









一、写在前面
Transformer主要用在机器翻译这个小的领域上。BERT可以针对一般的语言理解任务。之前CV里面有预训练的CNN模型,那BERT出现后使得NLP也有了预训练模型。
摘要:本文介绍一个新的语言模型BERT。BERT和之前的language representation models不一样(如ELMo, GPT),BERT是双向,而且不需要对架构进行调整。像GPT是单向的,而像ELMo是基于RNN的,所以应用到下游任务的时候需要进行架构调整,很麻烦。
二、Introduction
BERT之前也有一些NLP的预训练工作,只不过是BERT的工作使得预训练有名了,后来大家都开始做这个了。
2.1 BERT为什么要引入深度双向?
现有的一些技术有局限性,主要原因是你标准的语言模型是一个单向的,这样导致你在选架构的时候会有一些局限性。比如GPT里面是从左到右的架构,比如你看一个句子的时候,是从左读到右的。
BERT作者认为这个东西不是很好,因为如果要做一些sentence-level的分析时,比如判断一个句子的情绪是不是positive的,那我从左看到右和从右看到左,或者一次看到所有,都是合法的。就算是question answering的任务,我也是能先看完整个句子,然后让我去选答案的。而不是真的要一个个往下走。
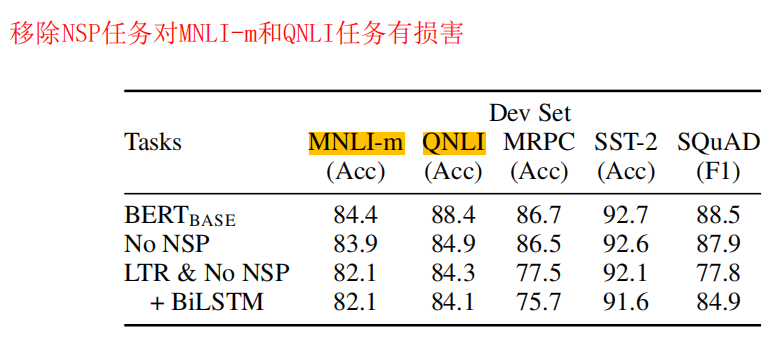
那BERT是如何实现深度双向的呢?(做一个完形填空,显然做完形填空的时候你不能只看左边,你也得看看右边的信息才行,不然你也不知道怎么去填这个空)。。。还有一个任务是预测两个句子是不是在原文中相邻的句子,这个可以学一些句子层面的信息。

2.2 BERT的创新点


2.3 BERT的工作总结(对比之前的ELMo和GPT)

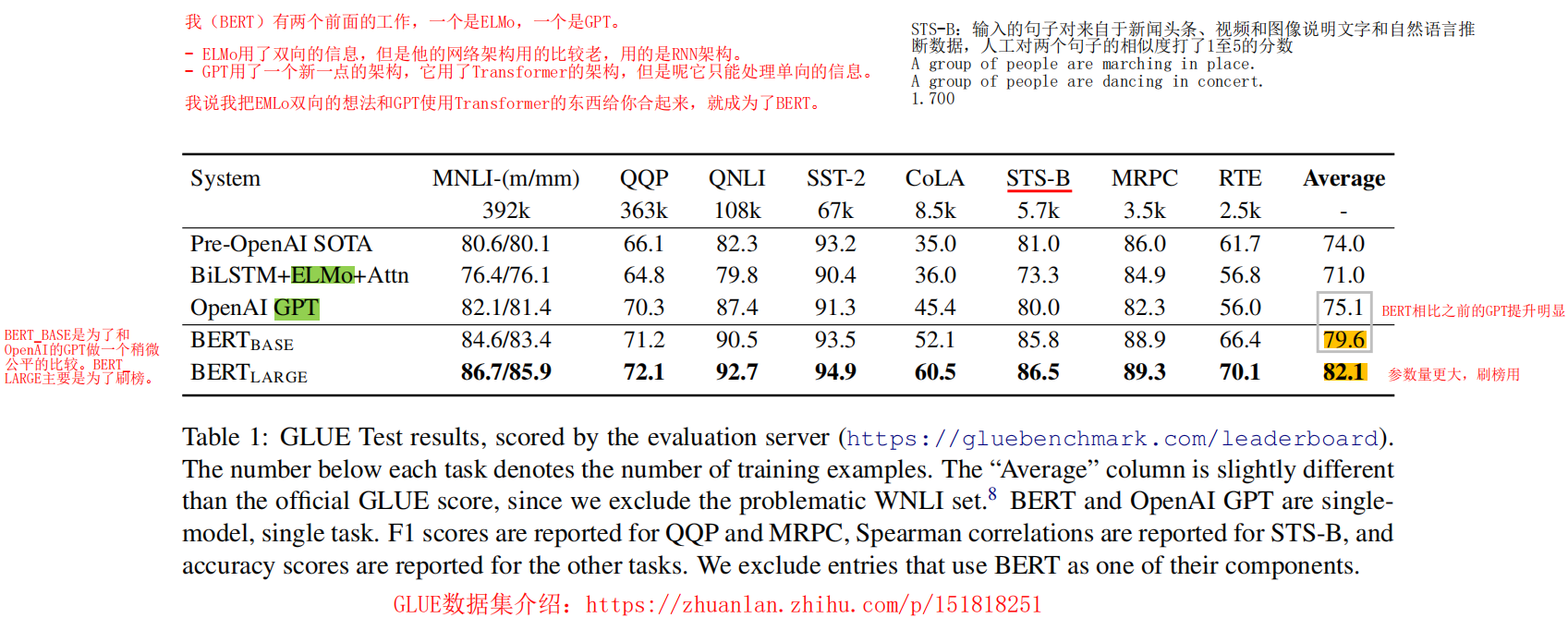
我有两个前面的工作,一个是ELMo,一个是GPT。
- ELMo用了双向的信息,但是他的网络架构用的比较老,用的是RNN架构。
- GPT用了一个新一点的架构,它用了Transformer的架构,但是呢它只能处理单向的信息。
我说我把EMLo双向的想法和GPT使用Transformer的东西给你合起来,就成为了BERT。
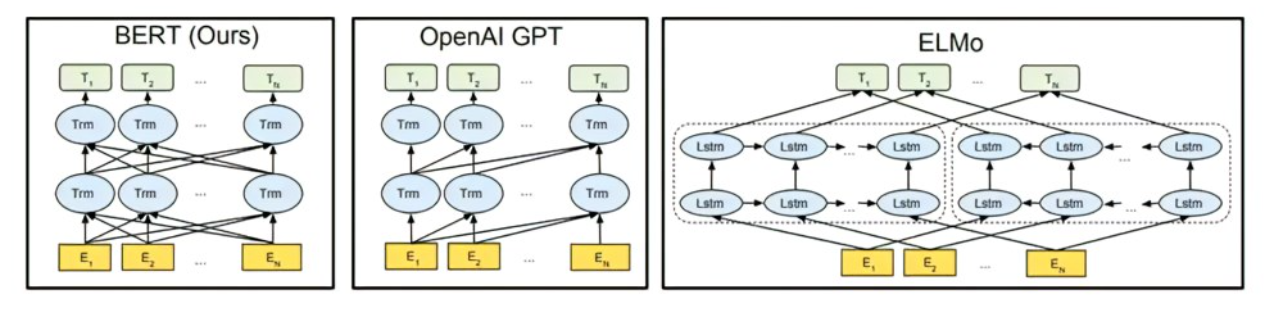
具体的改动是我预测语言模型的时候不是预测未来,而是让你做完形填空。
三、Method
3.1 🕵️ 概念:pre-training预训练 vs. fine-tuning微调(调所有参数)vs. Feature-based(只调下游任务参数)🍔
下面介绍BERT实现的细节,我们总共会进行两个步骤:pre-training and fine-tuning
-
During pre-training, the model is trained on unlabeled data over different pre-training tasks.
-
For fine-tuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks.
-
Each downstream task has separate fine-tuned models, even though they are initialized with the same pre-trained parameters.
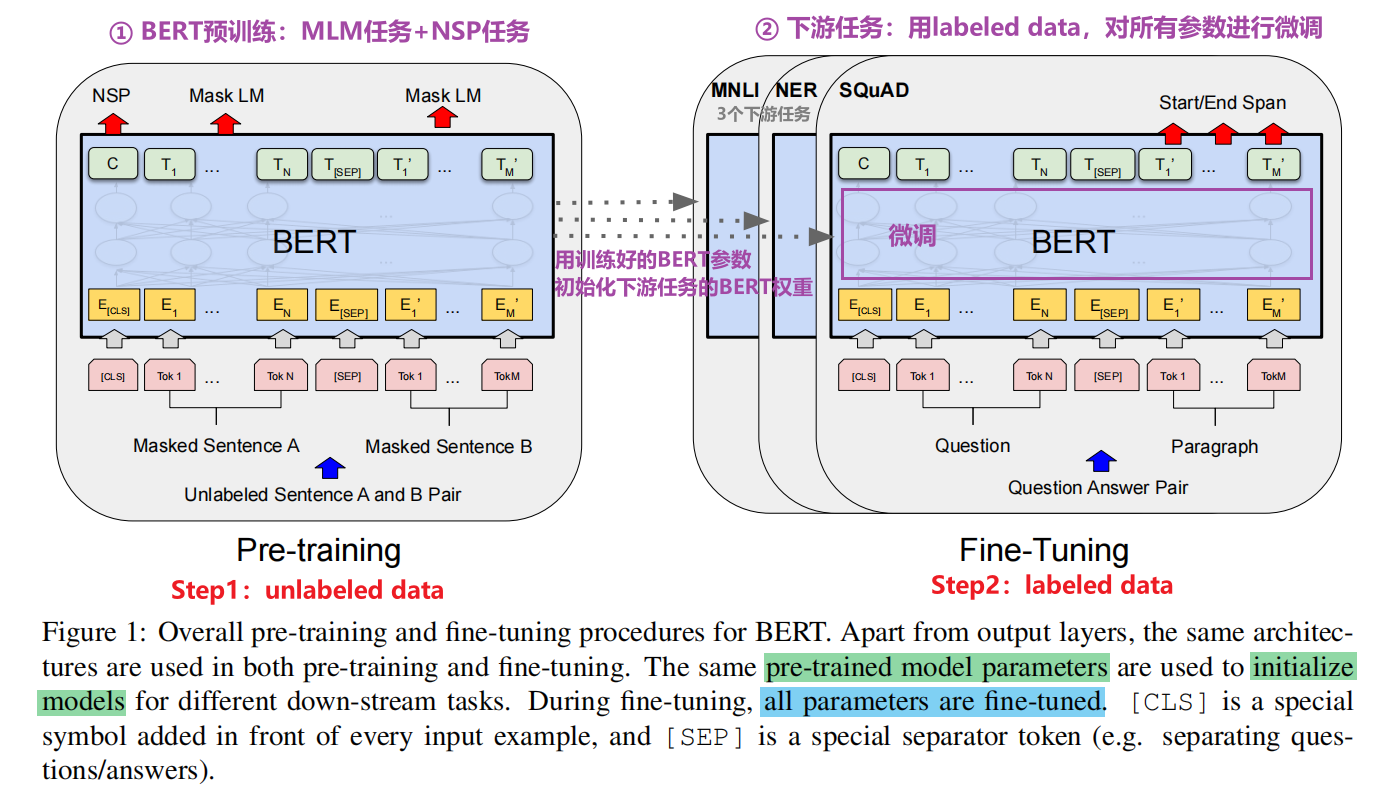
其他方法:Feature-based Approach with BERT
简单来说就是固定BERT的参数,只调下游任务的参数

3.2 Model Architecture(BERT 12层 1亿参数,24层 3亿参数)
BERT’s model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation described in Vaswani et al. (2017) and released in the tensor2tensor library

BERT_BASE是为了和OpenAI的GPT做一个稍微公平的比较。BERT_LARGE主要是为了刷榜。
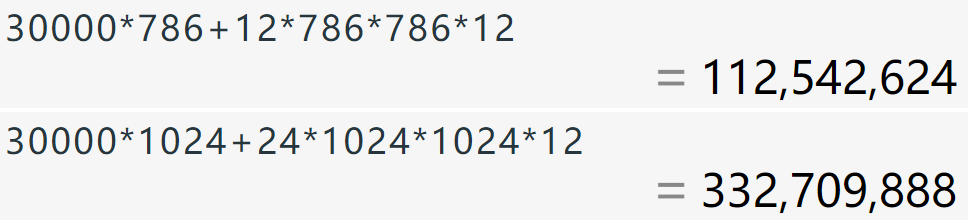
3.3 BERT参数量计算(手写笔记)

BERT参数主要集中在嵌入层和Encoder块
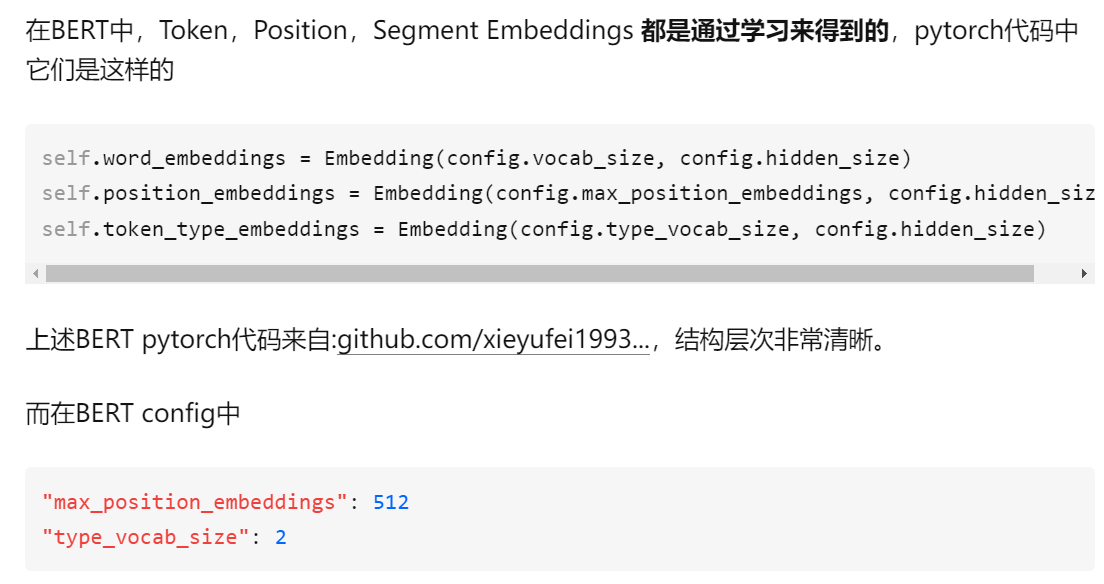
嵌入层的输入是字典的大小,BERT的字典大小是30k(所以不会像推荐系统那样存在上亿商品进行Embedding的问题)
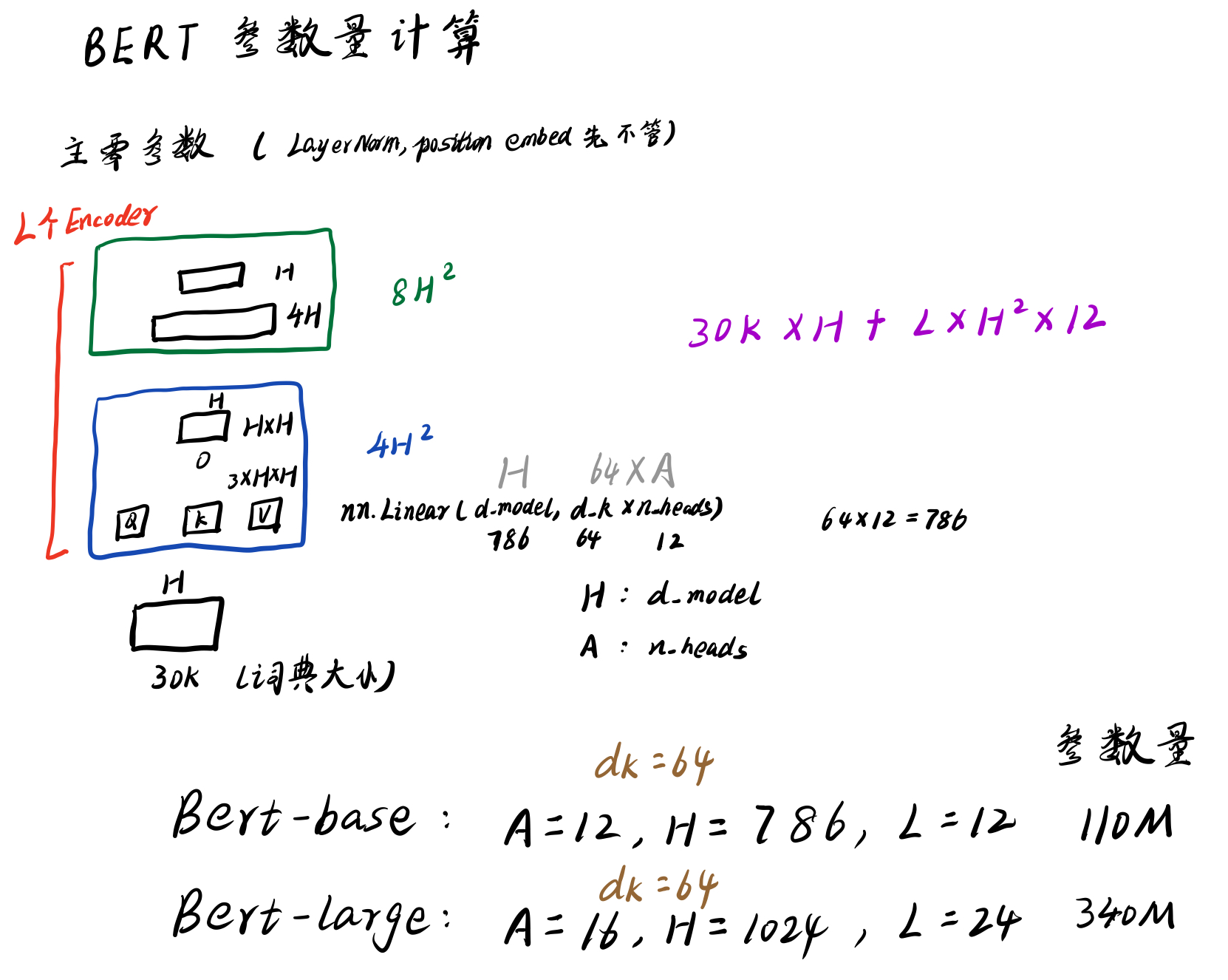
具体可以看Transformer Encoder层的nn.Linear定义
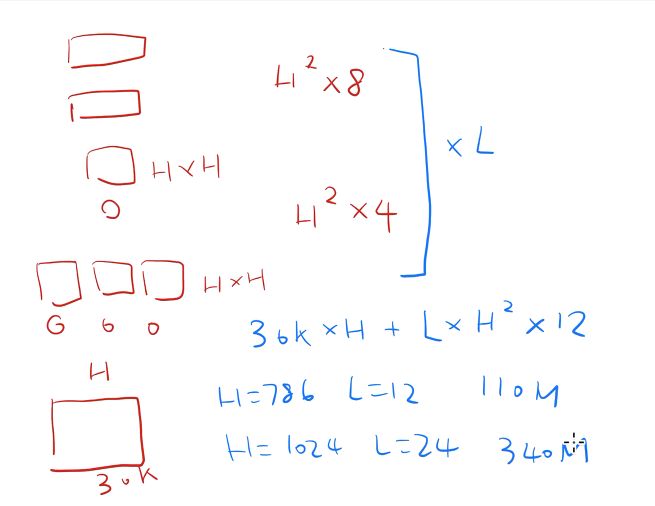
3.4 BERT实战应用(我能调哪些超参)
显然heads的数量,Encoder层的数量,这些我已经没法调了,否则你得重新训练BERT了。我能调的好像就是微调时的学习率吧
https://github.com/WeChat-Big-Data-Challenge-2022/challenge/blob/main/model.py

四、细节
4.1 BERT的输入(sequence:一个句子或两个句子)
BERT为了能够统一处理一个句子的下游任务和两个句子的下游任务,所以BERT统一叫做one token sequence(所以bert的输入只要是一个连续的text就行了,可以是两个句子拼在一起的!)

如果有两个句子的情况,我们需要把两个句子合并成一个序列(sequence)!
4.2 BERT的[CLS]的作用
BERT希望[CLS]对应的最后的状态向量能够代表整个sequence的信息。
因为BERT使用的是Transformer的编码器,所以他的自注意力层里面,每一个词都会去看输入里面所有词的关系,就算是我的这个词放在第一个位置,他也是有办法能看到之后所有的词的。


NSP任务预训练的时候是:每句话之间加个[SEP]变成cls+sentence1+sep+sentence2+sep
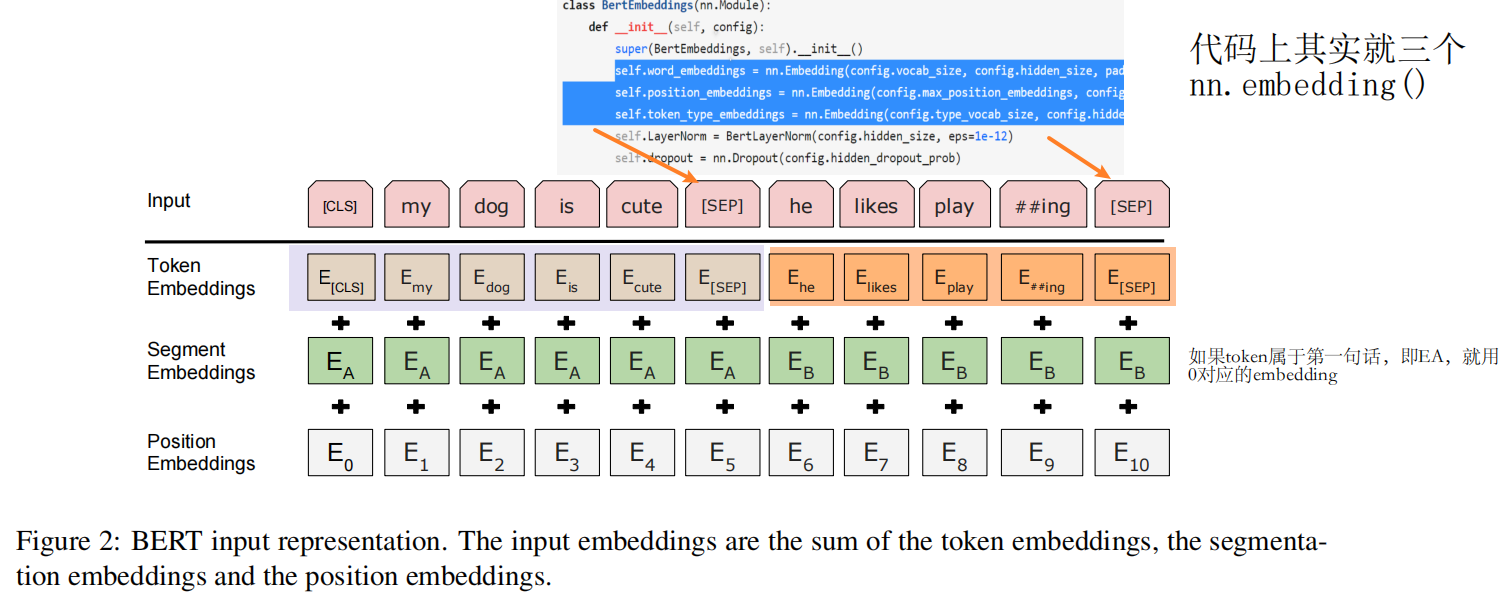
Transformer中的Position Embeddings是通过公式得到的,但是BERT中的Position Embeddings是学习得到的。
4.3 两个预训练任务
4.3.1 MLM:BERT的MASK机制随机15% (80%概率[Mask] + 10%概率不变 + 10%概率随机替换其他词)
Each training example 有15%的词会进行[MASK]机制
如果一句话有300个词,那预训练的时候大概会有300*15%=45个词汇进行MASK机制处理
Masked LM
顾名思义,Masked LM就是说,我们不是像传统LM那样给定已经出现过的词,去预测下一个词,而是直接把整个句子的一部分词(随机选择)盖住(make it masked),这样模型不就可以放心的去做双向encoding了嘛,然后就可以放心的让模型去预测这些盖住的词是啥。这个任务其实最开始叫做cloze test(大概翻译成“漏字填充测验”)。
这样显然会导致一些小问题。这样虽然可以放心的双向encoding了,但是这样在encoding时把这些盖住的标记也给encoding进去了╮( ̄▽ ̄””)╭而这些mask标记在下游任务中是不存在的呀。。。那怎么办呢?对此,为了尽可能的把模型调教的忽略这些标记的影响,作者通过如下方式来告诉模型“这些是噪声是噪声!靠不住的!忽略它们吧!”,对于一个被盖住的单词:
- 有80%的概率用“[mask]”标记来替换
- 有10%的概率用随机采样的一个单词来替换
- 有10%的概率不做替换(虽然不做替换,但是还是要预测哈)
4.3.2 NSP任务


由于出现概率不高,所以wordpiece中分成flight ##less
##表示less是和之前的词拼在一起的

4.3.3 🍉代码:BERT 的 PyTorch 实现
https://wmathor.com/index.php/archives/1457/
# sample IsNext and NotNext to be same in small batch size
def make_data():
batch = []
positive = negative = 0
while positive != batch_size/2 or negative != batch_size/2:
tokens_a_index, tokens_b_index = randrange(len(sentences)), randrange(len(sentences)) # sample random index in sentences
tokens_a, tokens_b = token_list[tokens_a_index], token_list[tokens_b_index]
input_ids = [word2idx['[CLS]']] + tokens_a + [word2idx['[SEP]']] + tokens_b + [word2idx['[SEP]']]
segment_ids = [0] * (1 + len(tokens_a) + 1) + [1] * (len(tokens_b) + 1)
# MASK LM
n_pred = min(max_pred, max(1, int(len(input_ids) * 0.15))) # 15 % of tokens in one sentence
cand_maked_pos = [i for i, token in enumerate(input_ids)
if token != word2idx['[CLS]'] and token != word2idx['[SEP]']] # candidate masked position
shuffle(cand_maked_pos)
masked_tokens, masked_pos = [], []
for pos in cand_maked_pos[:n_pred]:
masked_pos.append(pos)
masked_tokens.append(input_ids[pos])
if random() < 0.8: # 80%
input_ids[pos] = word2idx['[MASK]'] # make mask
elif random() > 0.9: # 10%
index = randint(0, vocab_size - 1) # random index in vocabulary
while index < 4: # can't involve 'CLS', 'SEP', 'PAD'
index = randint(0, vocab_size - 1)
input_ids[pos] = index # replace
# Zero Paddings
n_pad = maxlen - len(input_ids)
input_ids.extend([0] * n_pad)
segment_ids.extend([0] * n_pad)
# Zero Padding (100% - 15%) tokens
if max_pred > n_pred:
n_pad = max_pred - n_pred
masked_tokens.extend([0] * n_pad)
masked_pos.extend([0] * n_pad)
if tokens_a_index + 1 == tokens_b_index and positive < batch_size/2:
batch.append([input_ids, segment_ids, masked_tokens, masked_pos, True]) # IsNext
positive += 1
elif tokens_a_index + 1 != tokens_b_index and negative < batch_size/2:
batch.append([input_ids, segment_ids, masked_tokens, masked_pos, False]) # NotNext
negative += 1
return batch
# Proprecessing Finished
batch = make_data()
input_ids, segment_ids, masked_tokens, masked_pos, isNext = zip(*batch)
input_ids, segment_ids, masked_tokens, masked_pos, isNext = \
torch.LongTensor(input_ids), torch.LongTensor(segment_ids), torch.LongTensor(masked_tokens),\
torch.LongTensor(masked_pos), torch.LongTensor(isNext)
class MyDataSet(Data.Dataset):
def __init__(self, input_ids, segment_ids, masked_tokens, masked_pos, isNext):
self.input_ids = input_ids
self.segment_ids = segment_ids
self.masked_tokens = masked_tokens
self.masked_pos = masked_pos
self.isNext = isNext
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.segment_ids[idx], self.masked_tokens[idx], self.masked_pos[idx], self.isNext[idx]
loader = Data.DataLoader(MyDataSet(input_ids, segment_ids, masked_tokens, masked_pos, isNext), batch_size, True)
4.4 预训练数据集

4.5 下游任务使用BERT时只要设置输入是一个句子或两个句子
对于每个具体的任务, 我们只要设置好特定的输入和输出就行了。
五、实验
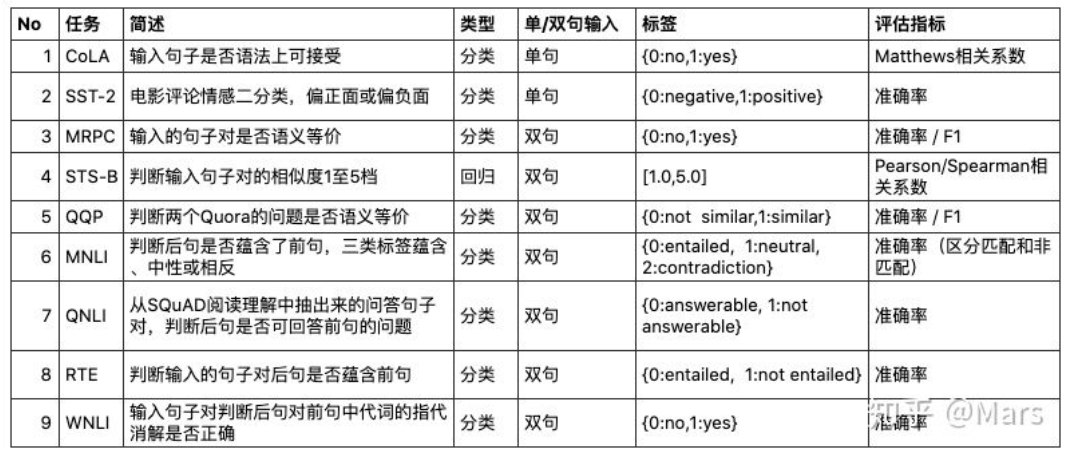
5.1 🕵️GLUE评测基准(各种下游任务)
如果要用一句话形容文本分类任务在NLP中的应用之广,某种程度上,大概这句话最适合:
一切NLP皆分类
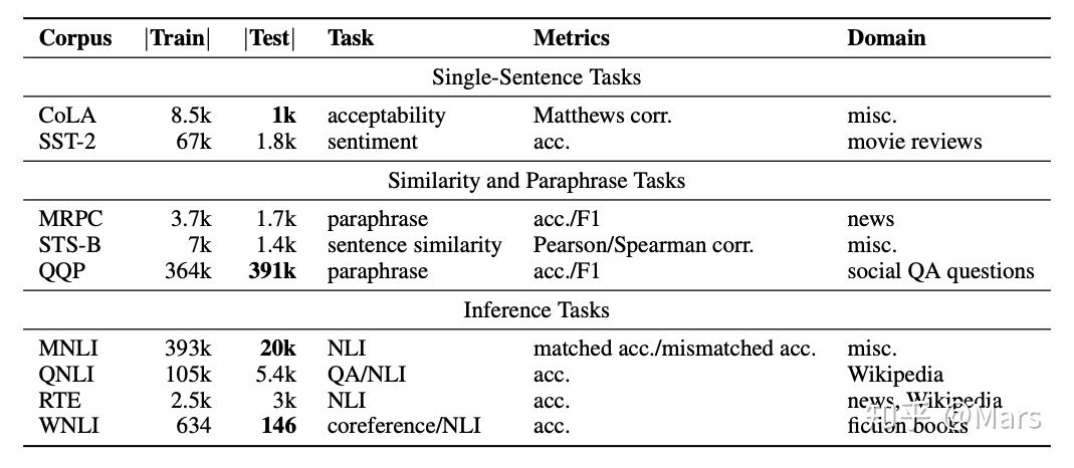
通常来说,NLP可以分为自然语言理解(NLU)和自然语言生成(NLG)。在NLU方面,我们拿时下最流行的GLUE(General Language Understanding Evaluation)排行榜举例,其上集合了九项NLU的任务
当你想测一下你的BERT的好坏时,你可以拿GLUE上面的9个任务去考一下它,看平均性能怎么样。
GLUE主要由9项任务组成,一个预训练模型在9项任务上的得分的平均即为它的最终得分。
- 知乎:GLUE数据集详细介绍
GLUE的全称是General Language Understanding Evaluation,在2018年,由纽约大学、华盛顿大学以及DeepMind的研究者们共同提出。这个基准由一系列自然语言理解数据集/任务组成,最主要的目标是鼓励开发出能够在任务之间共享通用的语言知识的模型。BERT正是建立在这样一种预训练知识共享的基础之上,在刚推出的时候狂刷11项GLUE任务的纪录,开启了一个新的时代。
GLUE:General Language Understanding Evaluation
GLUE有9项主要任务,可以归为3大类,
- CoLA和SST-2属于“单句任务”,输入是一个单一的句子,输出是某种分类判断
- MRPC、STS-B、QQP属于“句子相似任务”,输入是一个句子对,输出是这两个句子的相似度衡量
- MNLI、QNLI、RTE、WNLI这几项都是“推断任务”,输入是一个句子对,输出是后句相对于前句语义关系的一个推断
1)CoLA
全称The Corpus of Linguistic Acceptability,它是一个二分类任务,输入一个句子判断它是否在语法上可接受,可接受为1,不可接受为0. 数据的来源主要是一些语言学的书刊。示例如下:
Digitize is my happiest memory - 0
Herman hammered the metal flat. - 1
2)SST-2
该数据集来自Stanford Sentiment Treebank,针对来自于电影评论的文本进行正向或者负向的区分,因为是二极情感分析任务,因此被称作SST-2。示例如下:
standard horror flick formula 0
comes across as darkly funny , energetic , and surprisingly gentle 1
3)MRPC
全称是 Microsoft Research Paraphrase Corpus,从新闻数据源中自动摘取出一些句子对,人工标注了它们是否在语义上是相同的。示例如下:
A: More than 60 percent of the company 's 1,000 employees were killed in the attack . B: More than 60 per cent of its 1,000 employees at the time were killed .
Label: 1
A: Scientists have reported a 90 percent decline in large predatory fish in the world 's oceans since a half century ago .
B: Scientists reported a 90 percent decline in large predatory fish in the world 's oceans since a half-century ago , a dire assessment that drew immediate skepticism from commercial fishers .
Label: 0
4)QQP
全称是Quora Question Pairs,来自于著名的社区问答网站Quora,这项任务要求判断给定的两个问句是否在问同一件事情。示例如下:
A: Should animals be kept in zoos? What are your views on zoos? Why?
B: Why animals should not be kept in zoos?
Label: 1
A: How can I make money from Fivesquid?
B: How can I make money from Clikbank?
Label: 0
5)STS-B
全称是Semantic Textual Similarity Benchmark,输入的句子对来自于新闻头条、视频和图像说明文字和自然语言推断数据,人工对两个句子的相似度打了1至5的分数(浮点数),分数越高则说明相似度越高。这是9项任务中唯一一项回归任务。示例如下,最后的数字为得分:
A group of people are marching in place.
A group of people are dancing in concert.
1.700
A large black bird is sitting in the water.
The birds are swimming in the water.
2.6
From Florida to Alaska, thousands of revelers vowed to push for more legal rights, including same-sex marriages.
Thousands of revellers, celebrating the decision, vowed to push for more legal rights, including same-sex marriages.
4.200
6)MNLI
全称是Multi-Genre Natural Language Inference Corpus,文本蕴含类任务,数据来自于10种不同的数据源,包含演讲、小说、政府报告等。文本蕴含类的任务也由两个句子组成,一个句子称为premise前提,另一个句子称为hypothesis假设。需要判断在给定前提的情况下假设是否成立entailment、相反contradiction或者中性neutral。示例:
What is so original about women?
There are a lot of things original about women.
neutral
The official indicated, however, that SBA’s policy may change since future certifications will need to be justified more specifically and will be subject to judicial review.
The official indicated that there would be no change in the SBA’s policy.
contradiction
She waved me away impatiently.
She was impatiently waving me away.
entailment
7)QNLI
全称是Stanford Question Answering Dataset,来源于SQuAD阅读理解数据集。原任务是要求针对一个问题,从一篇wikipedia的文章中标识出可能存在的答案。QNLI将该问题转化成了句子对分类问题,问题句不变,但从文章中自动抽出一些句子来作为答案,需要判断该答案是否合理。示例:
What are the power variants in USB 3.0 ports?
As with previous USB versions, USB 3.0 ports come in low-power and high-power variants, providing 150 mA and 900 mA respectively, while simultaneously transmitting data at SuperSpeed rates.
entailment
What property of wood has a correlation to its density?
There is a strong relationship between the properties of wood and the properties of the particular tree that yielded it.
not_entailment
8)RTE
全称是Recognizing Textual Entailment,数据来自于年度文本蕴含挑战赛。句子对之间标识了entailment和not_entailment(neutral and contradiction)两类。示例:
Intel has decided to push back the launch date for its 4-GHz Pentium 4 desktop processor to the first quarter of 2005.
Intel would raise the clock speed of the company’s flagship Pentium 4 processor to 4 GHz.
not_entailment
Hepburn, a four-time Academy Award winner, died last June in Connecticut at age 96.
Hepburn, who won four Oscars, died last June aged 96.
entailment
9)WNLI
全称为Winograd Schema Challenge,该任务要求阅读一个含有代词的句子并判断出该代词指代的内容。GLUE的维护者们人工地将可能的指代对象组织成句子,和原句放在一起,并标注其指代是否相同,因此也是一个句子对分类任务。示例如下:
Jane knocked on the door, and Susan answered it. She invited her to come out.
Jane invited her to come out.
1
It was a summer afternoon, and the dog was sitting in the middle of the lawn. After a while, it got up and moved to a spot under the tree, because it was cooler.
The dog was cooler.
0
🤩总结:GLUE九项任务各自评估指标
GLUE中的9项任务都有各自的评估指标,如下表小结:
5.2 GLUE实验结果
GLUE是BERT论文里其中一个实验数据集,他还用了其他的一些数据集,比如斯坦福的SQuAD v1.1数据集

GLUE上面有各种下游任务,Table 1是BERT模型的效果图
六、相关问题
问题1:BERT对比的工作是ELMo和GPT吗?
是的
BERT_BASE是为了和OpenAI的GPT做一个稍微公平的比较。BERT_LARGE主要是为了刷榜。
问题2:🕵️ 概念:pre-training预训练 vs. fine-tuning微调(调所有参数)vs. Feature-based(只调下游任务参数)🍔
下面介绍BERT实现的细节,我们总共会进行两个步骤:pre-training and fine-tuning
-
During pre-training, the model is trained on unlabeled data over different pre-training tasks.
-
For fine-tuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks.
-
Each downstream task has separate fine-tuned models, even though they are initialized with the same pre-trained parameters.
其他方法:Feature-based Approach with BERT
简单来说就是固定BERT的参数,只调下游任务的参数



















 2479
2479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











