










Beyond Prompting: Making Pre-trained Language ModelsBetter Zero-shot Learners by Clustering Representations
| 介绍 | |
|---|---|
| 论文录取 | EMNLP2022 |
| 发布单位 | ETH Zurich, Peking University |
| 论文链接 | 2210.16637.pdf |
| 论文源码 | github地址 |
1. 摘要及背景介绍
1.1摘要
现在的zero-shot TC的研究要么是有繁杂的人体工程或复杂的self-training过程,阻碍了它们在新情况下的应用。 在这一工作中,我们证明了在PLMS嵌入空间中对文本进行聚类可以简单地改进零镜头文本分类。【聚类的方法】在使用类名初始化聚类位置和形状后,我们用贝叶斯-高斯混合模型对未标记文本进行拟合。
尽管简单,但该方法在主题和情感分类数据集上都取得了优越或可比的性能,并且在非平衡数据集上的性能显著优于以往的工作。 我们通过对14个主题、文本长度和类数更加多样化的数据集进行评估,进一步探索了我们的聚类方法的适用性。 我们的方法与基于提示的零镜头学习获得了平均20%的绝对改进。
最后,我们比较了不同的PLM嵌入空间,发现即使PLM没有显式地预先训练生成有意义的句子嵌入,文本也能很好地按主题聚类。 这一工作表明PLM嵌入可以在不对特定任务进行微调的情况下对文本进行分类,从而为分析和利用文本知识以及零镜头学习能力提供了一种新的方法。
1.2 背景介绍
现有的主流方法:
还有一种:Clustering-based methods:
Clustering-based methods: 早期基于聚类的方法处理离散文本表示,如TF-IDF或Bagof-Words。 最近,Ulr探索了基于聚类的文本分类和上下文化句子嵌入。 然而ULR需要在额外的任务相关数据上对PLM进行微调,并使用启发式正则化。 基于K-均值的方法也在聚类形状上放置了一个很强的球形假设。 在这项工作中,我们证明了与任务相关的预训练和启发式设计都是不必要的。 PLMS的原始嵌入空间足以给出更灵活的聚类算法的强结果。 然而,利用无监督学习来进一步提高文本表示的聚类质量是可能的,就像Gupta等人所说的那样。 我们把这个作为未来的方向。
Keyword-driven methods
Prompt-based methods: 现有的许多关于提示的工作都集中在文本分类上,其中使用模板将分类任务转换为完形填空任务,并由动词化器将预测的单词映射为分类标签
作者的工作:Simptc共享利用自然语言模板和类名的思想。 然而,SIMPTC不是重新制定分类任务,而是使用自然语言模板和类名来构造类相关文本,这些文本用于计算初始聚类位置和形状,以便后续的概率聚类步骤。
1.3 作者的贡献
这篇工作follow文章:2020ACL
这表明PLMS已经具备了区分不同意义文本的知识。作者提出了一个简单的概率文本分类框架SIMPTC,它建立在最先进的句子嵌入SimCSE的基础上。给定一个未标记的数据集和相应的类名,SimPTC用高斯分布对每个类中的文本建模,并用贝叶斯高斯混合模型 (BGMM) 拟合文本嵌入。
为了初始化集群,我们首先使用类名来生成类相关的锚语句。 然后根据文本与嵌入空间中类锚点的相似度确定文本的初始聚类分配。
优点:
1)在不需要PLM自我训练的情况下,SIMPTC在主题和情感分类数据集上都取得了优于或类似的性能;
2)与基于提示的方法不同,SIMPTC在没有人工工程或外部知识的情况下运行良好;
3)SIMPTC在数据集不平衡的情况下优于以前的方法。 最后,一旦我们获得了句子嵌入,我们不再使用PLM,SIMPTC将嵌入聚类在一个固定的维空间中。 因此,可以很容易地将SIMPTC应用于新的大型数据集。
2.研究方法
SimPTC
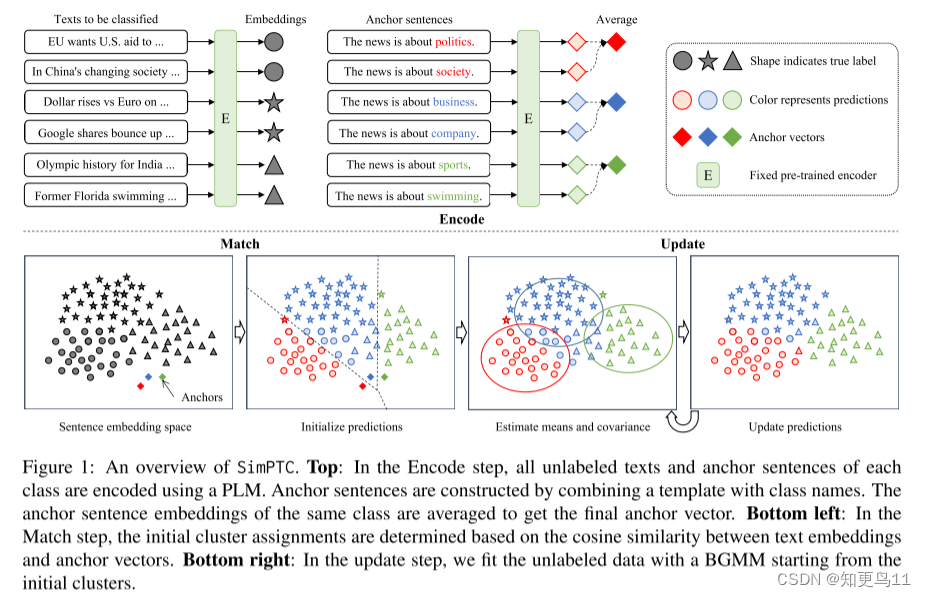
如图1所示,Simptc将零镜头文本分类任务形式化为聚类问题,并通过三个步骤解决它:Encoder、Match和Update。 我们首先在嵌入空间中用一个高斯聚类对每个类建模。 接下来,Encode步骤和Match步骤使用类名提供对集群均值和协方差的粗初始化。 最后,从初始化开始,用BGMM对未标记的数据进行拟合。
2.1 Encode
SIMPTC的第一步是将基于外部知识库扩展的类名填充到自然语言模板中,构造class anchor语句。然后,我们将未标记文本和类锚语句都编码到PLM嵌入空间。(上图顶部)
Expanding class names:
为了使class anchor定句更具有类指示性,更少依赖于类名的确切文本形式,我们使用外部知识库对类名进行扩展。[具体来说,我们使用ConceptNet NumberBatch,这是一组来自ConceptNet的半结构化的常识性知识的词嵌入,结合了Word2VEC和Glove。]
对于给定一个类名
s
i
s_{i}
si的m个相关词,我们简单地选择嵌入的最大内积为top-M个的词,用SI嵌入
S
i
=
top
−
M
x
∈
V
(
x
⊤
s
i
)
S_{i}=\underset{x \in \mathcal{V}}{\operatorname{top}-M}\left(\mathbf{x}^{\top} \mathbf{s}_{i}\right)
Si=x∈Vtop−M(x⊤si)
其中
s
i
s_{i}
si是
S
i
S_{i}
Si的扩展类名集,
V
\mathcal{V}
V是词汇,粗体字体表示单词嵌入。词出现在多个
S
i
S_{i}
Si的删除。如果m > 1类名称有一个类,每个名字我们提取M / m。
Constructing anchor sentences:
我们将使用自然语言模板的概念从prompt-based方法构建锚的句子,一个template是一块文本包含一个或多个特殊令牌填写,“The text is about [mask].”.
用
s
i
∈
S
i
s_{i} \in S_{i}
si∈Si替换[mask],我们得到了一组与class有关的句子。与prompt-based方法不同,我们允许类名与多个令牌。anchor嵌入同一个类的平均给最终锚向量。
2.2 Match
{
x
i
,
x
2
,
…
,
x
N
}
\left\{\mathbf{x}_{i}, \mathbf{x}_{2}, \ldots, \mathbf{x}_{N}\right\}
{xi,x2,…,xN}是一组大小N的无标记的文本嵌入,
{
a
i
,
a
2
,
…
,
a
N
}
\left\{\mathbf{a}_{i}, \mathbf{a}_{2}, \ldots, \mathbf{a}_{N}\right\}
{ai,a2,…,aN}是K类的平均锚向量。pseudo-label

{yi}用于计算初始聚类均值和协方差。 我们称之为伪标签生成过程encode&match(E&M).
图2说明了执行PCA后的编码锚向量 a i \mathbf{a}_{i} ai和示例向量 x i \mathbf{x}_{i} xi。 锚向量 a i \mathbf{a}_{i} ai确实反映了集群的相对位置。 为了提供更多的见解,我们在AG的News数据集上进行了试点实验。 我们在表1中展示了E&M和Vanilla Prompting的零镜头性能,Schick and Schütze中使用的基于Vanilla提示的零镜头文本分类方法。 为了公平的比较,我们直接使用原始类名来构造E&M的锚句。 E&M提供了一个竞争性的初始化,并且在不同的自然语言模板选择中更加稳定。
2.3Updata
***Model classes with Gaussian clusters:***为了捕捉文本簇的位置和形状特征,我们在嵌入空间中用高斯模型对同一类文本进行建模,并定义了高斯混合模型(GMM)。 则数据集的可能性由

其中θ=(π,μ,σ)表示模型参数; π={π1,…,πk},μ={μ1,…,μk}和σ={σ1,…,σk}分别是每个分量的先验值、均值和协方差。 当数据稀疏时,我们可以进一步要求所有组件共享相同的协方差矩阵,以增加额外的正则化,或者我们有额外的先验知识,即聚类具有相似的形状。
Variational update: 当数据有限或初始化不良时,高维空间中的聚类可能具有挑战性。 一个简单的解决方案是注入先验知识,例如在几种基于提示的方法中假设类具有统一的先验,然而,当先验不正确时,显式去偏模型可能是有害的。
为了平衡先验知识的注入和数据的拟合,我们转向贝叶斯方法,并在模型参数上引入先验分布。 我们选择 Dirichlet 分布作为混合权重π的优先级,以支持平衡权重:

其中C(α0)是一个归一化常数,α0可以解释为与每一类相关的先验观测数。 我们简单地选择α0=N/K。 对于均值和协方差,我们选择了一个非信息性的高斯-维夏先验(详见附录C)。 然后我们用标准变分优化对模型进行了更新。 由于保证BGMM收敛,当模型预测停止改变或达到最大迭代次数时,我们停止更新。
注意,一般来说,我们可以用任何初始化方法代替encode&match,用任何聚类算法代替贝叶斯GMM,算法总结如下:

3.Experiments
3.1中比较了SIMPTC与最先进的zeroshot TC方法,
3.2中研究了SIMPTC各组成部分的作用
3.3中探讨了SIMPTC在广泛任务中的应用和局限性。
由于时间原因,后续在把消融实验3.2和对比实验3.3补上。
3.1 Comparison with State-of-the-art
关于实验的具体设置,后续进行补充。
作者进行实验主要是评估三个信息:
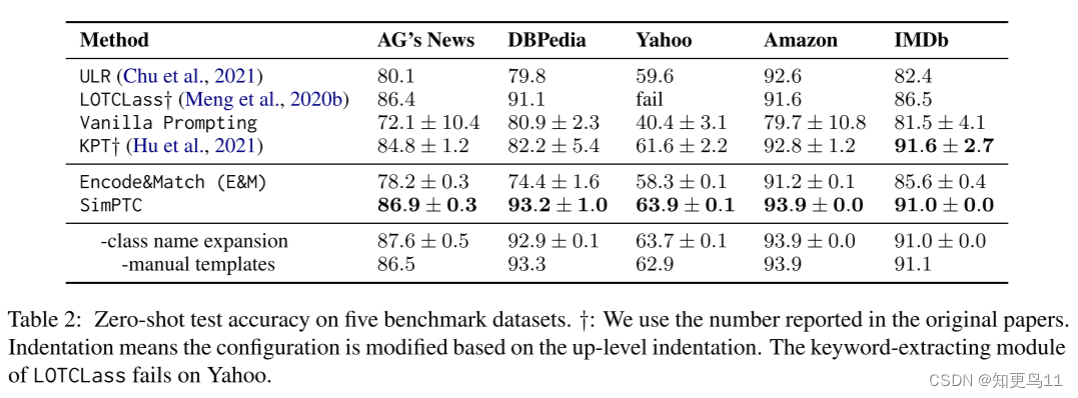
C1:SimPTC在主题和情感数据集上都实现了优越或可比的性能。 下图实验结果一为准确度。我们用标准差报告使用多个自然语言模板的方法的平均得分。 在不对PLM进行微调的情况下,SIMPTC在所有数据集上都表现出优越或可比的性能。
C2:SIMPTC提供了跨不同模板的稳定预测。
与Vanilla Prompting相比,E&M在不同的自然语言模板上以更低的标准偏差在所有数据集上提供了更好或可比的性能(下图实验结果一)。 即使我们将E&M与外部知识增强的基于提示的方法(KPT)进行比较,这一观察也是成立的。 SIMPTC进一步降低了标准差,提高了性能。
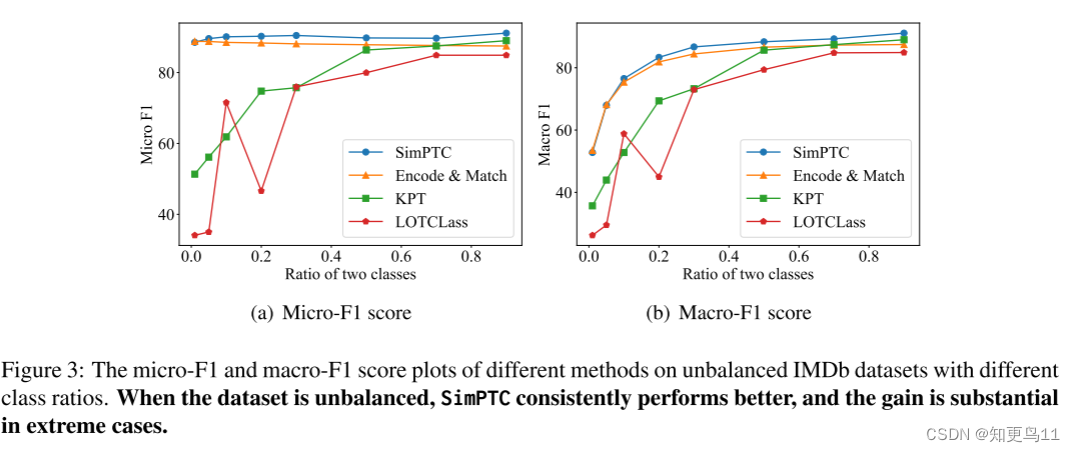
C3:当数据集中的类不平衡时,simptc的性能始终优于以前的工作。
4.讨论及思考
本文指出了SIMPTC的三个局限性:
(1)由于聚类和句子嵌入的性质,SIMPTC在多类任务和抽象类名(如主观类名和客观类名)中仍然存在困难;
(2)目前,将SIMPTC应用于NLI等其他NLP任务并不简单。
(3)由于计算资源的限制,我们的分析仅限于参数高达30亿的PLMS。 如果我们的方法能够推广到最大的模型,例如GPT-3 (175B) 和PaLM(540B), 也许会更加高效
聚类的方法,主要的问题:就是如何将文本映射到对应的空间上去,而且,随着文本的增加,如何减少计算量;都是需要解决的问题。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









