









2022-2023年论文系列之模型轻量化和推理加速
前言
通过Connected Papers搜索引用PaBEE/DeeBERT/FastBERT的最新工作,涵盖:
- 模型推理加速
- 边缘设备应用
- 生成模型
- BERT模型
- 知识蒸馏
论文目录
-
SmartBERT: A Promotion of Dynamic Early Exiting Mechanism for Accelerating BERT Inference
-
SKDBERT: Compressing BERT via Stochastic Knowledge Distillation
-
Knowledge Distillation with Reptile Meta-Learning for Pretrained Language Model Compression
-
Accelerating Inference for Pretrained Language Models by Unified Multi-Perspective Early Exiting
-
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
主要内容:近两年(2022-2023年)动态早退的工作进展,粗读motivation和method以及experiment setup。# 6. A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
6. A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
a. 论文信息
发表会议: Findings of ACL 2022
作者:Tianxiang Sun, Xiangyang Liu, Wei Zhu, Zhichao Geng, Lingling Wu, Yilong He, Yuan Ni, Guotong Xie, Xuanjing Huang, Xipeng Qiu
发表单位:
- 复旦大学计算机学院
- 鹏城实验室
开源:https://github.com/txsun1997/hashee
b. 内容
motivation
- 以往的EE采用启发式方法,比如中间输出的熵评估实例难度,受到泛化和阈值调整的影响。
- 学习退出或者学习预测实例难度的方法更加好,但是现有的研究未知是否可以学习实例难度以及如何学习。
method
研究实例难度的可学习性
构造两种类型的实例难度数据集:1)人为定义的难度;2)模型定义的难度
-
人为定义的难度:
构造数据集:从SNLI数据集收集UnKnown标签的1119条数据作为困难实例,收集带标签的(即蕴含,矛盾和中立)1119条数据作为简单实例,总共2238条数据。1238条数据作为训练集,1000条数据作为测试集。
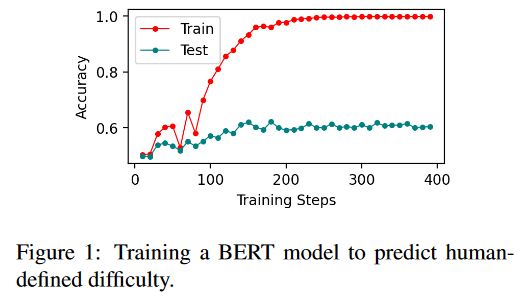
可学习的人为定义难度:使用BERT接上线性分类器,评估测试集能否预测实例为简单或困难。
实验现象:BERT模型很好的拟合训练集,但是测试集只有约60%准确率。
实验结论:神经网络模型,甚至是BERT模型,不能很好的学习人为定义的困难实例。
-
模型定义的难度
如果一个实例不能被训练良好的模型正确预测,则可以将其定义为困难的实例。特别是,我们构建了两个分别在句子级和token级标有模型定义难度的数据集。
构造数据集:
-
句子级难度:估计一个句子(或句子对)的模型定义的难度有助于语言理解任务,如文本分类和自然语言推理。
训练一个多出口BERT,每一层都附有一个内部分类器,使用SNLI训练集。一旦多出口BERT被训练,它就可以作为一个注释器来标记SNLI开发集中的每个实例,是否可以由每个内部分类器正确预测。在我们的实验中,我们使用具有 12 层的BERTBASE,因此对于 SNLI 开发集中的每个实例,我们有 12 个标签,每个标签的值为 0 或 1,以指示相应的内部分类器是否正确预测其标签。通过这种方式,我们对 9842 个 SNLI 开发实例进行标记以构建一个多标签分类数据集,从中随机抽取 8000 个实例作为训练集,并使用剩余的 1842 个实例作为测试集。
-
token级难度:估计每个token的难度,可以用于语言生成任务和序列标记任务。
训练一个多出口BERT,使用OntoNotes NER (Hovy et al., 2006) 训练集,使用它来注释 OntoNotes 开发实例中的每个token是否可以由每个内部分类器正确预测。通过这种方式,获得了一个由 13900 个实例组成的token级多标签分类数据集,从中我们随机抽取 10000 个实例来构建一个训练集,并使用剩余的 3900 个实例作为测试集。
可学习的模型定义难度:使用模型预测测试集的实例困难度
实验现象:对于句子级别的难度,预测性能差距不大,只有BERT略胜一筹;对于token级别,神经网络模型都略胜于Majority模型,但是神经模型的性能主要来自对标签先验分布的学习,而不是从实例中提取与难度相关的特征。

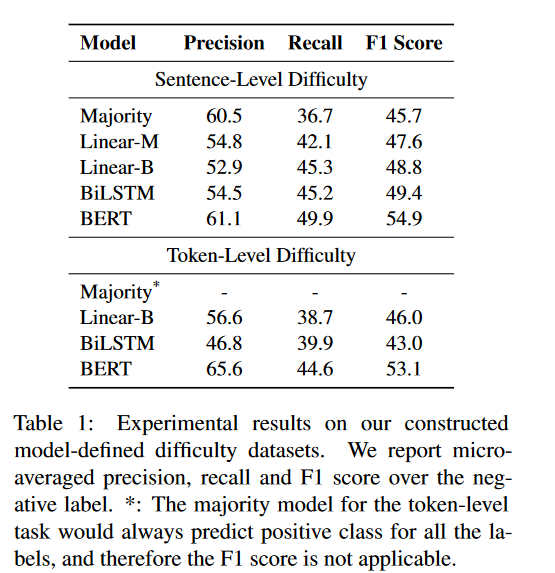
实验结论:无法得出实例难度无法学习的结论,因为仍有各种机器学习模型和训练技术正在探索中,但是我们的初步实验表明无论是人类定义的还是模型定义的实例难度,对于现代神经网络来说都很难学习。
-
HASHEE
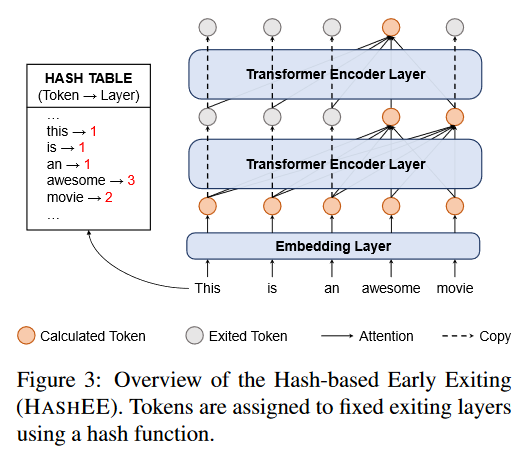
一方面,learn-to-exit模块的确实现了性能提升;另一方面,预测实例难度已经在我们的实验钟证明是很难实现的。因此我们分析learn-to-exit的实现性能提升是保持了训练和推理的一致性,所以我们设计删除学习过程,只保留一致性即用hash函数替换learn-to-exit模块。
本文提出的基于hash的EE方法为HASHEE,hash函数替换学习退出模块,分配每个token到固定的退出层。
experiment setup
数据集:
-
理解任务:ELUE benchmark,包括SST-2, IMDb, SNLI, SciTail, MRPC, STS-B
-
生成任务:两个英文摘要数据集 CNN/DailyMail, Reddit;两个中文摘要数据集:TTNews (Hua et al., 2017) 和CSL (Xu et al., 2020b).
评价指标:FLOPs&Acc/F1
Baseline:
- 预训练语言模型:BERT, RoBERTa, ALBERT, ElasticBERT
- 静态模型:DistilBERT, TinyBERT , HeadPrune, BERTof-Theseus
- 动态模型:DeeBERT , FastBERT, PABEE, BERxiT , CascadeBERT
训练:GeForce RTX 3090 GPUs
-
NLU实验使用ElasticBERTbase模型作为主干模型,训练5次,使用不同的随机种子。
-
文本摘要数据集,使用BARTBASE和CPTBASE作为主干模型,使用频率hash分配token到编码层。
result
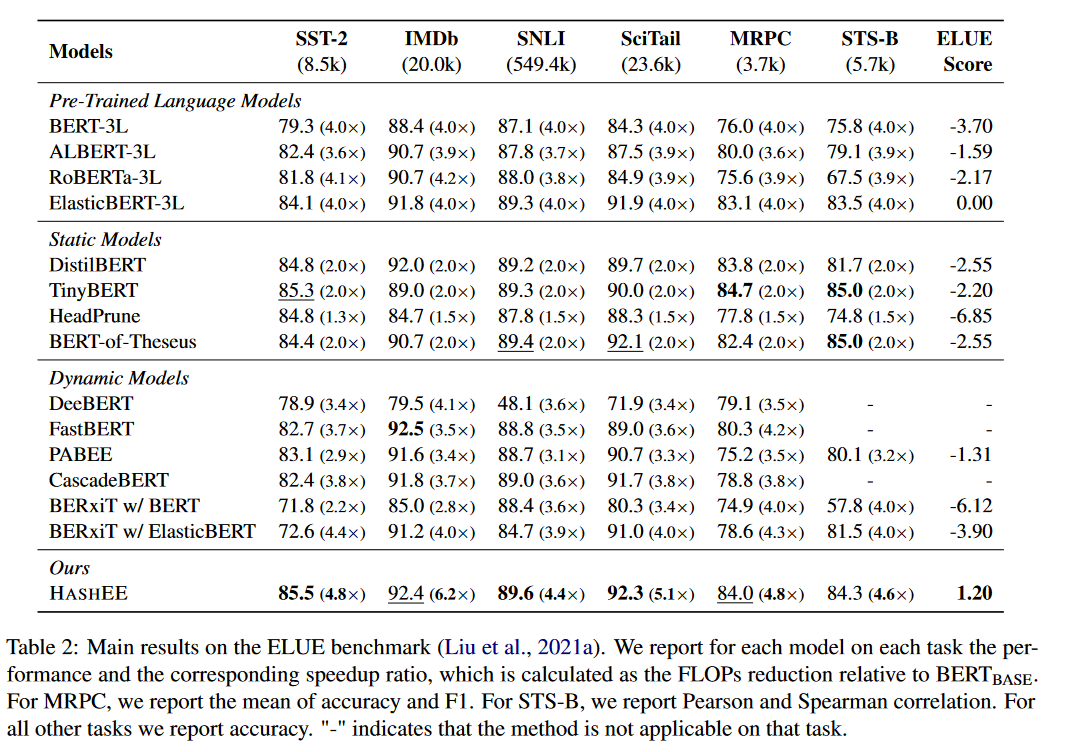
分类、回归和生成任务的实验结果表明,与以前最先进的早期退出方法相比,HASHEE 能够以更少的 FLOP 和推理时间实现更高的性能。
- ELUE: 加速超过所有baselines
- 生成任务
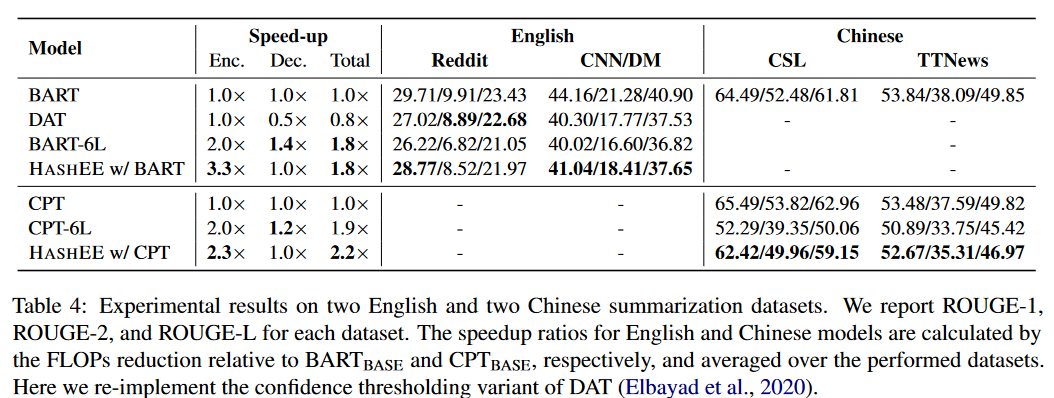
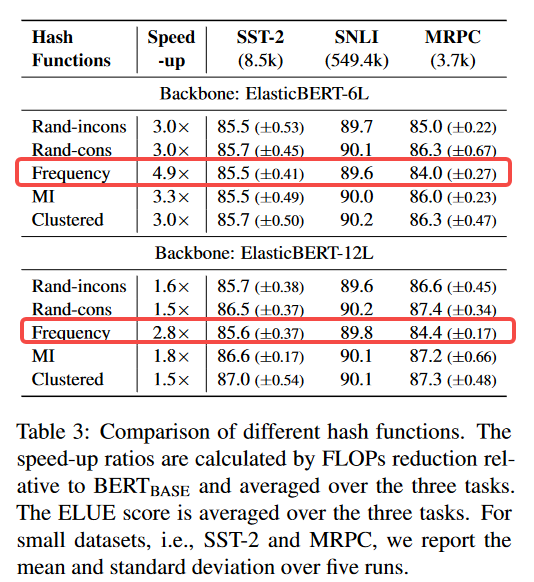
- 不同的哈希函数:frequency取得最高加速比。
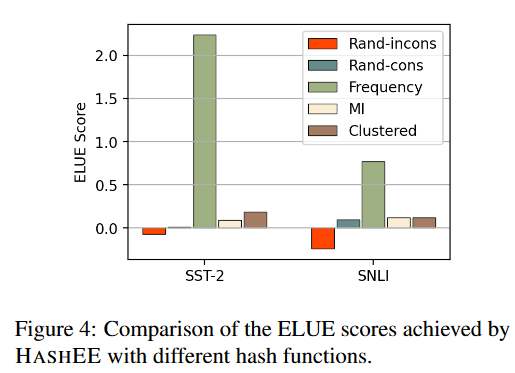
本文对高加速度比的情况更感兴趣,因此采用ElasticBERT-6L作为我们的主干模型。为了更直观地比较这些具有不同加速比的哈希函数,我们还显示了以 ElasticBERT-6L 为主干的 SST-2 和 SNLI 上的 ELUE 分数,如图 4 所示。Rand-incons取得负分,证明保持训练和推理一致性的好处。
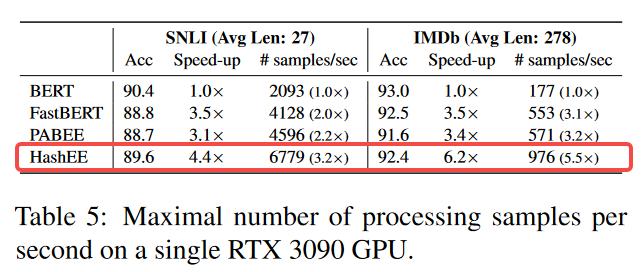
- 实际推理时间:在单块GPU测试,FastBERT和PABEE只支持批量大小为1的推理,但是批次推理在离线场景和低延迟场景中通常更有利。我们发现当批量大小超过 8 时,HASHEE 在处理速度方面具有优势。此外,HASHEE由于其内存效率,可以执行更大的批量推理。
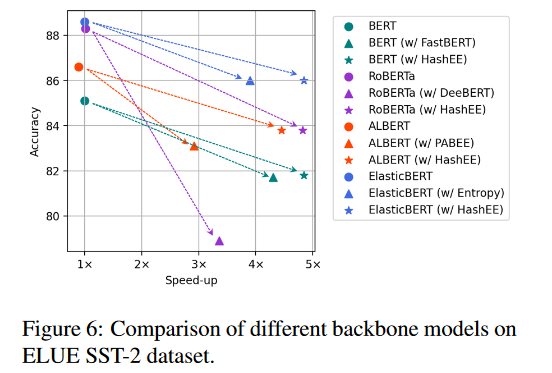
- 不同主干模型的加速:相比其他动态模型的更快,准确率更高
c. Summary
-
研究实例难度的可学习性,早期退出的关键问题是实例难度的可学习性,本文证实预测实例难度是很难的。
-
提出了一种基于哈希的早期退出方法,称为HASHEE,它消除了学习过程,只坚持训练和推理之间的一致性。
- HASHEE具有以下几个优点:
(a)HASHEE不需要内部分类器,也不需要额外的参数,这在以前的工作中是必需的。
(b) HASHEE可以在没有监督的情况下执行token级别的提前退出,因此可以广泛用于各种任务,包括语言理解和生成。
(c) 通过修改哈希函数,可以轻松调整加速比。
(d) HASHEE可以显着加快按批次的模型推理,而不是像以前的工作那样按实例进行模型推理。
-
在分类、回归和生成任务上的实验表明,HASHEE可以用更少的计算和推理时间实现最先进的性能。

















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











