









很多读者在观看JVM相关的书籍时会看到SymbolTable和StringTable,书中的三言二语介绍的不是很清楚,并且读者的水平有限,导致无法理解SymbolTable和StringTable。所以特意写此篇图文并茂的文章来彻底理解SymbolTable和StringTable这两张表。
版本信息如下:
jdk版本:jdk8u40因为Hotspot是c++构成,所以也存在面向对象的思想,也即存在类和对象,所以直接看到SymbolTable和StringTable的类定义即可。src/share/vm/classfile/symbolTable.hpp 文件中
// key为Symbol,value为mtSymbol
class SymbolTable : public Hashtable<Symbol*, mtSymbol> {
friend class VMStructs;
friend class ClassFileParser;
// The symbol table
static SymbolTable* _the_table;
}// key为oop,value为mtSymbol
class StringTable : public Hashtable<oop, mtSymbol> {
friend class VMStructs;
// The string table
static StringTable* _the_table;
}可以非常清楚的看到2者都继承了Hashtable,也更加肯定2者就是一张表。而Hashtable可以理解为Java中HashMap结构(数组+链表+特定条件下的红黑树)。而谈到map结构一定会出现key,value的映射关系。
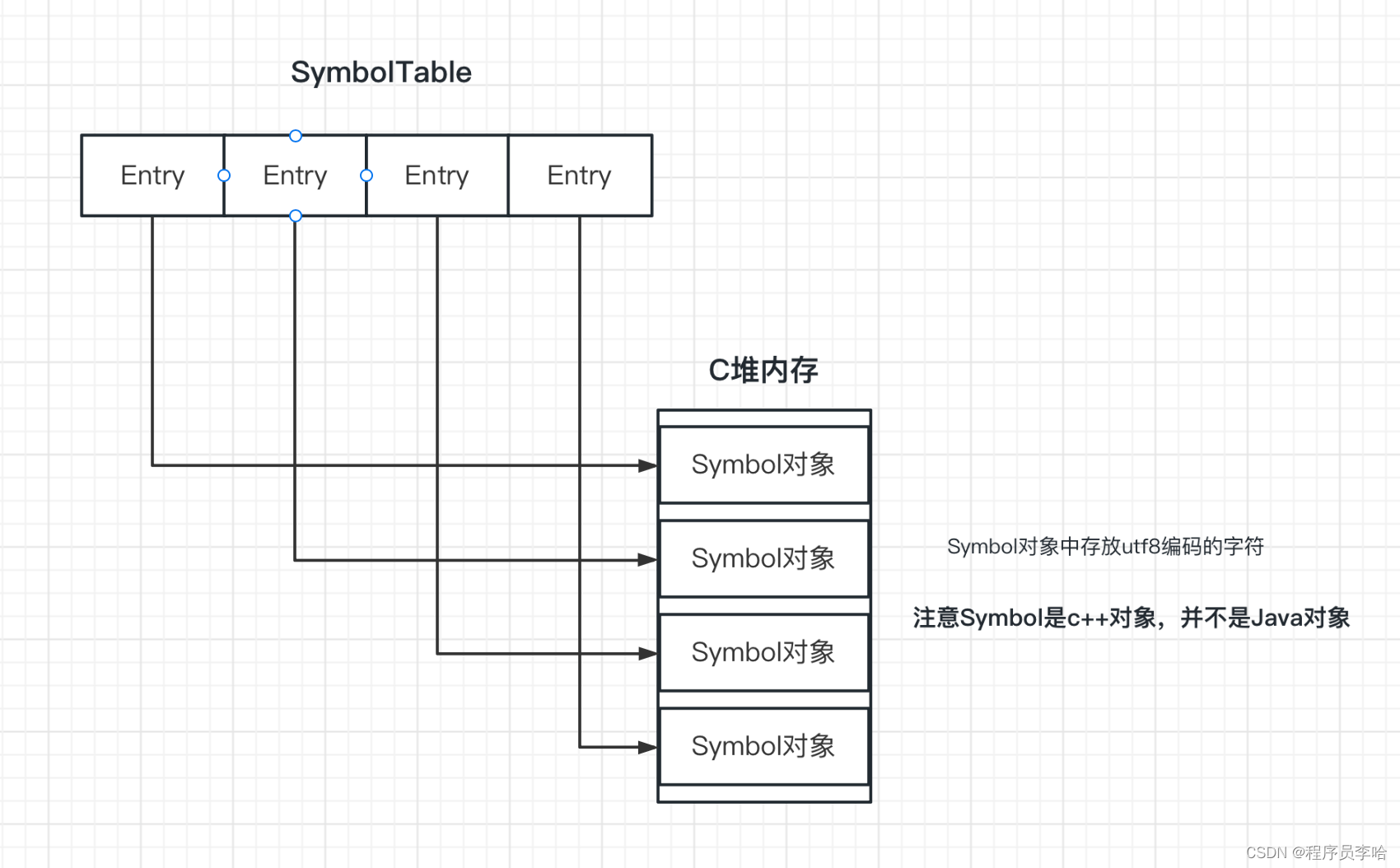
SymbolTable:key是Symbol,Symbol可以理解为utf8编码的字符信息
SymbolTable:value是mtSymbol,这是一个枚举值,仅仅表示内存的解释,不起实际作用
——————————————————————
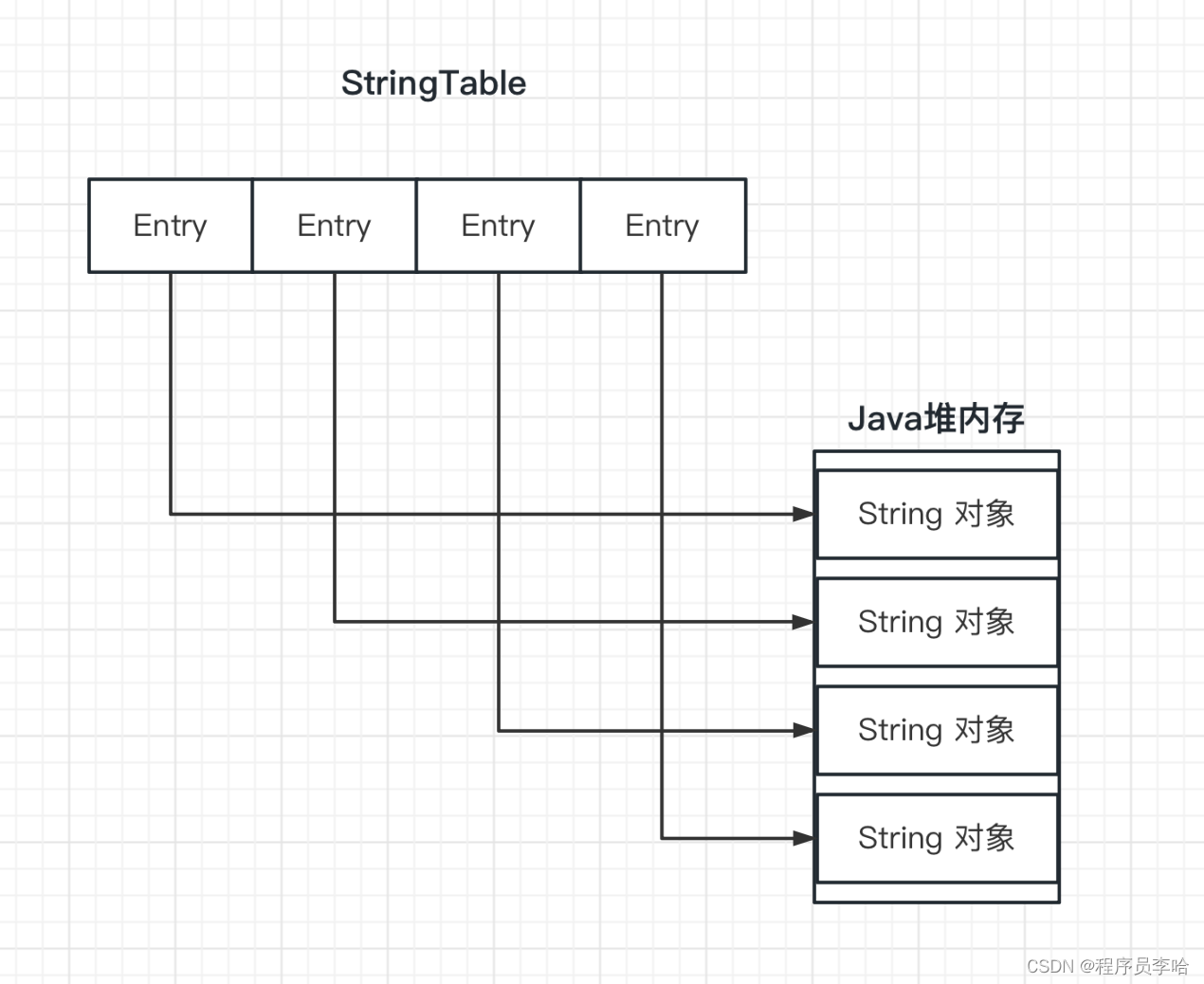
StringTable:key是oop,oop可以理解为Java对象地址(实际上存放的就是Java的String对象)
StringTable:value是mtSymbol,这是一个枚举值,仅仅表示内存的解释,不起实际作用
既然已经明白SymbolTable和StringTable的大致作用了,那么下面就是源码查看如何使用。
SymbolTable使用
从上文,我们清楚明白SymbolTable中存放的是Symbol对象,而Symbol对象存放的是utf8编码的字符。所以utf8编码的字符来自何处呢?
下面从一个很简单的例子来分析
public class demo{
public static void main(String[] args) {
System.out.println("123");
}
}简单的查看一下字节码的表示
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #18 // 123
#4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #21 // demo
#6 = Class #22 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 main
#12 = Utf8 ([Ljava/lang/String;)V
#13 = Utf8 SourceFile
#14 = Utf8 demo.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = Class #23 // java/lang/System
#17 = NameAndType #24:#25 // out:Ljava/io/PrintStream;
#18 = Utf8 123
#19 = Class #26 // java/io/PrintStream
#20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V
#21 = Utf8 demo
#22 = Utf8 java/lang/Object
#23 = Utf8 java/lang/System
#24 = Utf8 out
#25 = Utf8 Ljava/io/PrintStream;
#26 = Utf8 java/io/PrintStream
#27 = Utf8 println
#28 = Utf8 (Ljava/lang/String;)V
{
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String 123
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 4: 0
line 5: 8
}
SourceFile: "demo.java"
可以看到字节码常量池中存在很多Utf8的字段,那是不是这些常量池中Utf8的字段会解析成Symbol对象呢?抱着疑问,我们看到Hotspot中解析字节码常量池的源码。src/share/vm/classfile/classFileParser.cpp 文件中。
void ClassFileParser::parse_constant_pool_entries(int length, TRAPS) {
// 解析常量池,从下标#1开始
for (int index = 1; index < length; index++) {
// 拿到下标对应的tag,比如拿到Utf8、Class、String、NameAndType等等....
u1 tag = cfs->get_u1_fast();
// 根据一个字节的tag区分后续。
switch (tag) {
…………
// 省略了其他tag的解析,我们只关心Utf8的解析。
case JVM_CONSTANT_Utf8 :
{
cfs->guarantee_more(2, CHECK); // utf8_length
// 根据长度解析
u2 utf8_length = cfs->get_u2_fast();
u1* utf8_buffer = cfs->get_u1_buffer();
unsigned int hash;
// 从SymbolTable中尝试获取,如果存在就直接获取,如果不存在就创建。
Symbol* result = SymbolTable::lookup_only((char*)utf8_buffer, utf8_length, hash);
if (result == NULL) {
names[names_count] = (char*)utf8_buffer;
lengths[names_count] = utf8_length;
indices[names_count] = index;
hashValues[names_count++] = hash;
// 把Symbol添加到SymbolTable中
// 因为在常量池中最多的就是Utf8项,所以为了优化,这里采用批处理
// 如果当前常量池中Utf8项数量每8的倍数就一次性插入一轮。
if (names_count == SymbolTable::symbol_alloc_batch_size) {
SymbolTable::new_symbols(_loader_data, _cp, names_count, names, lengths, indices, hashValues, CHECK);
names_count = 0;
}
} else {
// 添加到常量池中。
_cp->symbol_at_put(index, result);
}
}
break;
default:
classfile_parse_error(
"Unknown constant tag %u in class file %s", tag, CHECK);
break;
}
}
// 把Symbol添加到SymbolTable中
// 如果没有批处理,那终究还是得插入。
if (names_count > 0) {
SymbolTable::new_symbols(_loader_data, _cp, names_count, names, lengths, indices, hashValues, CHECK);
}
}这里解析Utf8项,拿到Utf8的值,上文字节码常量池第#18项的 123 ,尝试去SymbolTable中拿到123对应的Symbol,如果不存在就创建Symbol对象并添加到SymbolTable,如果存在就直接获取Symbol对象放入到常量池对象中。
除了常量池第#18项,还有第#21、#22、#23、#24、#25...... 众多Utf8项。并且其他常量池项最终都是指向到Utf8项,所以也能看明白Utf8项或者说Symbol的作用是啥了。存放类名、字符串数据、方法签名、方法名。一言以蔽之:Utf8项最终会解析成Symbol,而Symbol存放Java程序中所需的元数据、真实数据。而SymbolTable作为一个载体存放所有的Symbol
StringTable使用
还是使用SymbolTable的案例。
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // 把2号常量池的静态变量押入操作数栈
3: ldc #3 // 把3号常量池的字符串解析成String对象,并且押入操作数栈
5: invokevirtual #4 // 执行4号常量池的方法,并且消耗2个操作数栈
8: return
LineNumberTable:
line 4: 0
line 5: 8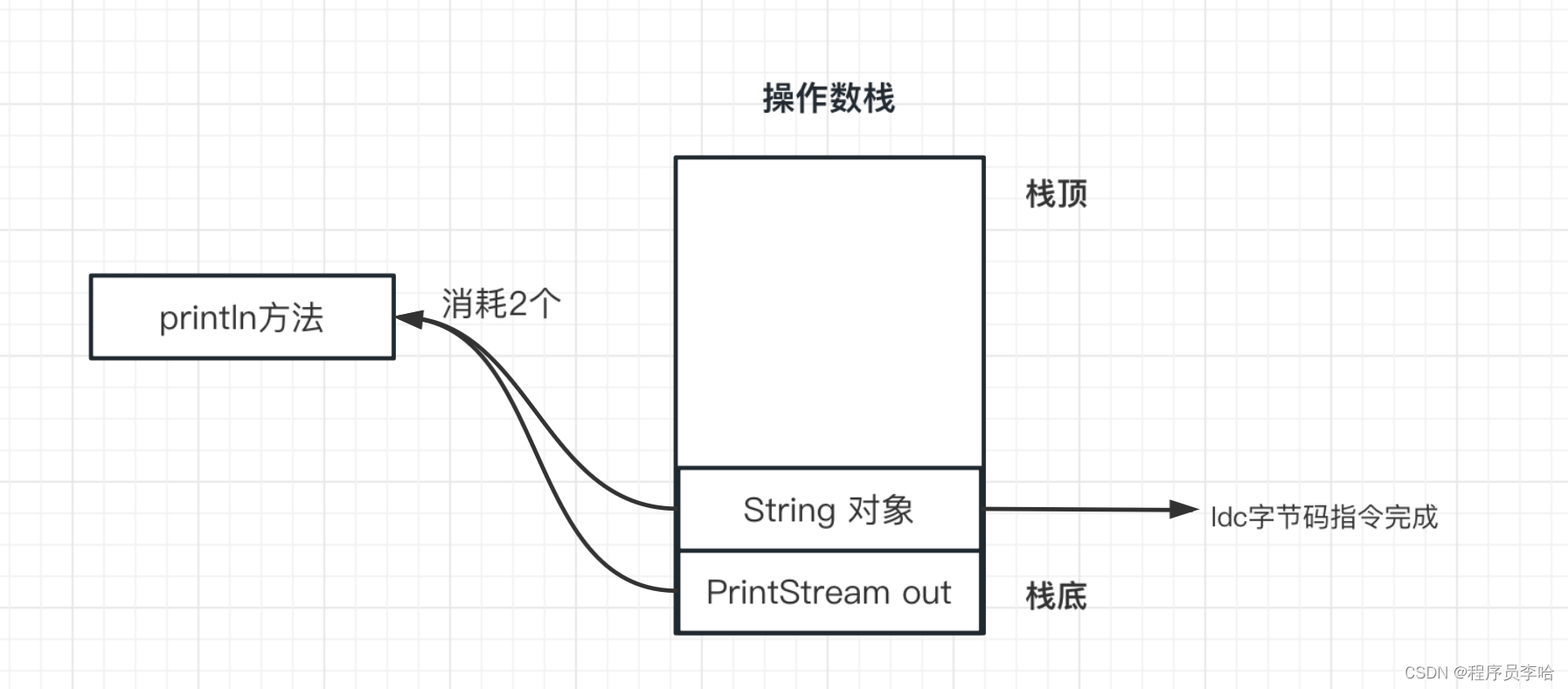
所以,我们需要去源码论证ldc字节码指令如何创建出String对象。这里为了源码简单,使用C++字节码解释器作为了论证。src/share/vm/interpreter/bytecodeInterpreter.cpp 文件
CASE(_ldc):
{
…………
省略其他的处理
ConstantPool* constants = METHOD->constants();
switch (constants->tag_at(index).value()) {
…………
省略其他的处理
case JVM_CONSTANT_String:
{
// 从常量池的对象池中拿对象
oop result = constants->resolved_references()->obj_at(index);
// 如果不存在
if (result == NULL) {
// 解析ldc,生成String对象。
CALL_VM(InterpreterRuntime::resolve_ldc(THREAD, (Bytecodes::Code) opcode), handle_exception);
// 线程变量是可以在线程中任意地方存取,并且线程安全。
// 这里把String对象添加到操作数栈中
SET_STACK_OBJECT(THREAD->vm_result(), 0);
THREAD->set_vm_result(NULL);
} else { // 如果存在就直接添加到操作数栈中。
VERIFY_OOP(result);
SET_STACK_OBJECT(result, 0);
}
break;
}
…………
省略其他的处理
}
UPDATE_PC_AND_TOS_AND_CONTINUE(incr, 1);
}继续往InterpreterRuntime::resolve_ldc 方法看
IRT_ENTRY(void, InterpreterRuntime::resolve_ldc(JavaThread* thread, Bytecodes::Code bytecode)) {
assert(bytecode == Bytecodes::_fast_aldc ||
bytecode == Bytecodes::_fast_aldc_w, "wrong bc");
ResourceMark rm(thread);
methodHandle m (thread, method(thread));
Bytecode_loadconstant ldc(m, bci(thread));
// 解析
oop result = ldc.resolve_constant(CHECK);
thread->set_vm_result(result);
}
IRT_END
oop Bytecode_loadconstant::resolve_constant(TRAPS) const {
assert(_method.not_null(), "must supply method to resolve constant");
int index = raw_index();
ConstantPool* constants = _method->constants();
// 解析
return constants->resolve_constant_at(index, THREAD);
}
oop ConstantPool::resolve_constant_at_impl(constantPoolHandle this_oop, int index, int cache_index, TRAPS) {
oop result_oop = NULL;
Handle throw_exception;
int tag_value = this_oop->tag_at(index).value();
switch (tag_value) {
…………
省略其他的处理
case JVM_CONSTANT_String:
// 拿到String对象
result_oop = string_at_impl(this_oop, index, cache_index, CHECK_NULL);
break;
…………
省略其他的处理
}
…………
省略其他的处理
return result_oop;
}
oop ConstantPool::string_at_impl(constantPoolHandle this_oop, int which, int obj_index, TRAPS) {
// 从常量池中的对象池中尝试拿到缓存对象。
oop str = this_oop->resolved_references()->obj_at(obj_index);
if (str != NULL) return str;
// 拿到ldc指向常量池下标最终对应的Utf8项
// 而从上文讲述的SymbolTable可以得知,Utf8项在JVM中使用Symbol对象表示。
// 所以这里拿到Symbol对象,而拿到Symbol对象,就拿到了具体数据
Symbol* sym = this_oop->unresolved_string_at(which);
// 尝试从StringTable中拿到String对象,如果存在就返回,如果不存在就创建并返回。
str = StringTable::intern(sym, CHECK_(NULL));
// 把对象添加到常量池中的对象池中
this_oop->string_at_put(which, obj_index, str);
return str;
}由于调用栈比较深,所以这里对以上的代码做一个总结:
- 拿到 ldc 字节码指令指向常量池的代表,拿案例来说,也即拿到下标#3,也即拿到常量池String项
- String项指向下标#18 Utf8项
- 而从上文讲述的SymbolTable可以得知,Utf8项在JVM中使用Symbol对象表示。所以这里拿到Symbol对象,而拿到Symbol对象,就拿到了具体数据,也即拿到具体数据 123
- 拿到Symbol对象后会调用StringTable::intern方法,所以下文继续关注此方法
oop StringTable::intern(Symbol* symbol, TRAPS) {
if (symbol == NULL) return NULL;
ResourceMark rm(THREAD);
int length;
// 把utf8字符串转换成unicode编码。
jchar* chars = symbol->as_unicode(length);
Handle string;
oop result = intern(string, chars, length, CHECK_NULL);
return result;
}
oop StringTable::intern(Handle string_or_null, jchar* name,
int len, TRAPS) {
// 上文得知,StringTable就是一张hash表。所以这里计算下标。
unsigned int hashValue = hash_string(name, len);
int index = the_table()->hash_to_index(hashValue);
oop found_string = the_table()->lookup(index, name, len, hashValue);
// 命中缓存,直接返回
if (found_string != NULL) return found_string;
// 因为没有命中缓存,所以需要创建一个String对象,并且添加到StringTable中
// 在Java堆创建一个String对象。
string = java_lang_String::create_from_unicode(name, len, CHECK_NULL);
// 把创建出来的String对象,添加到StringTable中。
return the_table()->basic_add(index, string, name, len,
hashValue, CHECK_NULL);
}这里就非常明显了,把Symbol对象中的值拿出来,然后去StringTable中尝试命中缓存,如果命中就直接返回。如果没有命中就创建Java的String对象并添加到StringTable中。
所以,一言以蔽之:StringTable 管理了多个Java中String对象。而这些String对象是根据常量池String项对应的Utf8项(Symbol)生成的
SymbolTable和StringTable区别
从上文对SymbolTable和StringTable的介绍完全可以得知,这两张表的职责完全不一样。SymbolTable是存储Java项目中元数据、真实数据。而StringTable是储存Java中String对象。
硬要说有点关联的话,就是StringTable的数据来源于SymbolTable。
















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











