







论文:
PA3D: Pose-Action 3D Machine for Video Recognition
背景
然而,现有的大多数方法主要建立在两种输入类型上,即RGB和光流。这忽略了另一个辨别动作线索,即人体姿势动态。
解决的问题
- 使用人体姿势动态区别于现在主流的方法:光流和RGB
- 姿势表示和动作识别是孤立的,没有自适应交互,这可能会限制对野生视频中复杂动作的理解能力。
- 解决动作识别研究缺乏一个统一的框架,即一个通用的语义流,这是对双流三维cnn的补充。
贡献
- PA3D是一个简洁的3D CNN框架,它可以在多层次的方式下分解语义任务(semantic task姿势/动作)、卷积运算convolution operate(空间/时间)、姿态模态pose modality(关节/部位亲和场/卷积特征)来达到学习效率。在这种情况下,PA3D可以灵活地编码各种姿态动态作为判别线索对复杂动作进行分类。
- 提出了一种新的时域位姿卷积算法(temporal pose convolution operation),该算法主要由时间关联(temporal pose)和语义卷积(semantic convolution)两部分组成,对姿势动作进行编码。与传统三维cnn中的时间卷积不同,我们的时域位姿卷积可以学习一个时空语义(spatio-temporal)表示来明确描述姿态运动。
此外,我们的时间扩张设计(temporal dilation)允许该卷积捕获复杂的动作与多尺度姿态动力学(multi-scale pose dynamics)。 - 它是双流3D cnn(如I3D)的高度补充,在双流3D cnn中,评分融合可在所有评估数据集上获得最先进的性能。因此,我们的PA3D可以用作人类动作识别的另一个语义流。
方法:Pose-Action 3D (PA3D) machine
结构
- 空间姿态CNN(Spational Pose CNN):空间姿态CNN可以为每个采样视频帧稳健地提取不同形式的姿态热图(即关节、部分亲和场和卷积特征)[1]
- 时间姿态卷积(Temporal Pose CNN):时间位姿卷积可以自适应聚合帧上的空间位姿热图,为每个位姿模态生成一个时空位姿表示
- 动作CNN(Action CNN):最后,action CNN将学习到的姿势表示作为输入来识别人类动作。由于PA3D是建立在一个简洁的时空三维框架之上的,它可以作为视频动作识别的另一种语义流。
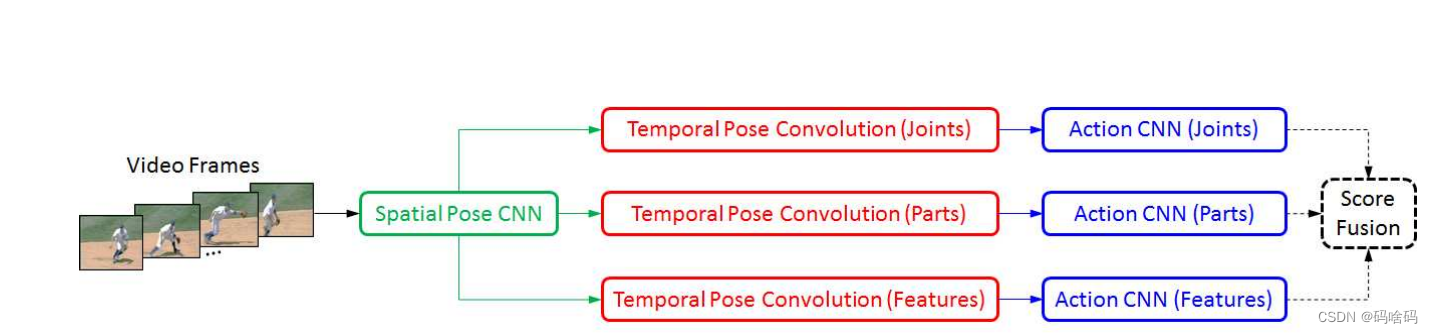
空间姿态CNN(Spational Pose CNN)
每个视频帧输入到这个Spational Pose CNN,提取三种姿势形态,
- joints :指人体关节的预测置信度图
- part affinity fields :指在身体肢体[1]的支撑区域内同时保留位置和方向信息的预测置信度图。
- convolutional features :指[1]中CNN骨干网的一个卷积层的特征映射,例如VGG19的第10层。
输入图像shape:(H*W)
经过此模块得到联合热图:
J t ∈ R C ∗ H ∗ W J_t \in R^{C*H*W} Jt∈RC∗H∗W,
它表示t时刻视频帧的联合热图,由C张热图组成,大小为H × W,其中C为人体关节的数量。
时间姿态卷积(Temporal Pose CNN)
在获得每个帧的空间位姿热图(例如Jt)后,我们提出了一种新的时间位姿卷积来编码帧上的位姿动态。如图2所示,它主要包括两个原子操作,即时间关联和语义卷积
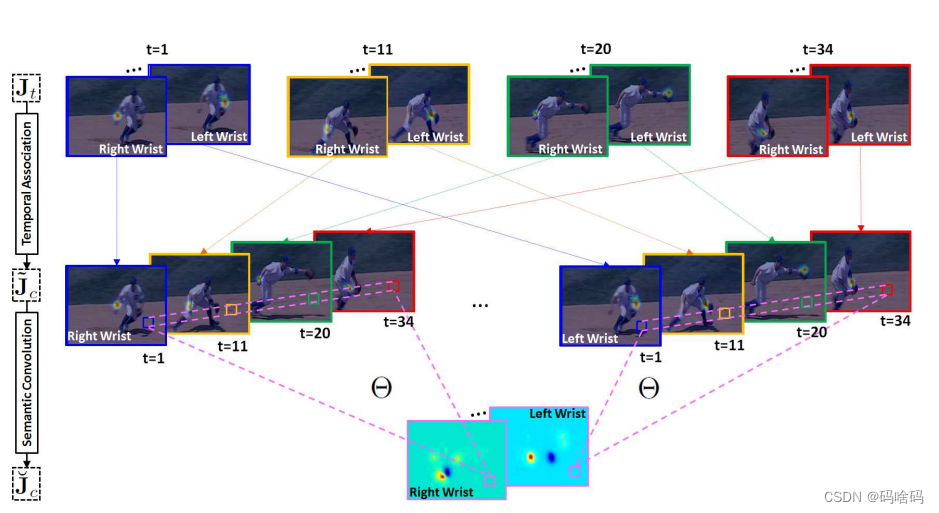
- 时序关联(Temporal Association):
对于每个关节,我们首先将所有帧的热图按时间顺序堆叠起来。该操作可以为第c个关节生成一个时间相关的立方体,即 J ~ c ∈ R T × H × W \tilde{J}_c∈R^{T ×H×W} J~c∈RT×H×W,其中, J ~ \tilde{J} J~的第t个通道指的是第c个关节在第t个时间的热图。 - 语义卷积(Semantic Convolution):在获得第c个关节的临时相关立方体在获得第c个关节的临时相关立方体
J
~
c
\tilde{J}_c
J~c之后,我们将其编码到帧上的时空姿势表示。正如前面所提到的,
J
~
\tilde{J}
J~的通道对应于第c个关节的时序热图。在本例中,我们直接对
J
~
c
\tilde{J}_c
J~c进行1 × 1卷积,以生成时空位姿表示
J
~
c
∈
R
N
×
H
×
W
\tilde{J}_c∈R^{N×H×W}
J~c∈RN×H×W之后,我们将其编码到帧上的时空姿势表示。正如前面所提到的,
J
~
c
\tilde{J}_c
J~c的通道对应于第c个关节的时序热图。在本例中,我们直接对
J
~
c
\tilde{J}_c
J~c进行1 × 1卷积,以生成时空位姿表示
J
˘
c
∈
R
N
×
H
×
W
\breve{J}_c∈R^{N×H×W}
J˘c∈RN×H×W

J ˘ c \breve{J}_c J˘c的N个输出通道不仅是抽象的特征映射,也表示语义上编码第c个关节在帧上的运动, Θ \Theta Θ表示 R N ∗ T ∗ 1 ∗ 1 R^{N*T*1*1} RN∗T∗1∗1的滤波器, J ˘ c ∈ R N ∗ H ∗ W \breve{J}_c\in R^{N*H*W} J˘c∈RN∗H∗W
- 通过时间扩张的多尺度设计(Multi-Scale Design via Temporal Dilation):对于每个关节,语义卷积在所有帧上执行。因此,时空表征
J
˘
c
\breve{J}_c
J˘c可能缺乏描述姿态运动的各种尺度的能力。为了解决这个问题,我们引入了时间膨胀卷积,

其中 Φ ∈ R M × ( T / d ) × 1 × 1 Φ∈R^{M×(T /d)×1×1} Φ∈RM×(T/d)×1×1为扩张卷积滤波器,d为扩张因子,M为输出热图数。如下图所示,时间扩展允许我们在那些通道上执行语义卷积
J ^ c ∈ R M ∗ H ∗ W \hat J_c\in R^{M*H*W} J^c∈RM∗H∗W

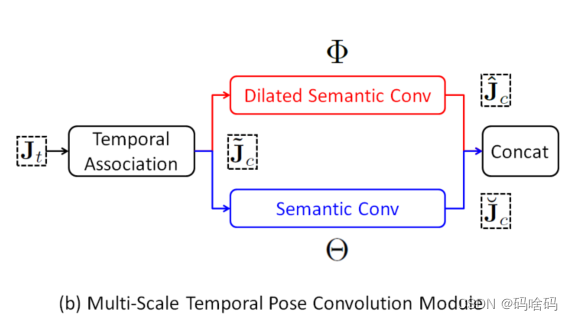
时间扩张允许我们在这些通道上以d个时间步的间隔(例如d = 2)进行语义卷积。因此,它可以学习不同时间尺度下的姿态动态。
动作卷积( Action CNN)
在获得动作的时空表示后,将其输入到动作CNN中,用于视频中的动作识别。
卷积网络如下图所示

R为时空姿态表示中的特征通道数
[1] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields















 2508
2508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









