







 本文详细介绍了一种从豆瓣电影网站抓取评论数据的方法,包括分析网页结构、编写爬虫代码、提取评论信息并存储到Excel的过程。文章还分享了解决特定技术难题的经验,如动态加载网页数据和处理复杂的网页元素。
本文详细介绍了一种从豆瓣电影网站抓取评论数据的方法,包括分析网页结构、编写爬虫代码、提取评论信息并存储到Excel的过程。文章还分享了解决特定技术难题的经验,如动态加载网页数据和处理复杂的网页元素。
一、分析网址网页
首先用浏览器进入豆瓣网站,查看几页评论网址间的联系
https://movie.douban.com/subject/26794435/comments?status=P
https://movie.douban.com/subject/26794435/comments?start=20&limit=20&sort=new_score&status=P
https://movie.douban.com/subject/26794435/comments?start=40&limit=20&sort=new_score&status=P
很容易看到只有中间的start=X发生变化,这里第一个网址看着和后面差别较大,但也可以将X=0代入,即
https://movie.douban.com/subject/26794435/comments?start=0&limit=20&sort=new_score&status=P
这样循环找网页就方便了很多
然后查看网页源代码,发现是静态网页,数据都一次加载出来了。
或者打开f12开发者工具,信息不在xhr文件也是静态网页,这就好办啦
二、代码分析
1.get参数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0'
}
cookies={'cookie': 'bid=iDf0tyAI54I; ps=y; ll="118183"; __utmc=30149280; _ga=\
GA1.2.1325106029.1530404146; _gid=GA1.2.1270378106.1530405800; ue="965454764@qq.com";\
dbcl2="180531938:E/xiLFShgbg"; ck=UDKl; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C153\
0409505%2C%22https%3A%2F%2Faccounts.douban.com%2Flogin%3Falias%3D965454764%2540qq.com\
%26redir%3Dhttps%253A%252F%252Fwww.douban.com%26source%3DNone%26error%3D1011%22%5D;\
_pk_id.100001.8cb4=cdbf383efde098e6.1530404145.2.1530409505.1530405796.; _pk_ses.100001.\
8cb4=*; push_noty_num=0; push_doumail_num=0; __utma=30149280.1325106029.1530404146.153040\
4146.1530409505.2; __utmz=30149280.1530409505.2.2.utmcsr=accounts.douban.com|utmccn=(referral)\
|utmcmd=referral|utmcct=/login; __utmt=1; __utmv=30149280.18053; __utmb=30149280.2.10.1530409505;\
__yadk_uid=5eZwp3s8j7joGLL911UWJkWQpVQg6IX4'}
IPs = [
{'HTTPS': 'https://115.237.16.200:8118'},
{'HTTPS': 'https://42.49.119.10:8118'},
{'HTTPS': 'http://60.174.74.40:8118'}
]
headers有很多参数,这里只说明是浏览器即可
cookies是很多网站辨明身份的小段文本,打开浏览器,f12打开工具—>
f5刷新—>点击第一条信息,查看—>点击headers,查看头部响应信息->
复制cookie即可,这个cookies是在网上找的

ip池是我在网上随便找的,后面会随机使用一个ip
2.获取页面
通过random.choice()函数随机选择一个ip
写入文件是为了查看访问的页面源代码是否正确,后面可以注释掉
def download_page(url):
ip=random.choice(IPs)
r=requests.get(url,headers=headers,cookies=cookies,proxies=ip)
with open ('./test.txt','wb+') as f:
f.write(r.content)
return r.text
记事本内容:

3.信息提取
def get_comments(html,page):
soup=bs(html,'html.parser')
coms=soup.find_all('div',class_='comment')
# print(coms)
for com in coms:
#获得赞数
agree=com.find('span',class_='comment-vote').find('span',class_="votes").get_text()
agrees.append(agree)
#名字
name=com.find('span',class_='comment-info').find('a').string
names.append(name)
#得到打分和推荐程度
info=com.find('span',class_='comment-info').find_all('span')
#打分
star=info[1]['class'][0][7:8]
#推荐程度
recommend=info[1]['title']
stars.append(star)
recommends.append(recommend)
#评论
comment=com.find('span',class_="short").string
comments.append(comment)
#每次获取完休息一下
time.sleep(random.randint(1,2))
print('第{}页获取完成'.format(page+1))
storge(names,stars,agrees,comments,recommends)
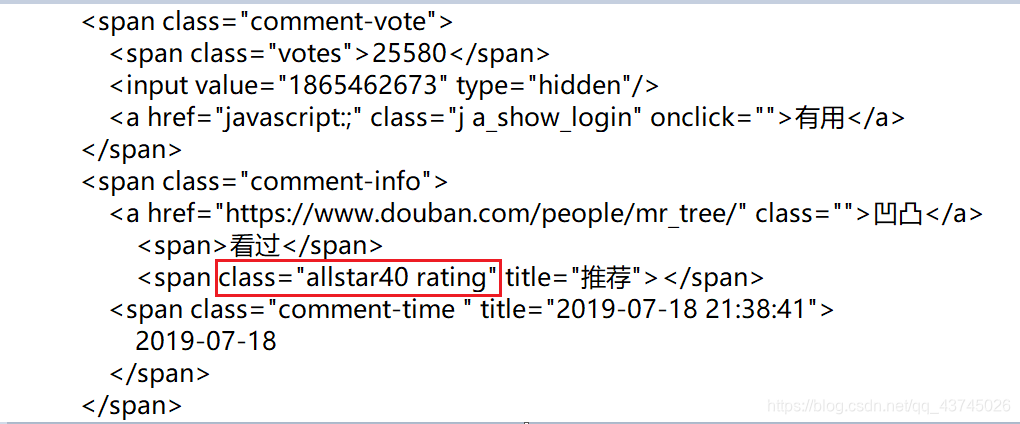
其它信息还好,在获取打分星级时出了问题,可以看到信息在class为comment-info的第二个span里,于是我用了info[1][‘class’][7:8]获取星级,但总是为空
后来发现这个class里有个空格,所以info[1][‘class’]结果为[’‘allstar40’’,’‘rating’’],加个下标0就好啦。这里太坑了
4.存储至excel
def storge(*a):
#建立一个df对象
df=pd.DataFrame()
#赋值
df['名字']=names
df['打分']=stars
df['支持数']=agrees
df['推荐程度']=recommends
df['评论']=comments
#写入excel
df.to_excel('./哪吒评论.xlsx')
5.主函数
def main():
depth=2#爬取深度
for i in range(0,depth):
url='https://movie.douban.com/subject/26794435/comments?start='+str(i*20)+'&limit=20&sort=new_score&status=P'
html=download_page(url)
if html is not None:
print('正在访问第{}页'.format(i+1))
get_comments(html,i)
else:
print('第{}页访问失败'.format(i+1))
三、完整代码
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 11 18:21:08 2020
@author: DZY
"""
import requests
from bs4 import BeautifulSoup as bs
import random
import time
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0'
}
cookies = {'cookie': 'bid=iDf0tyAI54I; ps=y; ll="118183"; __utmc=30149280; _ga=\
GA1.2.1325106029.1530404146; _gid=GA1.2.1270378106.1530405800; ue="965454764@qq.com";\
dbcl2="180531938:E/xiLFShgbg"; ck=UDKl; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C153\
0409505%2C%22https%3A%2F%2Faccounts.douban.com%2Flogin%3Falias%3D965454764%2540qq.com\
%26redir%3Dhttps%253A%252F%252Fwww.douban.com%26source%3DNone%26error%3D1011%22%5D;\
_pk_id.100001.8cb4=cdbf383efde098e6.1530404145.2.1530409505.1530405796.; _pk_ses.100001.\
8cb4=*; push_noty_num=0; push_doumail_num=0; __utma=30149280.1325106029.1530404146.153040\
4146.1530409505.2; __utmz=30149280.1530409505.2.2.utmcsr=accounts.douban.com|utmccn=(referral)\
|utmcmd=referral|utmcct=/login; __utmt=1; __utmv=30149280.18053; __utmb=30149280.2.10.1530409505;\
__yadk_uid=5eZwp3s8j7joGLL911UWJkWQpVQg6IX4
IPs = [
{'HTTPS': 'https://115.237.16.200:8118'},
{'HTTPS': 'https://42.49.119.10:8118'},
{'HTTPS': 'http://60.174.74.40:8118'}
]
def download_page(url):
ip=random.choice(IPs)
r=requests.get(url,headers=headers,cookies=cookies,proxies=ip)
with open ('./test.txt','wb+') as f:
f.write(r.content)
return r.text
#目标:名字,打分,赞数,评语,推荐程度
names=[]
stars=[]
agrees=[]
comments=[]
recommends=[]
def get_comments(html,page):
soup=bs(html,'html.parser')
coms=soup.find_all('div',class_='comment')
# print(coms)
for com in coms:
#获得赞数
agree=com.find('span',class_='comment-vote').find('span',class_="votes").get_text()
agrees.append(agree)
#名字
name=com.find('span',class_='comment-info').find('a').string
names.append(name)
#得到打分和推荐程度
info=com.find('span',class_='comment-info').find_all('span')
#打分
star=info[1]['class'][0][7:8]
#推荐程度
recommend=info[1]['title']
stars.append(star)
recommends.append(recommend)
#评论
comment=com.find('span',class_="short").string
comments.append(comment)
#每次获取完休息一下
time.sleep(random.randint(1,2))
print('第{}页获取完成'.format(page+1))
storge(names,stars,agrees,comments,recommends)
def storge(*a):
#建立一个df对象
df=pd.DataFrame()
#赋值
df['名字']=names
df['打分']=stars
df['支持数']=agrees
df['推荐程度']=recommends
df['评论']=comments
#写入excel
df.to_excel('./哪吒评论.xlsx')
def main():
depth=2#爬取深度
for i in range(0,depth):
url='https://movie.douban.com/subject/26794435/comments?start='+str(i*20)+'&limit=20&sort=new_score&status=P'
html=download_page(url)
if html is not None:
print('正在访问第{}页'.format(i+1))
get_comments(html,i)
else:
print('第{}页访问失败'.format(i+1))
main()
四、执行结果



















 740
740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









