







云数据库学习🛵🛵🛵上车
1:云数据库入门,基本概念了解💕
1.1 云数据库是关系型还是Nosql?
uniCloud提供了一个 JSON 格式的文档型数据库。顾名思义,数据库中的每条记录都是一个 JSON 格式的文档,它是 nosql
非关系型数据库。
1.2 uniCloud 云数据库和关系型数据库的对比
| 关系型 | JSON 文档型 |
|---|---|
| 数据库 database | 数据库 database |
| 表 table | 集合 collection。但行业里也经常称之为“表”。无需特意区分 |
| 行 row | 记录 record / doc |
| 字段 column / field | 字段 field |
| 使用sql语法操作 | 使用MongoDB语法或jql语法操作 |
一个uniCloud服务空间,有且只有一个数据库,这一点和关系型数据库还是有区别的。像mysql和sqlserver 都是多数据库可以创建.
1.3 官方文档传送门
2: 基本操作表 创建 && CRUD💕
2.1: 创建表的三种方式
1:在uniCloud web控制台 进行创建
🚗🚗🚗🚗🚗🚗🚗

2:在项目根目录/uniCloud/database
在项目根目录/uniCloud/database点右键新建schema,如果没有database自行创建,如果是最新版本,默认是有这个文件夹。
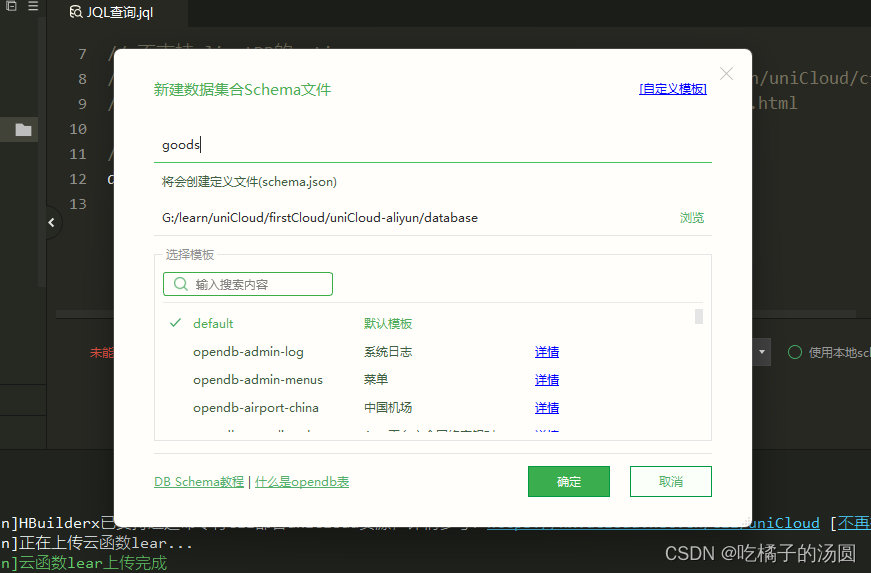
创建好右击表名.schema.json点击上传
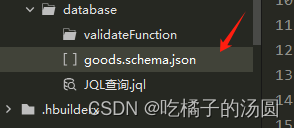
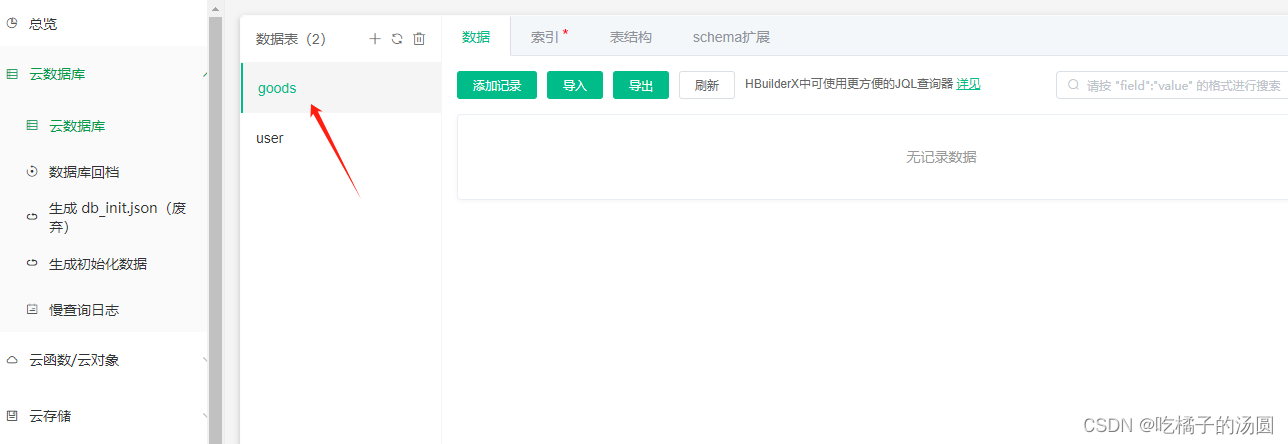
在控制台查看刚才创建好的表:
3:在代码中创建表(不是很推荐)
在代码中也可以创建表,官方不是很推荐这种创建方式了解即可,有兴趣的可以自行学习,这里只给出阿里云服务空间的创建方式
- 阿里云
调用add方法,给某数据表新增数据记录时,如果该数据表不存在,会自动创建该数据表。如下代码给table1数据表新增了一条数据,如果table1不存在,会自动创建。
const db = uniCloud.database();
db.collection(“table1”).add({name: ‘Ben’})
2.2:在项目根目录创建关联表练习💖
创建`user`表和`articles`文章表练习,其中`articles`表中关联`user` 表ID
1:user 表结构
{
"bsonType": "object",
"required": [],
"permission": {
"read": false,
"create": false,
"update": false,
"delete": false
},
"properties": {
"_id": {
"description": "ID,系统自动生成"
},
"username": {
"bsonType": "string",
"title": "用户名",
"description": "用户名,不允许重复",
"trim": "both"
},
"password": {
"bsonType": "password",
"title": "密码",
"description": "密码,加密存储",
"trim": "both"
}
}
}
2: articles 表结构
{
"bsonType": "object",
"required": [],
"permission": {
"read": true,
"create": true,
"update": true,
"delete": true
},
"properties": {
"_id": {
"description": "ID,系统自动生成"
},
"user_id": {
"bsonType": "string",
"description": "文章作者ID, 参考`user` 表",
"foreignKey": "user._id"
},
"title": {
"bsonType": "string",
"title": "标题",
"description": "标题",
"label": "标题",
"trim": "both"
},
"content": {
"bsonType": "string",
"title": "文章内容",
"description": "文章内容",
"label": "文章内容",
"trim": "right"
}
}
}
其中 articles 表中的user_id是关联user表中的ID,如果是后端数字MySQL的可能知道两表查询是有 join
leftjoin 等关联查询,在云数据库里面是没有的,通过foreignKey 属性就可以定义关联关系。
创建好之后根据上面创建表的第二种方式上传到uniCloud 控制台。
3:上述表结构属性分析
基本表结构
{
"bsonType": "object", // 固定节点
"description": "该表的描述",
"permission": {
"read": true, // 任何用户都可以读
"create": false, // 禁止新增数据记录(admin权限用户不受限)
"update": false, // 禁止更新数据(admin权限用户不受限)
"delete": false, // 禁止删除数据(admin权限用户不受限)
"count": false // 禁止查询数据条数(admin权限用户不受限),新增于HBuilderX 3.1.0
},
"required": [], // 必填字段列表
"properties": { // 该表的字段清单
"_id": { // 字段名称,每个表都会带有_id字段
"description": "ID,系统自动生成"
// 这里还有很多字段属性可以设置
},
"field2": { // 字段2,每个表都会带有_id字段
"description": ""
// 这里还有很多字段属性可以设置
"foreignKey":""//关联表
}
}
}
2.3:JQL描述(操作数据库的语法)💖
- JQL,全称 javascript query language,是一种js方式操作数据库的规范
- JQL大幅降低了js工程师操作数据库的难度,比SQL和传统MongoDB API更清晰、易掌握
- JQL支持强大的DB Schema,内置数据规则和权限。DB Schema 支持uni-id,可直接使用其角色和权限。无需再开发各种数据合法性校验和鉴权代码
- QL利用json数据库的嵌套特点,极大的简化了联表查询和树查询的复杂度,并支持更加灵活的虚拟表
1:几种场景使用JQL
- 客户端clientDB,包括js内以及unicloud-db组件内
- HBuilderX JQL数据库管理器
- 启用了jql扩展的云函数
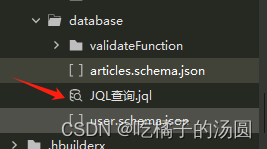
以下操作数据使用第二种方式在database 里面会有一个JQL查询.jql 在里面执行就可以:
2.4:添加数据 add()方法💖
1:user 表添加一条数据
写好语句之后全选右击执行即可
db.collection('user').add({
username:'李四',
password:'123456'
});
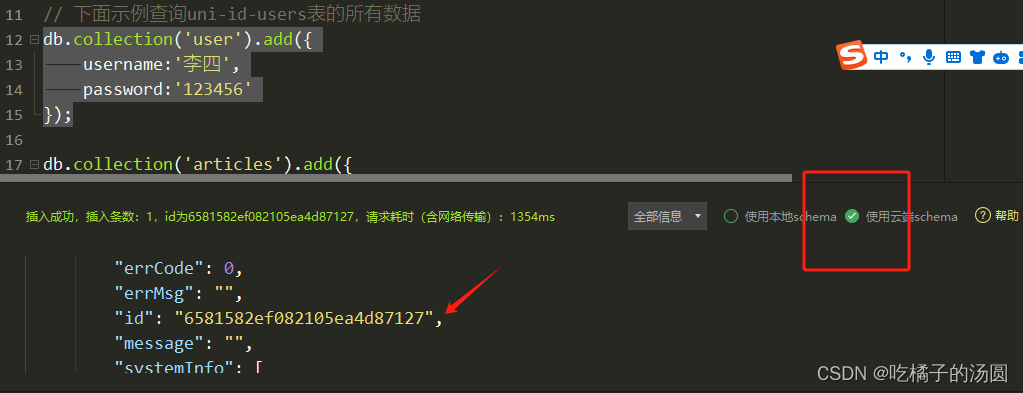
成功之后会返回一个ID
2:user 表添加多条数据
db.collection('user').add([
{
username:'王五',
password:'123456'
},
{
username:'赵六',
password:'123456'
}
]);
成功之后:
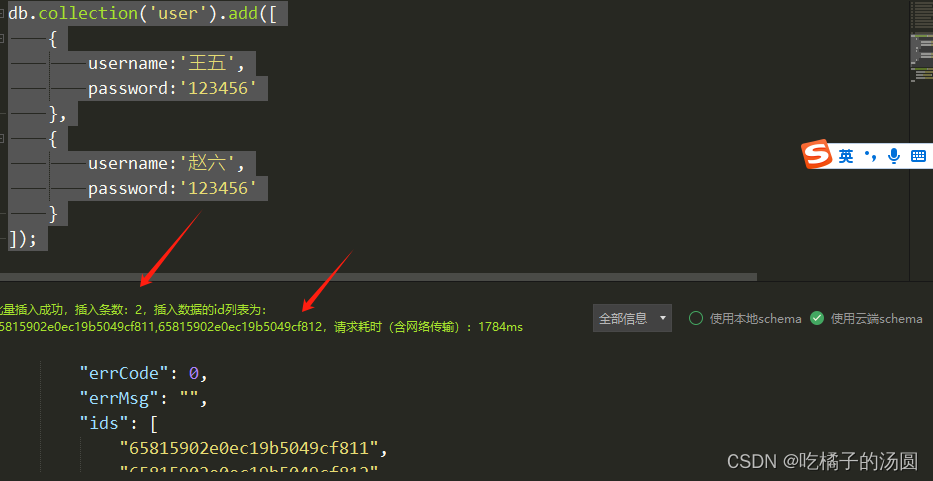
3: articles 表添加数据(单条多条同上,注意)
db.collection('articles').add({
user_id:'65814f6f652341901b75d140',//需要注意user_id 是上面添加返回的ID
title:'西游记',
content:'猪八戒打孙悟空'
});
4:添加数据响应格式
// 添加一条记录成功之后响应的数据格式(其实返回的比官方给的文档多):
{
errCode: 0,
errMsg: '',
id: '' // 新增数据的id
}
//多条记录添加之后返回响应的数据格式:
{
errCode: 0,
errMsg: '',
ids: [], // 新增数据的id列表
inserted: 3 // 新增成功的条数
}
``
2.5: 删除数据的两种方式 remove()💖
1: 通过指定ID删除 doc(id).remove()
//删除user表 id等于65815902e0ec19b5049cf812 的数据
db.collection('user').doc('65815902e0ec19b5049cf812').remove()
2: 条件查找之后删除 where().remove()
//删除user 表 username=王五 的数据
db.collection('user').where({
username:"王五"
}).remove()
3: 删除数据返回响应格式
{
errCode: 0,
errMsg: '',
deleted: 1 // 删除的条数
}
2.6 :更新数据 update()💖
1:使用doc(id).update()
//更新user表 id等于 6581582ef082105ea4d87127 的数据
db.collection('user').doc('6581582ef082105ea4d87127')
.update({
username: "李四1"
})
2: 使用where(条件).update()
//更新user表 id等于 6581582ef082105ea4d87127 的数据
db.collection('user').where({
_id: '6581582ef082105ea4d87127'
})
.update({
username: "李四2"
})
3: 更新数组类型通过集合下标进行更新(注意jql是没有这个语法的)
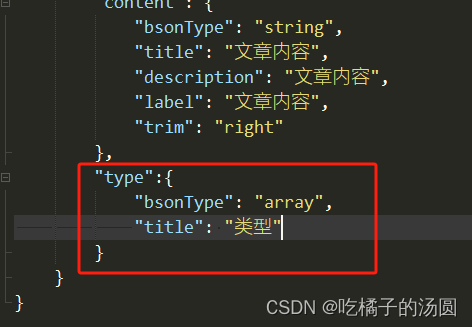
//articles 增加数组类型字段
"type":{
"bsonType": "array",
"title": "类型"
}
//添加数据
db.collection('articles').add({
user_id: '65814f6f652341901b75d140',
title: '西游记',
content: '猪八戒打孙悟空',
type:['a','b']
});
在控制台查看结果:
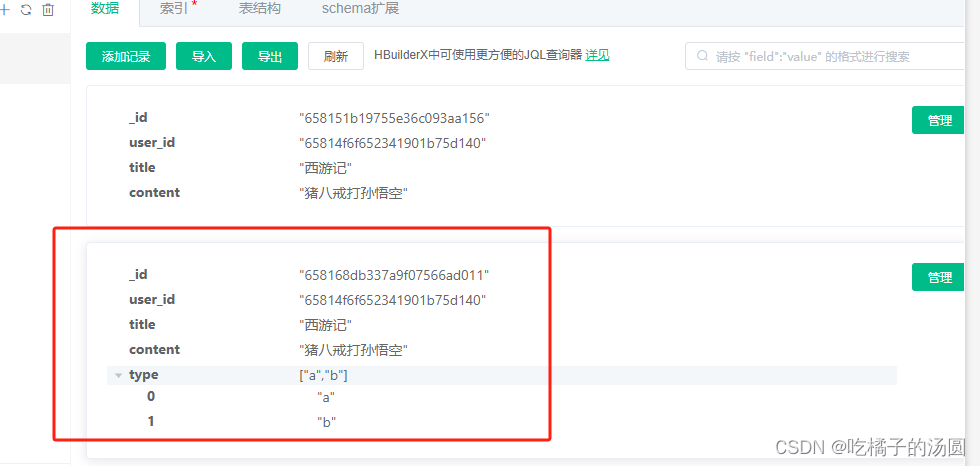
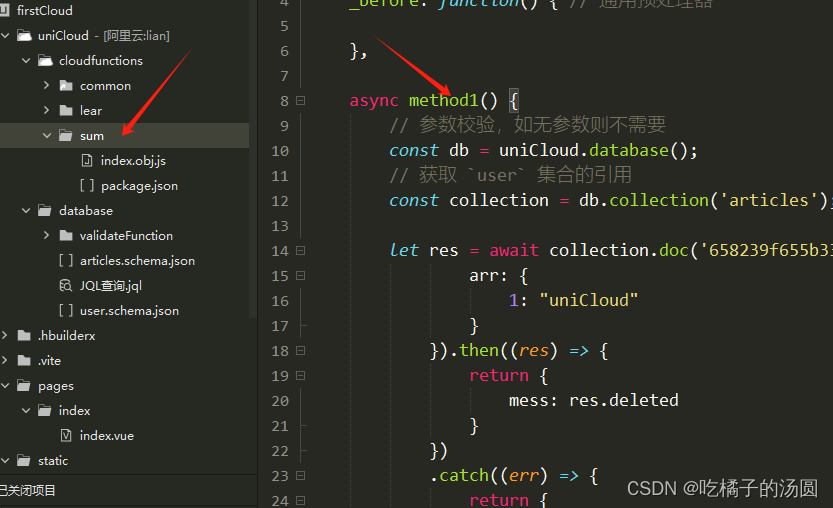
修改type 字段的数据:
//这块代码写在云对象方法中进行调用
const db = uniCloud.database();
const collection = db.collection('articles');
let res = await collection.doc('658239f655b337cfad67fd84').update({
arr: {
1: "uniCloud"
}
}).then((res) => {
return {
mess: res.deleted
}
})
.catch((err) => {
return {
mess: 'err'.err.message
}
})
4:更新数据响应的格式
{
errCode: 0,
errMsg: '',
updated: 1 // 更新的条数,数据更新前后无变化则更新条数为0
}
2.7: 查询数据(重要)🍭
1:查询条件预览
| 运算符 | 说明 | 示例 | 示例解释(集合查询) |
|---|---|---|---|
| == | 等于 | name == 'abc' | 查询name属性为abc的记录,左侧为数据库字段 |
| != | 不等于 | name != 'abc' | 查询name属性不为abc的记录,左侧为数据库字段 |
| > | 大于 | age>10 | 查询条件的 age 属性大于 10,左侧为数据库字段 |
| >= | 大于等于 | age>=10 | 查询条件的 age 属性大于等于 10,左侧为数据库字段 |
| < | 小于 | age<10 | 查询条件的 age 属性小于 10,左侧为数据库字段 |
| <= | 小于等于 | age<=10 | 查询条件的 age 属性小于等于 10,左侧为数据库字段 |
| in | 存在在数组中 | status in ['a','b'] | 查询条件的 status 是['a','b']中的一个,左侧为数据库字段 |
| !(xx in []) | 在数组中不存在 | !(status in ['a','b']) | 查询条件的 status 不是['a','b']中的任何一个 |
| && | 与 | uid == auth.uid && age > 10 | 查询记录uid属性 为 当前用户uid 并且查询条件的 age 属性大于 10 |
| || | 或 | uid == auth.uid||age>10 | 查询记录uid属性 为 当前用户uid 或者查询条件的 age 属性大于 10 |
| test | 正则校验 | /abc/.test(content) | 查询 content字段内包含 abc 的记录。可用于替代sql中的like。还可以写更多正则实现更复杂的功能 |
2:User 表批量添加测试数据
db.collection('user').add([{
username: '王五',
password: '123456'
},
{
username: '赵六',
password: '123456'
},
{
username: '孙悟空',
password: '123456'
},
{
username: '猪八戒',
password: '123456'
},
{
username: '小猪佩奇',
password: '123456'
},
{
username: 'GGboy',
password: '123456'
}
]);
3:单表查询💕
3.1:查询全部数据 get()
db.collection('user').get()
3.2: 带查询条件 where()
//查询 username 等于zhangsan
db.collection('user').where({
username:'zhangsan',
}).get()
// 查询 username 等于zhangsan 和猪八戒
db.collection('user')
.where("username in ['zhangsan','猪八戒']").get()
//查询 username 等于zhangsan 或者_id==65814f6f652341901b75d140
db.collection('user')
.where("username=='zhangsan' || _id=='65814f6f652341901b75d140'").get()
//查询 username 等于zhangsan 并且_id==65814f6f652341901b75d140
db.collection('user')
.where("username=='zhangsan' && _id=='65814f6f652341901b75d140'").get()
//正则匹配 username 里面包含李四的数据
db.collection('user')
.where("/李四/.test(username)").get()
3.3:运算方式查询

比如有个test 表 数据格式如下
运算方法参考【点击上车🏎️】
{
"_id": "1",
"name": "n1",
"chinese": 60, // 语文
"math": 60 // 数学
}
{
"_id": "2",
"name": "n2",
"chinese": 60,
"math": 70
}
{
"_id": "3",
"name": "n3",
"chinese": 100,
"math": 90
}
//筛选语文数学总分大于150的数据
const db = uniCloud.database()
const res = await db.collection('test')
.where('add(chinese,math) > 150')
.get()
// 返回结果如下
res = {
result: {
data: [{
"_id": "3",
"name": "n3",
"chinese": 100,
"math": 90
}]
}
}
3.4:分页查询 skip()+limit()
- skip 跳过前多少条
- limit 获得多少条
limit不设置的情况下默认返回100条数据;设置limit有最大值,腾讯云限制为最大1000条,阿里云限制为最大1000条。
// 跳过前面两条返回一条数据
db.collection('user').skip(2).limit(1).get()
//只返回一条数据
db.collection('user').limit(1).get()
3.5:只查询指定字段 field()
//只返回username 字段
db.collection('user').field('username').get()
🤠复杂嵌套json数据过滤
如果数据库里的数据结构是嵌套json,比如book表有个价格字段,包括普通价格和vip用户价格,数据如下:
{
"_id": "1",
"title": "西游记",
"author": "吴承恩",
"price":{
"normal":10,
"vip":8
}
}
那么使用db.collection(‘book’).field(“price.vip”).get(),就可以只返回vip价格,而不返回普通价格。查询结果如下
{
"_id": "1",
"price":{
"vip":8
}
}
3.6:字段别名 as
//返回字段名不再是username 而是 username1
db.collection('user').field('username as username1').get()
3.7: 对查询的数据进行排序 orderby()
orderBy每个字段可以指定 asc(升序)、desc(降序)。默认是升序
//根据名称进行升序 db.collection('user').field('username').orderBy('username asc').get()
3.8: 对查询的数据分组 groupby()和 groupField()
groupby对某个字段进行分组groupField里面对file 字段的操作,注意groupField里不能直接写field字段,只能使用分组运算方法来处理字段,常见的累积器计算符包括:count(*)、sum(字段名称)、avg(字段名称)
如果数据库score表为某次比赛统计的分数数据,每条记录为一个学生的分数。学生有所在的年级(grade)、班级(class)、姓名(name)、分数(score)等字段属性 结构如下:
{
_id: "1",
grade: "1",
class: "A",
name: "zhao",
score: 5
}
{
_id: "2",
grade: "1",
class: "A",
name: "qian",
score: 15
}
{
_id: "3",
grade: "1",
class: "B",
name: "li",
score: 15
}
{
_id: "4",
grade: "1",
class: "B",
name: "zhou",
score: 25
}
{
_id: "5",
grade: "2",
class: "A",
name: "wu",
score: 25
}
{
_id: "6",
grade: "2",
class: "A",
name: "zheng",
score: 35
}
使用sum方法可以对数据进行求和统计:
const res = await db.collection('score')
.groupBy('grade,class')
.groupField('sum(score) as totalScore')
.get()
返回结果如下:
{
data: [{
grade: "1",
class: "A",
totalScore: 20
},{
grade: "1",
class: "B",
totalScore: 40
},{
grade: "2",
class: "A",
totalScore: 60
}]
}
3.9:数据去重distinct()
如果数据库score表为某次比赛统计的分数数据,每条记录为一个学生的分数
{
_id: "1",
grade: "1",
class: "A",
name: "zhao",
score: 5
}
{
_id: "2",
grade: "1",
class: "A",
name: "qian",
score: 15
}
{
_id: "3",
grade: "1",
class: "B",
name: "li",
score: 15
}
{
_id: "4",
grade: "1",
class: "B",
name: "zhou",
score: 25
}
{
_id: "5",
grade: "2",
class: "A",
name: "wu",
score: 25
}
{
_id: "6",
grade: "2",
class: "A",
name: "zheng",
score: 35
}
按照grade、class两字段去重,获取所有参赛班级
const res = await db.collection('score')
.field('grade,class')
.distinct() // 注意distinct方法没有参数
.get()
{
data: [{
grade:"1",
class: "A"
},{
grade:"1",
class: "B"
},{
grade:"2",
class: "A"
}]
}
3.10: getone() 和 getcount()
- getone 在get方法内传入参数getOne:true来返回一条数据,getOne其实等价于上一节的limit(1)
- getcount 根据条件查询到的count
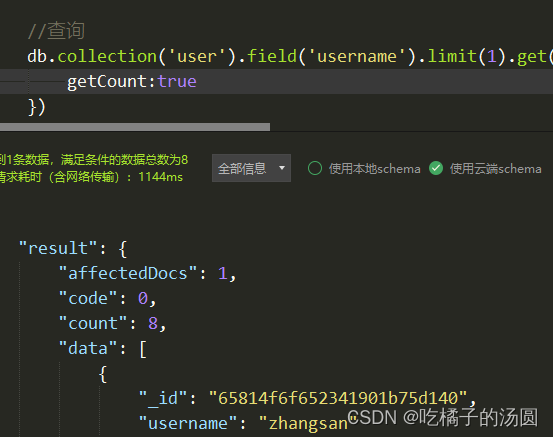
//添加 getcount db.collection('user').field('username').limit(1).get({
getCount:true
})
只返回一条数据 limit 控制,但是查询出来的count 有8条,如果不加getCount 返回结果是没有这个字段的
//添加 getOne 就返回一条跟limit(1)效果一样
db.collection('user').field('username').get({
getOne:true
})
4:联表查询 ,下面没了,别慌💕
4.1:基本的操作
- 临时表:getTemp方法返回的结果,例:const articles=
db.collection(‘articles’).getTemp(),此处 articles就是一个临时表 - 虚拟联表:主表与副表联表产生的表,例:db.collection(user, ‘articles’).get()
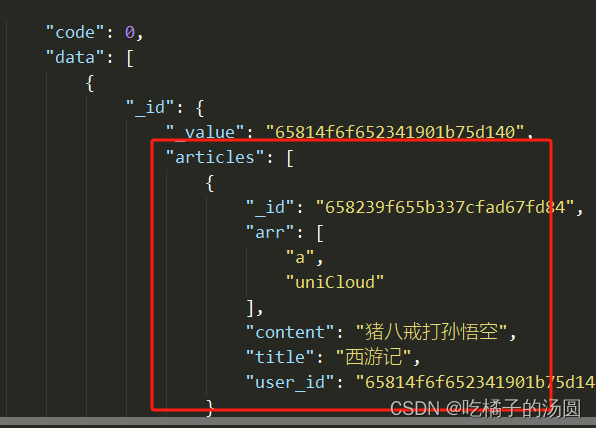
// user 和 articles 联表
const user=db.collection('user').getTemp()
const articles=db.collection('articles').getTemp()
db.collection(user, articles).get()
返回数据如下:
4.1:优化上面的查询
// user 和 articles 联表,但是user 表可以指定where 查询某个数据
const user=db.collection('user').where("_id=='65814f6f652341901b75d140'").getTemp()
const articles=db.collection('articles').getTemp()
db.collection(user, articles).get()
4.3:临时表可以使用的方法
where
field // 关于field的使用限制见下方说明
orderBy
skip
limit
5:查询返回的数据格式🐳
查询数据
{
errCode: 0,
errMsg: '',
data: []
}
批量发送数据库查询请求
{
errCode: 0,
errMsg: '',
dataList: [] // dataList内每一项都是一个查询数据的响应结果 {errCode: 0, errMsg: '', data: []}
}



















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











