






图像复原任务中对退化过程参数估计,亲测了一下,加在性能较好的网络下,效果提升很微弱

Abstract:
许多图像恢复技术是高度依赖于训练时候的退化模式,在输入退化模型轻微变化的时候性能会严重下降。盲的和通用的技术试图通过产生一个能适应不同条件的训练过的模型来缓解这个问题。但是,到目前为止的盲法技术要求对退化过程有先验知识,并对退化过程的参数空间有假设。在本文中,我们提出了SelfNormalziation Slide-Chain,这是一种不需要退化先验知识的盲通用图像复原的新方法。这个模块可以添加到任何现有的CNN拓扑中,并以端到端方式与网络的其他部分一起训练。从训练数据的变化中推导出与任务相关的成像参数及其动态特性。我们将我们的解决方案应用于多个图像恢复任务,并证明了SNSC编码了退化参数,提高了复原性能。
Introduction:
目前为止的所有盲图像复原技术都需要对退化过程的先验知识和对其参数空间的假设。在通常情况下,一些方法需要对退化参数进行量化或对参数估计值进行迭代修正,这使得退化空间是复杂的(多维的)时这些方法是不可行的。

SNSC执行两项操作。首先,一个全球加权平均池(GWAP)层将整个框架的测量结果聚集成一个紧凑的表示。然后,这个全局信息通过其与图像中特定位置的相关性进行调整,并反馈到CNN的主分支。度量、平均权重和相关性度量都是通过端到端的训练来学习的。
structure:

这个模块可以添加到任何现有的架构中,为CNN的中间层提供信息,这些信息通过比其他方式更大的感受野范围进行聚合,从而使它们能够适应全局成像条件。结构主要包含:
- 1X1 Conv通道压缩
- 3个分支分别使用3x3Conv提取 relevance, estimate, validity
- 使用estimate和validty计算gwap
- 与relevance相乘操作
Global Weighted Average Pooling:
成像参数估计的难点在于许多图像区域不合适,不能用于成像参数的估计。例如,通过收集一个预定义区域的局部方差统计信息来估计噪声水平。如果整个测量区域是高度纹理化的,则纹理控制了方差,无法对噪声级进行评估。另一方面,模糊宽度最好通过测量突出边缘的宽度来估计,如果不存在模糊宽度,则无法可靠地估计。具体公式如下:
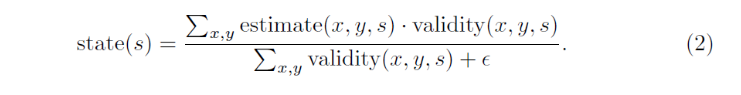
因此,CNNs只能在数据流的后期(在收集了足够的空间信息之后)才能获得这些估计,而其余各层的能力不足以有效地利用这些估计。相比之下,我们的方法通过在靠近CNN输入的地方附加SNSC,从而在流程的早期整合整个框架的统计信息,从而获得一个大的有效感受野。
Experiments:
1.盲去噪:

2.盲去雾:

Coding :
class SNSC(nn.Module):
def __init__(self, channel):
super(SNSC, self).__init__()
self.compress = nn.Conv2d(channel * 8, channel, kernel_size=1)
self.relev = nn.Sequential(
nn.Conv2d(channel, channel, 3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, stride=1, padding=1),
nn.ReLU(inplace=True),
)
self.estim = nn.Sequential(
nn.Conv2d(channel, channel, 3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, stride=1, padding=1),
nn.ReLU(inplace=True),
)
self.valid = nn.Sequential(
nn.Conv2d(channel, channel, 3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channel, channel, 3, stride=1, padding=1),
nn.ReLU(inplace=True),
)
def gwap(self, e, v, eopish=1e-8):
assert e.shape == v.shape
N,C,H,W = e.size()
o = torch.FloatTensor(N, C, 1, 1).cuda()
for i in range(N):
for j in range(C):
tmp_1 = (e[i, j, :, :] * v[i, j, :, :]).sum()
tmp_2 = v[i, j, :, :].sum() + eopish
t = tmp_1 / tmp_2
o[i, j,:,:] = t
return o
def forward(self, x):
x1 = self.compress(x)
relev = self.relev(x1)
estim = self.estim(x1)
valid = self.valid(x1)
gw = self.gwap(estim, valid)
o = relev * gw
return o















 69
69











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









