









2022-2023年论文系列之模型轻量化和推理加速
前言
通过Connected Papers搜索引用PaBEE/DeeBERT/FastBERT的最新工作,涵盖:
- 模型推理加速
- 边缘设备应用
- 生成模型
- BERT模型
- 知识蒸馏
论文目录
-
SmartBERT: A Promotion of Dynamic Early Exiting Mechanism for Accelerating BERT Inference
-
SKDBERT: Compressing BERT via Stochastic Knowledge Distillation
-
Knowledge Distillation with Reptile Meta-Learning for Pretrained Language Model Compression
-
Accelerating Inference for Pretrained Language Models by Unified Multi-Perspective Early Exiting
-
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
主要内容:近两年(2022-2023年)动态早退的工作进展,粗读motivation和method以及experiment setup。
1. SmartBERT: A Promotion of Dynamic Early Exiting Mechanism for Accelerating BERT Inference
a. 论文信息
发表会议:IJCAI2023
作者:Boren Hu, Yun Zhu, Jiacheng Li, Siliang Tang
发表单位:Zhejiang University
开源:None
b. 内容
motivation
现有的early existing方法仍存在计算冗余,体现在退出之前必须要经过连续层的计算,复杂样本就需要经过更多层。
method
本文提出结合early existing和skipping layer方法,在每个BERT层添加一个skipping gate和existing operator。训练过程,本文提出交叉层对比学习以提高分类效果,还提出一个严格的权重机制以保证训练和推理时的skipping gate的一致性。
模型架构基于FastBERT和DeeBERT,在此基础上添加了skipping gate,计算skip概率决定是否跳过该层:
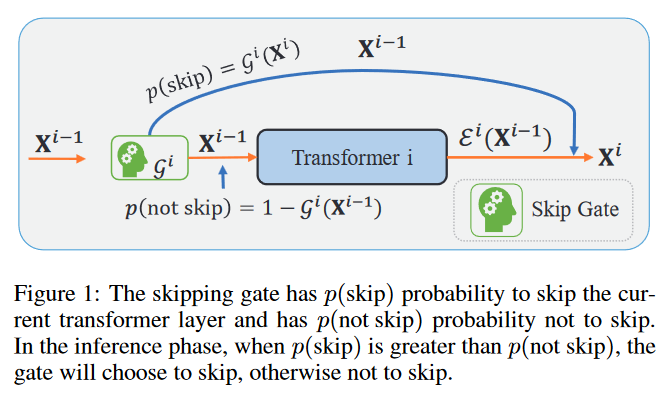
有了skipping gate之后第 i 个encoder block的输出计算如下:
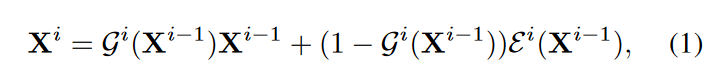
skipping gate 的概率在训练阶段为[0,1],但是推理阶段为0/1,导致了不一致问题。
解决办法:训练阶段你的skipping gate的输出为soft权重,按照如下公式截断,达成和推理阶段一致的离散值:

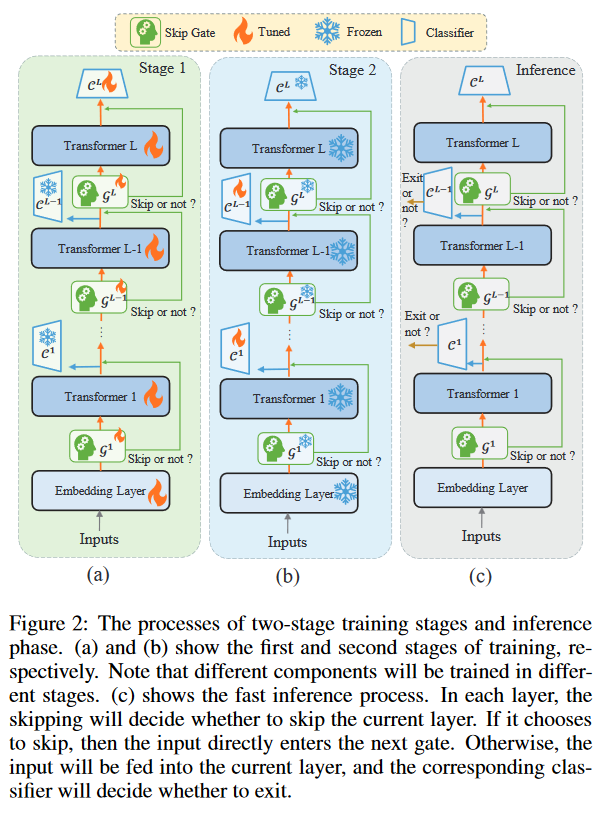
模型训练使用的是2-stages训练策略:
两个阶段训练的对比学习如何进行,可以看文章了解。连续层的相同token表示为正样,否则为负样。
- 第一个训练阶段:中间分类器不参与训练
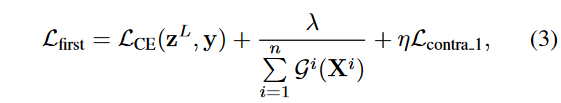
- 第二个训练阶段:冻结第一阶段训练好的模块,训练中间分类器
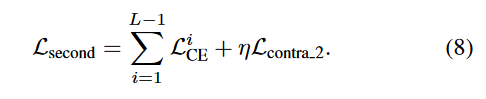
对于skipping gate的特殊训练方式:软权重预热所有skipping gate和transformer层,然后使用硬权重进行训练。
推理:
- 判断是否跳出的公式
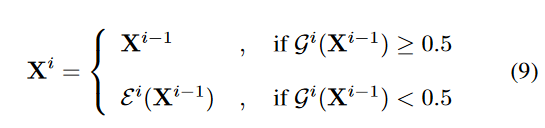
- 不跳出该层,进入早退判断的中间分类器
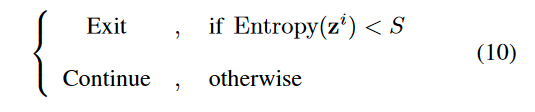
experiment setup
数据集:GLUE的八个分类数据集
baselines:
- BERT: bert-base model pre-trained by Google
- DistilBERT: 从BERT模型蒸馏的更小的模型
- Early exiting model:DeeBERT, FastBERT (相同分类方法)
实验环境:NVIDIA 2080Ti GPU
SmartBERT第一阶段训练了5轮,第二阶段训练4轮。
- result
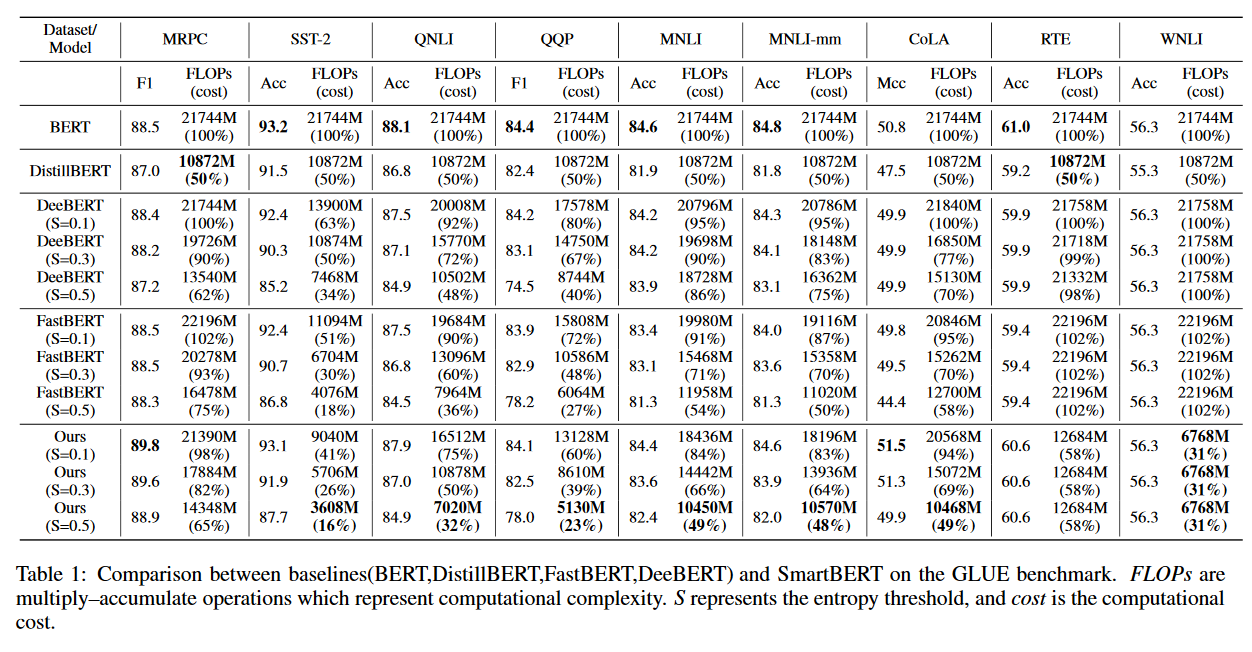
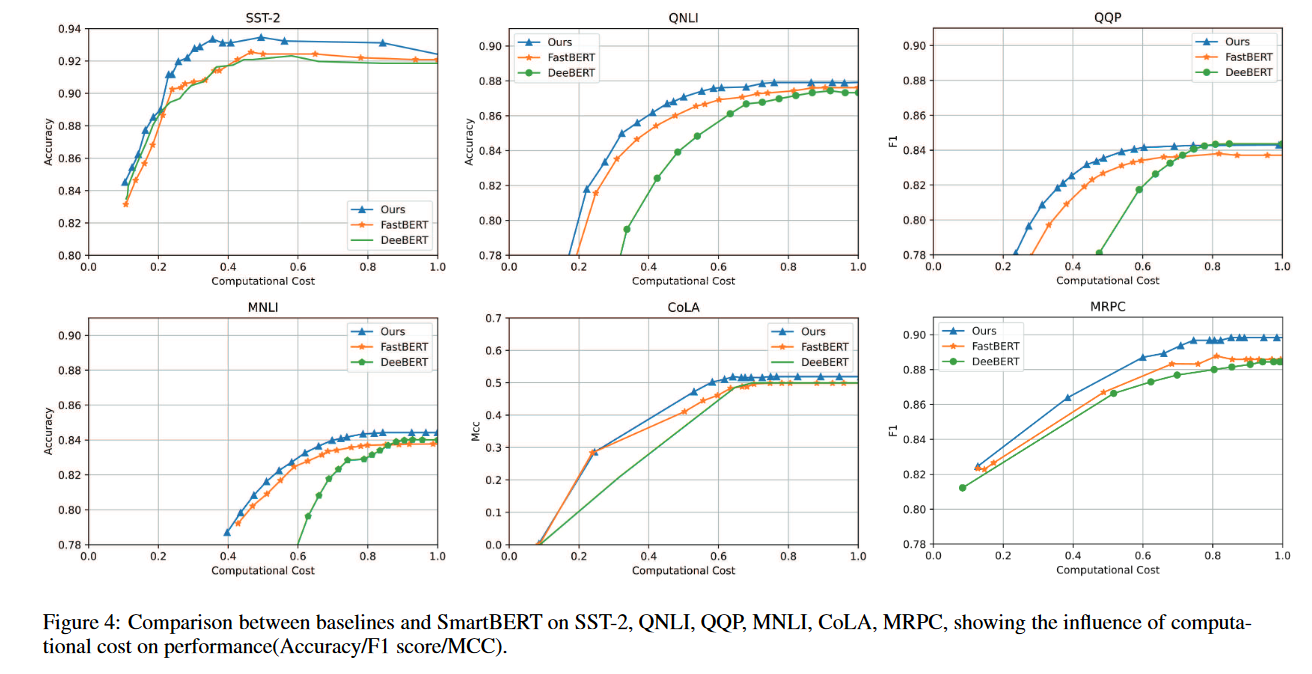
-
相比BERT,实现2-3x的计算量减少
-
相比其他方法,在效率和准确率上更出色
-
在复杂数据集,熵难以起作用,skipping mechanism对减少计算量起了关键作用
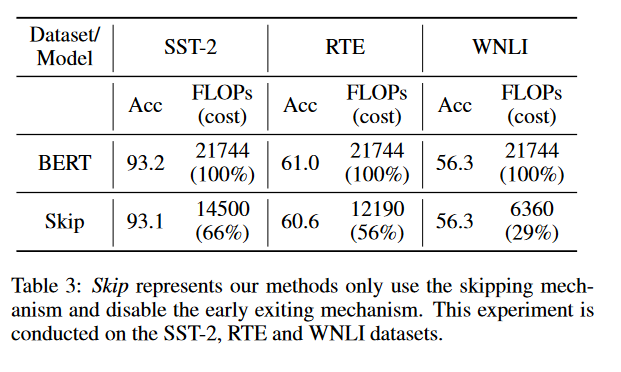
不使用早退机制,只用skipping gate。
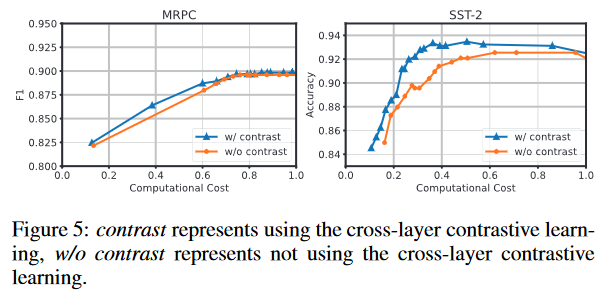
- 消融实验:对比学习
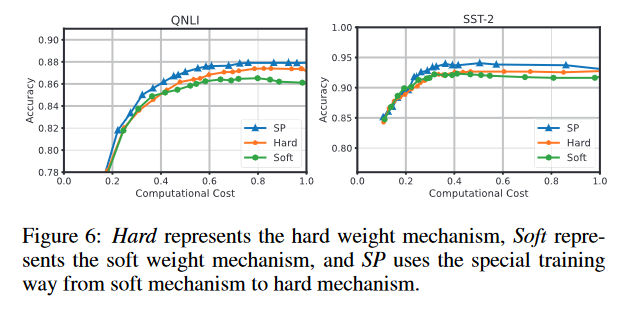
-
特殊的训练机制
Soft:软权重训练
Hard:硬权重训练
SP:先用软权重训练再用硬权重训练
c. Summary
针对deebert和fastbert模型的早退仍存在冗余计算这一点加入skipping gate机制,在训练时使用跨层对比学习思想提高模型分类器的性能,由于skipping gate的加入,造成训练和推理时的参数不一致,将训练时的前向传播的软权重截断成硬权重,并且引入了特殊的训练机制(即软权重预热再用硬权重训练)。
和BERT相比实现2-3x的计算量减少,做了仅用skipping gate进行推理加速的实验、对比学习的消融实验、特殊训练机制的实验。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











