







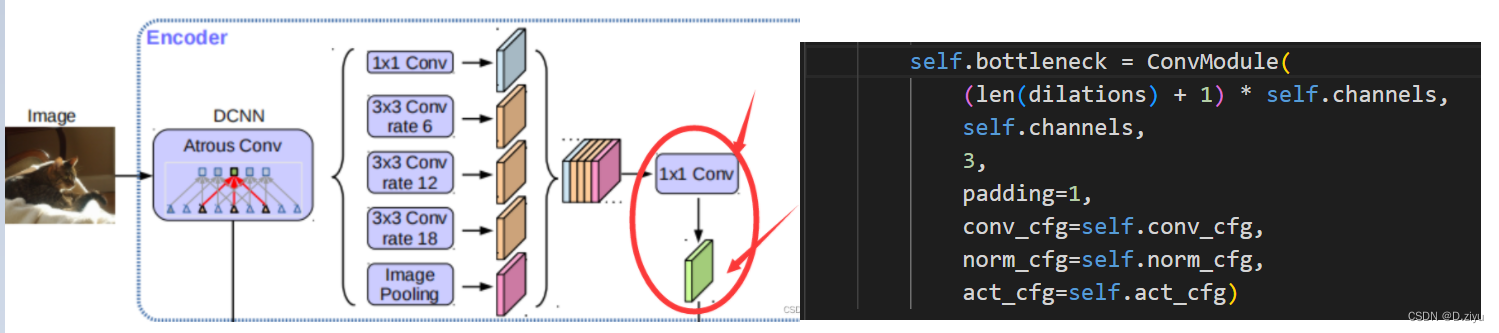
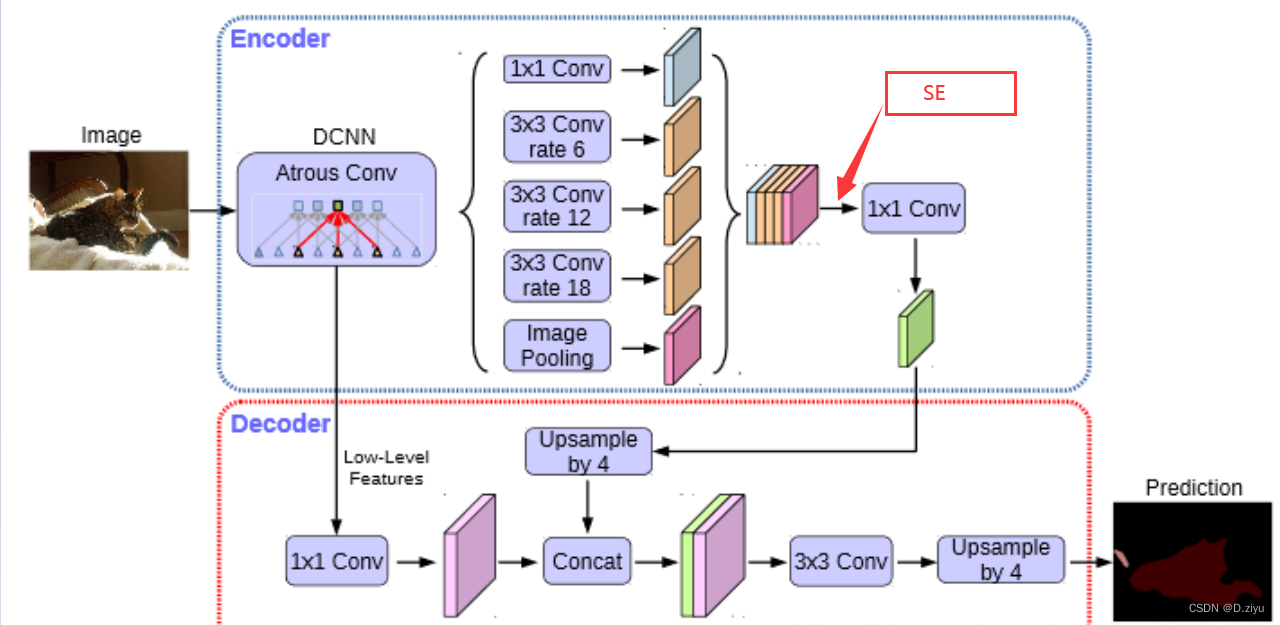
deeplabv3+框架图
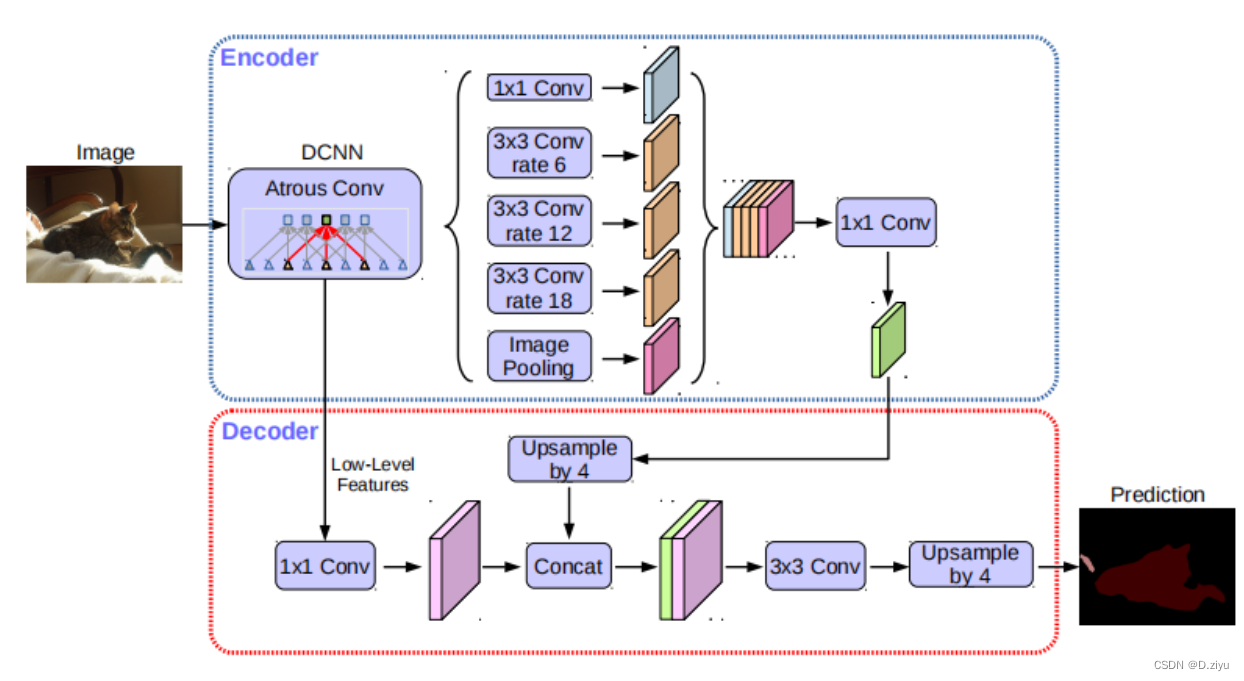
图源自网络,后面会出现多次。本文会指出每个部分对应代码的哪一段。
PS:该框架图只表示大概流程,具体数字在代码中会有变动。
程序入口
一般都是在终端运行python tools/train.py ./configs/你的配置文件 --work-dir 指定的工作目录 执行命令
要调试代码,就要在pycharm里debug它,所以不能用终端的命令。
进入mmsegmentation/tools/train.py
parse_args()是个函数,定义在111行前面。
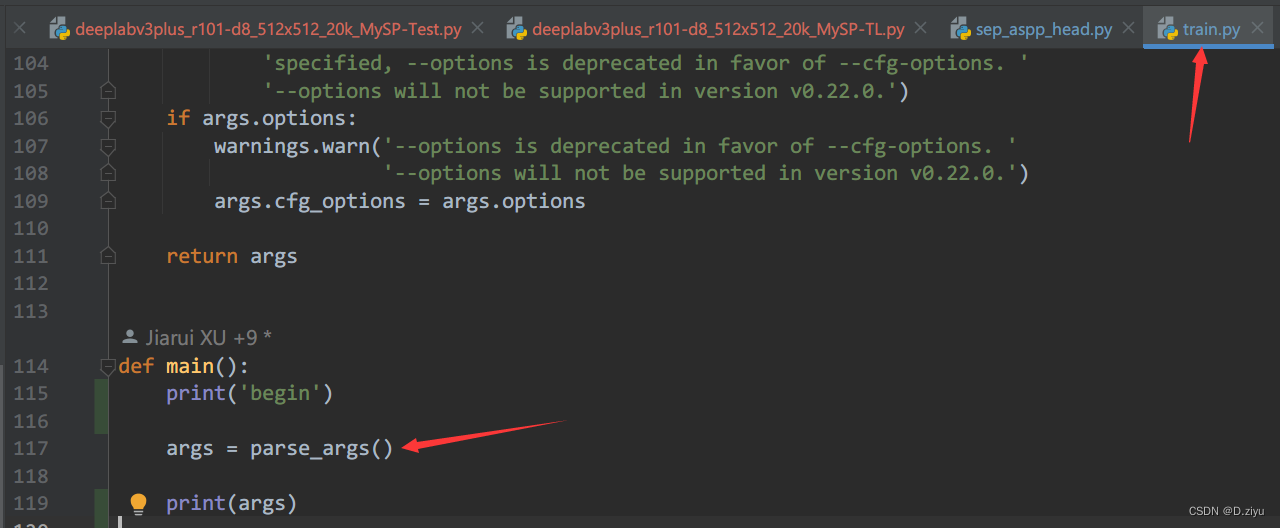
进入函数,发现用的是args = parser.parse_args() 接收终端的命令
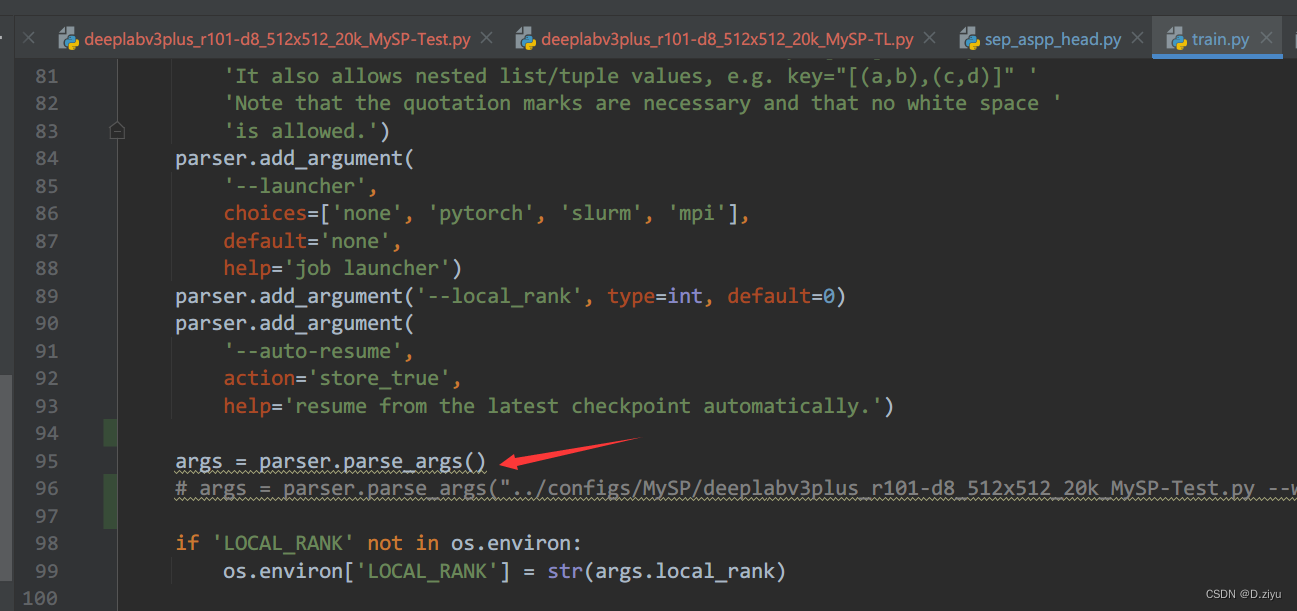
把它注释掉,改成新的命令。
其中 ../configs/MySP/deeplabv3plus_r101-d8_512x512_20k_MySP-Test.py 是配置文件
--work-dir ../work/Test 自建的工作区,是用来试错的输出。

查看该配置文件的详细配置
python tools/print_config.py ./configs/MySP/deeplabv3plus_r101-d8_512x512_20k_MySP-Test.py
发现decode_head是DepthwiseSeparableASPPHead,就去找它
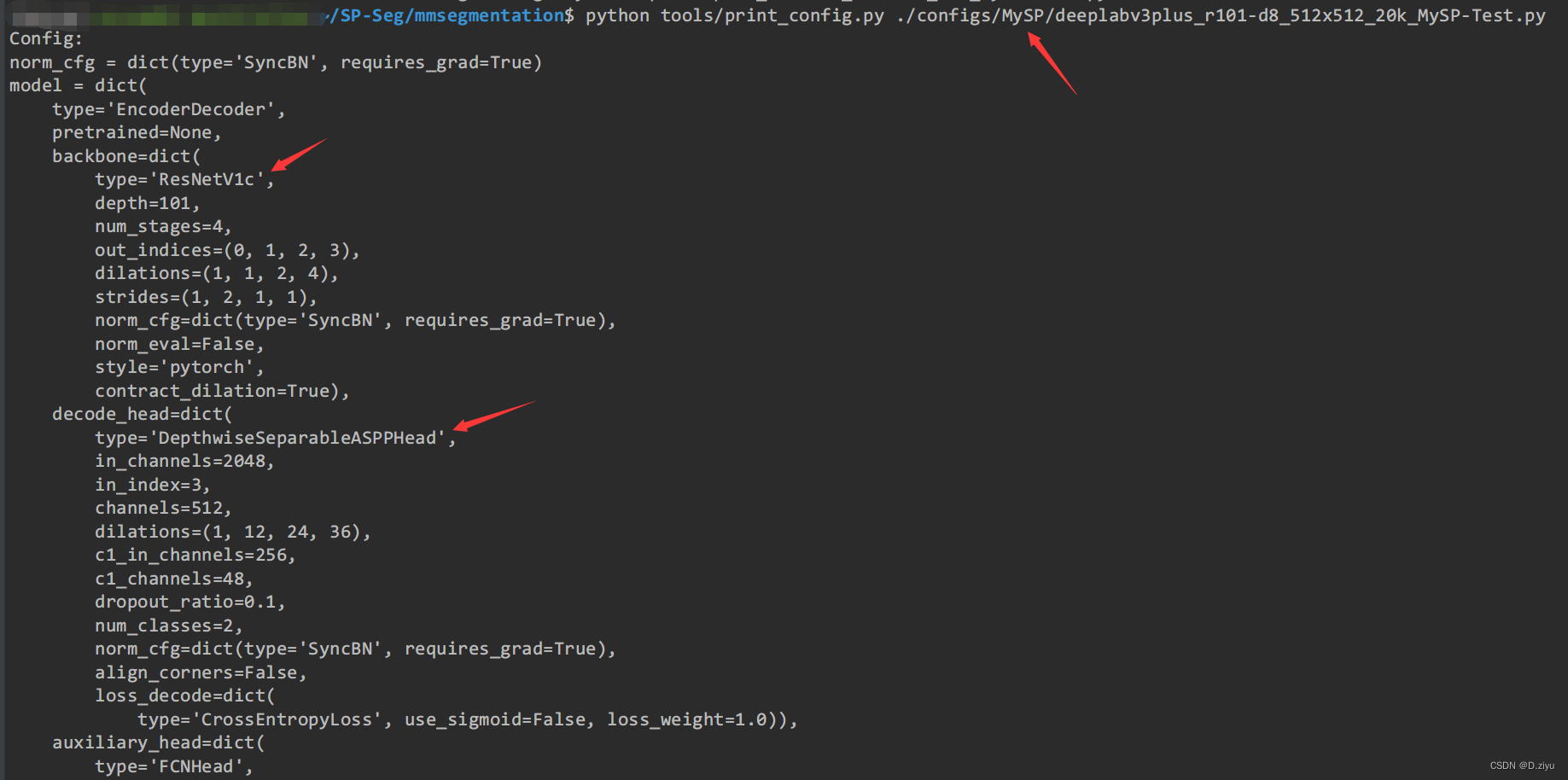
在mmsegmentation/mmseg/models/decode_heads/sep_aspp_head.py 里找到了该类
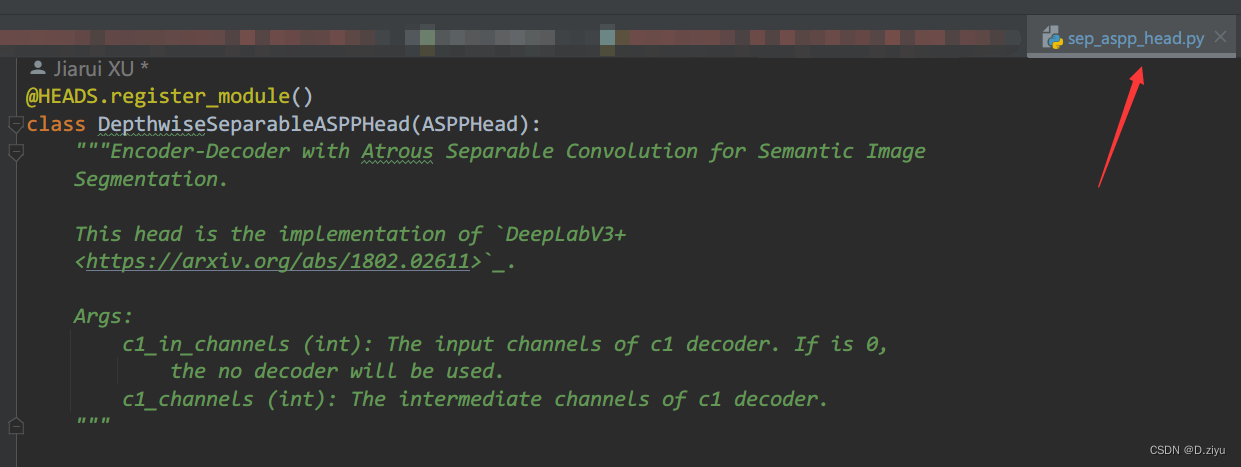
这里就是要改的地方 ,直接看forword函数
调试
先打断点
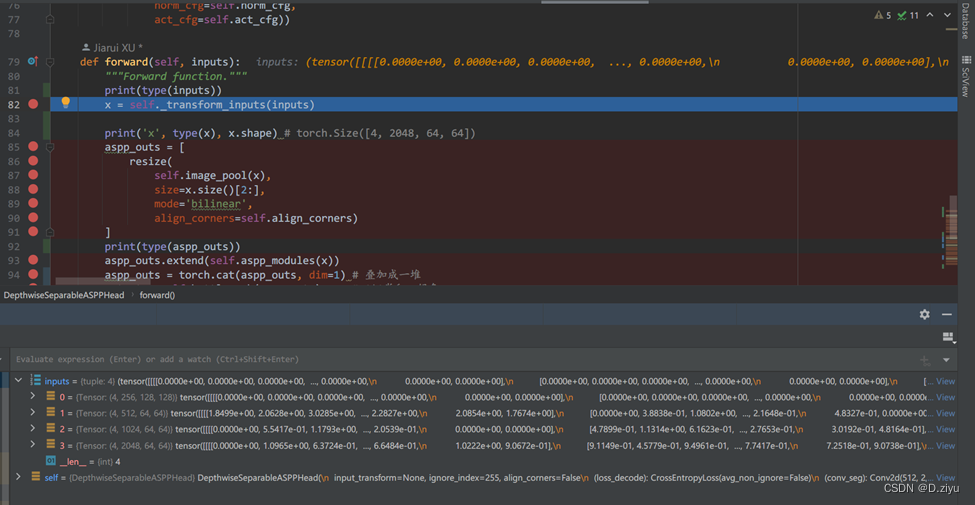
这两个绿虫子都可以点,开始调试。就在train里开始调试就行。
下一步按钮:
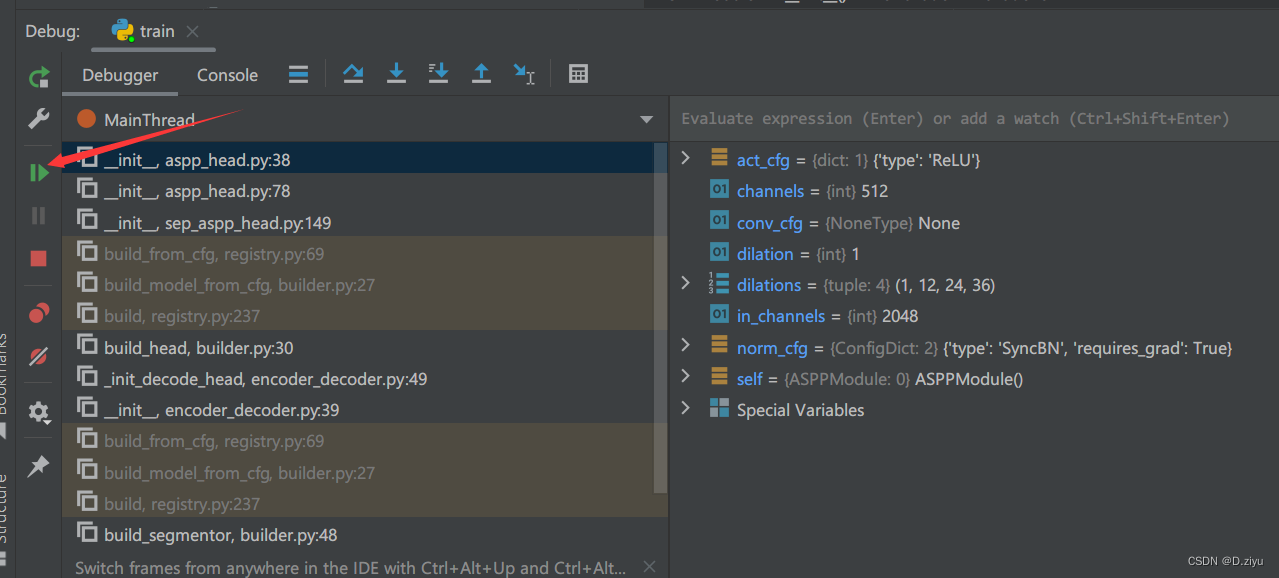
开局inputs里有四个不同深度层产生的的feature maps
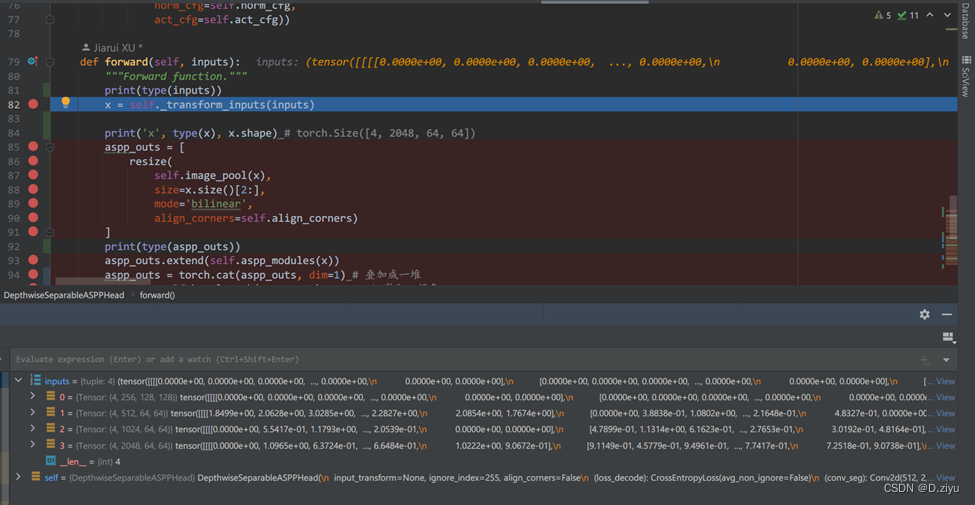
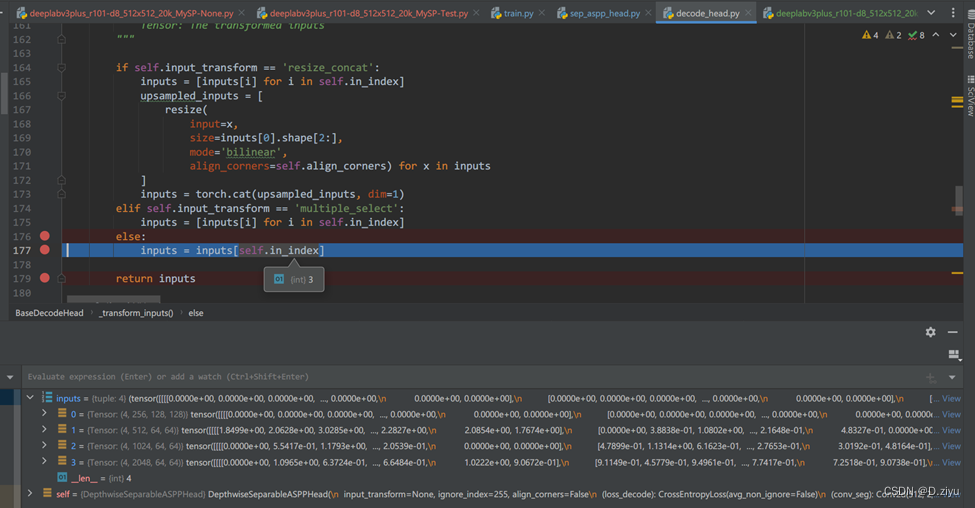
经过了transform_inputs函数后,进了decode_head.py。直接是else情况,in_index=3,说明是backbone最深层的feature map
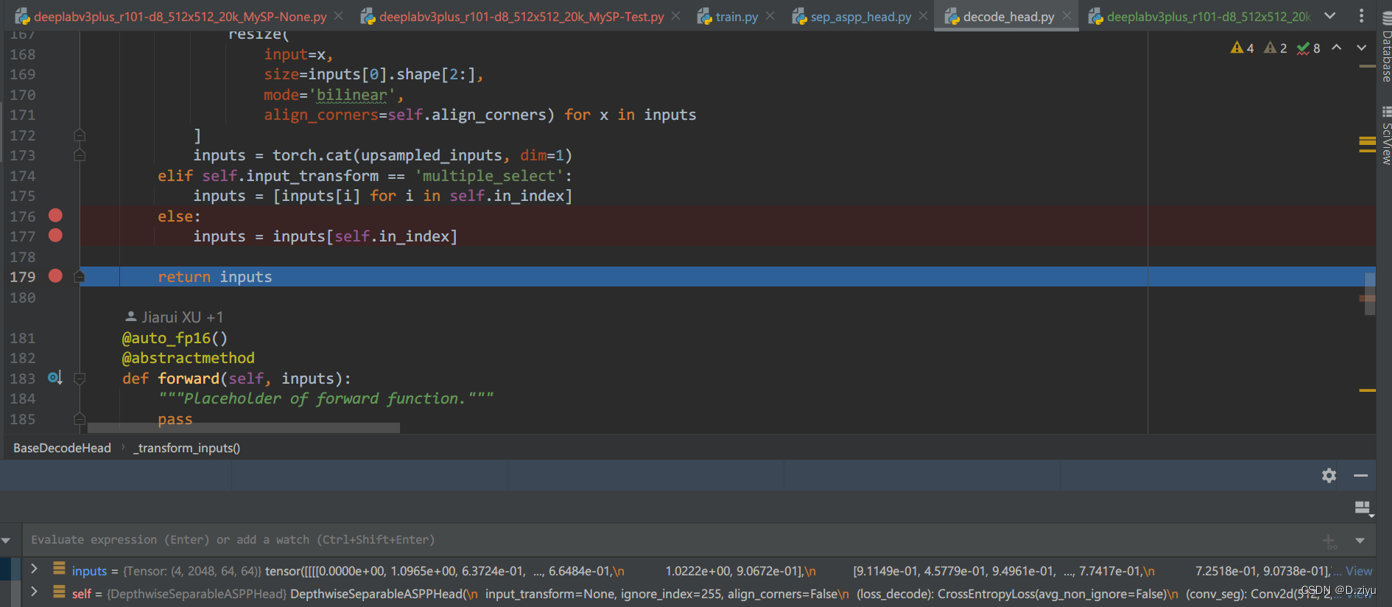
从那个函数回来,x是最深层的特征,shape = [2048 x 64 x 64]
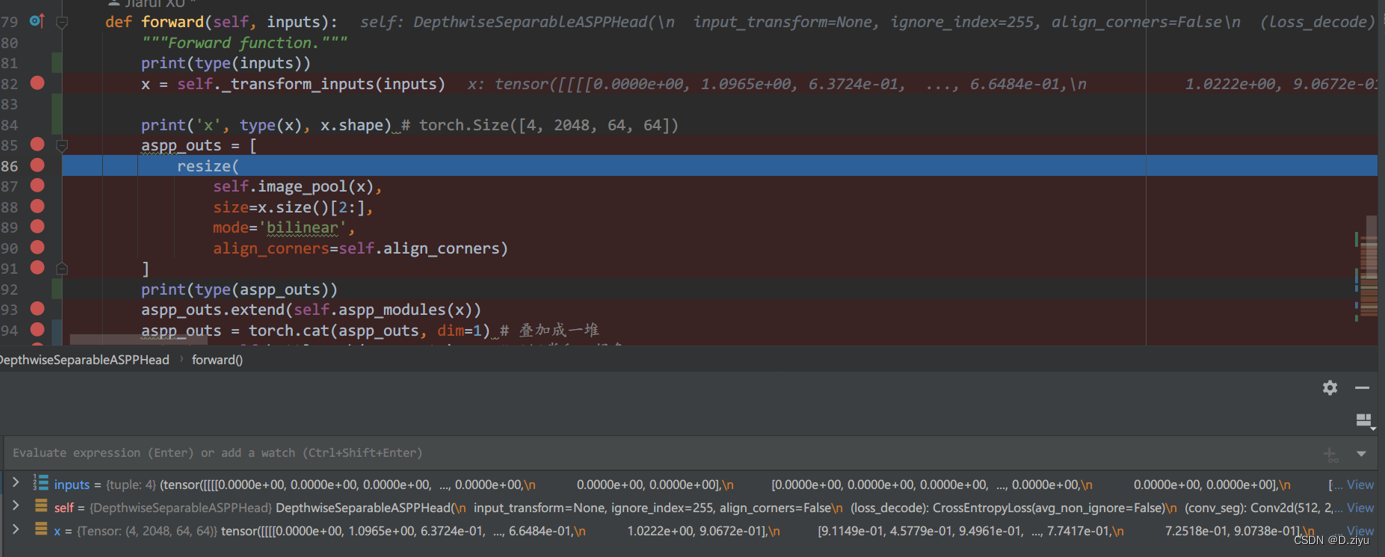
-----2022.10.30修改------
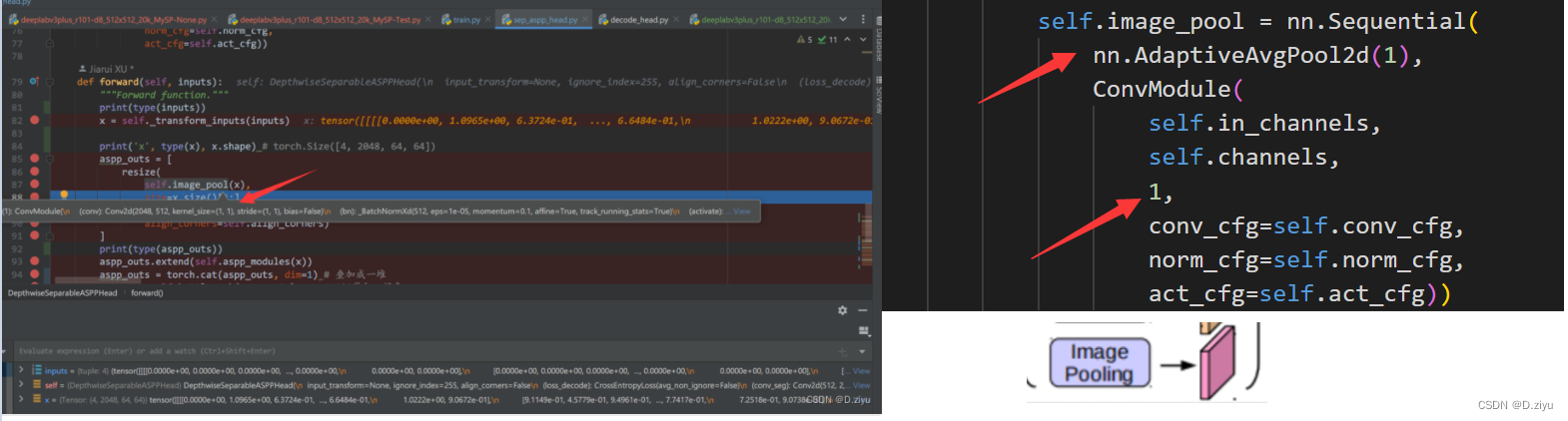
而图中的85-91行表明:
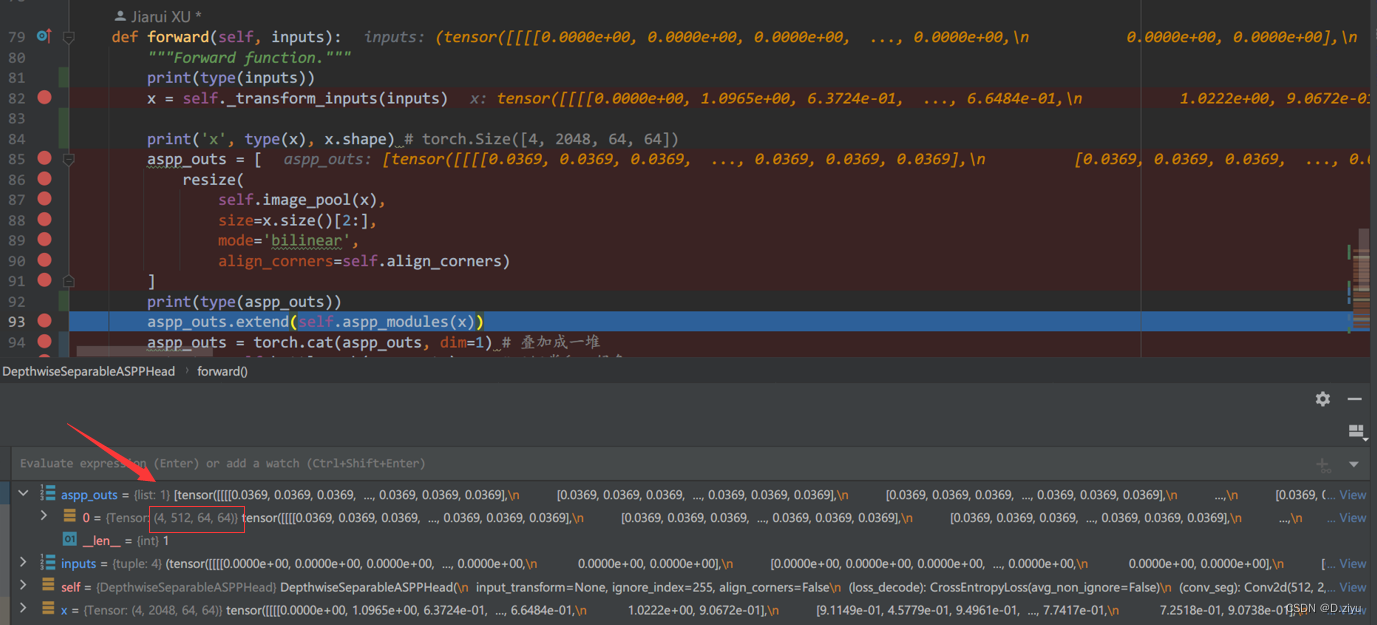
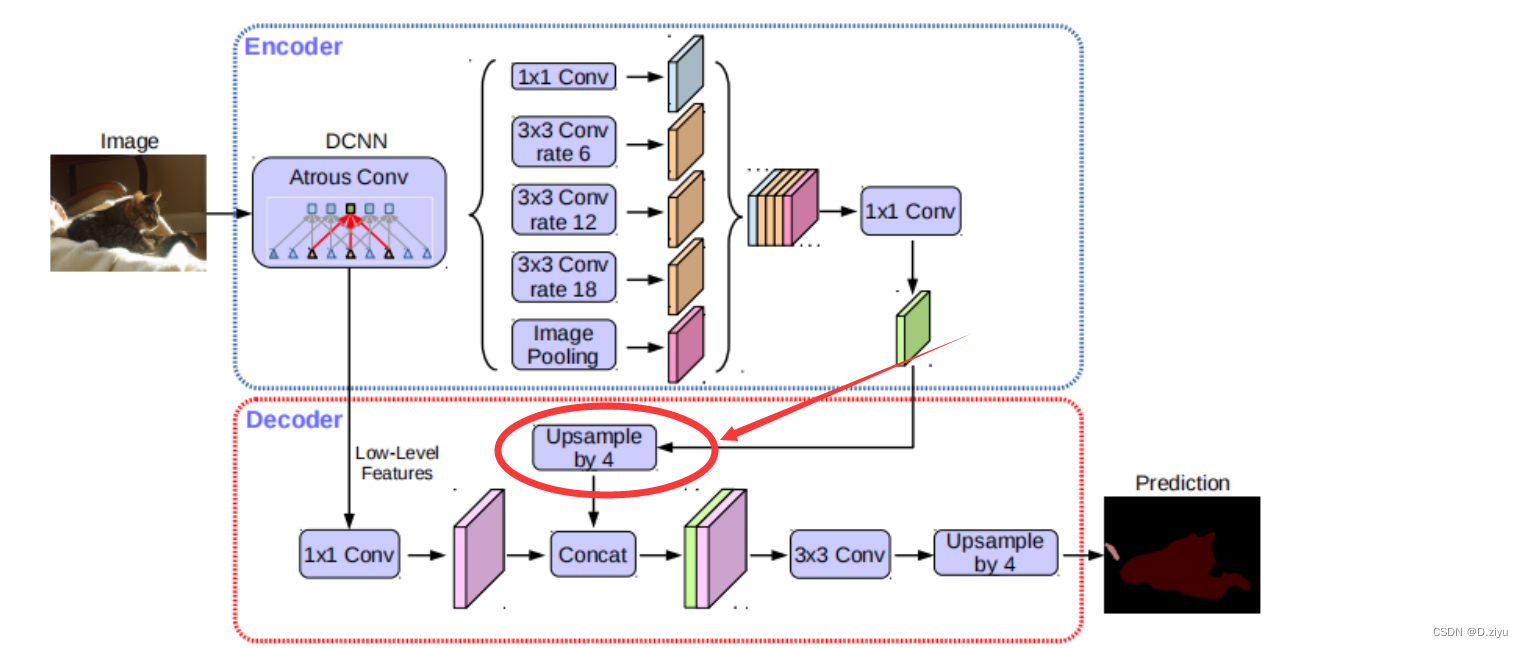
aspp_outs是x产生的。image_pool里先做了一个全局池化,此时shape=[Cx1x1],然后是1x1卷积,通道数由2048改为512,紧接着上采样,空间分辨率回到了64x64。这个过程如右下角图所示。
aspp_outs被赋值,512通道。
x给了aspp_modules,产生了其余四个列表。过程是:
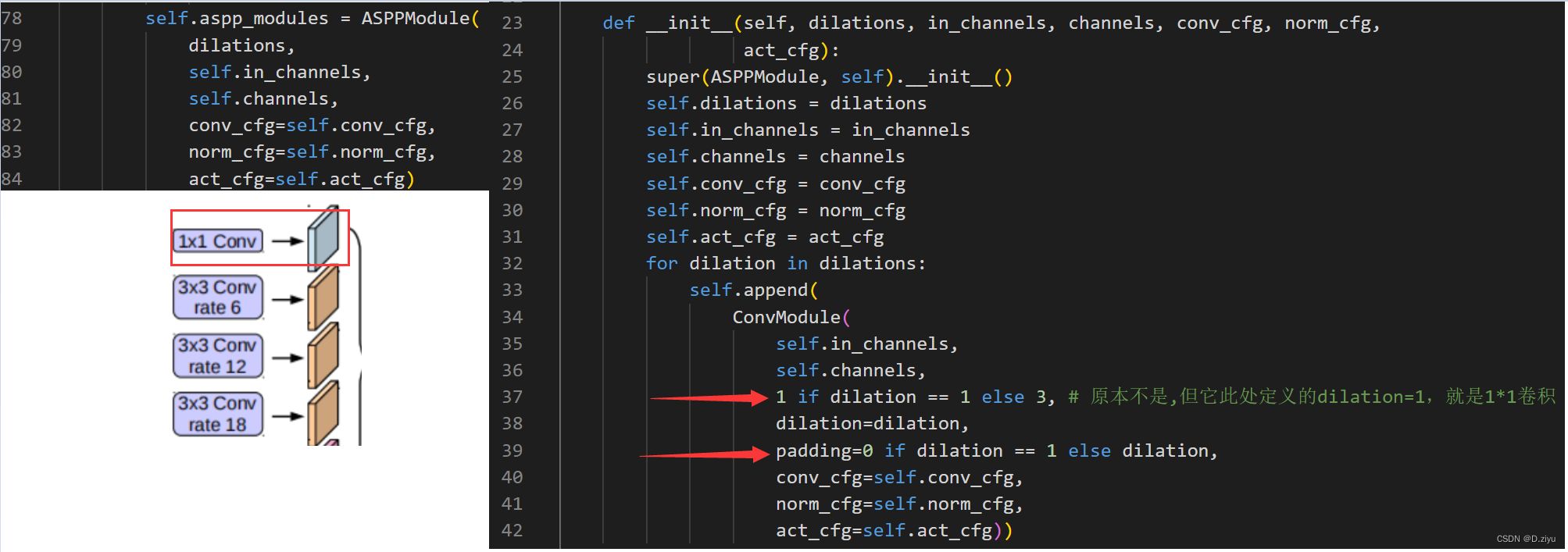
一般dilations=(1, 6, 12, 18),当dilation=1时,按理说是普通的3x3卷积,但mmseg规定是1x1卷积(红箭头标明)。上图左下角表明self.aspp_modules(x)过程。(特殊情况1x1卷积红框标明)
extend后,内有5个列表
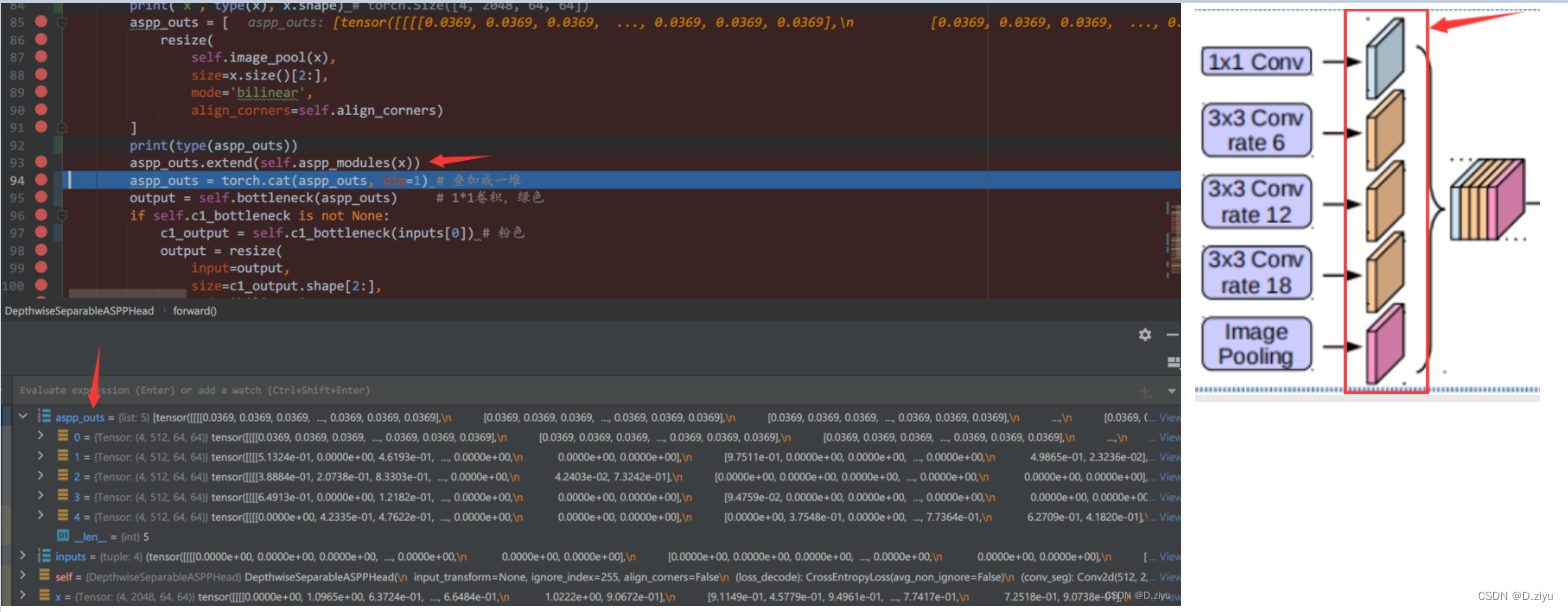
叠加为一堆,2560个通道(512*5)
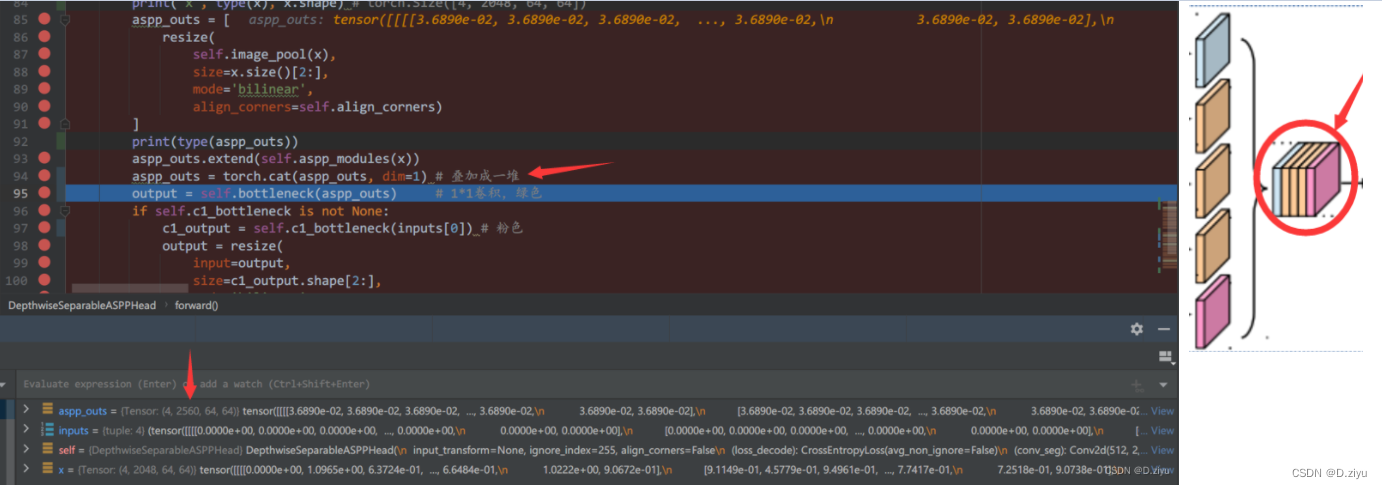
----2023.2.14修改-----
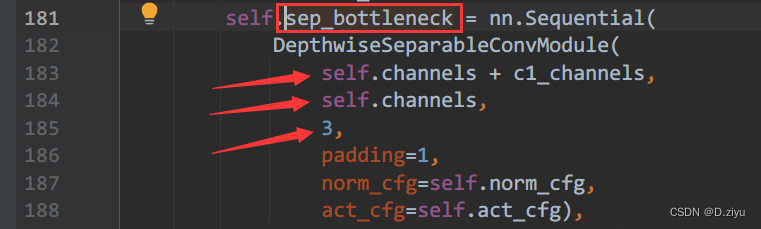
bottleneck负责调整通道数,从2560->512通道。原文做了一个1* 1的卷积,mmseg代码中是3*3卷积,padding=1,也在不改变空间分辨率的条件下调整了通道数。
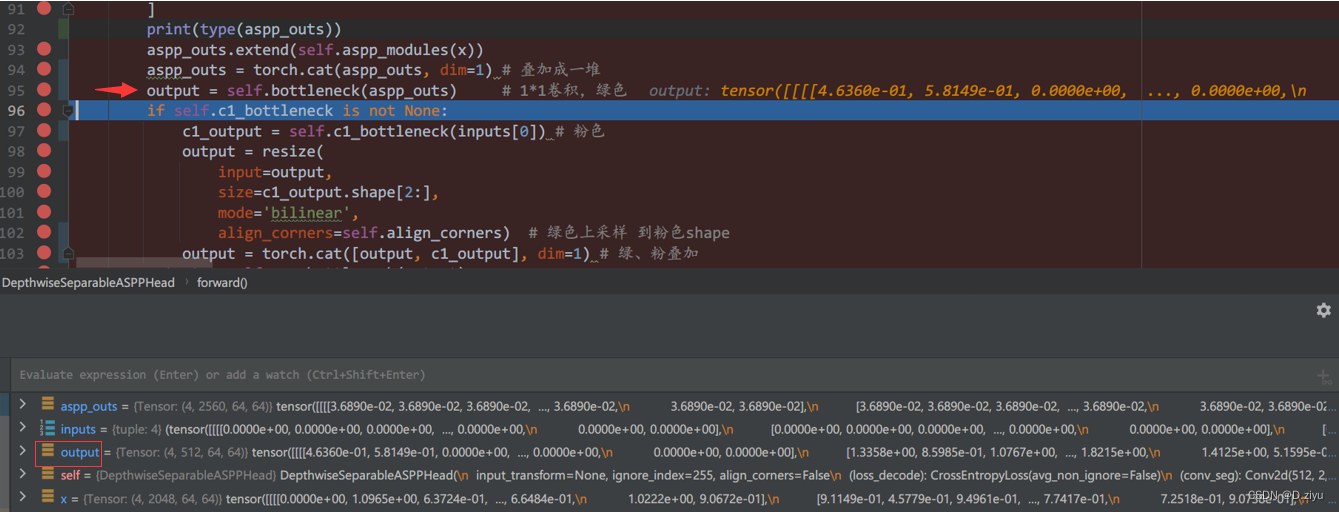
对应:
还记得最开始的inputs吗?inputs[0]就是浅层特征
回看inputs

inputs[0]对应这里:
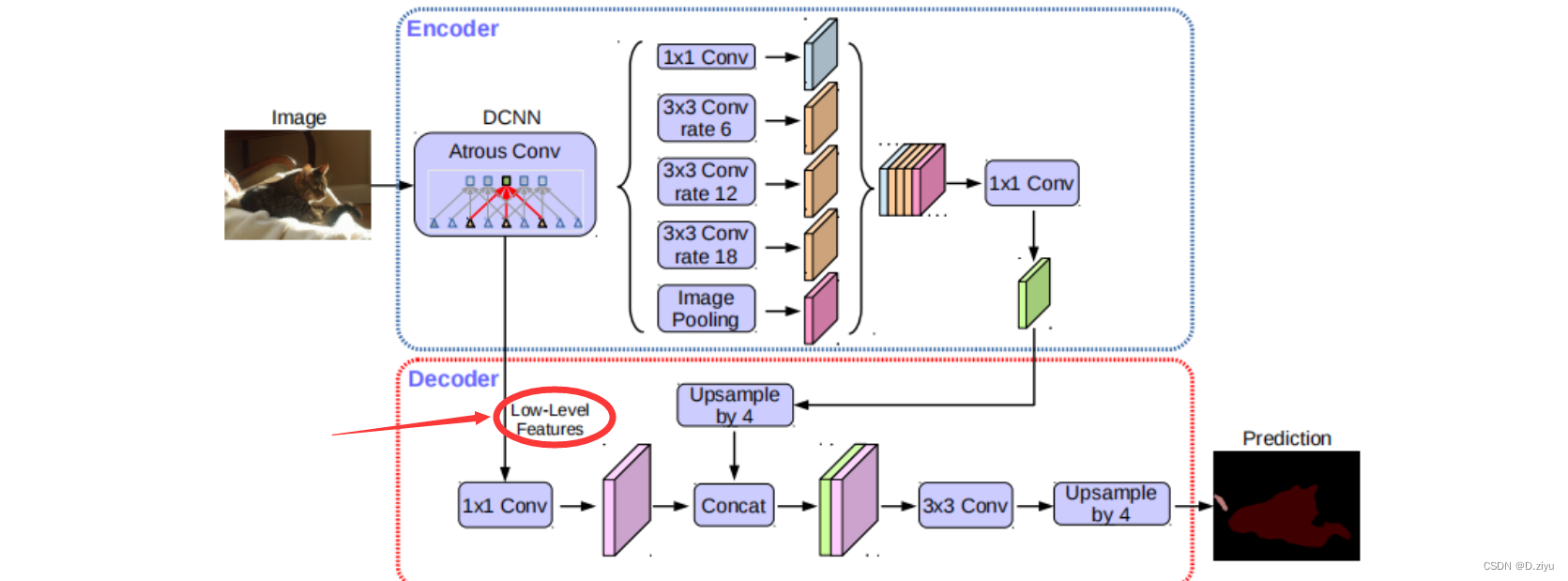
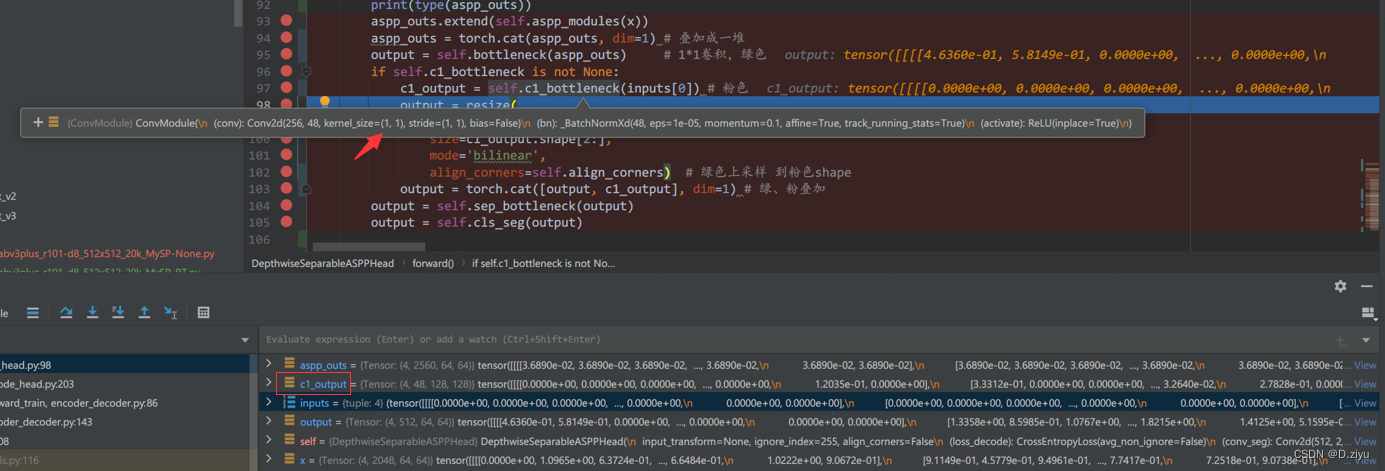
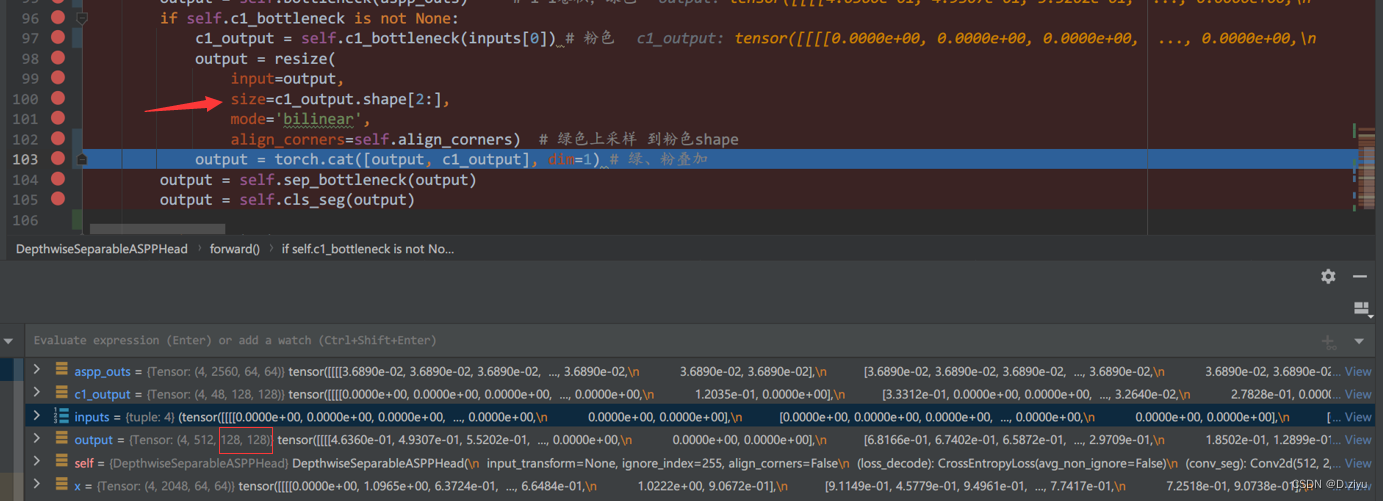
c1_bottleneck也是1*1卷积,得到的c1_output就是粉块
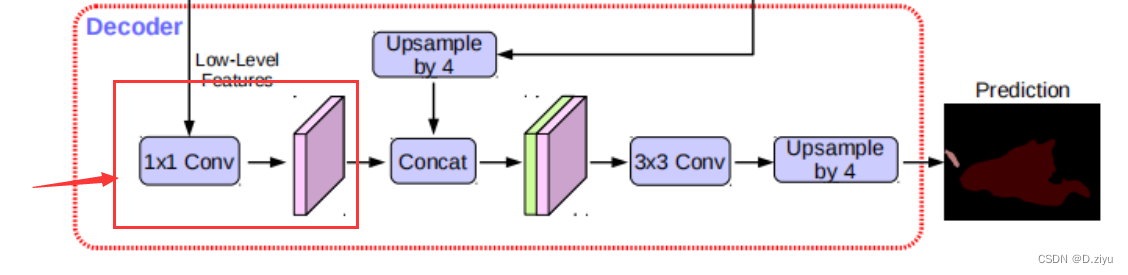
Output(绿色高级语义信息)经过2倍上采样后,128*128
框架图里是4倍上采样,但它只表示大概过程,这里代码其实做的是2倍上采样,都是可以改的
对应:
粉绿叠加
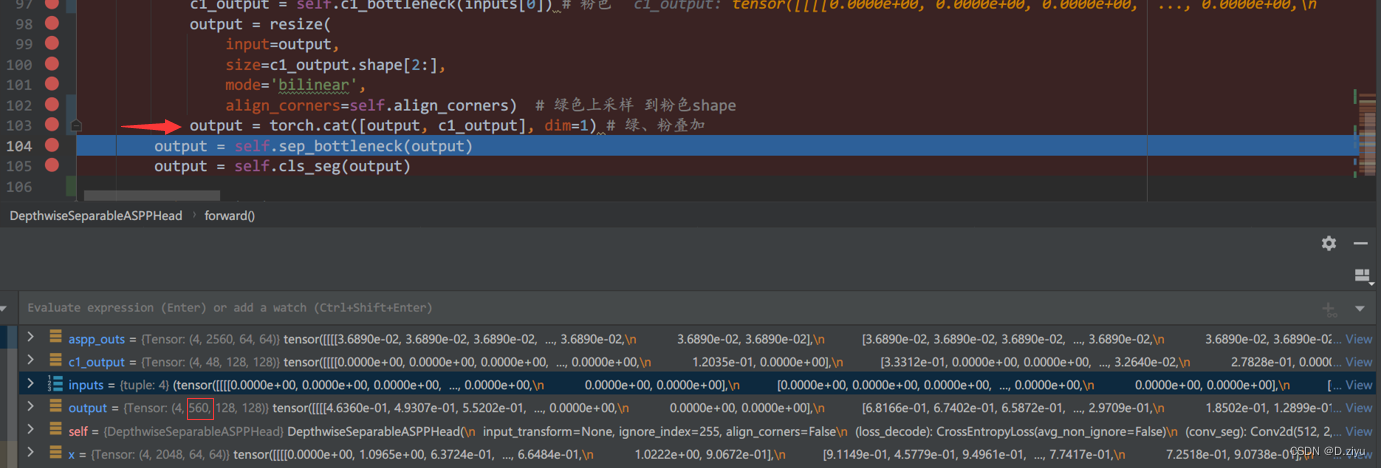
对应:

sep_bottleneck就是这个3*3卷积
由于我做的是二分类问题,所以最后通道为2。
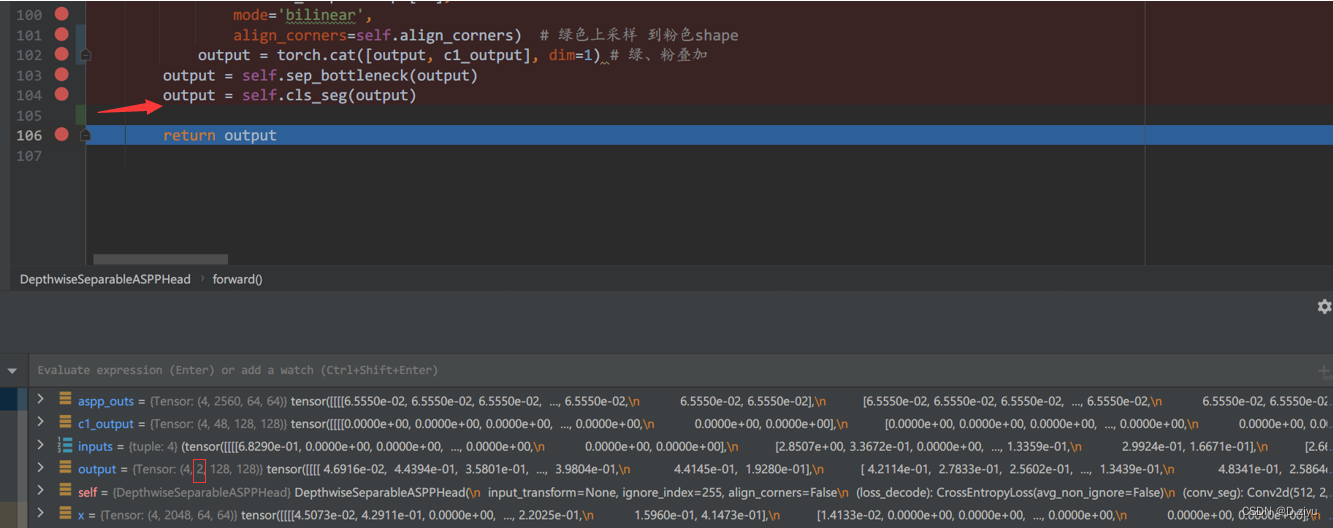
到这里就跑完了原有的deeplabV3+的流程。
还没结束!
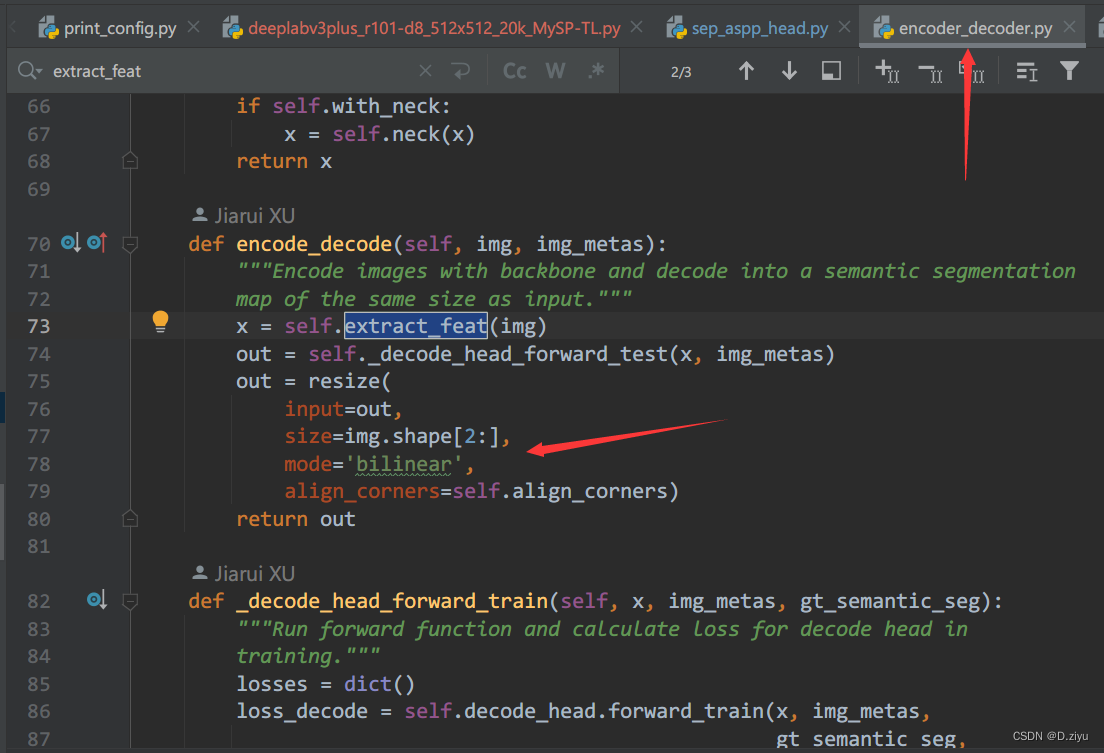
最后的output是128*128,没有那个4倍上采样,return后在encoder_decoder.py里做的最后的上采样。(这里只做补充说明,不影响加入Attention机制)
加入注意力机制
SE机制
SE(压缩激励)的介绍网上有很多,此处不再赘述
加入位置:(可以改,不固定)
方便起见,类声明直接加在前面
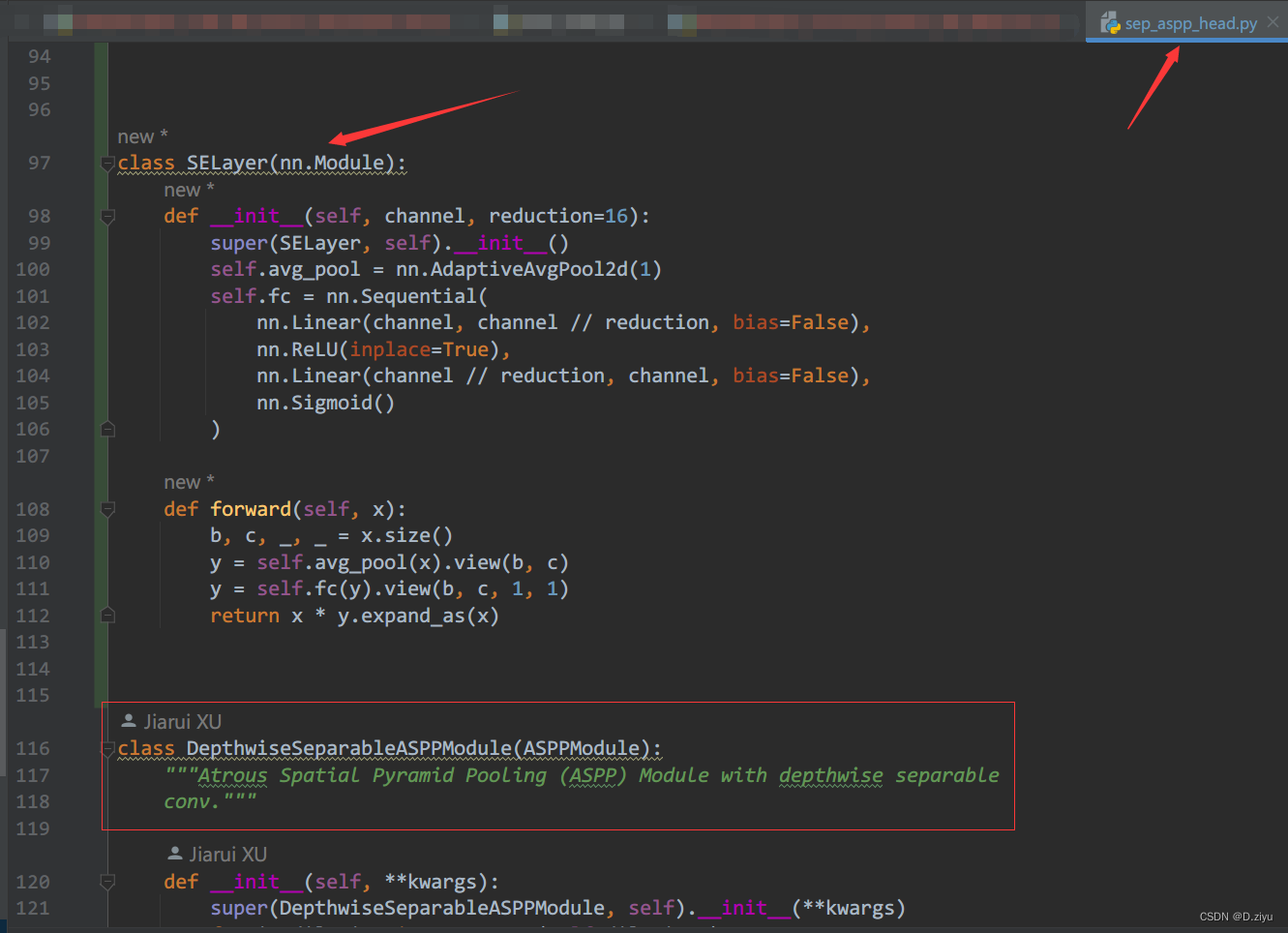
SE代码:
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
SE代码也是我在网上找的,改了一点就加进来了,可见注意机制还是好用的。
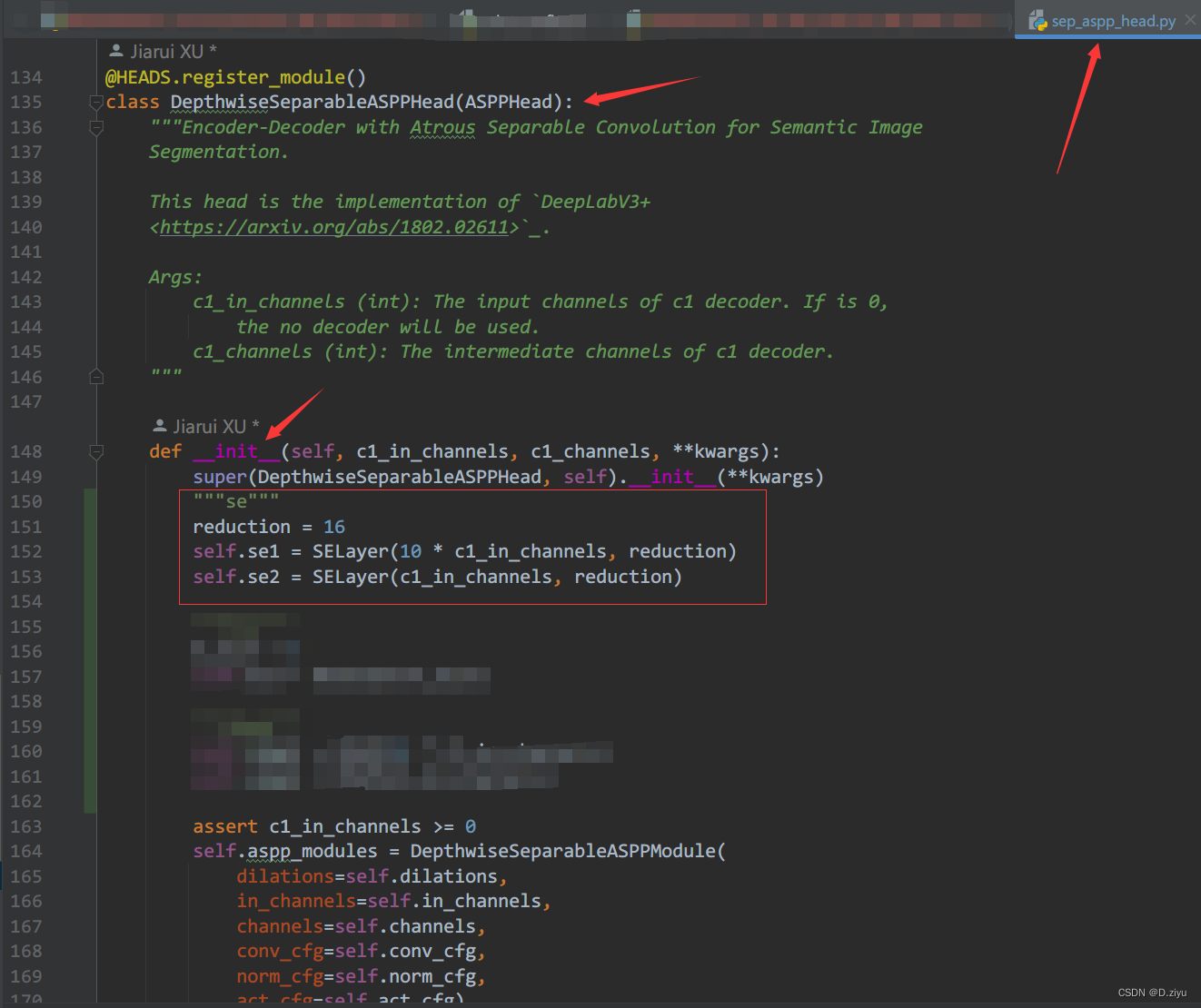
----修改于2023.2.23—
经网友提醒,发现这里写的不清楚,导致出现通道数不一致情况。我的锅~
"""se"""
reduction = 16 #
self.se1 = SELayer(10 * c1_in_channels, reduction)#我的c1_in_channels为256,所以直接就是10*256=2560,记得修改
通道数是待使用se的featuremaps的通道数,要换成自己的,比如2560。如果不知道通道数,debug也不方便,可以直接print它的size就知道了。
将SE加入这
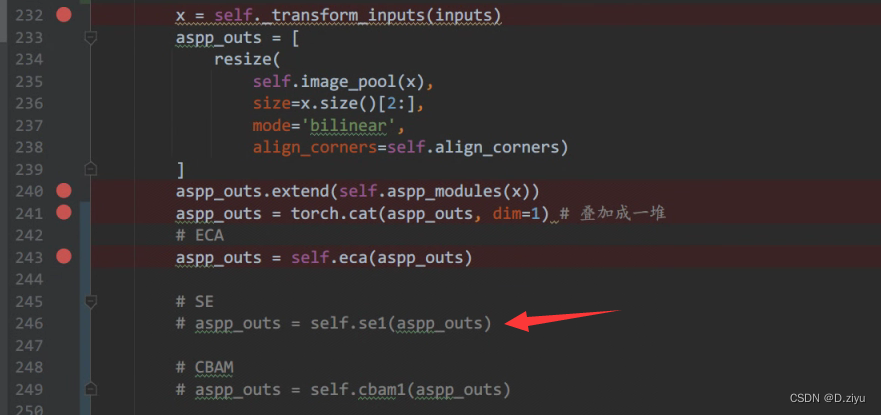
"""SE"""
aspp_outs = self.se1(aspp_outs)
改完后
原来的aspp_outs:
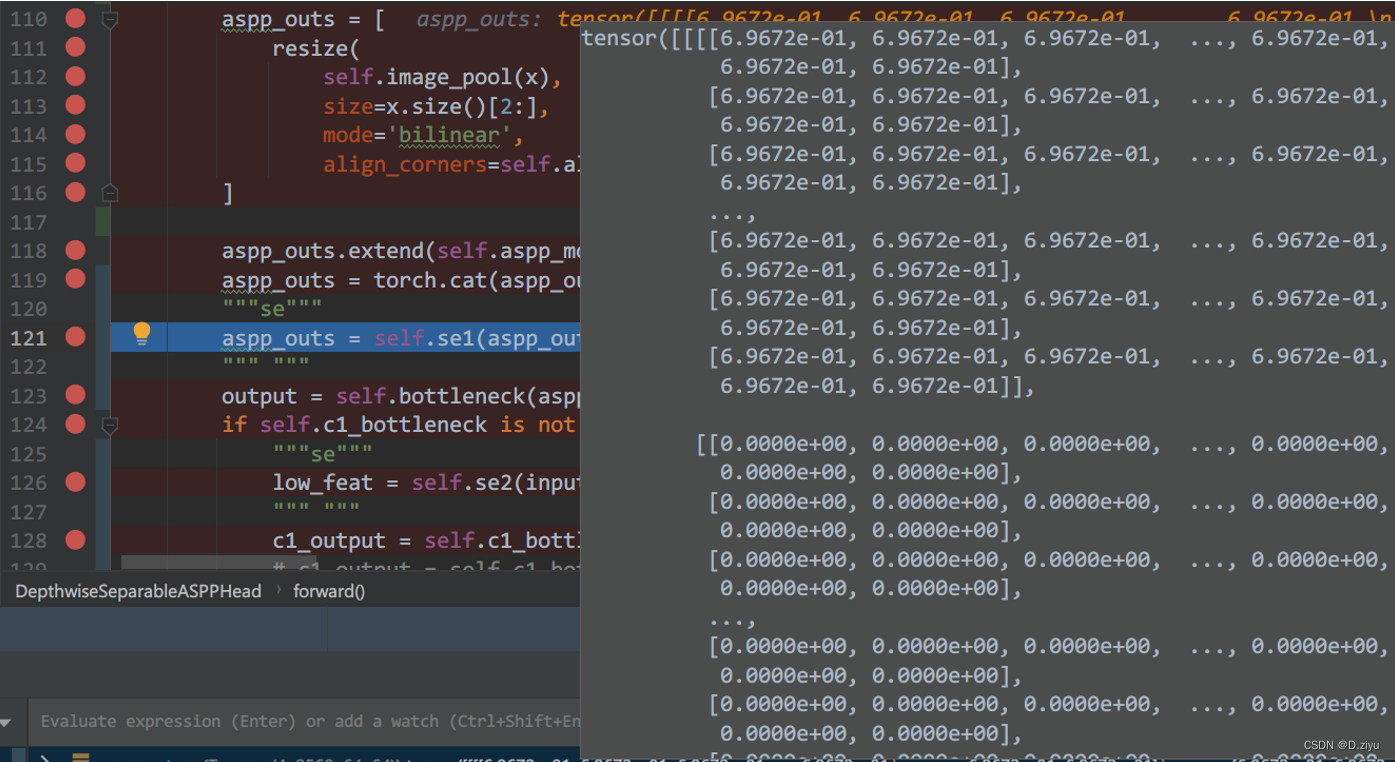
SE后,通道数未变,数据变了,添加成功
ECA
--------2022.12.10修改----------
代码也是网上copy来的,将下面三段代码分别按上面SE的步骤加入进去就行了
class ECALayer(nn.Module):
def __init__(self, k_size=3):
super(ECALayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: input features with shape [b, c, h, w]
b, c, h, w = x.size()
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y) ## y为每个通道的权重值
return x * y.expand_as(x) ##将y的通道权重一一赋值给x的对应通道
"""ECA"""
k_size = 3
self.eca = ECALayer(k_size)
# ECA
aspp_outs = self.eca(aspp_outs)
--------2022.11.12修改----------
看到有些小伙伴出现了下面的问题,这应该是对应的通道数没有输入正确,检查修改一下就好了。
mat1 and mat2 shapes cannot be multiplied
照猫画虎,加入ECA机制进行对比。最后的mIoU是 加入ECA > 加入SE > 不使用注意机制。可见加入注意力机制后,效果还是可以的。


















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









