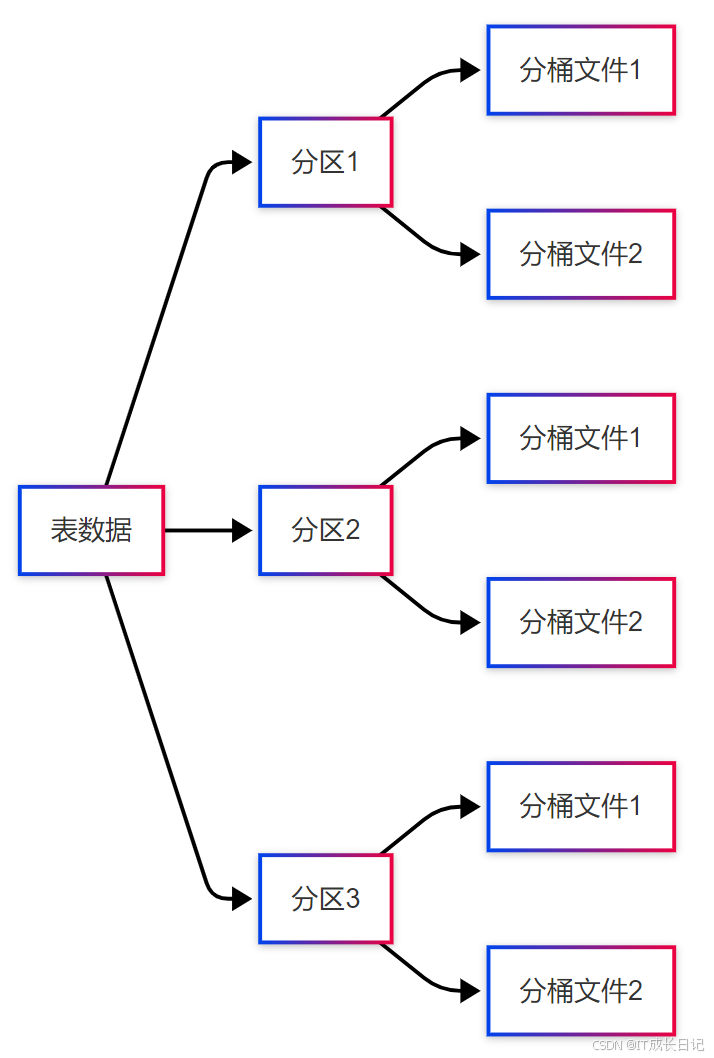
Hive提供了多种数据组织方式,使其非常适合数据仓库场景:
- 分区(Partitioning):根据某列的值将表数据物理分割到不同目录
- 分桶(Bucketing):根据哈希函数将数据均匀分布到固定数量的文件中
- 存储格式:支持多种文件格式(TextFile、SequenceFile、ORC、Parquet等)
- 压缩:支持多种压缩算法(Snappy、Gzip、Bzip2等)
3.3 扩展性与灵活性
Hive具有极强的扩展性:
- 自定义函数(UDF):用户可以编写自己的函数扩展Hive功能
- SerDe(序列化/反序列化):支持自定义数据格式处理
- 执行引擎可插拔:支持MapReduce、Tez、Spark等多种计算引擎
- 存储处理程序:可以集成HBase、Druid等其他存储系统
4 Hive在数据仓库中的优势
4.1 处理大规模数据的能力
Hive建立在Hadoop之上,天然具备处理PB级数据的能力:
- 水平扩展:可以通过增加节点线性扩展处理能力
- 容错性:数据在HDFS上有多个副本,计算失败可自动重试
- 批处理优化:针对大规模扫描操作进行了优化
4.2 成本效益
与传统数据仓库解决方案相比,Hive具有显著的成本优势:
- 开源免费:无需支付高昂的软件许可费用
- 商用硬件:运行在普通服务器组成的集群上
- 线性扩展:按需增加节点,初始投资可很小
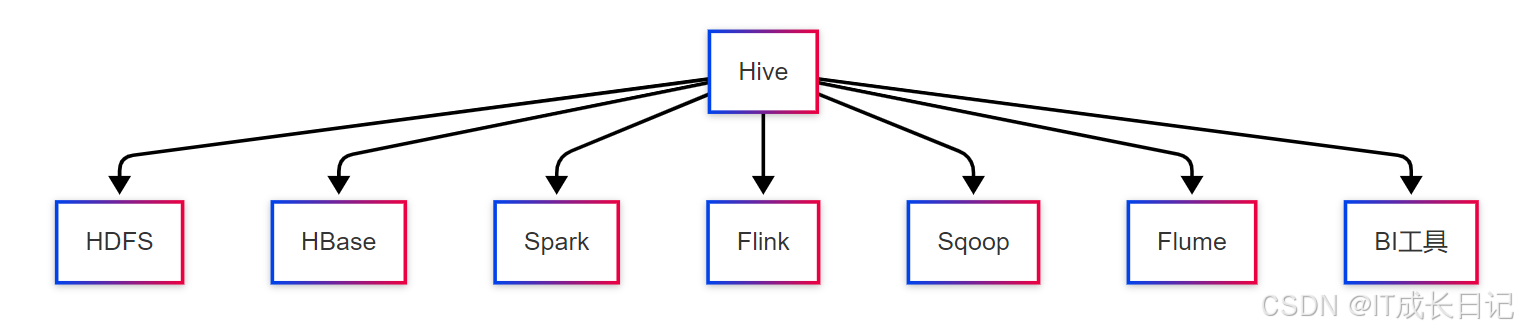
4.3 与Hadoop生态系统的无缝集成
Hive可以轻松与Hadoop生态系统中的其他工具集成:
- 数据采集:与Flume、Sqoop等数据采集工具集成
- 数据处理:与Spark、Flink等数据处理框架协同工作
- 数据可视化:通过JDBC/ODBC与Tableau、Superset等BI工具连接
4.4 元数据管理
Hive的元数据管理系统提供了与传统数据仓库类似的体验:
- 表结构存储:表名、列名、数据类型等信息存储在元数据库中
- 数据统计:收集和存储表的统计信息用于查询优化
- 权限控制:基于角色的访问控制(RBAC)
5 Hive与传统数据仓库的对比
| 特性 | 传统数据仓库 | Hive |
| 架构 | 共享一切(Share-Everything) | 无共享(Share-Nothing) |
| 扩展性 | 垂直扩展 | 水平扩展 |
| 数据规模 | TB级 | PB级 |
| 查询延迟 | 亚秒级 | 分钟级或更长 |
| 数据更新 | 完全支持 | 有限支持(需要特殊配置) |
| 成本 | 高 | 低 |
| 数据类型 | 结构化数据 | 结构化/半结构化数据 |
| 最佳适用场景 | 交互式分析 | 批处理分析 |
6 Hive的适用场景
- 大数据批处理分析:处理日志分析、ETL作业等
- 数据仓库建设:构建企业级数据仓库或数据集市
- 历史数据分析:分析时间序列数据或历史快照
- 数据探索:对原始数据进行初步探索和分析
7 Hive的局限性
尽管Hive作为数据仓库工具非常强大,但也存在一些局限性:
- 延迟较高:不适合交互式查询场景
- 更新限制:对ACID事务支持有限(虽然Hive 3有所改进)
- 学习曲线:需要理解Hadoop生态系统和分布式计算概念
- 实时分析:不适合实时或近实时分析需求
8 总结
Hive作为一个建立在Hadoop之上的数据仓库工具,通过提供类SQL接口、强大的数据组织能力和与Hadoop生态系统的深度集成,成功填补了传统数据仓库与大数据技术之间的鸿沟。它特别适合处理超大规模数据集、构建企业级数据仓库和执行复杂的批处理分析任务。虽然Hive在实时性方面存在不足,但通过不断的技术演进(如LLAP、ACID支持改进等),它正在扩展其适用场景。对于已经投资Hadoop生态系统的组织,或者需要处理PB级数据的场景,Hive无疑是一个极具价值的数据仓库解决方案。在选择数据仓库技术时,组织应根据自身的数据规模、分析需求和实时性要求,权衡Hive与其他解决方案(如传统数据仓库、MPP数据库或实时分析系统)的优缺点,做出合理的技术选型决策。


















 1199
1199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











