







由于这两个模块比较相像,而且结果也都十分的好,且CMX在nyu数据集上取得了第一的成绩,两个都是在encoder进行特征的矫正,交互,融合。
先看一下模型框架:
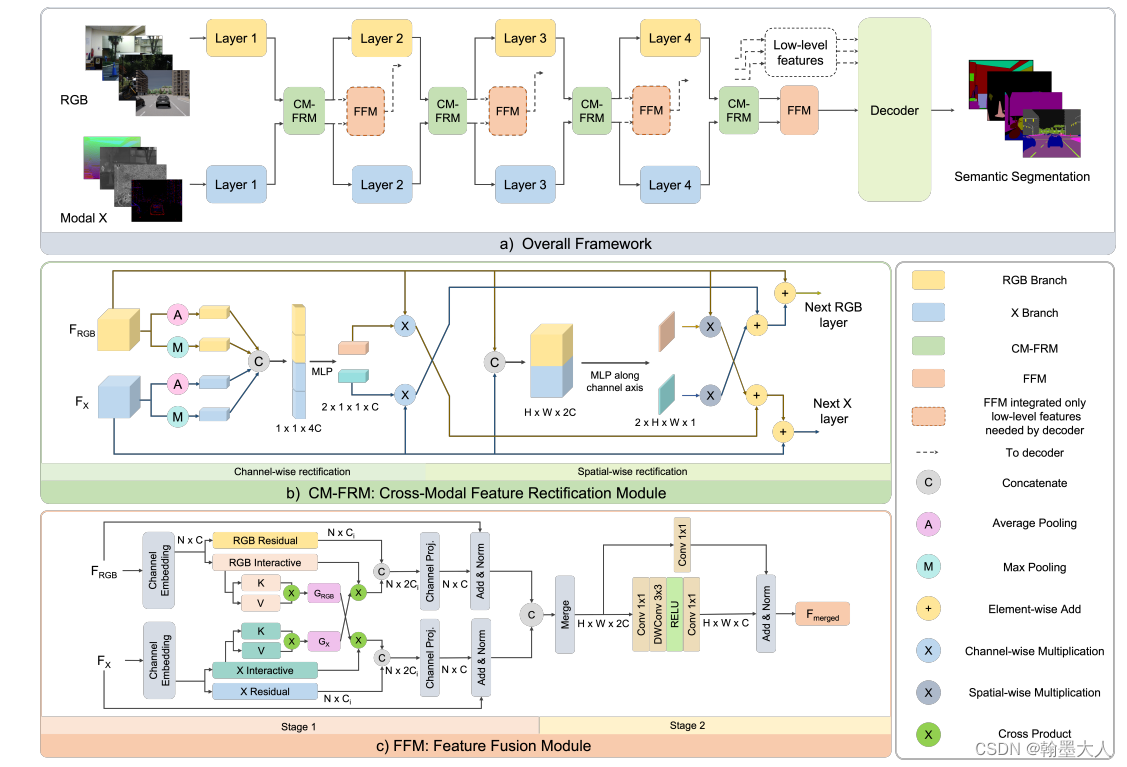
这里主要看他们的创新点模块的实现,就不看整体框架的搭建了。
先看CMX的:
模型首先经过FRM模块,
class FeatureRectifyModule(nn.Module):
def __init__(self, dim, reduction=1, lambda_c=.5, lambda_s=.5):
super(FeatureRectifyModule, self).__init__()
self.lambda_c = lambda_c
self.lambda_s = lambda_s
self.channel_weights = ChannelWeights(dim=dim, reduction=reduction)
self.spatial_weights = SpatialWeights(dim=dim, reduction=reduction)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x1, x2):
channel_weights = self.channel_weights(x1, x2)
spatial_weights = self.spatial_weights(x1, x2)
out_x1 = x1 + self.lambda_c * channel_weights[1] * x2 + self.lambda_s * spatial_weights[1] * x2
out_x2 = x2 + self.lambda_c * channel_weights[0] * x1 + self.lambda_s * spatial_weights[0] * x1
return out_x1, out_x2
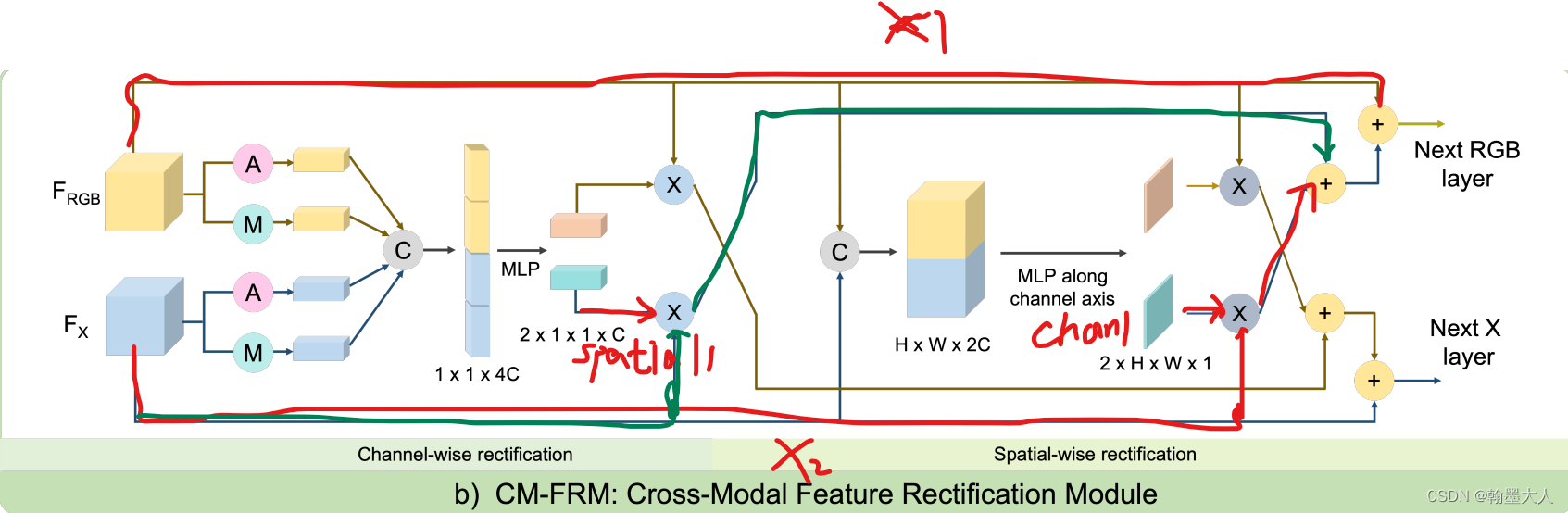
输入的rgb和depth首先经过通道和空间注意力生成权重,我们调到两个注意力的代码:
先看ChannelWeights,首先获得x1大小,然后将x1和x2拼接起来,经过自适应平均池化和自适应最大池化,并转换到(B,2C)大小,然后将两个结果拼接起来,变为(B,4C),经过mlp函数,通道又变为2C,然后reshape为(2 B C 1 1)大小。那么他就是有两个tensor组成的,大小分别为channel_weights[0]=(B,C,1,1), channel_weights[1]=(B,C,1,1)。
class ChannelWeights(nn.Module):
def __init__(self, dim, reduction=1):
super(ChannelWeights, self).__init__()
self.dim = dim
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.mlp = nn.Sequential(
nn.Linear(self.dim * 4, self.dim * 4 // reduction),
nn.ReLU(inplace=True),
nn.Linear(self.dim * 4 // reduction, self.dim * 2),
nn.Sigmoid())
def forward(self, x1, x2):
B, _, H, W = x1.shape
x = torch.cat((x1, x2), dim=1)
avg = self.avg_pool(x).view(B, self.dim * 2)
max = self.max_pool(x).view(B, self.dim * 2)
y = torch.cat((avg, max), dim=1) # B 4C
y = self.mlp(y).view(B, self.dim * 2, 1)
channel_weights = y.reshape(B, 2, self.dim, 1, 1).permute(1, 0, 2, 3, 4) # 2 B C 1 1
return channel_weights # channel_weights[0]=(B,C,1,1) channel_weights[1]=(B,C,1,1)
接着看SpatialWeights,将rgb和depth拼接起来,然后经过mlp函数,经过reshape函数,在permute到(2,B,1,H,W)大小。同样spatial_weights[0]=(B 1 H W),spatial_weights[1]=(B 1 H W)。
class SpatialWeights(nn.Module):
def __init__(self, dim, reduction=1):
super(SpatialWeights, self).__init__()
self.dim = dim
self.mlp = nn.Sequential(
nn.Conv2d(self.dim * 2, self.dim // reduction, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(self.dim // reduction, 2, kernel_size=1),
nn.Sigmoid())
def forward(self, x1, x2):
B, _, H, W = x1.shape
x = torch.cat((x1, x2), dim=1) # B 2C H W
spatial_weights = self.mlp(x).reshape(B, 2, 1, H, W).permute(1, 0, 2, 3, 4) # 2 B 1 H W
return spatial_weights
我们得到两个权重,然后继续往下看,out_x1 = x1 + self.lambda_c * channel_weights[1] * x2 + self.lambda_s * spatial_weights[1] * x2,如图标注了数据处理。out_x2同理。
然后是FFM模块,分为两个stage:
class FeatureFusionModule(nn.Module):
def __init__(self, dim, reduction=1, num_heads=None, norm_layer=nn.BatchNorm2d):
super().__init__()
self.cross = CrossPath(dim=dim, reduction=reduction, num_heads=num_heads)
self.channel_emb = ChannelEmbed(in_channels=dim*2, out_channels=dim, reduction=reduction, norm_layer=norm_layer)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x1, x2):
B, C, H, W = x1.shape
x1 = x1.flatten(2).transpose(1, 2) #(B,C,N)-->(B,N,C)
x2 = x2.flatten(2).transpose(1, 2) #(B,C,N)-->(B,N,C)
x1, x2 = self.cross(x1, x2) #(B,N,C)
merge = torch.cat((x1, x2), dim=-1) #(B,N,2C)
merge = self.channel_emb(merge, H, W)#(B,C,H,W)
return merge
首先我们将输入展平,并转置为(B,N,C)形式,然后两个输入共同经过cross函数,对应于crosspath函数:
class CrossPath(nn.Module):
def __init__(self, dim, reduction=1, num_heads=None, norm_layer=nn.LayerNorm):
super().__init__()
self.channel_proj1 = nn.Linear(dim, dim // reduction * 2)
self.channel_proj2 = nn.Linear(dim, dim // reduction * 2)
self.act1 = nn.ReLU(inplace=True)
self.act2 = nn.ReLU(inplace=True)
self.cross_attn = CrossAttention(dim // reduction, num_heads=num_heads)
self.end_proj1 = nn.Linear(dim // reduction * 2, dim)
self.end_proj2 = nn.Linear(dim // reduction * 2, dim)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
def forward(self, x1, x2):
y1, u1 = self.act1(self.channel_proj1(x1)).chunk(2, dim=-1) #(B,N,C)->(B,N,2C)-->{(b,n,c),(b,n,c)}
y2, u2 = self.act2(self.channel_proj2(x2)).chunk(2, dim=-1) #(B,N,C)->(B,N,2C)-->{(b,n,c),(b,n,c)}
v1, v2 = self.cross_attn(u1, u2) #(B,N,C)
y1 = torch.cat((y1, v1), dim=-1)#(b,n,2c)
y2 = torch.cat((y2, v2), dim=-1)
out_x1 = self.norm1(x1 + self.end_proj1(y1))#(B,N,2C)-->(B,N,C)
out_x2 = self.norm2(x2 + self.end_proj2(y2))
return out_x1, out_x2
展平的两个输入,先投射,维度扩大两倍,然后进行切割为两个维度为(B,N,C)大小的tensor,输出为y1, u1,同理x2,输出为 y2, u2,然后u1,u2做一个交叉注意力。cross_attn,跳到CrossAttention。
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None):
super(CrossAttention, self).__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.kv1 = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.kv2 = nn.Linear(dim, dim * 2, bias=qkv_bias)
def forward(self, x1, x2):
B, N, C = x1.shape
#(B,N,C)-->(B,N,8,C//8)-->(B,8,N,C//8)
q1 = x1.reshape(B, -1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3).contiguous()
q2 = x2.reshape(B, -1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3).contiguous()
#(B,N,C)-->(B,N,2C)-->(B,N,2,8,C//8)-->(2,B,8,N,C//8)={(B,8,N,C//8),(B,8,N,C//8)}
k1, v1 = self.kv1(x1).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4).contiguous()
k2, v2 = self.kv2(x2).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4).contiguous()
#((B,8,N,C//8))-->(B,8,C//8,N)@(B,8,N,C//8)=(B,8,C//8,C//8)
ctx1 = (k1.transpose(-2, -1) @ v1) * self.scale
ctx1 = ctx1.softmax(dim=-2)
#(B,8,N,C//8)-->(B,8,C//8,N)@(B,8,N,C//8)=(B,8,C//8,C//8)
ctx2 = (k2.transpose(-2, -1) @ v2) * self.scale
ctx2 = ctx2.softmax(dim=-2)
#(B,8,N,C//8)@(B,8,C//8,C//8)=(B,8,N,C//8)-->(B,N,C)
x1 = (q1 @ ctx2).permute(0, 2, 1, 3).reshape(B, N, C).contiguous()
x2 = (q2 @ ctx1).permute(0, 2, 1, 3).reshape(B, N, C).contiguous()
return x1, x2
在这里进行注意力计算,维度变换已经标出,主要是Q@(K转置乘以 V),结果大小仍为(B,N,C)。
回到crosspath函数中,生成的v1与y1进行concat,v2与y2进行concat,维度变为(B,N,2C),结果在进行一个线性投射,维度变为(B,N,C)。
回到FeatureFusionModule中,生成的两个结果进行concat,通过channel_emb。
class ChannelEmbed(nn.Module):
def __init__(self, in_channels, out_channels, reduction=1, norm_layer=nn.BatchNorm2d):
super(ChannelEmbed, self).__init__()
self.out_channels = out_channels
self.residual = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.channel_embed = nn.Sequential(
nn.Conv2d(in_channels, out_channels//reduction, kernel_size=1, bias=True),
nn.Conv2d(out_channels//reduction, out_channels//reduction, kernel_size=3, stride=1, padding=1, bias=True, groups=out_channels//reduction),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels//reduction, out_channels, kernel_size=1, bias=True),
norm_layer(out_channels)
)
self.norm = norm_layer(out_channels)
def forward(self, x, H, W):
B, N, _C = x.shape #(B,N,2C)
x = x.permute(0, 2, 1).reshape(B, _C, H, W).contiguous() #(B,N,2C)-->(B,2C,N)-->(B,2C,H,W)
residual = self.residual(x) #(B,2C,H,W)-->(B,C,H,W)
x = self.channel_embed(x) #(B,2C,H,W)-->(B,C,H,W)
out = self.norm(residual + x)
return out
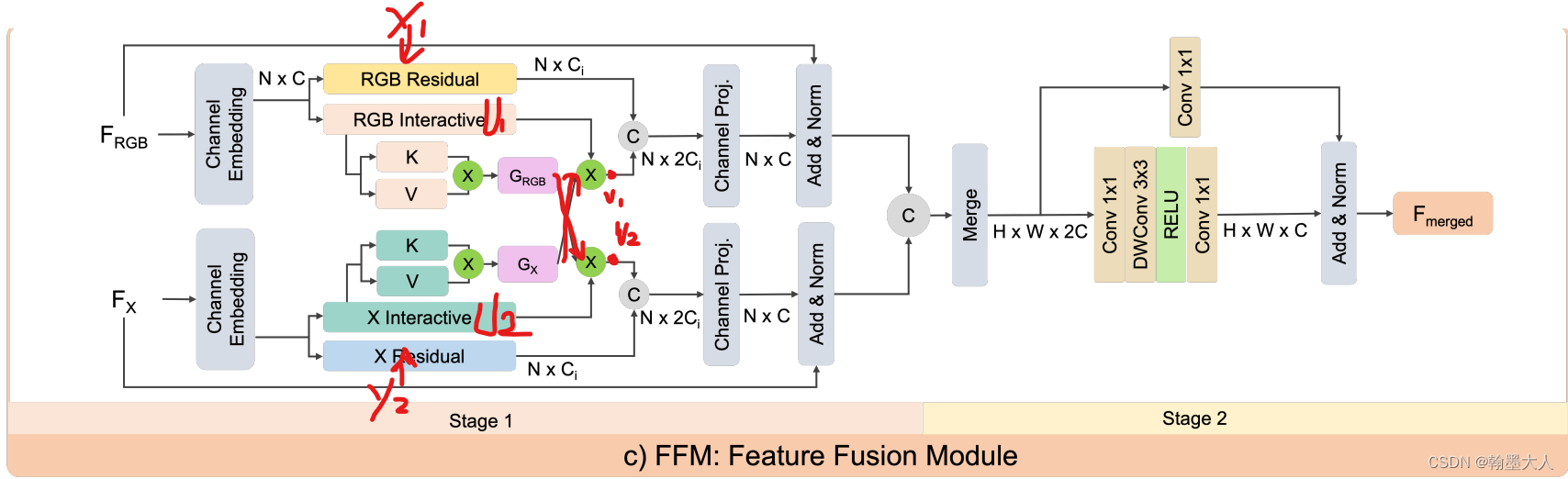
经过1x1卷积做为跳跃连接,同时经过channel_embed,结果进行相加得到最终输出。即为FeatureFusionModule最终输出。
------------------------------------------------------------------------CMX代码已完结-------------------------------------------------------------------
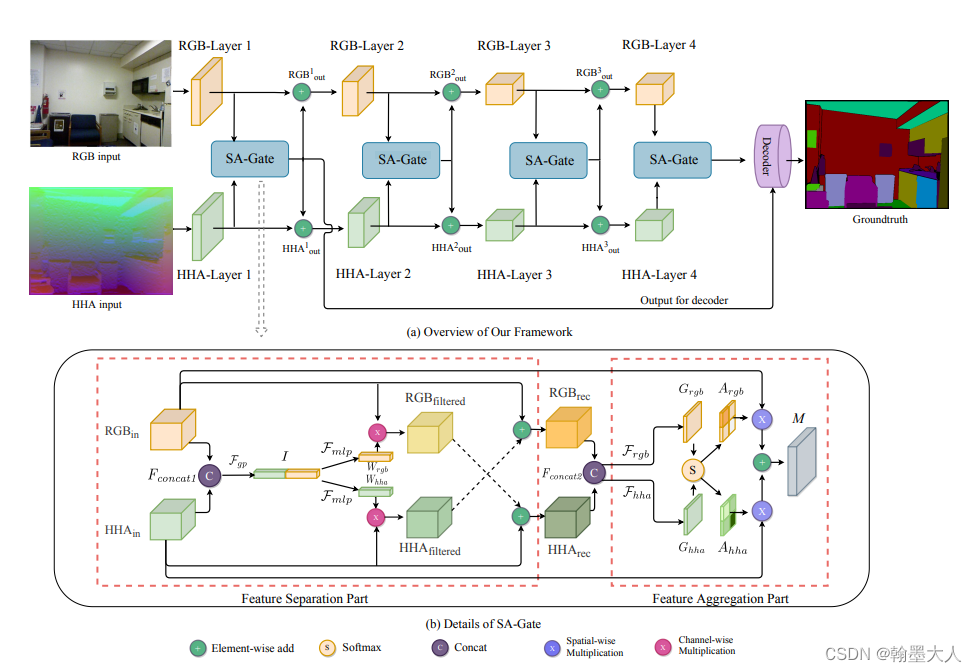
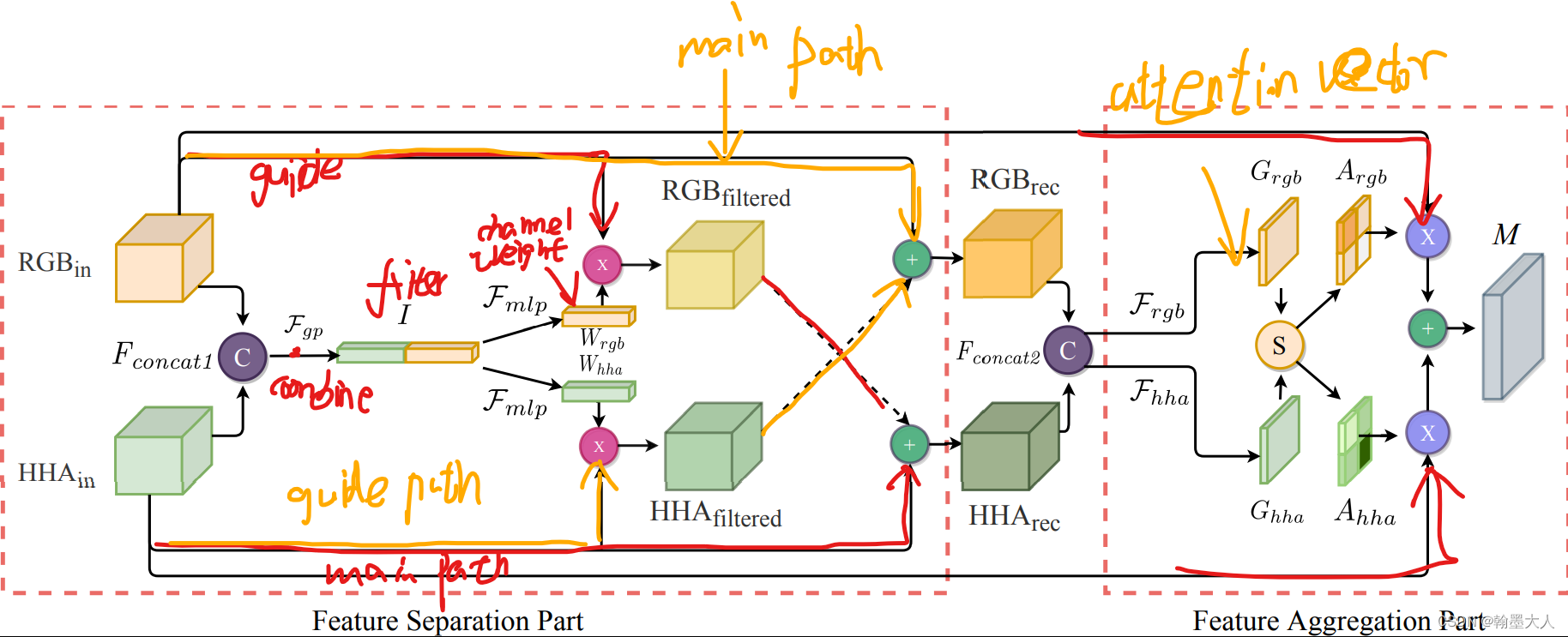
同理我们看一下SA-Gate模块的代码编写:
class SAGate(nn.Module):
def __init__(self, in_planes, out_planes, reduction=16, bn_momentum=0.0003):
self.init__ = super(SAGate, self).__init__()
self.in_planes = in_planes
self.bn_momentum = bn_momentum
self.fsp_rgb = FSP(in_planes, out_planes, reduction)
self.fsp_hha = FSP(in_planes, out_planes, reduction)
self.gate_rgb = nn.Conv2d(in_planes*2, 1, kernel_size=1, bias=True)
self.gate_hha = nn.Conv2d(in_planes*2, 1, kernel_size=1, bias=True)
self.relu1 = nn.ReLU()
self.relu2 = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
rgb, hha = x
b, c, h, w = rgb.size()
rec_rgb = self.fsp_rgb(hha, rgb)
rec_hha = self.fsp_hha(rgb, hha)
cat_fea = torch.cat([rec_rgb, rec_hha], dim=1)
attention_vector_l = self.gate_rgb(cat_fea)
attention_vector_r = self.gate_hha(cat_fea)
attention_vector = torch.cat([attention_vector_l, attention_vector_r], dim=1)
attention_vector = self.softmax(attention_vector)
attention_vector_l, attention_vector_r = attention_vector[:, 0:1, :, :], attention_vector[:, 1:2, :, :]
merge_feature = rgb*attention_vector_l + hha*attention_vector_r
rgb_out = (rgb + merge_feature) / 2
hha_out = (hha + merge_feature) / 2
rgb_out = self.relu1(rgb_out)
hha_out = self.relu2(hha_out)
return [rgb_out, hha_out], merge_feature
对于两个输入,rgb和hha,首先经过FSP函数,
class FSP(nn.Module):
def __init__(self, in_planes, out_planes, reduction=16):
super(FSP, self).__init__()
self.filter = FilterLayer(2*in_planes, out_planes, reduction)
def forward(self, guidePath, mainPath):
combined = torch.cat((guidePath, mainPath), dim=1)
channel_weight = self.filter(combined)
out = mainPath + channel_weight * guidePath
return out
在rec_rgb = self.fsp_rgb(hha, rgb)中,跳到FSP,hha是guidepath,rgb是mainpath,将两个输入拼接起来,经过filter函数,
class FilterLayer(nn.Module):
def __init__(self, in_planes, out_planes, reduction=16):
super(FilterLayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_planes, out_planes // reduction),
nn.ReLU(inplace=True),
nn.Linear(out_planes // reduction, out_planes),
nn.Sigmoid()
)
self.out_planes = out_planes
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, self.out_planes, 1, 1)
return y
首先进行一个平均池化,并view到b,c大小,然后经过一个线性层,view到(b,c,1,1)大小,同理ec_rgb也是如此,最终生成了两个权重,将通道权重乘以guidepath,这里对hha和rgb都进行通道注意力,并与主path进行相加。FSP函数结束后,回到主函数。
我们将经过矫正过的hha和rgb进行拼接。然后就进入了特征聚合模块。经过两个输出通道为1的1x1卷积,获得两个注意力向量,再拼接起来,经过softmax获得相似度矩阵,经过两个切片获得Argb和Ahha,与原始的输出相乘再相加。最后再与原始的输入逐像素相加求平均。















 7584
7584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









