







MIMIC-III数据集
这是师姐对MIMIC-III数据库介绍的笔记。
数据库介绍


- 一个患者对应一个subject_id,但是可能多次入院,有多个hadm_id,一次入院可能有多次进入ICU,即一个hadm_id可能对应多个icustay_id
- 通常采用一个hadm_id对应的第一个icustay_id开展相关的研究
- 字典表用于某个项的查询,举例如下:
比如查询某个患者的白细胞的数据(在LABEVENTS表中),首先需要找到患者对应的三个ID,然后在实验室检查编码(d_labitems)中找到白细胞的item_id,然后再去LABEVENTS表中查找.
26张表的详细解释

- 这张表用主要记录患者的入院情况,用的比较多的可能有患者的人口统计学信息
- 入院时间对我们采集特定时间窗口的患者信息是比较重要的,大多数研究都会用到.
- 死亡时间在对应看患者结局是会用到.
- ICUSTAY表中入科出科的时间戳也很重要;住院时长即在ICU中待的时间的长度.
- PATIENTS表中记录着患者的信息,可以与ADMISSONS综合起来使用.比如这里的死亡日期可以对前面的表做一个补充;通过入院时间和出生日期可以计算出患者的年龄.
- SERVICES和TRANSFERS可能在做一些资源配置的研究中会用到,做生理指标方面的研究时用得较少.

- CAREGIVERS用的相对较少
- CHARTEVENTS是最重要的一张表,记录的大部分是患者生命体征的数据,如心率,血压,体温等等.该表是通过患者编号\病案号和ICU编号作为联合主键确定患者.项目标志符也就是item_id,比如心率这个项目所对应的项目标识符可以在d_labitems字典中查到.记录时间和存储时间是对应该项的存储时间.记录时间可以用于筛选特定的时间窗口(比如说进入ICU24小时内的数据).要用到前面的ICUSTAYS的入科时间以及当前测量的时间做差值,从而确定研究队列.
- DATETIMEEVENTS表中主要是患者操作信息,使用相对较少.
- 两张INPUTEVENTS应组合起来使用.提供比如说患者给药的速率(如葡萄糖输入的速率),给药途径,给药部位.基于这两个表可以做一些关于给药,药物干预方面的研究
- NOTEEVENTS大部分是患者的医嘱,如患者的既往史和现病史等,再比如患者体温波动的情况等,都是通过文本形式给出的.
- OUTPUTEVENTS主要记录了患者的出量信息,比如说患者的尿量等信息,可以作为患者生命情况的表示.
- PROCEDUREEVENTS记录诸如手术开始时间,结束时间,手术操作等信息

- DIAGNOSES_ICD表中记录了患者的ICD-9诊断编码,比如说想做一些疾病诊断或疾病预测的研究时会用到.一个患者可能会对应多个诊断,所以是一个序列格式的表.可能会认为第一个是患者的主病.
- DRGCODES表中记录了患者的诊断类别和诊断编码
- LABEVENTS表中是患者的化验项目,有比如像白细胞,红细胞这种指标值.LABEVENTS,CHARTEVENTS和OUTPUTSEVENTS表合起来基本上可以代表患者进入ICU后生理指标的大部分特征.
- PRESCRIPTIONS中是患者的用药记录,和前面的INPUTEVENTS综合起来可以作为用药干预的研究
- PROCEDURE_ICD表记录的是病人的手术记录.

前面提到抽取患者的数据比如说生命体征,心率等,实验室指标(如白细胞红细胞等)等, 就需要在相应的字典中找到相应的item,即项目标识符,再对应查找某一个患者对应指标下的数据.心率,血压等指标在D_ITEMS中查找索引
数据表中的基本信息


MIMIC-III代码库
网址:https://github.com/MIT-LCP/mimic-code
https://github.com/MIT-LCP/mimic-iii-paper/

- 比较常用到的有concepts文件夹中的,记录着大部分可以获得患者生命指标的SQL代码.durations是患者出入量的信息.firstday是封装好了的获取患者第一天(即前24h)的生理指标的数据.
其它临床数据集

研究主题
在此主要是对三届Datathon的研究题目进行总结
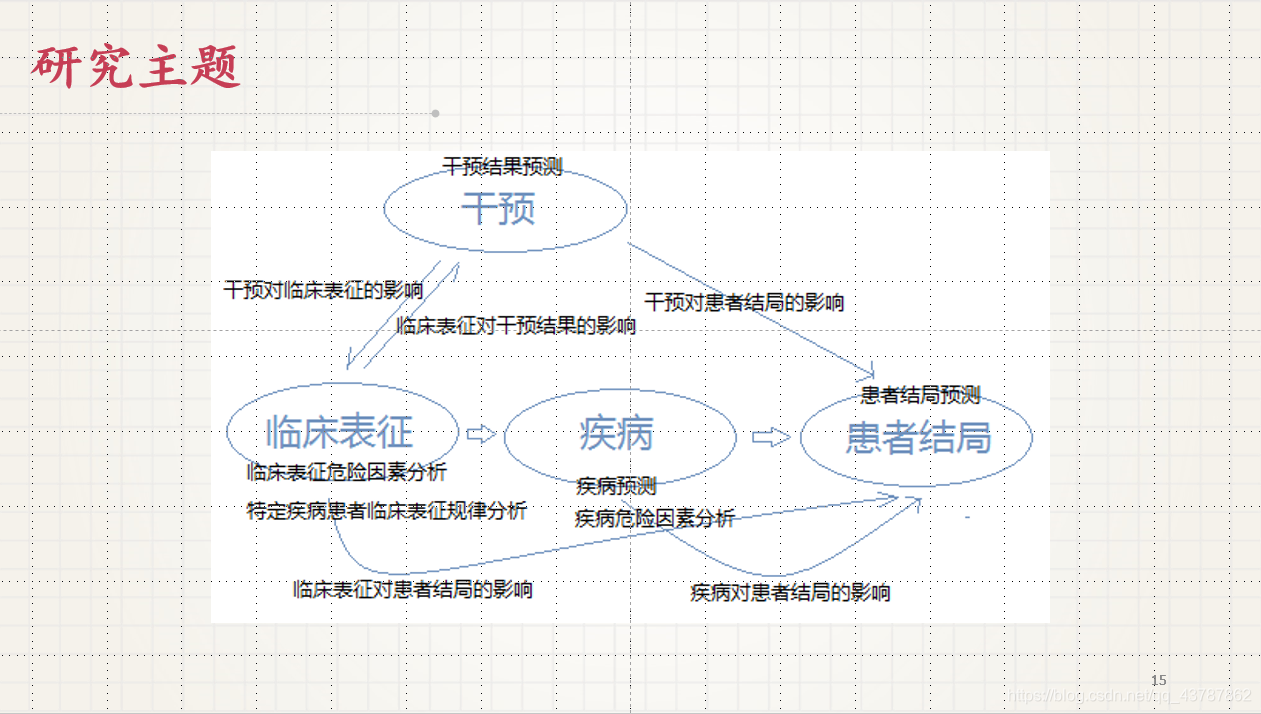
相关题目







研究基本流程梳理

师姐总结的分类任务的基本流程
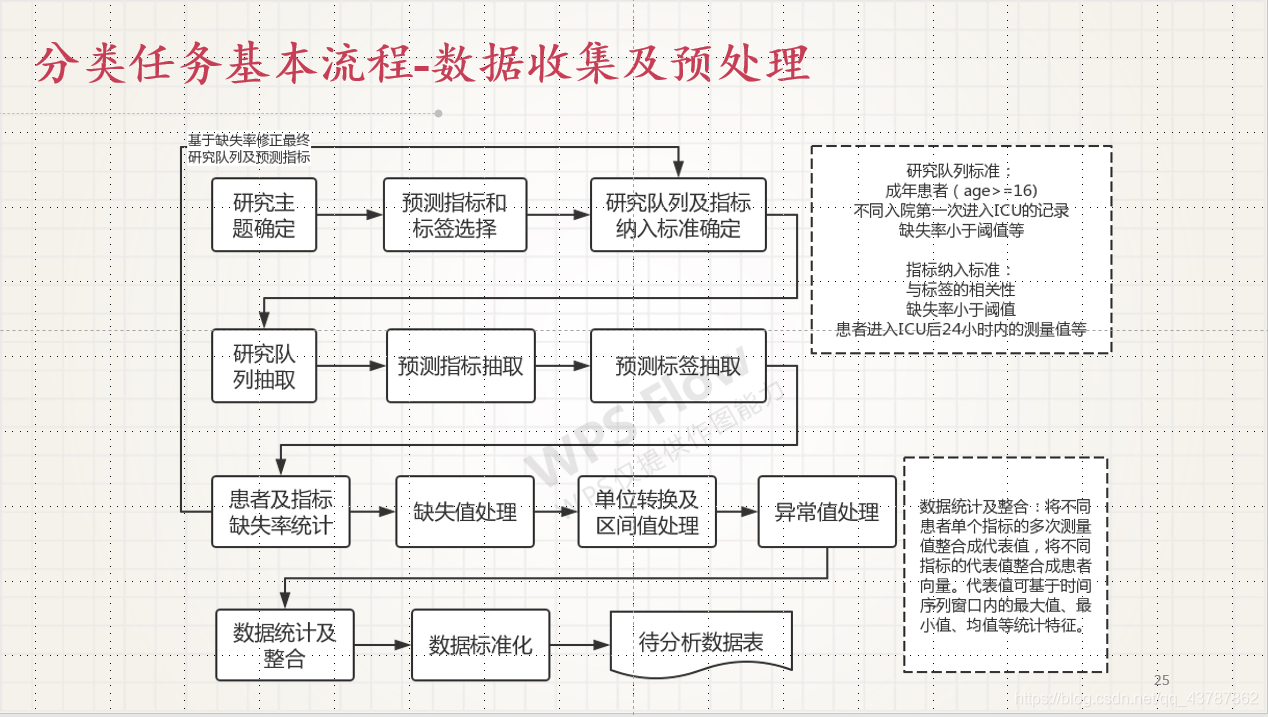
在具体的研究工作中,通常花费最多时间的还是在数据收集和预处理的过程中,模型通常还是比较现成的.
首先是研究主题的确定,比如研究患者的死亡风险预测,那么需要选择患者结局(是否死亡,什么时间死亡等指标)等,可以通过看相关论文以及和相关医生作沟通来选择预测指标;指标确定之后,就是研究队列及指标纳入标准的确定,比如说针对脓毒症的患者,那么研究队列是脓毒症的患者;一般来说会选择不同入院(hadm_id)中的第一次进入ICU的数据;患者的某个指标的数据缺失率也应被考虑在纳入指标当中(通过设定一个缺失率阈值来判断是否使用某个指标);通常选用前24h的指标.
区间值转比如说白细胞有记录是less than 5,就可以转换成2.5或采用当作缺失值的方法.单位转换比如说INPUTEVENTS_CV和INPUT_MV中可能存在单位不一致的情况,需要按照临床上一些标准进行单位转换.
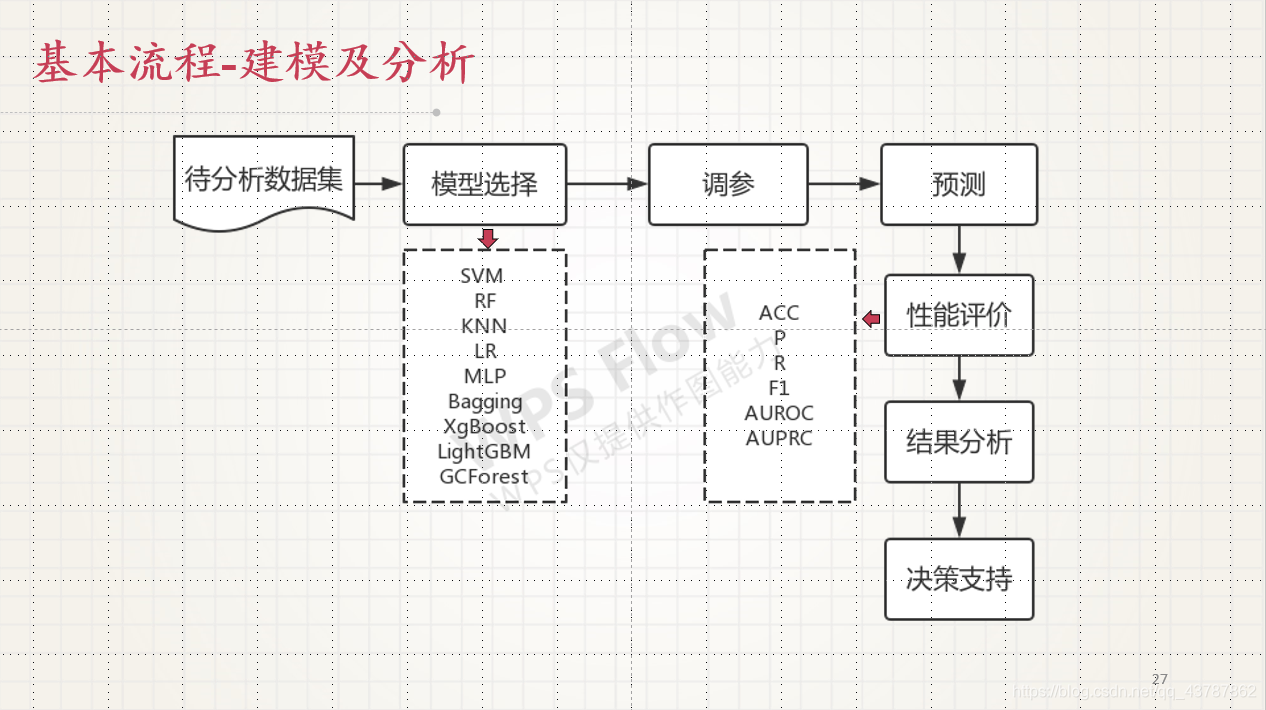

















 4338
4338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









