









论文信息
作者:Arian Bakhtiarnia, Nemanja Milošević, Qi Zhang, Dragana Bajović, Alexandros Iosifidis
发表会议:
- ICML 2022 DyNN Workshop
- ICASSP 2023
发表单位:
∗DIGIT, Department of Electrical and Computer Engineering, Aarhus University, Denmark.
†Faculty of Sciences, University of Novi Sad, Serbia.
‡Faculty of Technical Sciences, University of Novi Sad, Serbia.
开源工作:MaLeCi / DynamicSplitComputing · GitLab (au.dk)
引用格式:
@INPROCEEDINGS{10096914,
author={Bakhtiarnia, Arian and Milošević, Nemanja and Zhang, Qi and Bajović, Dragana and Iosifidis, Alexandros},
booktitle={ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={Dynamic Split Computing for Efficient Deep EDGE Intelligence},
year={2023},
volume={},
number={},
pages={1-5},
doi={10.1109/ICASSP49357.2023.10096914}}
ABS
| ABS | Tips |
|---|---|
 | bg: 由于计算机资源有限,在物联网和移动设备上部署深度神经网络是一项具有挑战的任务 motivation:要求苛刻的任务通常卸载到能加速推理的边缘服务器,但是会带来 1)通信成本和隐私问题。2)且还没有使用终端设备的计算能力。 method:提出动态拆分计算,根据通信信道的状态选取最佳拆分点 result:在数据速率和服务器负载随时间变化的边缘计算环境下实现更快的推理 |
INTRO
BG:IoT和深度学习结合应用于各种领域,例如医疗健康,智慧家居,运输和工业。但是深度学习模型含有巨大参数量(百万级/亿万级),部署于资源受限的设备很困难。
现有方案之一:卸载计算到在边缘服务器或者云服务器,隐含问题的如下:
- 模型输入巨大,卸载计算到服务器将消耗带宽、能量,造成延迟
- IoT设备仍含有一些计算能力没有被用上
- 数据涉及健康数据或者人类的影音流会触及隐私问题,额外处理数据造成另外的计算量
拆分计算(Split computing): 将深度学习模型拆分成两部分(头+尾),头部模型在边缘设备运行,将头部的输出结果(中间表示)转换到服务器处理,通过服务器获取尾部模型的最终输出结果。
拆分计算相对于完全卸载的另一个好处是,它可以用作隐私保护技术,因为传输的是中间表示而不是实际输入,并且原始输入不能轻易地从中间表示重建。
ref: [6] Jeong, H.-J., Jeong, I., Lee, H.-J., and Moon, S.-M. Computation offloading for machine learning web apps in the edge server environment. In 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), pp. 1492–1499, 2018. doi: 10.1109/ICDCS. 2018.00154.
拆分计算可以与早退结合,当转换中间表示到服务器比想象中更久的时候。
ref: [7]Scardapane, S., Scarpiniti, M., Baccarelli, E., and Uncini, A. Why should we add early exits to neural networks? Cognitive Computation, 12(5):954–966, Sep 2020. ISSN 1866- 9964. doi: 10.1007/s12559-020-09734-4. URL https: //doi.org/10.1007/s12559-020-09734-4.
[5]Matsubara, Y., Levorato, M., and Restuccia, F. Split computing and early exiting for deep learning applications: Survey and research challenges. arXiv:2103.04505, 2021.
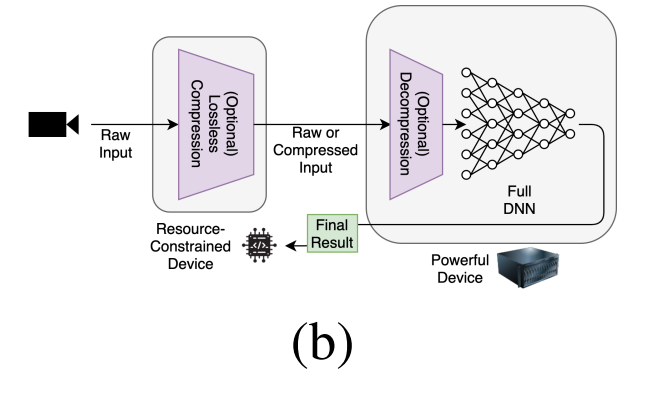
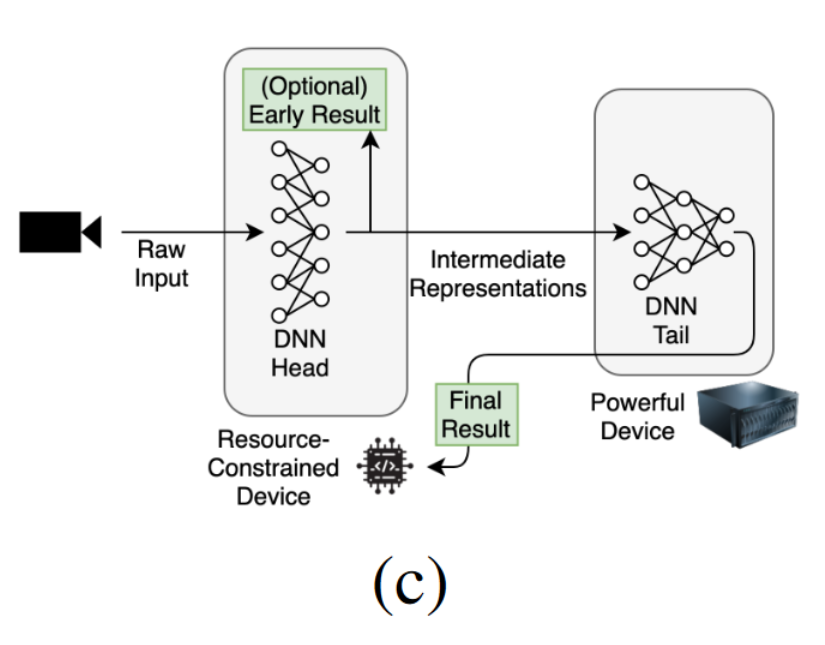
(b)全卸载; (c)拆分计算
拆分计算旨在减少通信成本,深度学习的自然瓶颈即在中间表示的大小小于输入大小就可以用作为拆分点。本文发现EfficientNet等最先进的模型具有许多自然瓶颈,因此提出一种动态拆分计算的方法,可以基于输入和通道状态自动化动态地选取最佳的拆分点。
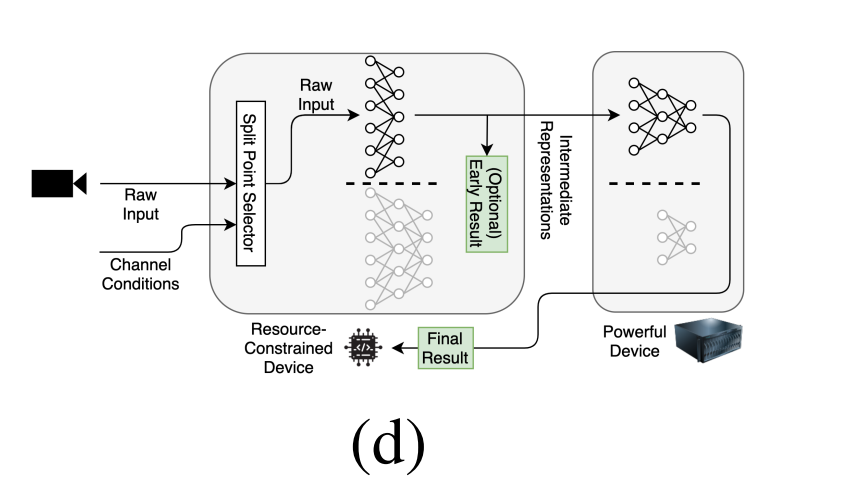
动态拆分(dynamic split computing)优点:
-
不改变底层深度学习模型结构,是一种即插即用方法,可以在没有关于正在使用的特定深度学习模型的领域知识的情况下使用。
-
作为一种补充的高效推理方法,可以于其他方法结合使用,比如模型压缩方法(剪枝,量化)以及动态推理方法(早退)。
相关工作
已经有工作探索过动态决定拆分点地可行性,但是这些方法没有考虑瓶颈处,且尝试将所有层平等得看作是拆分点,增加了不必要的开销。
另外,使用瓶颈减少从中间表示推理源数据的可能性,这对于隐私保护很重要。
DYNAMIC SPLIT COMPUTING
本文方法的目标是通过通信信道状态和批大小动态检测给定 DNN 的最佳拆分点优化端到端推理时间。
-
查找自然瓶颈
对于每个层的压缩比计算为 c l = ∣ h l ∣ / ∣ x ∣ c_l=|h_l|/|x| cl=∣hl∣/∣x∣(x代表输入大小,h代表中间表示大小)
自然瓶颈为: c l < 1 c_l<1 cl<1
-
压缩瓶颈
不是所有的自然瓶颈都是有用的,只有某个自然瓶颈的压缩比小于先前瓶颈的压缩比的时候,此瓶颈才是有用的即压缩瓶颈。
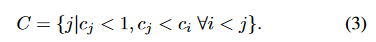
-
动态拆分计算 基于公式在每个时间步长(数据速率和批大小) 找到最佳拆分点,并切换到该配置。
动态拆分计算包含无卸载和拆分计算,根据需要切换。如果要求隐私保护,可以定义l 为0-(L-1)
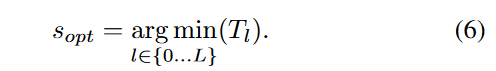
其中,对于特定batch输入的端到端推理时间计算如下:D为数据大小,r为数据速率。
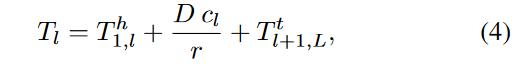
疑问:压缩瓶颈就等于是从前往后最小压缩比的瓶颈?不就代表只有1个嘛?那么还需要去选取最佳拆分点吗?
-
衡量动态拆分计算在每种特定情况下的增益
每个步长 i i i的状态 S S S为 ( B i , r i ) (B_i,r_i) (Bi,ri)
动态拆分计算对端到端推理时间的相对平均增益为:
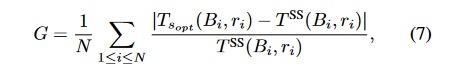
实验及其结果
实验设置
models:EfficientNetV2的7种变体、EfficientNetV1的7种变体
devices:边缘服务器使用2080 Ti GPU;资源受限的设备使用相同的GPU,降频为300MHz。
(降频GPU的推理速度为2.37 TFLOPS,类似于Nvidia Jetson TX2和Xavier系列,其范围从1.33到5.25 TFLOPS。)
实验
-
分析每个模型架构的压缩的自然瓶颈
这些架构有15-68个自然瓶颈,其中3/4都是压缩瓶颈。
-
分析每个模型的最佳拆分点
根据不同状态(data rate, batch size)的推理时间分析,最小推理时间的压缩瓶颈为最佳拆分点。
模型 结果图 EfficientNetV1-B4 ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p2CD8cQv-1687853525181)(./Dynamic Split Computing for Efficient Deep Edge Intelligence.assets/image-20230627000047932.png)]](https://img-blog.csdnimg.cn/be238fcd826a4d5da362a26676ebc3bb.png)
EfficientNetV2-S ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T4wGS5tI-1687853525181)(./Dynamic Split Computing for Efficient Deep Edge Intelligence.assets/image-20230627000109737.png)]](https://img-blog.csdnimg.cn/821f5348c3fc499dafeb108832d3342d.png)
EfficientNetV2-L ![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u6iEgjLk-1687853525181)(./Dynamic Split Computing for Efficient Deep Edge Intelligence.assets/image-20230627000136264.png)]](https://img-blog.csdnimg.cn/7cb8afeaadaf4d63ad3818baaec4104e.png)
观察图表得出信息:每个压缩瓶颈对应多个状态下的最佳拆分点
因此,根据通信信道的状态在拆分点之间动态切换(以及无卸载)可以提高推理速度。
-
动态拆分计算方法对于端到端推理时间的增益
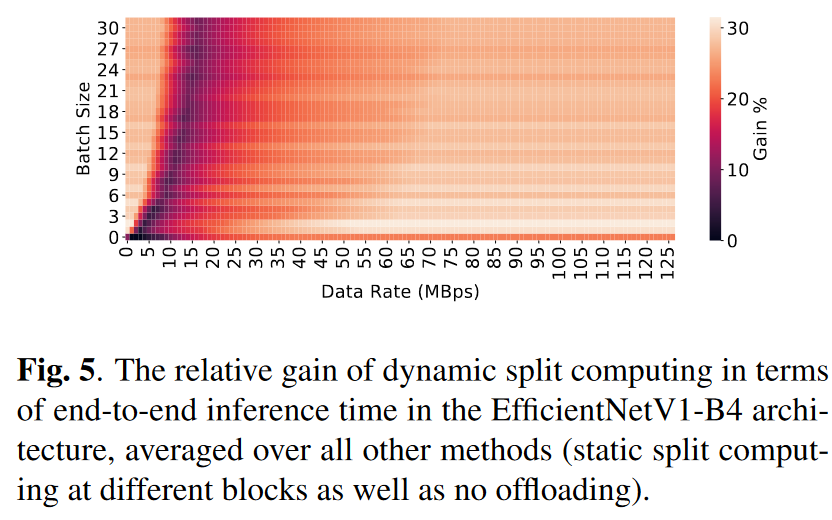
动态拆分计算方法相对比其他方法(静态拆分计算方法/无卸载方法),在大多数情况下,推理速度平均会提高 20% 到 30%,而无需任何训练或影响准确性。
总结
本文展示了动态拆分计算在推理时间提高上同时超过了无卸载和固定位置的拆分计算方法。
另外,相对于全卸载方法,动态拆分计算通过运用终端设备的计算性能实现减少服务器的负载。
最后,通过转换中间表示信息而不是输入,动态拆分计算方法克服了全卸载所面对的隐私问题。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











