







Attention Is All You Need
attention:连接encoder和decoder
注意力机制是啥?
贡献:
使用纯注意力机制构建神经网络,没有使用卷积和循环。
用途:机器翻译
背景
1.在时序模型(例如RNN)中,在计算时将位置与步骤对齐,它们生成一系列隐藏状态
h
t
,
t
h_t,t
ht,t位置的
h
t
h_{t}
ht 使用它的前驱隐藏状态
h
t
−
1
h_{t − 1}
ht−1和当前的输入生成的。这样限制了模型的并行能力。
2.顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于 特别长的依赖现象,LSTM依旧无能为力。
贡献
1.文中提出了Transformer,第一个完全基于attention的序列转换模型,将序列中的任意两个位置之间的距离是缩小为一个常量;
2.它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架
模型架构

编码-解码器架构
编码器:从单词序列到句子表示
解码器:从句子到单词输出–自回归
自回归(auto-regression):当前时刻的输入是下一时刻的输出
编码器
N=6,完全一样的层(layer)
每个层中会有两个子层(sub-layer):
第一个子层,第一层是multi-head self-attention机制;第二个子层,(a simple, position wise fully connected feed-forward network)是一个简单的、位置全连接的前馈神经网络,每一个子层用一个残差连接,接着进行layer normalization。
每个子层的输出是LayerNorm(x+Sublayer(x))
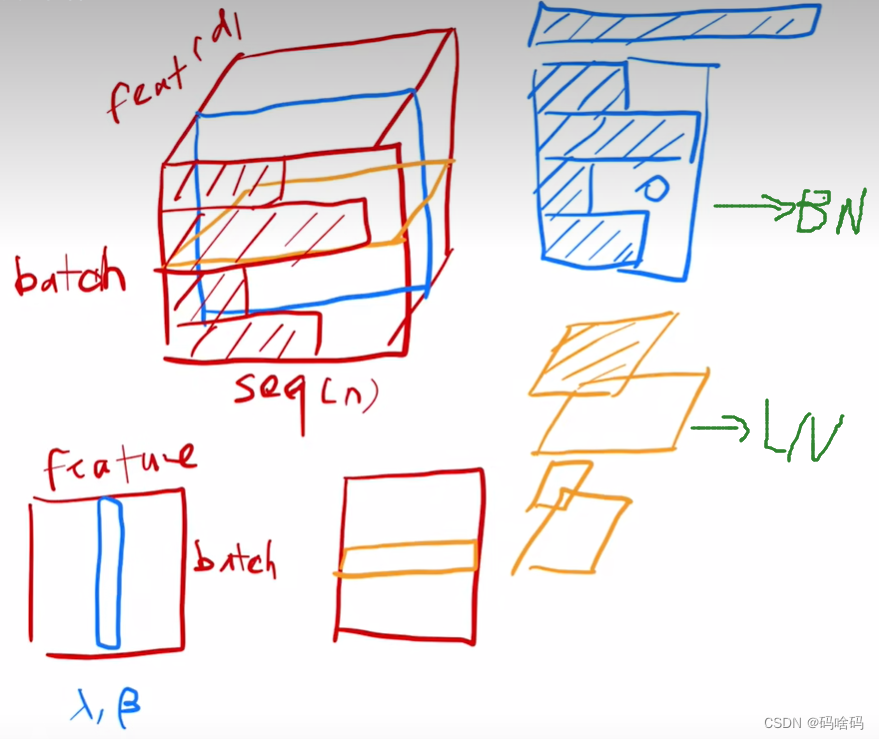
LayerNorm,
LayerNorm与batchNorm比较类似
以二维为例,BN是将feature在一个小的mini-batch中变为均值为0方差为1,BN也会学习一个
l
a
m
b
d
a
和
g
a
m
m
a
lambda和gamma
lambda和gamma将其变为任意方差和均值。而LN是将每一个行变为均值为0方差为1
解码器
解码器中前两个子层和编码器相同,但比编码器多一个子层,第三个子层,多头注意力机制,每一层都用残差网络连接,之后再采用layernorm。
在注意力机制可以看到完整输入,应该避免这种情况。解码器训练的时候,在预测t时刻的输出不应该看到时刻以后的输入,通过一个带掩码的注意力机制(masked Multi-Head Attention)实现。
注意力(Attention)
Attention机制可以描述为将一个query和一组key-value对映射到一个输出,其中query,keys,values和输出均是向量。输出是values的加权求和,其中每个value的权重 通过query与相应key的兼容函数来计算。
加法注意力机制(Additive attention),没有缩放因子 1 d k \frac{1}{\sqrt{d_k}} dk1其他都一样。
点积注意力机制(dot-product attention),使用一个具有单隐层的前馈神经网络来计算兼容性函数。尽管在理论上两者的复杂度相似,但是在实践中dot-product attention要快得多,而且空间效率更高,这是因为它可以使用高度优化的矩阵乘法代码来实现。


当 d k d_k dk的值较小时,这两种方法性能表现的相近,当 d k d_k dk比较大时,addtitive attention表现优于 dot-product attention。我们认为对于大的 d k d_k dk,点积在数量级上增长的幅度大,将softmax函数推向具有极小梯度的区域 4 ^4 4。为了抵消这种影响,我们对点积扩展 1 d k \frac{1}{\sqrt{d_k}} dk1倍。
多头注意力机制(Multi-Head Attention)
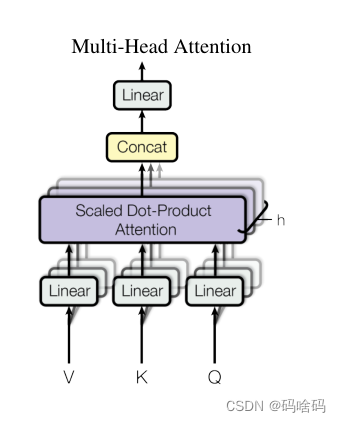
如果只对Q , K , V Q,K,VQ,K,V做一次这样的权重操作是不够的,这里提出了Multi-Head Attention,操作包括:
1.首先对
Q
,
K
,
V
Q , K , V
Q,K,V做若干次(
h
t
i
m
e
s
h \quad times
htimes)线性映射,将输入维度均为
d
m
o
d
e
l
d_{model}
dmodel 的
Q
,
K
,
V
Q , K , V
Q,K,V矩阵映射到
Q
∈
R
d
k
,
K
∈
R
d
k
,
V
∈
R
d
v
Q \in \mathbb R^{d_{k}}, K \in \mathbb R^{d_{k}}, V \in \mathbb R^{d_{v}}
Q∈Rdk,K∈Rdk,V∈Rdv
2.然后分别对每个线性映射结果采用Scaled Dot-Product Attention计算出结果,拼接在一起
3.将合并的结果进行线性变换
公式:

Position-wise Feed-forward Networks
在进行了Attention操作之后,encoder和decoder中的每一层都包含了一个全连接前向网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出。

其中每一层的参数都不同。
Position Embedding
因为模型不包括recurrence/convolution,因此是无法捕捉到序列顺序信息的,例如将 K 、 V K、V K、V按行进行打乱,那么Attention之后的结果是一样的。但是序列信息非常重要,代表着全局的结构,因此必须将序列的token相对或者绝对position信息利用起来。
这里每个token的position embedding 向量维度也是
d
m
o
d
e
l
=
512
d_{model}= 512
dmodel=512然后将原本的input embedding和position embedding加起来组成最终的embedding作为encoder/decoder的输入。其中position embedding计算公式如下

其中
p
o
s
pos
pos表示位置index,
i
i
i表示dimension。
为什么要用自注意力机制
这里将Self-Attention layers和recurrent/convolutional layers来进行比较,来说明Self-Attention的好处。假设将一个输入序列
(
x
1
,
x
2
,
…
,
x
n
)
(x_1,x_2,\ldots,x_n)
(x1,x2,…,xn)分别用上述提到的网络来映射到一个相同长度的序列
(
z
1
,
z
2
,
…
,
z
n
)
(z_1,z_2,\ldots,z_n)
(z1,z2,…,zn)

Complexity per Layer:计算复杂度,越少越好
Sequential Operations:顺序计算,越少越好,下一步计算必须等前面计算
Maximum Path Length:一个数据点到另一个数据点要走多远,越短越好
并行计算
Self-Attention layer用一个常量级别的顺序操作,将所有的positions连接起来
Recurrent Layer需要
O
(
n
)
O(n)
O(n)个顺序操作
计算复杂度分析
如果序 列 长 度 n < 表 示 维 度 d 序列长度n< 表示维度 d序列长度n<表示维度d,Self-Attention Layer比recurrent layers快,这对绝大部分现有模型和任务都是成立的。
为了提高在序列长度很长的任务上的性能,我们对Self-Attention进行限制,只考虑输入序列中窗口为 r r r的位置上的信息,这称为Self-Attention(restricted), 这会增加maximum path length到 O ( n / r ) O(n/r) O(n/r)
length path
如果卷积层kernel width k
<
n
< n
<n,并不会将所有位置的输入和输出都连接起来。这样需要
O
(
n
/
k
)
O(n/k)
O(n/k)个卷积层或者
O
(
l
o
g
k
(
n
)
)
O(log_k(n))
O(logk(n))个dilated convolution,增加了输入输出之间的最大path length。
卷积层比循环层计算复杂度更高,是 k k k倍。但是Separable Convolutions将减小复杂度。
同时self-attention的模型可解释性更好(interpretable).
实验
WMT 2014英语-德语数据集上进行了训练
优化器:Adam,其中β1 = 0.9, β2 = 0.98及ϵ= 10-9。
对学习率不敏感,已经考虑到了
学习率,根据模型的-0.5次方
warmup从小慢慢爬到大的数
每个子层的输出上执行dropout操作,dropout=0.1
评价
1.减去了对文本的各种预处理
2.transform也在图片上有广泛的应用
3.对T理解还在初级阶段
4.其中的残差网络等必不可上,只有attention是不可以做训练的















 2923
2923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









