







目录
2.3 RCFile(Record Columnar File)
2.4 ORC(Optimized Row Columnar)
1 Hive存储格式概述
在大数据生态系统中,Hive作为构建在Hadoop之上的数据仓库工具,其存储格式的选择直接影响着查询性能、存储效率和扩展能力。Hive支持多种存储格式,每种格式都有其独特的设计哲学和适用场景。
1.1 什么是Hive存储格式
Hive存储格式指的是Hive表数据在HDFS上的物理组织方式,它决定了:
- 数据如何被序列化到存储介质
- 数据如何被反序列化回内存对象
- 数据的压缩方式和效率
- 查询引擎如何高效读取所需数据
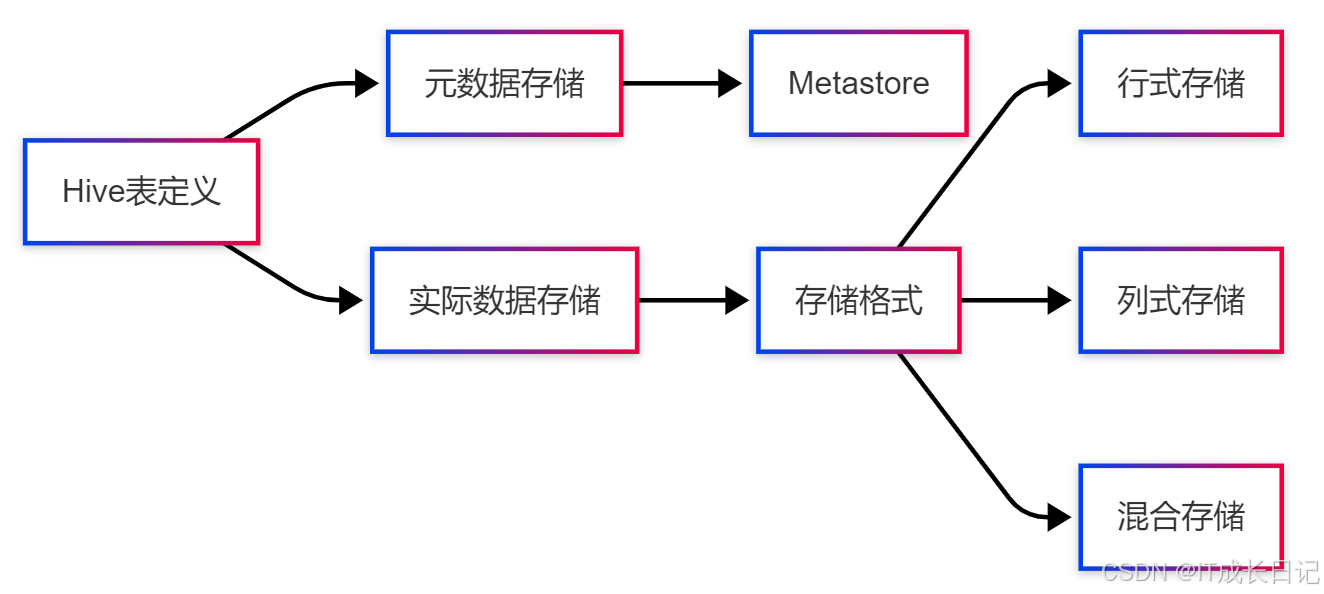
1.2 存储格式的核心组件
任何Hive存储格式都由三个关键组件组成:
- 序列化/反序列化器(SerDe):负责在Hive内部对象和存储字节流之间转换
- 输入格式(InputFormat):定义如何读取数据文件
- 输出格式(OutputFormat):定义如何写入数据文件
2 常见Hive存储格式详解
2.1 文本格式(TextFile)
基本特点:
- 默认存储格式
- 纯文本形式存储,人类可读
- 每行代表一条记录
- 支持自定义分隔符
适用场景:
- 数据交换和临时存储
- 需要人工查看原始数据的场景
- 与其他系统兼容性要求高的场景
- 建表示例
CREATE TABLE text_table (
id INT,
name STRING,
value DOUBLE
)
STORED AS TEXTFILE;2.2 序列文件(SequenceFile)
基本特点:
- 二进制键值对存储格式
- 支持块压缩和记录压缩
- 可分割(Splittable),适合MapReduce处理
- 比TextFile更紧凑的存储
- 内部结构:
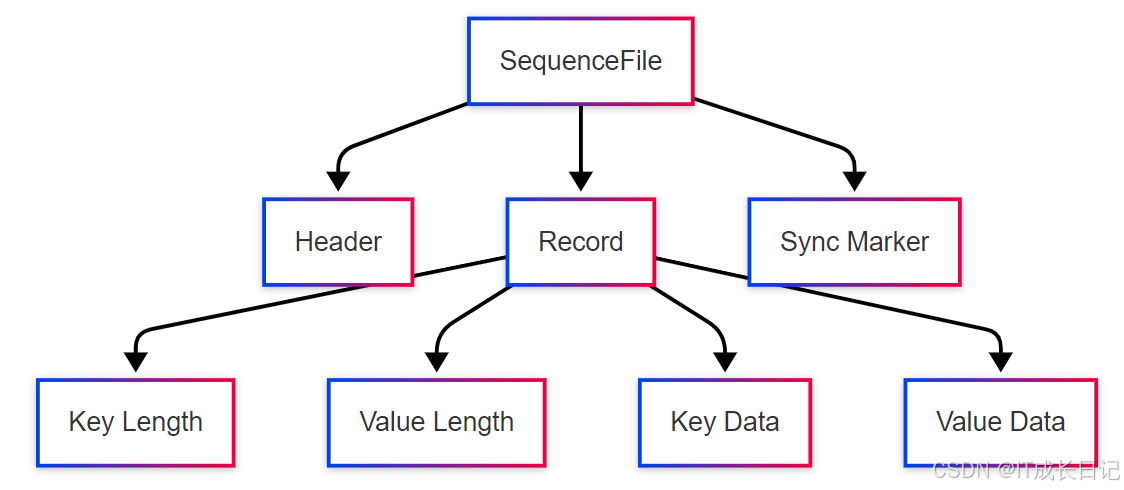
适用场景:
- 中等规模数据的存储
- 需要支持压缩的场景
- MapReduce作业的中间结果存储
性能特点:
- 比TextFile节省约20-30%存储空间
- 读取性能优于TextFile
- 写入性能略低于TextFile
2.3 RCFile(Record Columnar File)
设计理念:
- 混合行列存储格式
- 先水平分区(行组),再垂直分区(列存储)
- 延迟物化技术
- 存储结构:
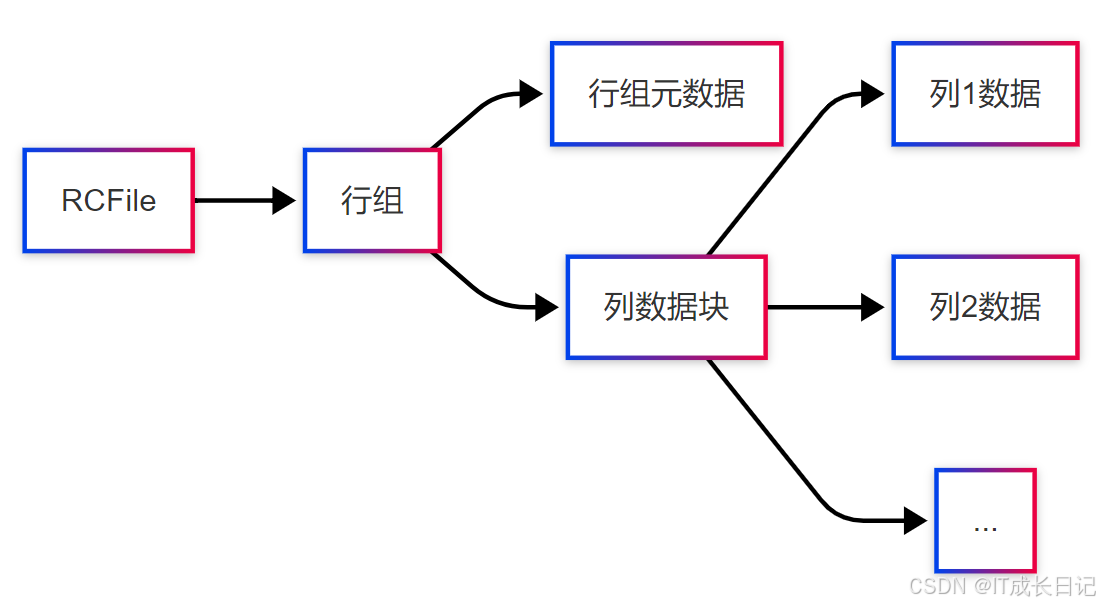
优势特点:
- 快速数据加载
- 高效查询处理
- 高效存储空间利用率
- 自适应负载优化
适用场景:
- 需要同时考虑加载和查询性能的场景
- 中等规模数据分析
- 需要平衡行列存储优势的场景
2.4 ORC(Optimized Row Columnar)
核心特性:
- 高度优化的行列存储格式
- 支持ACID操作
- 内置轻量级索引(布隆过滤器、最小值/最大值)
- 支持复杂数据类型
- 文件结构:
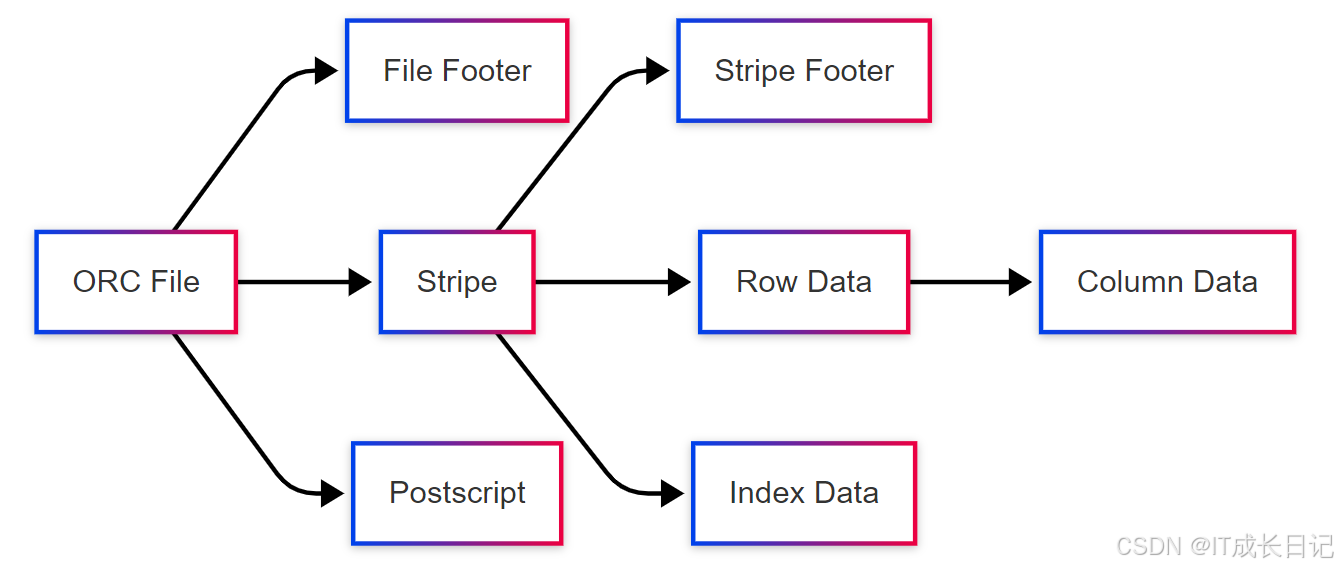
高级特性:
- 谓词下推:利用轻量级索引跳过无关数据
- 向量化执行:支持批量处理数据
- 延迟物化:减少不必要的数据反序列化
- 二级索引:支持布隆过滤器等高级索引
2.5 Parquet
设计哲学:
- 列式存储优化
- 为复杂嵌套数据结构设计
- 与处理框架无关
核心技术:
- 行列组(Row Group):数据处理单元
- 列块(Column Chunk):存储实际数据
- 页(Page):压缩和编码单元
- 文件结构:
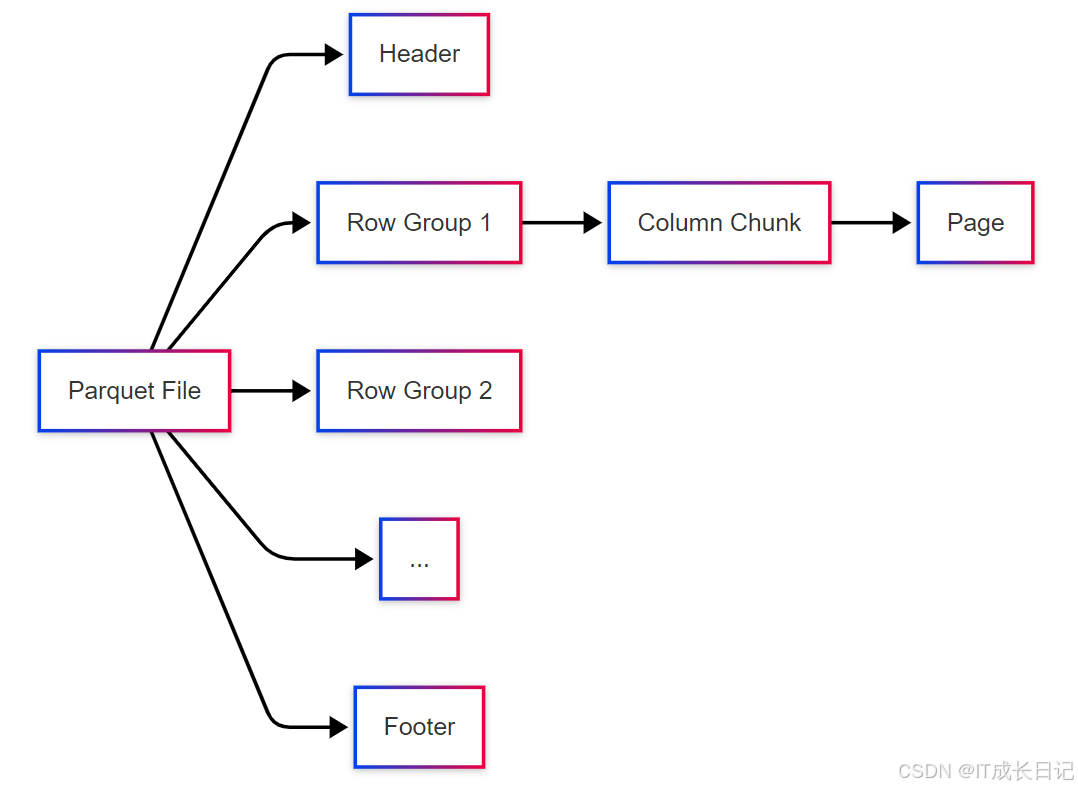
独特优势:
- 卓越的嵌套数据支持
- 跨平台兼容性
- 高级统计信息
- 灵活的压缩选项
3 存储格式选择标准
3.1 数据访问模式分析
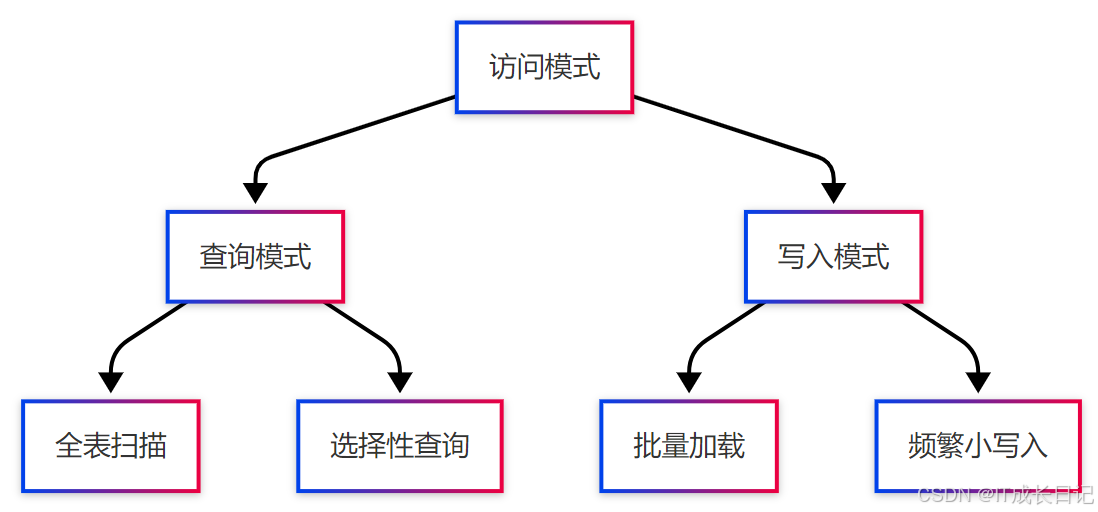
3.2 综合选择矩阵
| 考虑因素 | TextFile | SequenceFile | RCFile | ORC | Parquet |
| 读取性能 | 低 | 中 | 中高 | 高 | 高 |
| 写入性能 | 高 | 中 | 中 | 中 | 中低 |
| 存储效率 | 低 | 中 | 中高 | 高 | 高 |
| 压缩支持 | 有限 | 好 | 好 | 优秀 | 优秀 |
| 模式演化 | 容易 | 困难 | 困难 | 中等 | 优秀 |
| 复杂数据类型 | 基本 | 基本 | 基本 | 支持 | 优秀 |
| ACID支持 | 无 | 无 | 无 | 支持 | 有限 |
3.3 典型场景推荐
- 数据湖基础存储:Parquet
- Hive数仓核心表:ORC
- ETL中间结果:SequenceFile
- 临时/交换数据:TextFile
- 嵌套数据处理:Parquet
4 性能优化实践
4.1 ORC优化技巧
- 调整Stripe大小:
SET hive.exec.orc.default.stripe.size=256671088; -- 256MB- 启用压缩:
SET hive.exec.orc.default.compress=SNAPPY;- 利用索引:
CREATE TABLE orc_table (...)
STORED AS ORC
TBLPROPERTIES ("orc.create.index"="true");4.2 Parquet调优策略
- 优化行组大小:
SET parquet.block.size=268435456; -- 256MB- 选择压缩算法:
SET parquet.compression=SNAPPY;- 谓词下推配置:
SET parquet.filter.pushdown=true;5 总结
Hive存储格式的选择是大数据架构设计中的关键决策之一。通过本文的详细分析,我们可以看到,没有"放之四海而皆准"的最佳格式,只有最适合特定场景的选择。ORC和Parquet作为当前主流的列式存储格式,在大多数分析场景中表现优异,但传统的TextFile和SequenceFile仍然有其特定的应用价值。在实际项目中,建议:
- 基于工作负载特征进行基准测试
- 考虑数据全生命周期的格式需求
- 监控格式选择带来的长期影响
- 保持对新兴存储格式的关注
通过科学的存储格式选择和优化,可以显著提升Hive数据仓库的性能和效率,为大数据分析提供坚实的基础。


















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











