







文章目录
代码来源: 使用pytorch搭建AlexNet并训练花分类数据集
一、代码结构
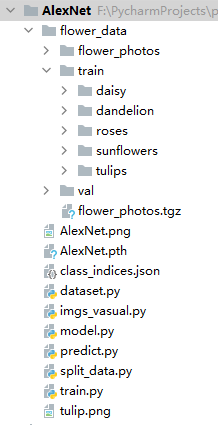
二、数据集的处理
2.1 数据集的下载和切分:split_data.py
"""
视频教程:https://www.bilibili.com/video/BV1p7411T7Pc/?spm_id_from=333.788
flower数据集为5分类数据集,共有 {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4} 5个分类。
该程序用于将数据集切分为训练集和验证集,使用步骤如下:
(1)在"split_data.py"的同级路径下创建新文件夹"flower_data"
(2)点击链接下载花分类数据集 http://download.tensorflow.org/example_images/flower_photos.tgz
(3)解压数据集到flower_data文件夹下
(4)执行"split_data.py"脚本自动将数据集划分为训练集train和验证集val
切分后的数据集结构:
├── split_data.py
├── flower_data
├── flower_photos.tgz (下载的未解压的原始数据集)
├── flower_photos(解压的数据集文件夹,3670个样本)
├── train(生成的训练集,3306个样本)
└── val(生成的验证集,364个样本)
"""""
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
data_path = os.path.join(cwd, "flower_data/flower_photos/flower_photos")
data_root=os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_path, "")
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()
2.2 数据集的加载:dataset.py
import os
import json
import torch
from torchvision import transforms, datasets
def dataset(batch_size):
train_path = "flower_data/train"
val_path = "flower_data/val"
assert os.path.exists(train_path), "{} path does not exist.".format(train_path)
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
"""
数据预处理,训练集做随机裁剪和随机翻转用来数据增强
RandomResizedCrop(224) 表示先随机裁剪为不同的大小和宽高比,然后缩放为(224,224)大小
RandomHorizontalFlip() 表示随机水平翻转(即左右翻转),默认概率为 0.5
"""
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
"""
torchvision.datasets.ImageFolder 适用于加载特定存储格式的数据集,具体使用可参考博客:
https://blog.csdn.net/qq_39507748/article/details/105394808
"""
train_dataset = datasets.ImageFolder(root=train_path,transform=data_transform["train"])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size,
shuffle=True, num_workers=nw)
validate_dataset = datasets.ImageFolder(root=val_path, transform=data_transform["val"])
valid_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size,
shuffle=True, num_workers=nw)
train_num = len(train_dataset)
val_num = len(validate_dataset)
print(f"using {train_num} images for training, {val_num} images for valid.")
flower_class_id = train_dataset.class_to_idx
# 按照不同分类数据集的排列顺序获得 train_dataset中图片对应的分类,得到字典格式:
# {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflower': 3, 'tulips': 4}
# 雏菊 蒲公英 玫瑰 向日葵 郁金香
# class_to_idx属性是通过.ImageFolder() 方法加载数据集才有的,并不是所有dataset都有该属性
cla_dict = dict((val, key) for key, val in flower_class_id.items())
# 将 dict中的 key和 value互换:
# {0: 'daisy', 1: 'dandelion', 2: 'roses', 3: 'sunflowers', 4: 'tulips'}
json_str = json.dumps(cla_dict, indent=4)
"""
json.dumps() 将 python对象转换成 json对象,生成一个字符串。
indent=4 表示缩进4个空格,方便阅读。
json_str的内容为:
{
"0": "daisy",
"1": "dandelion",
"2": "roses",
"3": "sunflowers",
"4": "tulips"
}
"""
# 将字符串写入json文件,便于predict时使用。python只能将字符串格式的数据写入文件。
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
return train_loader,valid_loader,val_num
2.3 数据集图片可视化:imgs_vasual.py
"""
图片可视化函数,用于imshow多张图片,并输出每张图片对应的label
"""""
import os
import torch
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
def imgs_imshow(batch_size):
# 产生数据集迭代器
train_path = "flower_data/train"
assert os.path.exists(train_path), "{} path does not exist.".format(train_path)
tramsform=transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_dataset = datasets.ImageFolder(root=train_path, transform=tramsform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size,
shuffle=True, num_workers=0)
# windows中只能设置 num_workers=0,即单个线程处理数据集。Linux系统中可以设置多个 num_workers
data_iter = iter(train_loader)
image, label = data_iter.next() # 每次产生batch_size张图片
# 产生图片和对应 label
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
print(' '.join('%5s' % cla_dict[label[j].item()] for j in range(batch_size)))
img = utils.make_grid(image) # make_grid() 用于将多张图像拼成一张
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
if __name__ == '__main__':
imgs_imshow(batch_size=6)
三、AlexNet介绍及网络搭建:model.py
3.1 AlexNet网络结构

本程序中输入图片的尺寸是 224*224,输出为5分类而不是1000分类,其他数据均为图中的数据。
3.2 AlexNet网络的亮点
(1)首次利用GPU进行网络加速训练,作者用了两块GPU进行并行训练。
(2)使用了ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数。
(3) 使用了LRN局部响应归一化(Local Response Normalization)。本程序中没有用LRN,因为这个方法现在已经用的很少了。
(4)在全连接层的前两层中使用了Dropout随机失活神经元操作,以减少过拟合。
3.3 网络搭建
import torch.nn as nn
"""
本程序中没有使用LRN归一化,因为这个方法现在已经用的很少了。
"""
class AlexNet(nn.Module):
def __init__(self,class_num=1000,init_weights=False):
super(AlexNet,self).__init__()
self.dropout=0.1
# 提取图像特征
self.features=nn.Sequential(
nn.ZeroPad2d((2, 1, 2, 1)),
# nn.ZeroPad2d 的填充顺序是左右上下
nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4),
# 图像数据通道存储顺序为 [N,C,H,W],即[batch_size,channels,height,weight]
# input[bsz,3, 224, 224] output[bsz,96, 55, 55]
# output_size=(W-K+P)/S+1,其中W*W是输入图像尺寸,K是kernel_size,P是padding的行/列数量,S是stride
nn.ReLU(inplace=True),
# inplace=True 表示对上一层的数据进行修改,用新数据覆盖旧数据,不存储旧数据,可以节省内存。默认值为 inplace=False
# 激活函数不改变数据尺寸
nn.MaxPool2d(kernel_size=3,stride=2), # output[bsz, 96, 27, 27]
# pooling层不改变channel,只改变H和W
nn.Conv2d(96,256,kernel_size=5,padding=2), # output[bsz, 256, 27, 27]
# padding=2 表示四边都 padding 两行或两列 0 像素值
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2), # output[bsz, 256, 13, 13]
nn.Conv2d(256,384,kernel_size=3,padding=1), # output[bsz, 384,13,13]
nn.ReLU(inplace=True),
nn.Conv2d(384,256,kernel_size=3,padding=1), # output[bsz, 256,13,13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2), # output[bsz, 256,6,6]
)
# 分类器,在全连接层的前两层使用了 dropout
self.classifier=nn.Sequential(
nn.Dropout(p=self.dropout),
nn.Linear(in_features=9216,out_features=4096), # input[bsz,9216] output[bsz,4096]
nn.ReLU(inplace=True),
nn.Dropout(p=self.dropout),
nn.Linear(in_features=4096, out_features=4096), # output[bsz,4096]
nn.ReLU(inplace=True),
nn.Linear(in_features=4096, out_features=class_num), # output[bsz,class_num]
)
# 初始化权重参数
if init_weights:
self._initialize_weights()
def forward(self,x):
x=self.features(x)
x=x.view(-1,256*6*6)
x=self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) # 用正态分布N(0,0.01)对weight初始化
nn.init.constant_(m.bias, 0) # 将bias初始化为0
"""
_initialize_weights()方法的解释:
self.modules(): Returns an iterator over all modules in the network,即遍历网络中的所有层,并返回一个迭代器。
for m in self.modules(): 遍历网络中的每一层
if isinstance(m, nn.Conv2d): 判断m是否是 nn.Conv2d层
其实并不需要用_initialize_weights()方法进行初始化,因为pytorch会默认以 nn.init.kaiming_normal_() 进行初始化。
"""
四、训练及保存精度最高的网络参数:train.py
import torch
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
from dataset import dataset
def train(batch_size, epochs, lr=0.001):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
train_loader, valid_loader, val_num = dataset(batch_size=batch_size)
model = AlexNet(class_num=5, init_weights=True)
model.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# model.parameters()表示优化网络中所有的可训练参数
save_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
model.train() # 启用 dropout和 Batch Normalization
running_loss = 0.0
train_bar = tqdm(train_loader) # 将 train_loader设置为进度条对象
for step, (images, labels) in enumerate(train_bar):
optimizer.zero_grad()
outputs = model(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = f"train epoch [{epoch+1}/{epochs}] loss= {loss:.3f}"
# validate
model.eval() # 不启用 dropout和 Batch Normalization
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(valid_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = model(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
# torch.eq() 用于对两个Tensor进行逐元素比较,若相同位置的两个元素相同,则返回1;否则返回0。
val_accurate = acc / val_num
print('[epoch %d] train_loss= %.3f val_accuracy= %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
# 保存验证精度最高的模型
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(model.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
train(batch_size=16, epochs=10, lr=0.0002)
训练结果(没有跑完):

五、用数据集之外的图片进行测试:predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import AlexNet
def predict():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "./tulip.png" # 用数据集之外的图片进行测试
assert os.path.exists(img_path), f"file: '{img_path}' dose not exist."
img = Image.open(img_path)
plt.imshow(img) # 在扩维之前 imshow
img = data_transform(img) # [C, H, W],图片只有三个维度,没有batch_size的维度
img = torch.unsqueeze(img, dim=0) # 扩维为 [N, C, H, W]
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# load model weights
model = AlexNet(class_num=5).to(device)
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), f"file: '{weights_path}' dose not exist."
model.load_state_dict(torch.load(weights_path))
# predict class
model.eval()
with torch.no_grad():
output = torch.squeeze(model(img.to(device))).cpu()
# 维度压缩,去掉batch_size维度
# output = tensor([-2.0011, -4.6823, 2.4246, -2.3200, 3.8126])
predict = torch.softmax(output, dim=0)
# predict = tensor([2.3797e-03, 1.6297e-04, 1.9888e-01, 1.7299e-03, 7.9685e-01])
predict_cla = torch.argmax(predict).item()
# 取出predict中最大值的索引(索引为tensor),并将索引转为数字
# predict_cla = 4
# imshow img and class
img_class = class_indict[str(predict_cla)]
img_preb=predict[predict_cla].item()
print_res = f"class: {img_class} prob: {img_preb:.3}"
plt.title(print_res) # 表头名称
for i in range(len(predict)):
print(f"class: {class_indict[str(i)]:12} prob: {predict[i].item():.3}")
plt.show()
if __name__ == '__main__':
predict()
测试结果:
class: daisy prob: 0.00238
class: dandelion prob: 0.000163
class: roses prob: 0.199
class: sunflowers prob: 0.00173
class: tulips prob: 0.797
测试图片及类别预测:



















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











