









DriftRec: Adapting diffusion models to blind image restoration tasks
Simon Welker, Universitat Hamburg, Germany, arXiv, Cited:0, Code: 无, Paper.
1. 前言
在这项工作中,我们利用扩散模型的高保真度生成能力来解决盲图像恢复任务,以高压缩级别的JPEG伪影去除为例。我们对扩散模型的前向随机微分方程(SDE)提出了一种优雅的修改,以使其适应恢复任务,并将我们的方法命名为DriftRec。将DriftRec与具有相同网络架构的L2回归baseline(JPEG重建的最新技术)进行比较,我们表明我们的方法可以避免两个基线生成模糊图像的倾向,并且显著更忠实地恢复干净图像的分布,同时只需要干净/损坏的图像对的数据集而不需要关于降质算子的知识。通过利用干净和损坏图像的分布比高斯先验更接近的思想,我们的方法只需要低水平的添加噪声,因此即使没有进一步的优化,也可以相对较少的采样步骤。
2. 整体思想
将扩散过程建模为特定的形式。作者把相同方法相同的论文,一篇应用在语音《Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain》,这篇是图像。

3. 方法
相对于将清晰图像分布转变为纯噪声,本文采用将清晰图像分布转变为降质图像的分布,这么做有一下目的:
- 相对于纯噪声,使用损坏的图像(加上可处理的噪声)作为反向SDE的初始值,从而通过过程本身的公式来实现任务自适应,而不是仅提供损坏的图像作为条件信息。
- 由于添加的是高斯白噪声,因此在整个反向过程中,它充当所有可能的空间频率的连续源。然后,经过训练的分数模型对这些频率进行适当滤波,以在不损失高频细节的情况下从目标分布生成看似干净的图像。
即使图像受到其他噪声污染,其分布仍然适用于恢复任务,因为可以通过取一个受损图像并添加高斯噪声来从中抽样。现在提出以下线性前向SDEs模型family来实现本文的想法:
f
(
x
t
,
t
)
=
γ
F
(
t
)
(
y
−
x
t
)
,
g
(
t
)
=
ν
(
σ
m
a
x
σ
m
i
n
)
2
t
\begin{equation} f(x_{t}, t) = \gamma F(t)(y-x_{t}), \quad g(t) = \nu (\frac{\sigma_{max}}{\sigma_{min}})^{2t} \end{equation}
f(xt,t)=γF(t)(y−xt),g(t)=ν(σminσmax)2t
其中,
y
y
y是对应
x
0
x_{0}
x0的损坏图像。
γ
\gamma
γ是强度,控制着
y
y
y和
x
0
x_{0}
x0之间的距离程度。
F
(
t
)
F(t)
F(t)是控制曲线的形状。
ν
\nu
ν是正则化因子,确保
σ
T
≈
σ
m
a
x
\sigma_{T} \approx \sigma_{max}
σT≈σmax,
σ
T
\sigma_{T}
σT是(1)所描述的高斯过程的闭合形式方差。直觉上,提出的family结合了VE-SDE扩散的
g
g
g和一个添加的漂移项
f
f
f,
f
f
f用于将
x
t
x_{t}
xt拉向受损图像
y
y
y。有趣的是,逆向过程中,漂移项为负,这说明了逆向过程中
x
t
x_{t}
xt不断远离受损图像
y
y
y。如下图所示:

如果没有分数项,反向过程的状态
x
t
x_{t}
xt只会从
y
y
y开始偏离并发散。因此,分数模型可以被解释为一种适用于问题和数据集的学习控制策略,其必须在存在由于
−
f
-f
−f而远离
y
y
y的这种排斥动作的情况下将
x
t
x_{t}
xt转向合理的样本
x
0
x_{0}
x0。
3.1 考虑两种SDEs
本文中,仅仅考虑了两种SDEs,既
F
(
t
)
=
1
,
F
(
t
)
=
t
F(t)=1, \ F(t)=t
F(t)=1, F(t)=t。前一种称为Ornstein-Uhlenbeck Variance Exploding (OUVE) SDE,后一种称为 t-squared Variance Exploding (TSDVE) SDE。这里定义了两种方法的均值:
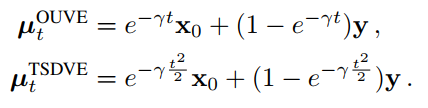
这两个表达式都描述了
x
0
x_{0}
x0和
y
y
y之间的线性(逐像素)插值,插值参数由随时间t的指数(OUVE)或半高斯形状(TSDVE)衰减控制。对于两个SDE,对于所有有限
t
t
t,均值和
Y
Y
Y不等,这似乎是一个问题,因为其目的是使过程向
y
y
y移动。然而,设
z
~
N
(
0
;
I
)
z~N(0;I)
z~N(0;I),只要求
(µ
t
+
σ
T
z
)
(µt+σTz)
(µt+σTz)和
(
y
+
σ
T
Z
)
(y+σTZ)
(y+σTZ)的分布接近,以便后者可以作为反向采样过程的合理初始值。我们可以通过增加刚度γ来控制这两个表达式的分布的匹配程度,代价是潜在地破坏反向过程的稳定,或者通过增加σmax来进一步平滑这两个分布的密度函数,代价是更多的反向迭代。















 69
69











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









