






接上篇:
例如如下第一张表得到第二张表
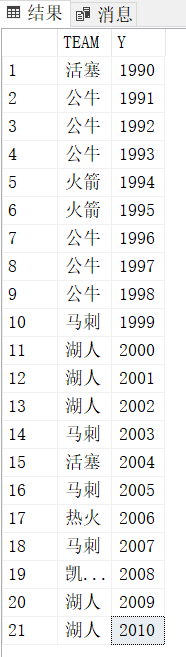
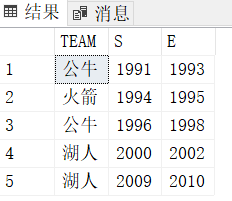
- 建表
CREATE TABLE #t(TEAM varchar(20), Y int)
INSERT #t(TEAM,Y) VALUES
('活塞',1990),
('公牛',1991),
('公牛',1992),
('公牛',1993),
('火箭',1994),
('火箭',1995),
('公牛',1996),
('公牛',1997),
('公牛',1998),
('马刺',1999),
('湖人',2000),
('湖人',2001),
('湖人',2002),
('马刺',2003),
('活塞',2004),
('马刺',2005),
('热火',2006),
('马刺',2007),
('凯尔特人',2008),
('湖人',2009),
('湖人',2010);
- 思路
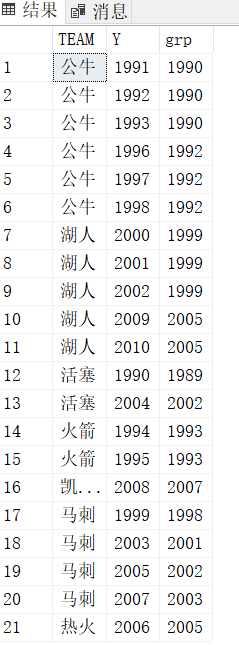
首先根据上一篇的思路将其进行如下操作
select TEAM,Y,Y-rnk grp --grp
from (select TEAM,Y,row_number() over(partition by TEAM order by Y) rnk from #t) t
得到如下的表:
select TEAM,min(Y) S,max(Y) E
from
(
select TEAM,Y,Y-rnk grp
from (select TEAM,Y,row_number() over(partition by TEAM order by Y) rnk from #t
) t1
) t2
group by grp,TEAM having count(*)>1 order by max(Y);
















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









