







论文笔记--BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
1. 文章简介
- 标题:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 作者:Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
- 日期:2018
- 期刊:ARXIV preprint/NAACL
2. 文章导读
2.1 概括
文章给出了一种语言模型的预训练方法,同时也将训练后的模型Bert开源。Bert是当前NLP任务中的一种主流预训练模型,其在推理、相似分析、文本分类等多个下游任务中取得了SOTA表现,以至后续又衍生了一系列的BERT模型,如ROBERTa,ALBERT等。
BERT提出了两种训练目标(objective),即MLM和NSP目标,下文会有介绍。模型的整体框架如下图所示,左边为预训练任务,右边为下游微调任务。
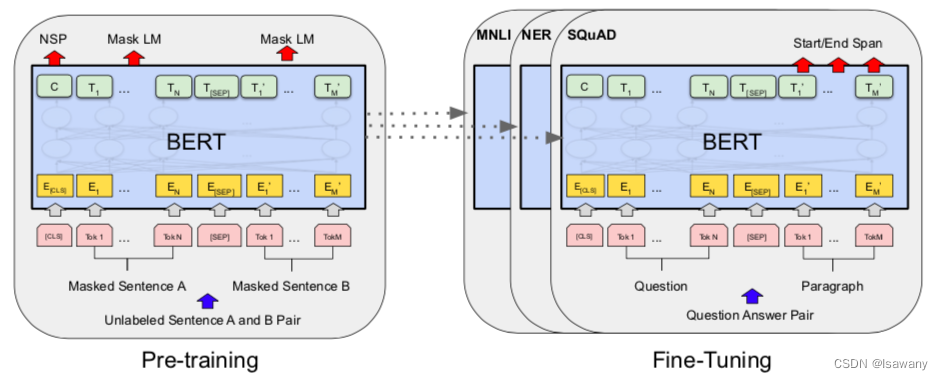
2.2 文章重点技术
2.2.1 基于Transformer的模型架构
模型基于Transformer的编码架构进行词向量训练。文章训练了两个模型
BERT
BASE
\text{BERT}_\text{BASE}
BERTBASE和
BERT
LARGE
\text{BERT}_\text{LARGE}
BERTLARGE,其中
BERT
BASE
\text{BERT}_\text{BASE}
BERTBASE和GPT-1[1]的参数大小相同,均为12层,隐藏层大小768,参数大小为110M(GPT-1为117M)。
和GPT-1区别的点在于,文章使用的是Encoder部分,即双向Transformer结构,从而预测当前词的时候考虑的是它的上下文信息。而GPT-1用的是Transformer 的Decoder部分,只用到了当前词的上文信息。
2.2.2 Masked Language Model(MLM)
针对文章构建的词表vocab,随机筛选其中15%的token作为掩码(MASK)。比如当前选中的掩码候选词表为{international, province, …}。当输入的句子为"This page contains the latest international trade data for Hainan Province.“时,其中出现了两个可能被掩码当单词"international"和"Province”。接下来,模型会针对这些单词进行随机掩码,策略为:80%的可能用"[MASK]"替换该token,10%的可能不变,10%的可能随机用其它token替换当前token。回到上述例子,international有80%的可能被替换为[MASK],10%的可能仍保持international,10%的可能随机替换为任意token。文章这里采用的随机替换的tip,可以解决FT中样本没有[MASK]的问题。
2.2.3 Next Sentence Prediction(NSP)
文章提出的第二个预训练任务是NSP,即预测第二个句子是否是第一个句子的下一句话。为此文章获取了大量真实的上下句样本对(A, B),并将其中50%的B替换为语料库的其它句子C。真实的上下句标记为IsNext,伪造的非上下句标记为NotNext,相当于让模型学习一个分类任务。注意,NSP的输入句子中依然采用MLM策略,即可能存在[MASK]token。
NSP任务的输入句子对可通过[SEP]分隔。下图例子中输入包含两个句子,由[SEP]分隔,[CLS]表示句子开头,输入出了词向量编码、位置编码之外,还有分隔编码区别两个句子。
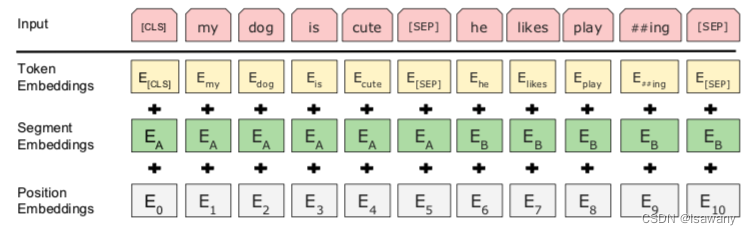
3. 文章亮点
文章提出了一种利用Transformer的双向编码结构进行预训练的方法,且提出了MLM和NSP两个训练模型。得到的 BERT LARGE \text{BERT}_\text{LARGE} BERTLARGE模型在包括QA、NLI、文本相似度等多个任务上达到了SOTA水平。BERT模型的成功证明了双向架构的预训练模型可以在很多NLP任务上取得成功。
4. 原文传送门
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
5. References
[1] 论文笔记–Improving Language Understanding by Generative Pre-Training















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









