







一、Hadoop

1.1 Hadoop是什么?
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
1.2 Hadoop组成

1.2.1 HDFS
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
1.2.2 HDFS概述

1.2.3 HDFS优缺点


1.2.4 HDFS组成框架


1.2.5 HDFS文件块


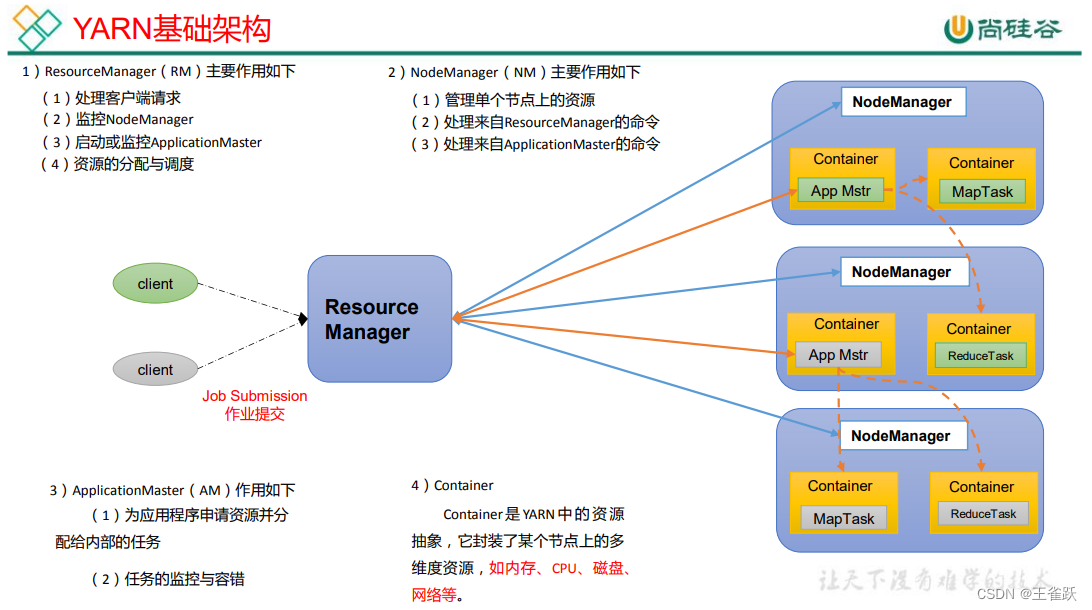
1.3.1 Yarn
Yet Another Resource Negotiator 简称 YARN ,另一种资源协调者,是 Hadoop 的资源管理器。

1.3.2 YARN架构概述
1.4.1 MapReduce
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
1)Map 阶段并行处理输入数据
2)Reduce 阶段对 Map 结果进行汇总
1.4.2 MapReduce 概述

1.4.3 MapReduce 优缺点



1.4.4 MapReduce 架构概述

1.3 HDFS、YARN、MapReduce 三者关系

二、Zookeeper(动物管理员)
![]()
2.1 概述
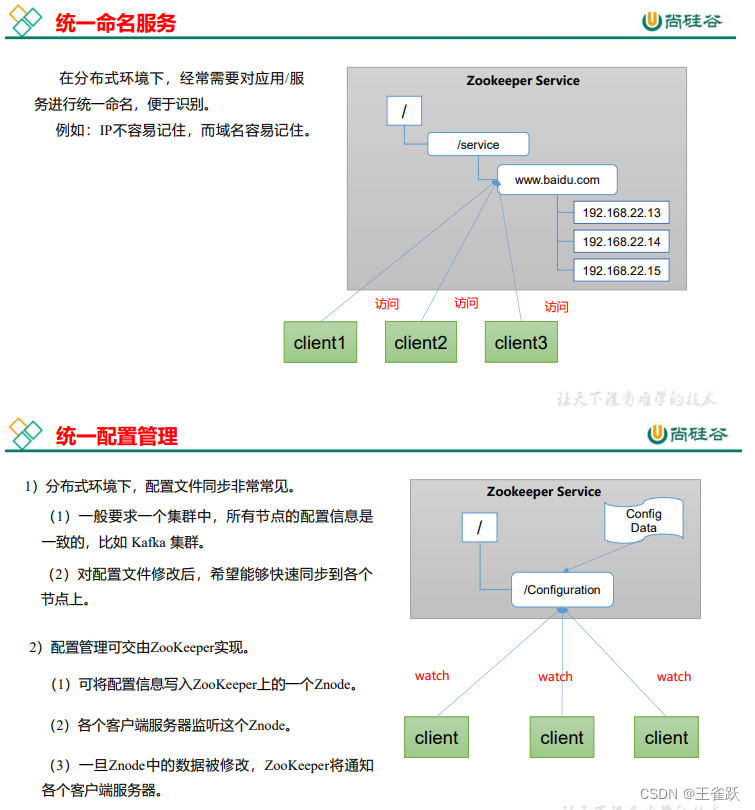
Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的 Apache 项目。
2.2 工作机制

2.3 特点

2.4 应用场景


2.5 zookeeper部分问题

三、Hive

3.1 概述(Hive 是为数据仓库而设计的)


3.2 优缺点


四、Sqoop

4.1 概述

4.2 原理

五、Scala(编程语言)

5.1 为何学Scala?

5.2 Scala特点

六、Spark(批处理数据)

6.1 什么是Spark

6.2 Spark和Hadoop关系



6.3 Spark和Hadoop如何选择


6.4 Spark核心模块


七、Flume

7.1 概述

7.2 flume架构


八、Kafka

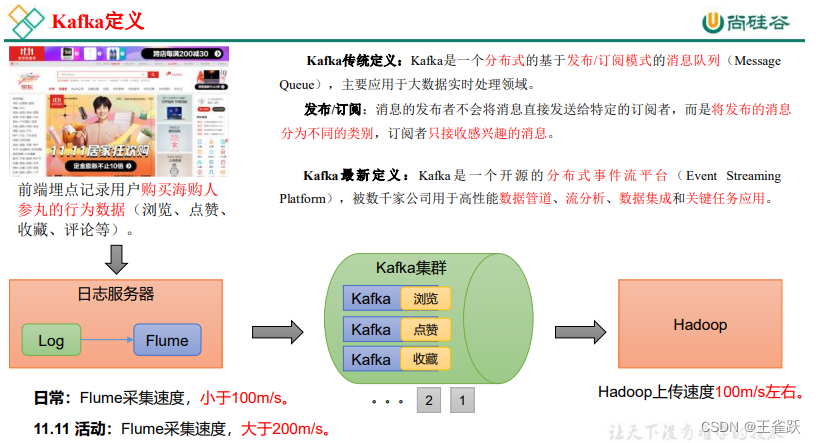
8.1 定义
8.1.1 消息队列

8.1.2 消息队列应用场景



8.1.3 消息队列模式

8.2 kafka架构

九、Flink(流式处理数据)

Flink 是 Apache 基金会旗下的一个开源大数据处理框架。
Flink 是一个大数据流处理引擎,它可以为不同的行业提供大数据实时处理的解决方案。
9.1 Flink核心特性

9.2 Flink分层Api

9.3 相较于Spark,更推荐Flink处理实时流处理

















 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











