







作用
把python中字典数据(dict)进行特征值化
类和方法
类
DictVectorizer(sparse=True)
默认为True,返回一个sparse矩阵
False,不转换为sparse矩阵
类 DictVectorizer实现了one-hot编码,将数据的特征分离,数据被分为分类属性和传统属性
eg:
data = [
{‘city’: ‘北京’,‘temperature’:100},
{‘city’: ‘上海’,‘temperature’:60},
{‘city’: ‘深圳’,‘temperature’:30},
]
城市是分类属性,温度是传统属性,经过特征抽取分类属性用0或者1表示,传统属性不变
方法
| 方法 | 作用 |
|---|---|
| fit_transform(Param) | Param:字典或者包含字典的迭代器 返回值:返回sparse矩阵 |
| inverse_transform(Param) | Parm:array数组或者sparse矩阵 返回值:转换之前的数据格式 |
| get_feature_names() | 返回值:返回分类类别的名称 |
| transform(data) | 按照之前的标准转换 |
流程
from sklearn.feature_extraction import DictVectorizer
data = [
{'city': '北京','temperature':100},
{'city': '上海','temperature':60},
{'city': '深圳','temperature':30},
]
def dictdata():
"""
字典数据抽取
:return: None
"""
# 实例化
dic = DictVectorizer(sparse=False)
# 数据转换
dat = dic.fit_transform(data)
# 数据分类名称
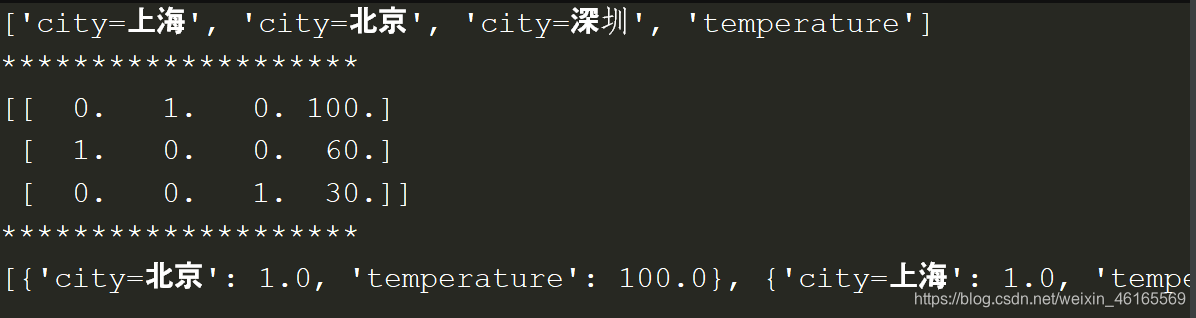
print(dic.get_feature_names())
print(dat)
# 数据回转,把数据转换为最先的未处理格式
print(dic.inverse_transform(dat))














 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









