









一、思维导图
Hadoop三部分组成即部署时节点分布思维导图

Hadoop平台搭建流程思维导图
二、 配置虚拟机(master,联网模式:NAT)
(一) 配置系统网络设置
指令:vi /etc/sysconfig/network-scripts/ifcfg-eno34234(eno后数字每台机器不同)
修改:
BOOTROTO=static//将IP修改为静态配置
ONBOOT=yes//是否开机启动网卡
删除:UUID(统一标识符)//UUID:通用唯一识别码
增加:
a) IPADDR=192.168.87.20(前三段数字随网关而定,最后一段自定义)
b) GATEWAY=192.168.87.2(VM虚拟网络编辑器中NAT网卡的网关)
c) PREFIX=24(配置子网掩码,这里的24是指子网掩码数值转换成二进制后的个数;可用NETMASK=255.255.255.0)

配置完毕后使用指令:systemctl restart network.service进行刷新
(二) 关闭系统防火墙
查看防火墙状态:sudo systemctl status firewalld
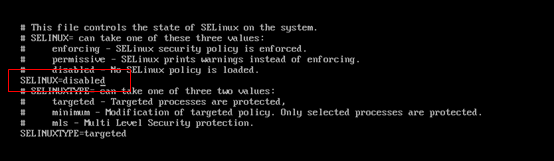
关闭防火墙Vi /etc/sysconfig/selinux :将SELINUX改为禁用(disabled),如图
关闭防火墙:systemctl stop firewalld service
防火墙开机禁用:systemctl diable firewalld
配置完毕后使用reboot指令重新启动
三、 配置环境变量
(一) 前期准备
目录:/opt
建立:新建两个文件夹(一个放压缩包,一个放解压缩):mkdir xx(file)
放入:使用secureCRT将JDK、Hadoop压缩包拖进新建立的文件夹中
解压:tar -zxf+文件路径 -C 存放路径


(二) 在系统中配置java环境变量
编辑profile文件,配置JAVA环境变量:vi /etc/profile
在profile最后添加(可用shift+g定位到文件末尾)
export JAVA_HOME=/opt/after_hadoop/jdk1.8.0_171
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
JAVA_HOME的路径,修改为解压缩后jdk的位置(可使用pwd指令进行查看其路径)
 让修改的内容立即生效:source /etc/profile,如果依旧无效就进行重启操作(reboot/shutdown now)(在重启之前可使用sync指令,此作用为将缓存区的文件强制存进硬盘)
让修改的内容立即生效:source /etc/profile,如果依旧无效就进行重启操作(reboot/shutdown now)(在重启之前可使用sync指令,此作用为将缓存区的文件强制存进硬盘)
检验:java -version

(三) 在系统中配置Hadoop环境变量
关联Hadoop与JAVA:修改hadoop-env.sh(位于hadoop文件中etc目录中)

可使用echo $JAVA_HOME获取jdk路径
(echo和pwd之间的区别:echo &xxxx 直接可获取存储文件路径;pwd 也可以获取文件存储路径,但需cd 到相应的路径,才能够获取。)
配置Hadoop环境变量(HADOOP_HOME):vi /etc/profile中在末尾(vi中使用shift+g到内容末尾)添加Hadoop文件夹的路径(pwd获取)
在profile末尾添加:
export HADOOP_HOME=/opt/after_hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
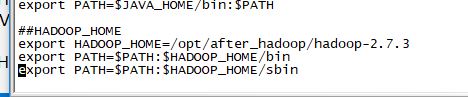
使用source /etc/profile让修改的内容立即生效
四、 完全分布式部署Hadoop
(一) 前期准备
- 建立;新建用户admin**(useradd admin**/passwd admin)
- 赋予其root权限:
指令:visudo,进入文件后可使用/root进行搜索
添加:admin ALL=(ALL) ALL(在root 用户之后进行添加)
.
- 更改:
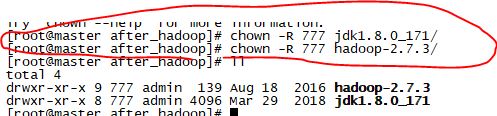
将Hadoop、java文件目录的所有权交给admin:chown -R +用户名:用户组 文件夹路径

将该两文件夹权限进行设置:chmod -R 777 +文件路径(777:表示所有用户都可读可写可执行)
- 设置三台节点之间的映射,即让其互相通信
指令:vi /etc/hosts
ip设置:将三台机器ip地址及名字添加,ip地址系用户自定义,但要与每台机器对应

添加名字;在hadoop下的etc文件中的slaves文件中添加三台机器的名字

(二) 配置三个site.xml文件三个-env.sh文件和core-site.xml文件
- 核心文件
vi core-site.xml:配置通用属性
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/after_hadoop/hadoop-2.7.3/data/tmp</value> </property> </configuration>

2.分布式存储-HDFS
vi hdfs-site.xml:配置HDFS属性
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.sendary.http-address</name>
<value>slave2:50090</value>
</property>
</configuration>

4. 分布式调度-Yarn
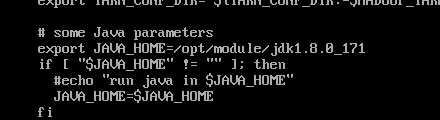
vi yarn-env.sh
在vi编辑器中使用/JAVA_HOME进行搜索,将jdk地址添加
vi yarn-site.xml:配置yarn的属性
获取数据的方式:套用万能模板就ok
<configuration>
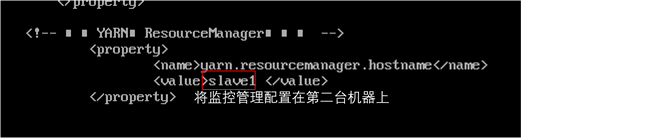
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

指定resource manager地址

- 分布式计算-Mapreduce
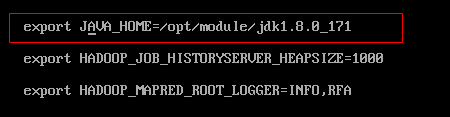
vi mapred-env.sh:
使用pwd获取jdk位置并添加至此文件JAVA_HOME中
vi mapred-site.xml
由于当前目录中无mapred-site.xml文件,所以使用复制并重命名口令生成一份所需文件

指令:mv mapred-site.xml.template mapred-site.xml

在mapred-site.xml文件中将mapreduce与yarn进行绑定
<configuration>
<!-- 指定mapreduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

(三) 克隆虚拟机并使其相互建立联系
-
克隆虚拟机并修改为对应ip
分别命名为master、slave1、slave2:vi /etc/hostname
将前设定的ip进行对应修改:vi /etc/sysconfig/network-scripts/ifcfg-ensxxxxxx(x为数字,此不定可用tab键进行自动填充) -
设置三台机器的通讯密码(su admin/不可用root用户进行操作)
master(第一台机器)
a) 生成ssh密钥:ssh-keygen -t rsa
b) 将生成的密钥复制给所有的机器:ssh-copy-id+ip(此处复制包含master slave1 slave2三台机器/包含本机)
c) 退出:exit slave2(第二台机器)
a) 即生成ssh密钥:ssh-keygen -t rsa
b) 将生成的密钥复制给所有的机器:ssh-copy-id+ip(此处复制包含master slave1 slave2三台机器/包含本机)
c) 退出:exit slave3(第一台机器)
a) 即生成ssh密钥:ssh-keygen -t rsa
b) 将生成的密钥复制给所有的机器:ssh-copy-id+ip(此处复制包含master slave1 slave2三台机器/包含本机)
c) 退出:exit
(四) 启动Hadoop平台(如果集群是第一次启动,需要格式化namenode)
- 启动HDFS
位置:master
a) 初始化命令:bin/hdfs namenode -format
b) 启动hadoop命令:sbin/start-dfs.sh
c) 查看进程指令:jps - 启动yarn
位置:在配置l额resource manager监控管理的机器上,此处是slave1
a) 启动指令:sbin/start-yarn.sh
b) 查看进程:jps















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









