







sklearn特征抽取API:sklearn.feature_extraction
DictVectorizer的处理对象是符号化(非数字化)的但是具有一定结构的特征数据,如字典等,将符号转成数字0/1表示。
字典特征抽取的API:sklearn.feature_extraction.DictVectorizer
DictVectorizer的语法:
DictVectorizer(sparse = True,……)
DictVectorizer.fit_transform(x)
# X :文本或者包含文本字符串的可迭代对象
# 返回值:返回sparse矩阵
DictVectorizer.inverse_transform(X)
# X:array数组或者sparse矩阵
# 返回值:转化之前的数据格式
DictVectorizer.get_feature_names()
# 返回值:单词列表
DictVectorizer.transform(x)
# 按照原先的标准转换
流程:
1.先实例化类DictVevtorizer
2.调取方法fit_transform(x)
例如,对字典:
{'city':'上海','temperature':60} {'city':'北京','temperature':100} {'city':'深圳','temperature':40}
进行特征处理。
代码如下:
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""
字典数据抽取
:return:None
"""
# 实例化
dict = DictVectorizer()
#调用 fit_transform
data = dict.fit_transform([{'city':'上海','temperature':60},
{'city':'北京','temperature':100},
{'city':'深圳','temperature':40}])
print(data)
return None
if __name__ == '__main__':
dictvec()
输出结果如下:

因为DictVectorizer(sparse = True,……) 参数sparse=True,所以默认返回得是 sparse矩阵(如上图),sparse矩阵可以节约内存,方便读取。
如果要输出数组形式,只用把将实例化时的程序改写为:
dict = DictVectorizer(sparse = False)
则输出结果如图:
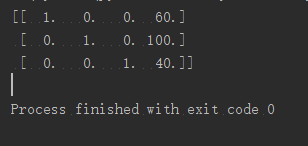
sparse矩阵就相当于把数组里面有值的地方单独写了出来。
调用 get_feature_names方法的程序为:
...
# 此属性包含在实例当中,直接调用就行
print(dict.get_feature_names())
输出结果如下
从输出结果可以直接看出,数组当中每一列的特征值是什么。
如果有什么错误的地方还希望大家在评论区给我指正,我也是在学习的过程中,一点点进步。















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









