







主要讲述钟才明教授于2019年在Pattern Recognition上发表的一篇论文《Ensemble clustering based on evidence extracted form the co-association matrix》。
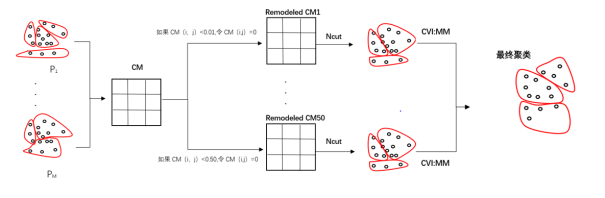
在5中我们已经讲述过,证据积累模型是原始数据集向共协矩阵的转换。共协矩阵中存在一些噪声数据,本文的目的是去除共协矩阵中的噪声数据后,将重构后的每个矩阵都采用Ncut算法从而得到多个聚类结果,最后用一个内部评价性指标MM选择最优聚类。
共协矩阵中的频率是从0-1的数值,并用频率代替相似性。1代表两个数据实例在每个基聚类中都属于同一簇,相似性最大,0代表两个数据实例在每个基聚类中都不属于同一簇,相似性最小。本文通过设置0.01的步长将0-0.5的频率逐步删除对共协矩阵进行重构。主要方法如下:
输入一组数据集,输出最终的聚类。具体步骤如下:用K-means生成基聚类集,然后创建共协矩阵,矩阵中的每个元素都在0和1之间。通过将小于不同阈值的元素设置为0来重构矩阵,然后将Ncut算法应用于这些矩阵以获得多个聚类集成结果。最终的聚类结果由一个内部评估性指标MM来选择。如图1。














02-12
08-05
 383
383
383
08-17
228
228
06-14
06-14
07-03
08-25
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









