






1:自信息
概率越大信息量越小,一个事件x的自信息: I(x) = -log(p(x))
2:信息熵
用来形容某个样本的不确定性总量
熵越大,样本的不确定性就越大
1:相对熵(KL散度):衡量两个分布的差异
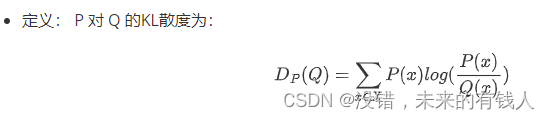
2:交叉熵:两个随机变量的“距离”

3:最大似然估计:
最大似然估计是一种统计方法,用于估计模型参数,使得观测到的数据出现的概率最大。
4:kl散度和交叉熵的关系:
1:联合熵:两个随机变量X,Y的联合分布
2:条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。
1:互信息:两个随机变量X,Y的互信息 为X,Y的联合分布和各自独立分布乘积的相对熵。
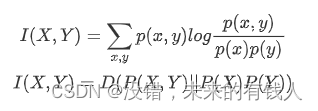
分层抽样适用的范围:可以事先掌握信息的组成
当总体由差异明显的几部分组成的时候,适合用分层抽样
1:伯努利分布:是只有两种可能结果的单次随机试验,每次试验都只有两个结果 0 或者 1
2:二项分布:是n重伯努利试验成功次数的离散概率分布
n重伯努利试验: 将伯努利试验独立重复进行 n 次, 称为 n 重伯努利试验
3:Beta分布:贝塔分布是定义在区间[0, 1]上的连续概率分布。它的概率密度函数(PDF)由两个正实数参数α(alpha)和β(beta)控制,这两个参数决定了分布的形状。

1:向量范数

2:矩阵的范数




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









