






一、大数据技术概述
1、大数据概述
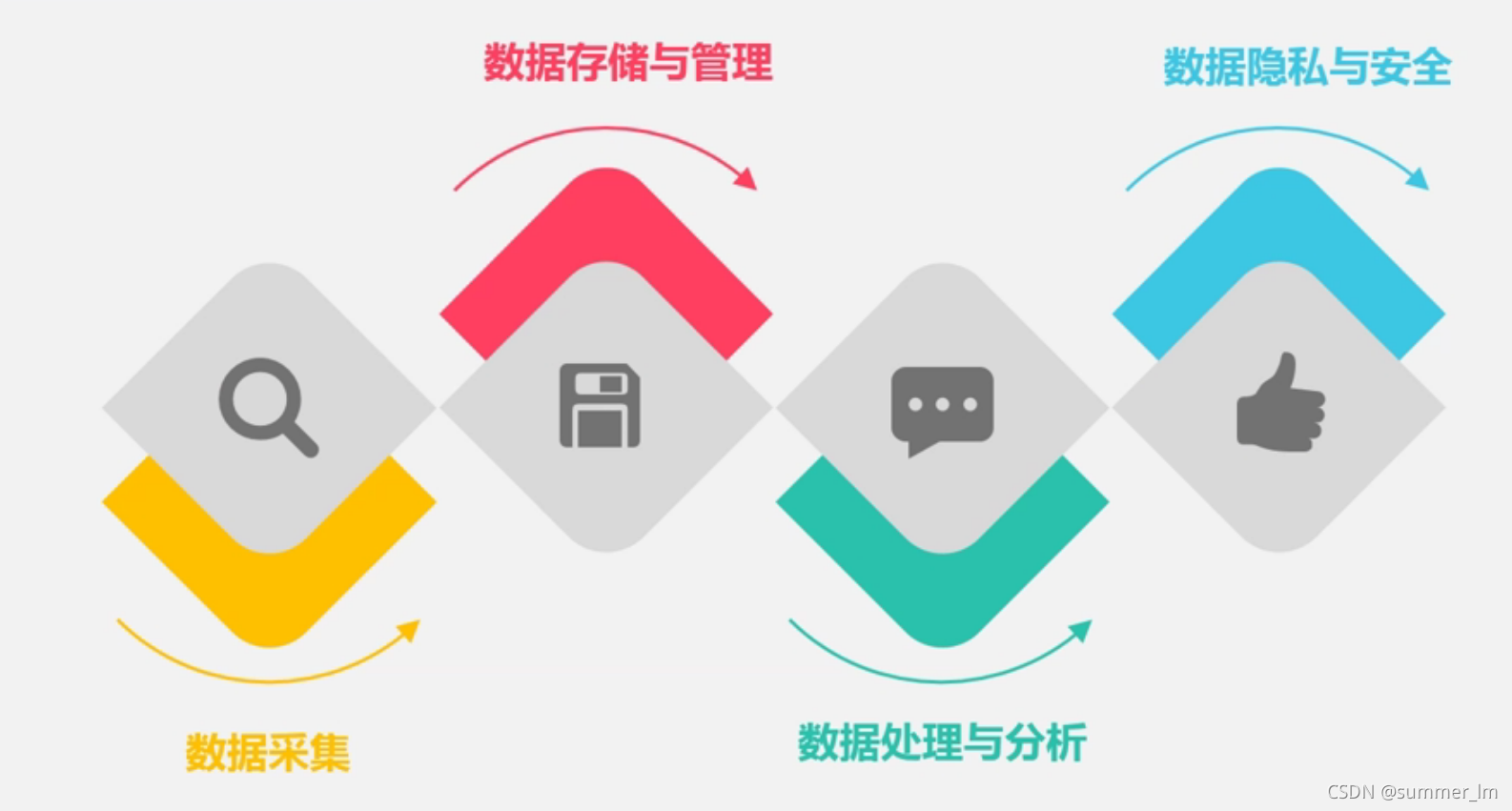 google技术:
google技术:
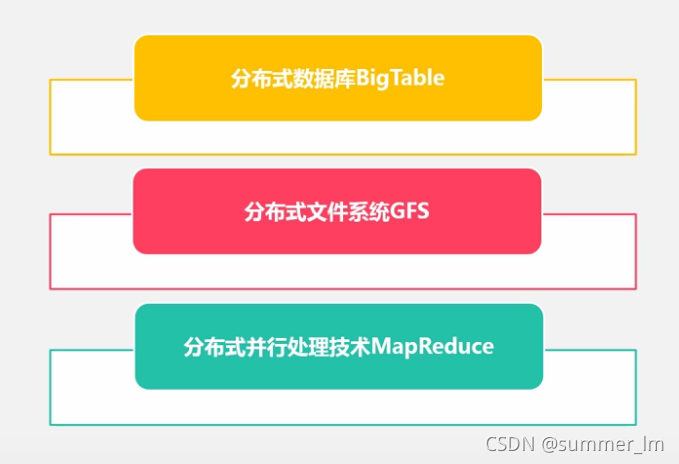
典型的计算模式:
1、批处理模式:MapReduce
2、流计算:实时处理,给出实时响应
3、图计算
4、查询分析计算

2、云计算:
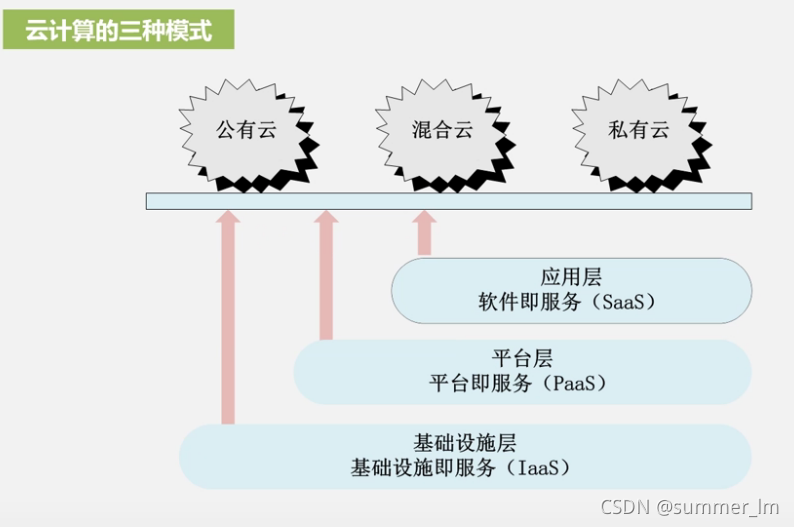
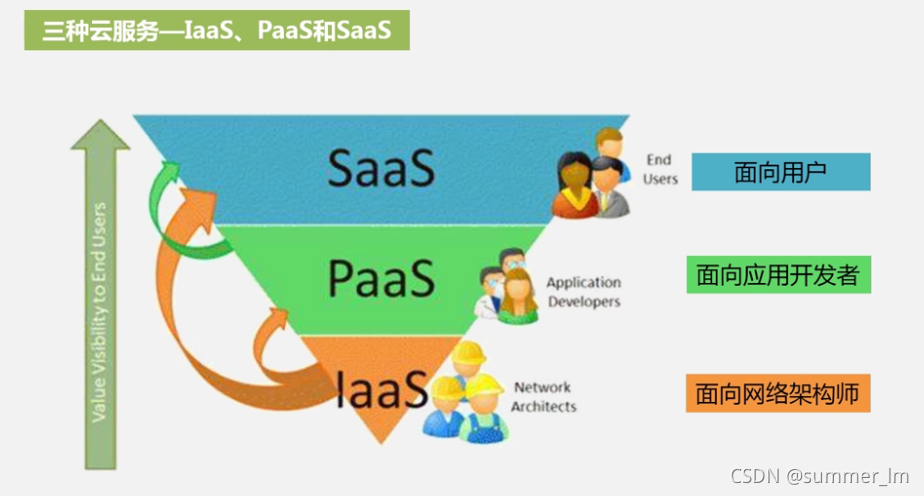
虚拟化:

2、物联网
物联网:物物相连的互联网。
物联网的层次架构:
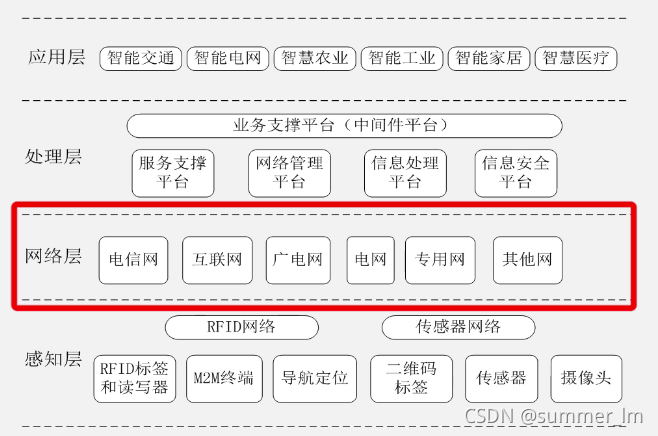
物联网的关键技术:
1、 识别技术
如:二维码
2、感知技术
如:公交卡
二、Hadoop
1、简介
Hadoop是Apache软件基金会旗下的开源软件。可以支持多种编程语言。
Hadoop的两大核心:HDFS+MapReduce。
2、特点:
高可靠性
高效性
高可扩展性
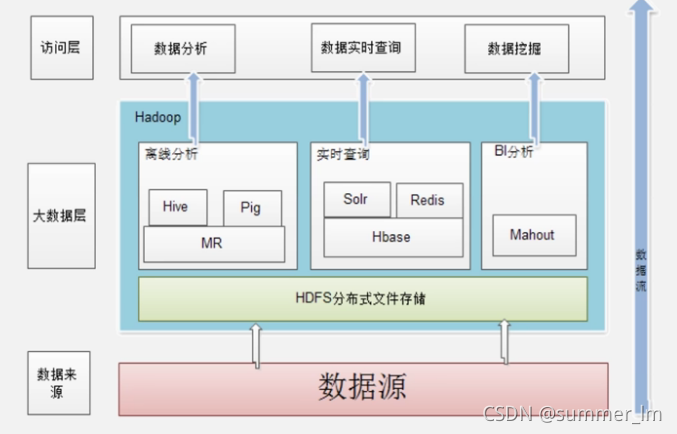
3、应用现状:
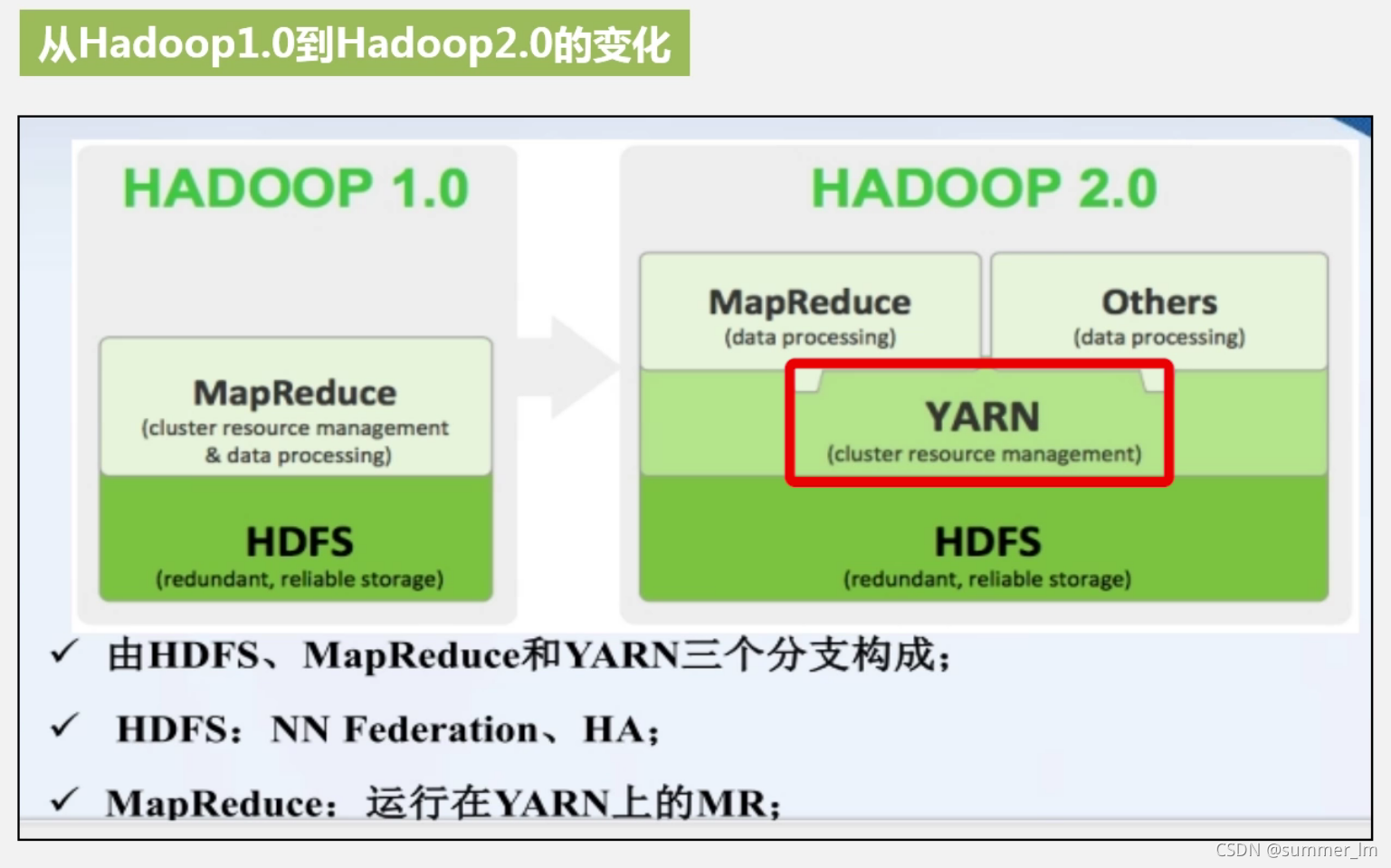
4、版本变化:
5、Hadoop的项目结构
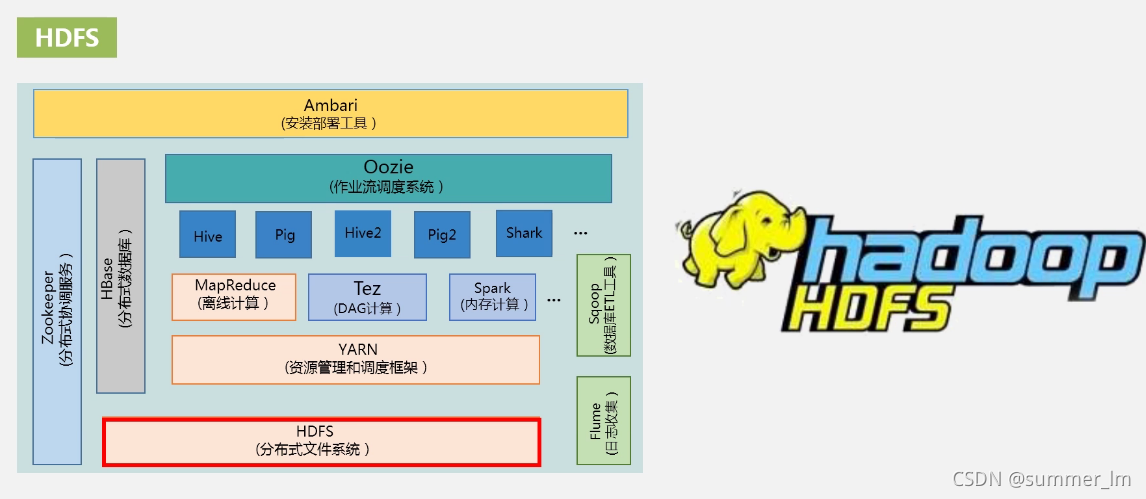
HDFS:分布式文件系统
YARN:资源管理和调度框架(集群资源管理)
MapReduce:离线计算
Tez:DAG计算
Spark:内存计算
Hive
Pig
Hive2
Pig2
Shark
Zookeeper:分布式协调服务
Hbase:分布式数据库
Flume:日志收集
Sqoop:数据库ETL工具
三、HDFS
HDFS:分布式文件系统。
HDFS实现目标:
1、兼容廉价的硬件设备
2、实现流数据读写
3、支持大数据集
4、支持简单的文件模型
5、强大的跨平台兼容性
HDFS自身的局限性:
1、不适合低延迟数据访问:不满足实时性
2、无法高效存储大量小文件
3、不支持多用户写入和任意修改文件,只允许追加
HDFS概述
块:
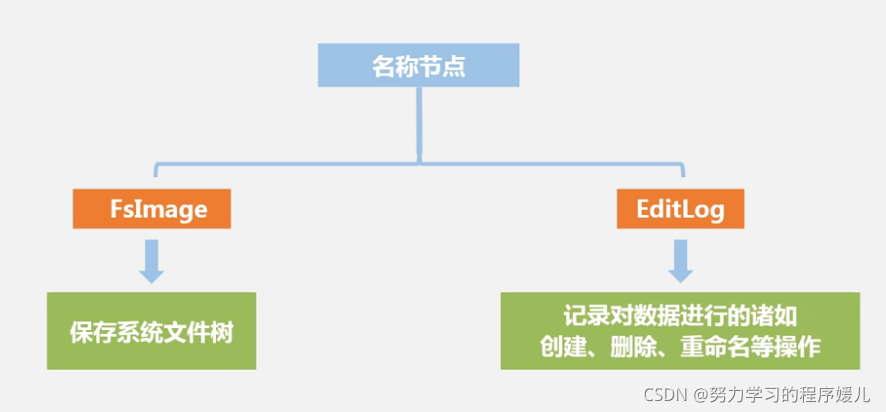
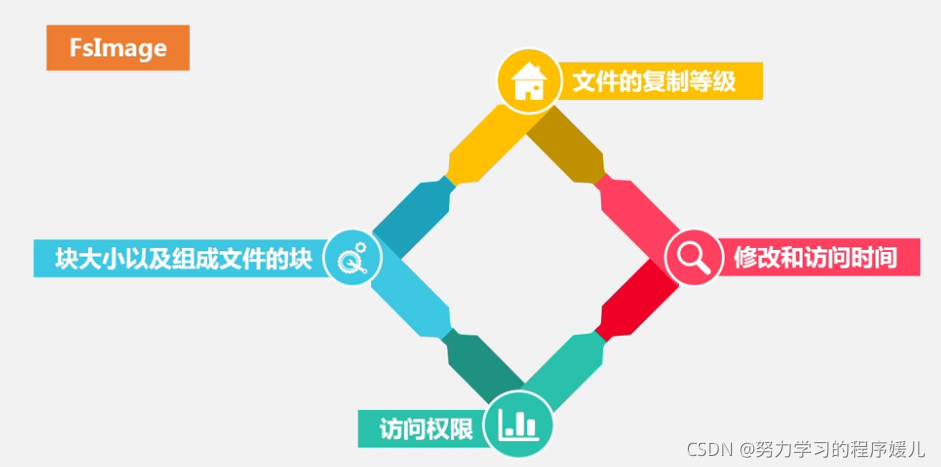
1、块:HDFS中最核心的概念,HDFS中的一个块比文件系统中的块大很多。为了分摊磁盘读写开销,也就是在大量数据间分摊磁盘寻址的开销。
2、目的:支持面向大规模数据存储、降低分布式节点的寻址开销。
3、缺点:如果块过大会导致 MapReduce 就 一两个任务在执行完全牺牲了 MapReduce 的并行度,发挥不了分布式并行处理的效果。
4、好处:支持大规模文件存储、简化系统设计、适合数据备份
HDFS两大组件:
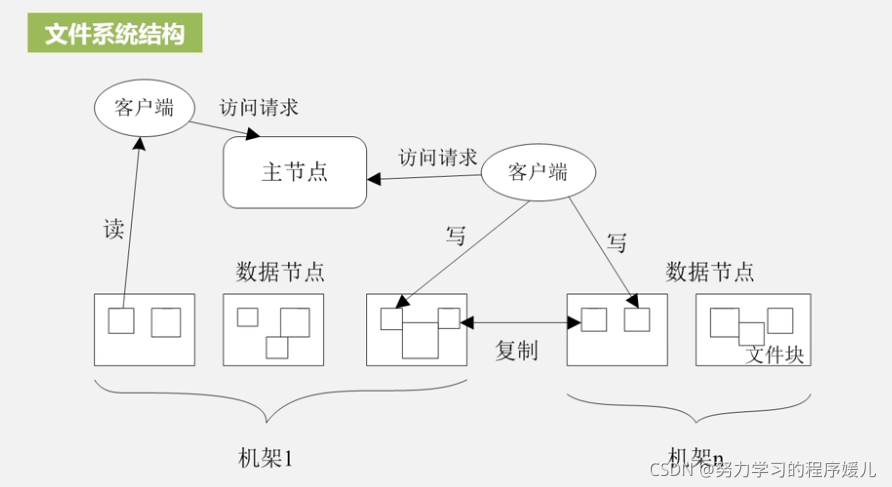
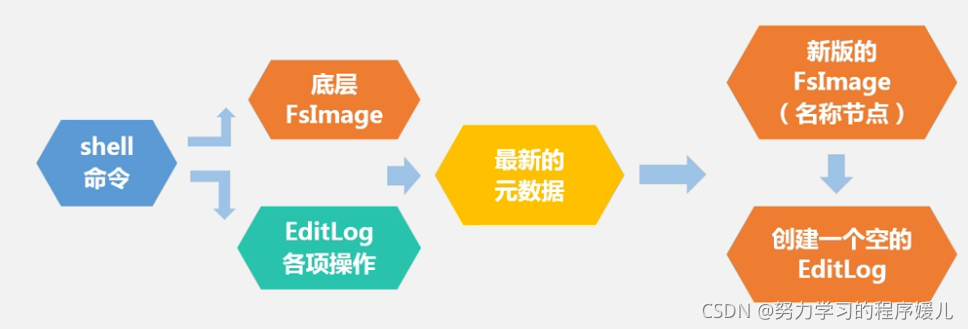
名称节点:整个HDFS集群的管家。EditLog,存储增量数据。
数据节点:存储实际数据
 HDFS的体系结构:主节点+多个数据节点构成
HDFS的体系结构:主节点+多个数据节点构成
局限性:
命名空间限制,名称节点是保存在内存中的,能够容纳的对象的个数会受到空间大小限制。
性能的瓶颈,整个分布式文件的吞吐量,受限于单个名称节点的吞吐量。
隔离问题,由于只有一个名称节点,只有一个命名空间,因此无法对不同的应用程序进行隔离。
集群的可用性:一旦名称节点发生故障,会导致整个集群不可用。
HDFS的存储原理:
1、冗余数据保存的问题
好处:加快数据的传输速度、很容易检查数据错误、保证数据可靠性
2、数据保存策略的问题
3、数据恢复的问题。
数据读取:HDFS提供了一个API可以确定一个数据节点的机架ID,客户端也可以调用API获取自己所属的机架。
读取过程:七步。
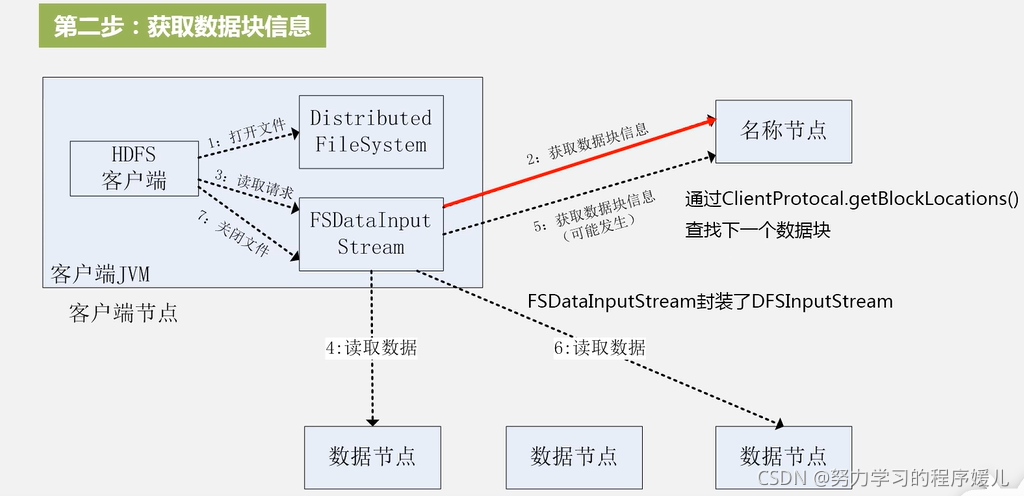
写数据过程:七步。
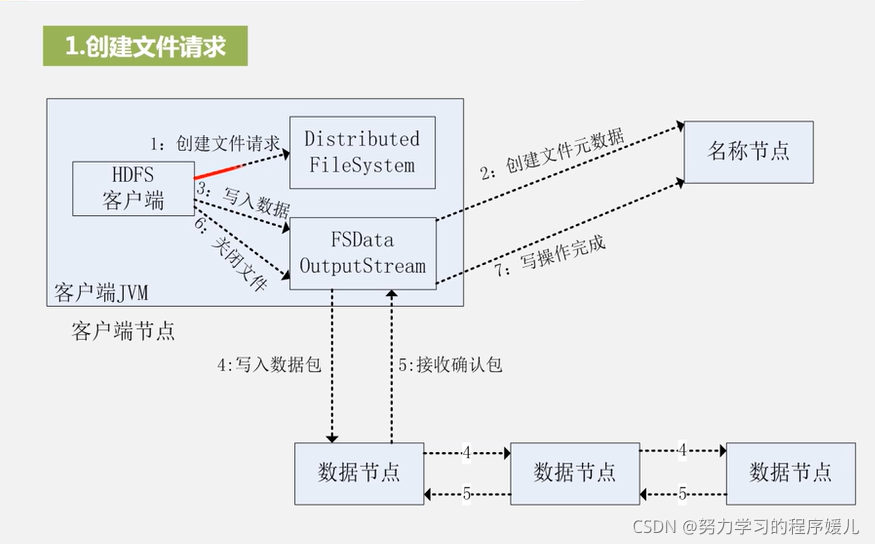
数据的错误和恢复:
名称节点出错:冷备份,暂停服务一段时间,恢复后再继续;热备份,服务不用暂停。
数据节点出错:可以调整冗余数据的位置。
数据本身出错:校验码,验证数据是否出错,出错了则需要恢复数据。















 1187
1187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









