









论文笔记 第一篇
Text Classification Using Label Names Only: A Language Model Self-Training Approach
1. 论文介绍
| 介绍 | |
|---|---|
| 论文录取 | EMNLP |
| 发布单位 | 伊利诺伊大学香槟分校韩家炜老师课题组 |
| 论文链接 | 2010.07245.pdf |
| 论文源码 | github地址 |
2. 摘要及背景介绍
主流的分本分类方法是基于预训练+微调的模式,而文本分类作为下游任务,需要标记数据进行辅助训练,也即是训练集数据,但是训练集的数据获取费时费力。后来的一部分研究转向于以基于描述要类别的一小组词进行分类,不需要训练数据,而本文中提出的方法在未标记数据上只使用每个类的标签名训练分类模型的潜力。
2.1半监督学习以及弱监督学习
半监督方法的成功源于对丰富的未标记数据的使用:未标记的文档提供了自然的正则化,以约束模型预测对输入的微小变化是不变的,从而提高了模型的泛化能力。尽管减轻了注释的负担,但半监督方法仍然需要领域专家的手工努力,这可能很难或昂贵地获得,尤其是当类的数量很大时。
弱监督学习:通过少量的数据来进行工作,效果相当。人类专家只需要理解每个类的标记名称(即单个或几个代表性单词)就可以对文档进行分类。(我们可以使用先验知识来理解语义),而文中研究了弱监督文本分类问题,其中只提供每个类的标签名,以训练纯无标签数据的分类器。。我们提出了一种语言模型自训练方法,其中预先训练的神经语言模型(LM),既作为范畴理解的通用知识源,又作为分类的特征表示学习模型,LM从未标注的数据中创建上下文化的词级类别监督来训练自己,然后通过一个自训练目标推广到文档级分类。
2.2 该工作的主要贡献:
(1)提出了一个基于预先训练的神经网络LM的弱监督文本分类模型LotClass。 LotClass不需要任何带标签的文档,只需要每个类的标签名。
(2)我们提出了一种寻找类别指示词的方法和一个上下文化的词级类别预测任务,该任务训练LM使用上下文来预测一个词的隐含类别。 经过训练的LM在对未标注语料进行自我训练的基础上,能够很好地推广到文档级分类。
(3)在四个基准数据集上,LotClass的性能显著优于弱监督模型,并与强半监督模型和有监督模型的性能相当。
3 研究方法
3.1 Category Understanding via Label Name Replacement
使用BERT作为骨架,从每个类的标签名称中学习类别词汇,类似于最近研究中主题挖掘的思想。(批注:感觉就是找近义词,内涵词外延词)
(1)通过MLM来预测在大多数上下文中哪些词可以替代标签名称。具体来说,对于语料库中出现的每一个标签名称,我们为其提供上下文嵌入向量h由BERT编码到MLM。它将在整个词汇V上输出一个概率分布,表明每个单词w出现在这个位置的可能性:
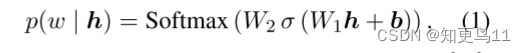
选取top50作为定义语料库中标签名称该句的有效替换(每一个mask,选取预测的50个词,再选取前100个词作为该类的形容词)。最后,统计出现的词汇频率,使用排名前100的单词来形成每个类的类别词汇,这些单词可以在语料库中替换标签名称的次数,丢弃带有NLTK (Bird等人,2009) 的停止词和出现在多个类别中的单词。(如图二所示)

3.2 Masked Category Prediction(MCP)
3.1中提到的方法,简单方便并且易于理解,但是却又一下的缺点:
(1)词义是上下文的; 并非类别关键字的每一次出现都表明类别。(没有结合上下文,光借助频率判断类别是不行的)
(2)类别词汇的覆盖范围有限; 某些特定上下文下的术语与类别关键字具有相似的含义,但未包含在类别词汇中。
作者为了解决以上问题,提出了一个新的训练任务MCP,其中,预先训练的LM创建上下文化的单词级类别监督,用于训练自身,以预测具有掩蔽词的单词的隐含类别。
首先,在3.1的基础上,建立类别词cw的类别词汇(100个有效替换的词汇),在进行MLM操作,用MLM预测单词w的前50个单词视为原始单词的有效替换,如果w的有效替换中有超过20个与cw类的类别词汇中相同,我们将w视为cw类的 “类别指示词”。通过如上检查语料库中的每个单词,我们将获得一组类别指示词及其类别标签,作为单词级别的监督。通过如上检查语料库中的每个单词,我们将获得一组类别指示词及其类别标签,作为单词级别的监督。
对于每个类别指示词w,我们用 [mask] 标记将其屏蔽,并训练模型,以通过在w的上下文嵌入h之上的分类器 (线性层) 通过交叉丢失来预测w的指示类别cw:
![[Alt]对应的损失函数](https://img-blog.csdnimg.cn/365cd9ca88a141a0a6f4fdb53ffa2fb9.png#pic_center)
这样就有效的融合了上下文的消息进行推断类别,而不是简单的单词频率。
3.3 self-training
仍然有两个问题:
(1)有部分文档没有被标记(没有检测到关键词,类别指示词,就是小于20的);
(2) 分类器已经在单词之上进行了训练,以预测它们的类别,并掩盖了它们,但尚未应用于 [CLS] 令牌,其中允许模型查看整个序列以预测其类别。自我训练 (ST) 的思想是迭代地使用模型的当前预测P来计算目标分布Q。
自我训练 (ST) 的思想是迭代地使用模型的当前预测P来计算目标分布Q,该分布Q指导模型的精化。ST目标的一般形式可以用KL散度损失表示:
![[Alt]损失函数](https://img-blog.csdnimg.cn/b6c8816bb0c5457891038db8a3f9b9f7.png#pic_center)
其中N是实例数。
目标分布Q有两大选择:
Hard labeling:将阈值 τ 上的高置信度预测转换为单热标签,概率大于阈值,就设为独热标签
Soft labeling:通过增强高置信度预测来导出Q,同时通过平方和归一化当前预测来降级低置信度预测。
![[Alt]在这里插入图片描述](https://img-blog.csdnimg.cn/3dc9d8a4be2442979b43692aaa1e656a.png#pic_center)
模型预测是通过应用MCP训练的分类器进行到每个文档的 [CLS] 令牌,
在实践中,作者发现软标签策略始终提供比硬标签更好,更稳定的结果,这可能是因为硬标签将高自信的预测直接视为基本事实标签,并且更容易发生错误传播。软标记的另一个优点是为每个实例计算目标分布,并且不需要预设置信度阈值。
我们通过公式更新目标分布Q。(5) 每50批,并通过公式对模型进行训练。(4)。总体算法如算法1所示。

4 实验结果
四个数据集:AG News , DBPedia , IMDB , Amazon

5.讨论
5.1 本文作者的思考:
(1)弱监督分类的潜力尚未得到充分挖掘
为了我们方法的简单性和清晰度,(1) 我们只使用BERT-base-uncased模型,而不是更高级和最新的LMs; (2) 我们每个类最多使用3个单词作为标签名称;(3) 我们避免使用其他依赖项,例如后翻译系统进行增强。我们相信,随着模型的升级,输入的丰富和数据增强技术的使用,性能将变得更好。
(2)弱监督在其他NLP任务中的适用性。许多其他NLP问题可以被表述为分类任务,例如命名识别和基于方面的情感分析。有时,标签名称可能过于通用而无法解释 。为了将本文介绍的类似方法应用于这些场景,可以考虑使用更具体的示例术语实例化标签名称。
(3)弱监督分类的局限性。在一些困难的情况下,标签名称不足以教导模型进行正确分类,
一些评论文本隐含地表达了超出单词级理解的情感极性,因此,通过主动学习来改善弱监督分类将很有趣,其中允许模型就困难的情况咨询用户
e.g:“I find it sad that just because Edward Norton did not want to be in the film or
have anything to do with it, people automatically think the movie sucks without even watching it or giving it a chance.”
(4)与半监督分类的协作。人们可以很容易地将弱监督方法与半监督方法集成在不同的场景中 :(1) 当没有训练文档时,弱监督方法的高置信度预测可以用作初始化半监督方法的基本事实标签。(2) 当训练文档和标签名称都可用时,可以设计一个联合目标来训练模型,其中既有word级任务 (如MCP),也有文档级任务 (如扩充、自我训练)
5.2 本人思考
感觉self-training和zero-shot TC的思路还是有异曲同工之妙的,包括之前将两者相结合的那一篇文章,效果也是有突破的;会不会其他的弱监督学习方法也能进行有效的结合,然后比之前的那个效果好?(感觉这两篇文章都在设计伪标签(或者子标签?),来丰富语义。
文中作者的方法听着很吓人,但是思路确实非常简单明了的,主要的创新点在于self-training的引入,还没有看到前人将其用于NLP,也算开拓了思维,对于细分领域的研究也许会有用处,只求别被大模型碾成个渣渣。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









